Tôi đã xuất bản nhiều điểm chuẩn so sánh các phiên bản PostgreSQL khác nhau, chẳng hạn như cuộc nói chuyện khảo cổ học về hiệu suất (đánh giá PostgreSQL 7,4 lên đến 9,4) và tất cả các điểm chuẩn đó được giả định trong môi trường cố định (phần cứng, nhân,…). Điều này tốt trong nhiều trường hợp (ví dụ:khi đánh giá tác động hiệu suất của một bản vá), nhưng trong quá trình sản xuất, những thứ đó thay đổi theo thời gian - bạn nhận được các bản nâng cấp phần cứng và thỉnh thoảng bạn nhận được bản cập nhật với phiên bản hạt nhân mới.
Đối với các nâng cấp phần cứng (lưu trữ tốt hơn, nhiều RAM hơn, CPU nhanh hơn,…), tác động thường khá dễ dự đoán và hơn nữa, mọi người thường nhận ra rằng họ cần đánh giá tác động bằng cách phân tích các nút thắt trong quá trình sản xuất và thậm chí có thể thử nghiệm phần cứng mới trước tiên .
Nhưng đối với các bản cập nhật hạt nhân thì sao? Đáng buồn là chúng tôi thường không đo điểm chuẩn trong lĩnh vực này. Hầu hết giả định là các nhân mới tốt hơn các nhân cũ (nhanh hơn, hiệu quả hơn, mở rộng đến nhiều nhân CPU hơn). Nhưng có thực sự đúng? Và sự khác biệt là lớn như thế nào? Ví dụ:điều gì sẽ xảy ra nếu bạn nâng cấp hạt nhân từ 3.0 lên 4.7 - điều đó có ảnh hưởng đến hiệu suất không và nếu có, hiệu suất có được cải thiện hay không?
Thỉnh thoảng, chúng tôi nhận được báo cáo về sự thụt lùi nghiêm trọng với một phiên bản hạt nhân cụ thể hoặc sự cải thiện đột ngột giữa các phiên bản hạt nhân. Vì vậy, rõ ràng, các phiên bản hạt nhân có thể ảnh hưởng đến hiệu suất.
Tôi biết một điểm chuẩn PostgreSQL duy nhất so sánh các phiên bản hạt nhân khác nhau, được thực hiện vào năm 2014 bởi Sergey Konoplev theo khuyến nghị tránh các hạt nhân 3.0 - 3.8. Nhưng điểm chuẩn đó khá cũ (phiên bản hạt nhân cuối cùng có sẵn ~ 18 tháng trước là 3,13, trong khi ngày nay chúng ta có 3,19 và 4,6), vì vậy tôi đã quyết định chạy một số điểm chuẩn với các hạt nhân hiện tại (và PostgreSQL 9.6beta1).
Phiên bản hạt nhân PostgreSQL so với
Nhưng trước tiên, hãy để tôi thảo luận về một số khác biệt đáng kể giữa các chính sách điều chỉnh cam kết trong hai dự án. Trong PostgreSQL, chúng tôi có khái niệm về các phiên bản chính và phụ - các phiên bản chính (ví dụ:9.5) được phát hành khoảng một năm một lần và bao gồm nhiều tính năng mới khác nhau. Các phiên bản nhỏ (ví dụ:9.5.2) chỉ bao gồm các bản sửa lỗi và được phát hành khoảng ba tháng một lần (hoặc thường xuyên hơn, khi một lỗi nghiêm trọng được phát hiện). Vì vậy, sẽ không có thay đổi lớn về hiệu suất hoặc hành vi giữa các phiên bản nhỏ, điều này làm cho việc triển khai các phiên bản nhỏ trở nên khá an toàn mà không cần thử nghiệm rộng rãi.
Với các phiên bản hạt nhân, tình hình ít rõ ràng hơn nhiều. Nhân Linux cũng có các nhánh (ví dụ:2.6, 3.0 hoặc 4.7), những nhánh này không giống với “các phiên bản chính” từ PostgreSQL, vì chúng tiếp tục nhận được các tính năng mới chứ không chỉ là các bản sửa lỗi. Tôi không khẳng định rằng chính sách lập phiên bản PostgreSQL bằng cách nào đó tự động vượt trội, nhưng hậu quả là việc cập nhật giữa các phiên bản hạt nhân nhỏ có thể dễ dàng ảnh hưởng đáng kể đến hiệu suất hoặc thậm chí gây ra lỗi (ví dụ:3.18.37 gặp phải sự cố OOM do một bản sửa lỗi không phải như vậy cam kết).
Tất nhiên, các bản phân phối nhận ra những rủi ro này và thường khóa phiên bản hạt nhân và kiểm tra thêm để loại bỏ các lỗi mới. Tuy nhiên, bài đăng này sử dụng hạt vani lâu năm, có trên www.kernel.org.
Điểm chuẩn
Có rất nhiều điểm chuẩn mà chúng tôi có thể sử dụng - bài đăng này trình bày một bộ các bài kiểm tra pgbench, tức là điểm chuẩn OLTP (giống TPC-B) khá đơn giản. Tôi dự định thực hiện các bài kiểm tra bổ sung với các loại điểm chuẩn khác (đặc biệt là định hướng DWH / DSS) và tôi sẽ trình bày chúng trên blog này trong tương lai.
Bây giờ, quay lại pgbench - khi tôi nói "bộ sưu tập các bài kiểm tra", ý tôi là sự kết hợp của
- chỉ đọc so với đọc-ghi
- kích thước tập dữ liệu - tập hợp hoạt động (không) vừa với bộ đệm / RAM được chia sẻ
- số lượng khách hàng - một khách hàng so với nhiều khách hàng (khóa / lập lịch)
Các giá trị rõ ràng phụ thuộc vào phần cứng được sử dụng, vì vậy hãy xem vòng điểm chuẩn này đang chạy trên phần cứng nào:
- CPU:Intel i5-2500k @ 3,3 GHz (turbo 3,7 GHz)
- RAM:8GB (DDR3 @ 1333 MHz)
- bộ nhớ:6x Intel SSD DC S3700 trong RAID-10 (Linux sw đột kích)
- hệ thống tệp:ext4 với bộ lập lịch I / O mặc định (cfq)
Vì vậy, đó cũng chính là chiếc máy tôi đã sử dụng cho một số điểm chuẩn trước đó - một chiếc máy khá nhỏ, không chính xác là CPU mới nhất, v.v. nhưng tôi tin rằng nó vẫn là một hệ thống “nhỏ” hợp lý.
Các thông số điểm chuẩn là:
- quy mô tập dữ liệu:30, 300 và 1500 (khoảng 450 MB, 4,5 GB và 22,5 GB)
- số lượng khách hàng:1, 4, 16 (máy có 4 lõi)
Đối với mỗi kết hợp, có 3 lần chạy chỉ đọc (mỗi lần 15 phút) và 3 lần chạy đọc-ghi (mỗi lần 30 phút). Tập lệnh thực tế thúc đẩy điểm chuẩn có sẵn tại đây (cùng với kết quả và dữ liệu hữu ích khác).
Lưu ý :Nếu bạn có phần cứng khác nhau đáng kể (ví dụ:ổ đĩa quay), bạn có thể thấy các kết quả rất khác nhau. Nếu bạn có một hệ thống mà bạn muốn thử nghiệm, hãy cho tôi biết và tôi sẽ giúp bạn làm điều đó (giả sử tôi được phép xuất bản kết quả).
Phiên bản hạt nhân
Về các phiên bản hạt nhân, tôi đã thử nghiệm các phiên bản mới nhất trong tất cả các nhánh dài hạn kể từ 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 và 4.7). Vẫn còn rất nhiều hệ thống chạy trên hạt nhân 2.6.x, vì vậy sẽ rất hữu ích nếu bạn biết được hiệu suất mà bạn có thể đạt được (hoặc mất đi) bằng cách nâng cấp lên nhân mới hơn. Nhưng tôi đã tự biên dịch tất cả các nhân (tức là sử dụng nhân vani, không có các bản vá dành riêng cho phân phối) và các tệp cấu hình nằm trong kho lưu trữ git.
Kết quả
Như thường lệ, tất cả dữ liệu có sẵn trên bitbucket, bao gồm cả
- tệp .config kernel
- tập lệnh điểm chuẩn (run-pgbench.sh)
- Cấu hình PostgreSQL (với một số điều chỉnh cơ bản cho phần cứng)
- Nhật ký PostgreSQL
- nhật ký hệ thống khác nhau (dmesg, sysctl, mount,…)
Các biểu đồ sau đây cho thấy tps trung bình cho mỗi trường hợp được chuẩn - kết quả cho ba lần chạy khá nhất quán, với sự khác biệt ~ 2% giữa tối thiểu và tối đa trong hầu hết các trường hợp.
chỉ đọc
Đối với tập dữ liệu nhỏ nhất, có sự sụt giảm hiệu suất rõ ràng từ 3,4 đến 3,10 đối với tất cả số lượng khách hàng. Tuy nhiên, kết quả cho 16 máy khách (gấp 4 lần số lõi) so với hồi phục trong 3,12.
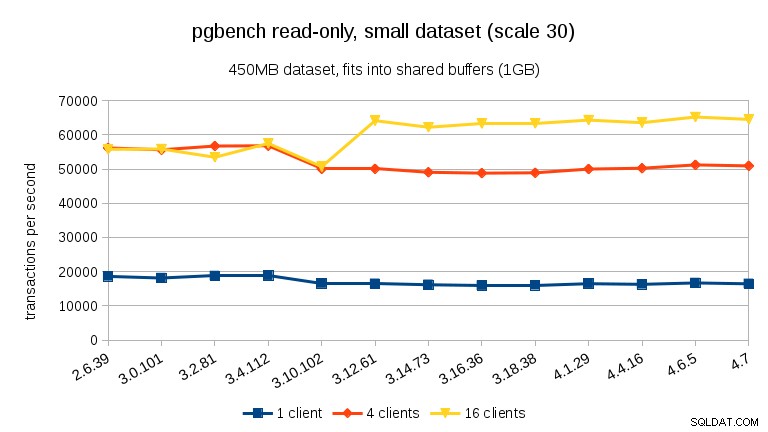
Đối với tập dữ liệu trung bình (vừa với RAM nhưng không phù hợp với bộ đệm được chia sẻ), chúng ta có thể thấy mức giảm tương tự giữa 3,4 và 3,10 nhưng không phải là sự phục hồi trong 3,12.
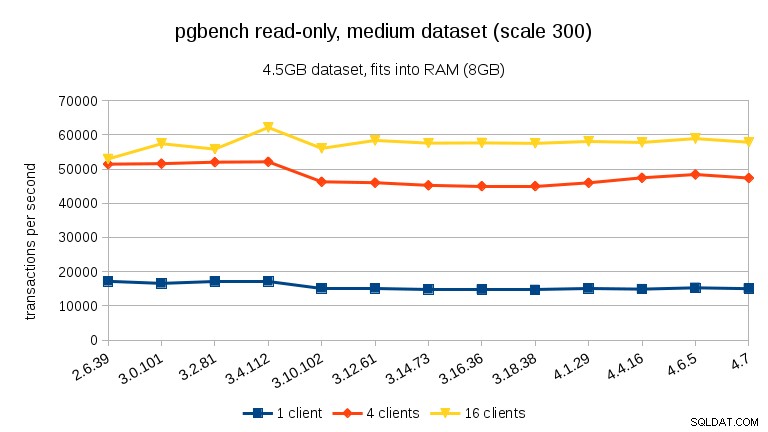
Đối với các bộ dữ liệu lớn (vượt quá RAM, quá nhiều I / O bị ràng buộc), kết quả rất khác nhau - tôi không chắc điều gì đã xảy ra giữa 3.10 và 3.12, nhưng việc cải thiện hiệu suất (đặc biệt đối với số lượng khách hàng cao hơn) là khá đáng kinh ngạc.
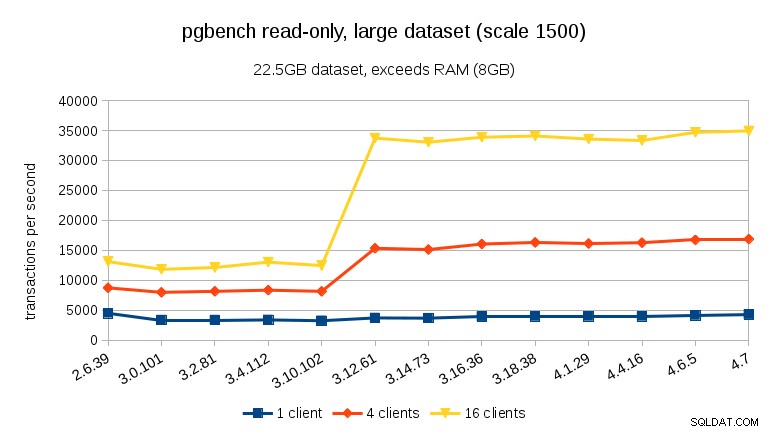
đọc-ghi
Đối với khối lượng công việc đọc-ghi, kết quả khá giống nhau. Đối với các tập dữ liệu vừa và nhỏ, chúng ta có thể quan sát thấy mức giảm tương tự ~ 10% trong khoảng từ 3,4 đến 3,10, nhưng đáng buồn là không có sự phục hồi nào trong 3,12.
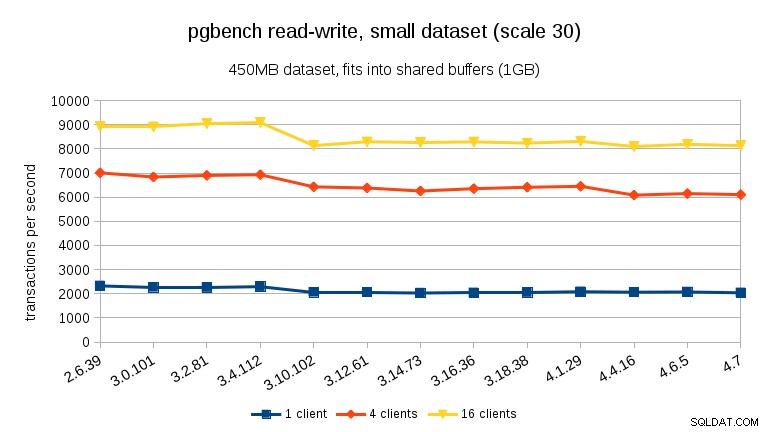
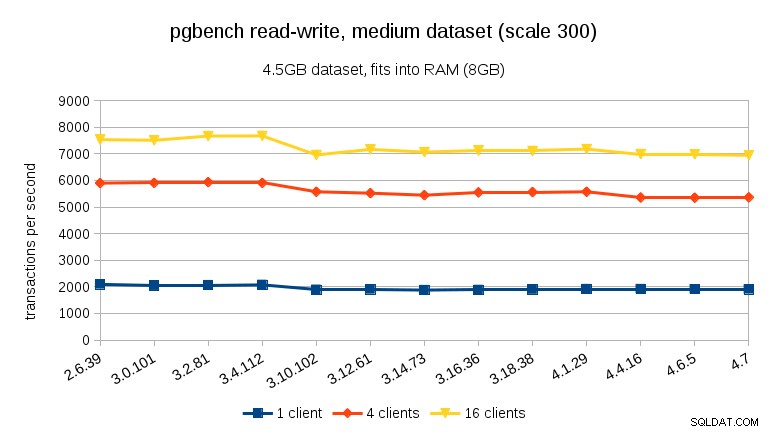
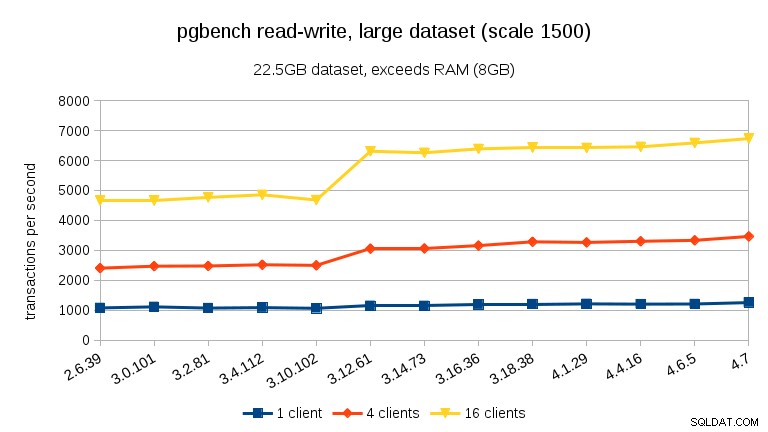
Đối với tập dữ liệu lớn (một lần nữa, ràng buộc I / O đáng kể), chúng ta có thể thấy sự cải thiện tương tự trong 3.12 (không đáng kể như đối với khối lượng công việc chỉ đọc, nhưng vẫn đáng kể):
Tóm tắt
Tôi không dám đưa ra kết luận từ một điểm chuẩn trên một máy duy nhất, nhưng tôi nghĩ có thể an toàn khi nói:
- Hiệu suất tổng thể khá ổn định, nhưng chúng ta có thể thấy một số thay đổi đáng kể về hiệu suất (theo cả hai hướng).
- Với các tập dữ liệu vừa với bộ nhớ (vào shared_buffers hoặc ít nhất là vào RAM), chúng tôi thấy hiệu suất có thể đo lường giảm trong khoảng từ 3,4 đến 3,10. Trong thử nghiệm chỉ đọc, điều này sẽ phục hồi một phần trong 3.12 (nhưng chỉ đối với nhiều ứng dụng khách).
- Với các tập dữ liệu vượt quá bộ nhớ và do đó chủ yếu là I / O bị ràng buộc, chúng tôi không thấy bất kỳ sự sụt giảm hiệu suất nào như vậy mà thay vào đó là sự cải thiện đáng kể trong 3.12.
Về lý do tại sao những thay đổi đột ngột đó lại xảy ra, tôi không chắc lắm. Có nhiều cam kết có thể liên quan giữa các phiên bản, nhưng tôi không chắc làm thế nào để xác định cam kết chính xác mà không cần thử nghiệm rộng rãi (và tốn thời gian). Nếu bạn có ý tưởng khác (ví dụ:biết về những cam kết đó), hãy cho tôi biết.