Phân vùng là một tính năng của SQL Server thường được triển khai để giảm bớt các thách thức liên quan đến khả năng quản lý, tác vụ bảo trì hoặc khóa và chặn. Việc quản lý các bảng lớn có thể trở nên dễ dàng hơn với việc phân vùng và nó có thể cải thiện khả năng mở rộng và tính khả dụng. Ngoài ra, sản phẩm phụ của phân vùng có thể được cải thiện hiệu suất truy vấn. Đó không phải là một sự đảm bảo hay một điều đã cho và đó không phải là lý do thúc đẩy việc triển khai phân vùng, nhưng đó là điều đáng xem xét khi bạn phân vùng một bảng lớn.
Bối cảnh
Như một đánh giá nhanh, tính năng phân vùng SQL Server chỉ có sẵn trong các Phiên bản dành cho nhà phát triển và doanh nghiệp. Phân vùng có thể được thực hiện trong quá trình thiết kế cơ sở dữ liệu ban đầu, hoặc nó có thể được đưa vào vị trí sau khi một bảng đã có dữ liệu trong đó. Hãy hiểu rằng việc thay đổi một bảng hiện có với dữ liệu thành một bảng được phân vùng không phải lúc nào cũng nhanh chóng và đơn giản, nhưng nó khá khả thi với việc lập kế hoạch tốt và có thể nhanh chóng nhận ra lợi ích.
Bảng được phân vùng là một trong đó dữ liệu được tách thành các cấu trúc vật lý nhỏ hơn dựa trên giá trị của một cột cụ thể (được gọi là cột phân vùng, được xác định trong hàm phân vùng). Nếu bạn muốn phân tách dữ liệu theo năm, bạn có thể sử dụng cột có tên DateSold làm cột phân vùng và tất cả dữ liệu cho năm 2013 sẽ nằm trong một cấu trúc, tất cả dữ liệu cho năm 2012 sẽ nằm trong một cấu trúc khác, v.v. Những tập hợp dữ liệu riêng biệt này cho phép bảo trì tập trung (bạn có thể chỉ xây dựng lại một phân vùng của một chỉ mục, thay vì toàn bộ chỉ mục) và cho phép nhanh chóng thêm và xóa dữ liệu vì nó có thể được sắp xếp trước khi thực sự được thêm vào hoặc xóa khỏi bảng.
Thiết lập
Để kiểm tra sự khác biệt về hiệu suất truy vấn cho bảng được phân vùng so với bảng không được phân vùng, tôi đã tạo hai bản sao của bảng Sales.SalesOrderHeader từ cơ sở dữ liệu AdventureWorks2012. Bảng không phân vùng được tạo chỉ với một chỉ mục được phân nhóm trên SalesOrderID, khóa chính truyền thống của bảng. Bảng thứ hai được phân vùng trên OrderDate, với OrderDate và SalesOrderID là khóa phân cụm và không có chỉ mục bổ sung. Lưu ý rằng có nhiều yếu tố cần xem xét khi quyết định sử dụng cột nào để phân vùng. Việc phân vùng thường xuyên, nhưng chắc chắn không phải lúc nào cũng sử dụng trường ngày tháng để xác định ranh giới phân vùng. Do đó, OrderDate đã được chọn cho ví dụ này và các truy vấn mẫu được sử dụng để mô phỏng hoạt động điển hình đối với bảng SalesOrderHeader. Có thể tải xuống các câu lệnh để tạo và điền cả hai bảng tại đây.
Sau khi tạo bảng và thêm dữ liệu, các chỉ mục hiện có đã được xác minh và sau đó được cập nhật thống kê với FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Ngoài ra, cả hai bảng đều có cùng phân phối dữ liệu chính xác và sự phân mảnh tối thiểu.
Hiệu suất cho một truy vấn đơn giản
Trước khi bất kỳ chỉ mục bổ sung nào được thêm vào, một truy vấn cơ bản đã được thực hiện dựa trên cả hai bảng để tính tổng số tiền mà nhân viên bán hàng kiếm được cho các đơn đặt hàng được đặt vào tháng 12 năm 2012:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOTHỐNG KÊ IO ĐẦU RA
Bảng 'Bàn làm việc'. Quét đếm 0, đọc lôgic 0, đọc vật lý 0, đọc trước đọc 0, đọc lôgic 0, đăng nhập vật lý 0, đọc trước lôgic đọc 0.
Bảng 'Big_SalesOrderHeader'. Quét đếm 9, đọc logic 2710440, đọc vật lý 2226, đọc trước 2658769, đọc logic lob 0, đọc vật lý lob 0, đọc trước lob đọc 0.
Bảng 'Bàn làm việc'. Quét đếm 0, đọc lôgic 0, đọc vật lý 0, đọc trước đọc 0, lôgic đọc 0, đọc dữ liệu vật lý 0, đọc trước hành động đọc 0.
Bảng 'Part_SalesOrderHeader'. Quét đếm 9, đọc logic 248128, đọc vật lý 3, đọc trước 245030, đọc logic lob 0, đọc vật lý lob 0, đọc trước lob đọc 0.

Tổng số theo Nhân viên bán hàng trong tháng 12 - Bảng không phân vùng
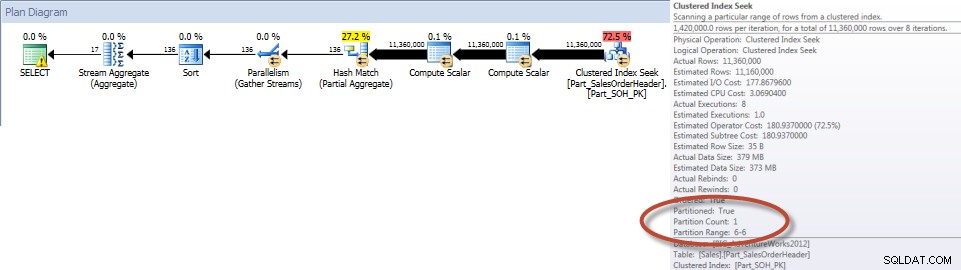
Tổng số theo Nhân viên bán hàng trong tháng 12 - Bảng phân vùng
Như mong đợi, truy vấn chống lại bảng không được phân vùng phải thực hiện quét toàn bộ bảng vì không có chỉ mục nào hỗ trợ nó. Ngược lại, truy vấn chống lại bảng được phân vùng chỉ cần thiết để truy cập một phân vùng của bảng.
Công bằng mà nói, nếu đây là một truy vấn được thực thi lặp đi lặp lại với các phạm vi ngày khác nhau, thì chỉ mục không phân tán thích hợp sẽ tồn tại. Ví dụ:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Với chỉ mục này được tạo, khi truy vấn được thực thi lại, thống kê I / O giảm xuống và kế hoạch thay đổi để sử dụng chỉ mục không phân biệt:
THỐNG KÊ IO ĐẦU RA
Bảng 'Bàn làm việc'. Quét đếm 0, đọc lôgic 0, đọc vật lý 0, đọc trước đọc 0, đọc lôgic 0, đăng nhập vật lý 0, đọc trước lôgic đọc 0.
Bảng 'Big_SalesOrderHeader'. Số lần quét 9, số lần đọc logic 42901, số lần đọc vật lý 3, số lần đọc trước 42346, số lần đọc logic 0, số lần đọc vật lý 0, số lần đọc trước của bài đọc số 0.

Tổng số theo Nhân viên bán hàng cho tháng 12 - NCI trên Bảng không phân vùng
Với một chỉ mục hỗ trợ, truy vấn đối với Sales.Big_SalesOrderHeader yêu cầu ít lần đọc hơn đáng kể so với quét chỉ mục theo nhóm đối với Sales.Part_SalesOrderHeader, điều này không nằm ngoài dự đoán vì chỉ mục được phân cụm rộng hơn nhiều. Nếu chúng tôi tạo chỉ mục không phân biệt có thể so sánh cho Sales.Part_SalesOrderHeader, chúng tôi sẽ thấy các số I / O tương tự:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);THỐNG KÊ IO ĐẦU RA
Bảng 'Part_SalesOrderHeader'. Số lần quét 9, số lần đọc logic 42894, số lần đọc vật lý 1, số lần đọc trước 42378, số lần đọc logic 0, số lần đọc vật lý 0, số lần đọc trước của bài đọc số 0.
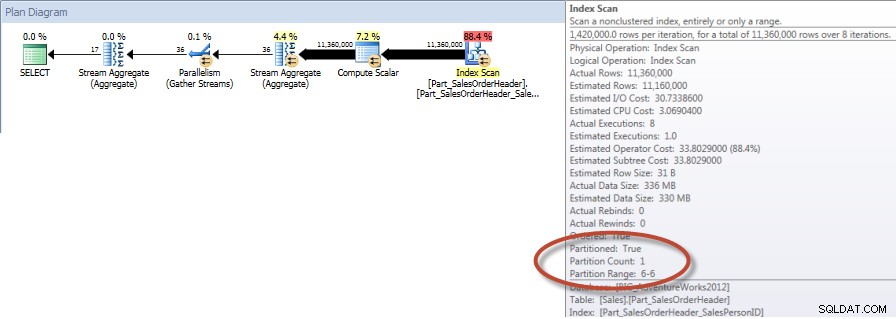
Tổng số theo Nhân viên bán hàng cho tháng 12 - NCI trên Bảng phân vùng có loại bỏ
Và nếu chúng tôi xem xét các thuộc tính của Quét chỉ mục không phân biệt, chúng tôi có thể xác minh rằng công cụ chỉ truy cập một phân vùng (6).
Như đã nêu ban đầu, phân vùng thường không được triển khai để cải thiện hiệu suất. Trong ví dụ được hiển thị ở trên, truy vấn chống lại bảng được phân vùng không hoạt động tốt hơn đáng kể miễn là tồn tại chỉ mục không phân tách thích hợp.
Hiệu suất cho Truy vấn Ad-Hoc
Một truy vấn chống lại bảng được phân vùng can hoạt động tốt hơn truy vấn tương tự so với bảng không được phân vùng trong một số trường hợp, ví dụ:khi truy vấn phải sử dụng chỉ mục được phân nhóm. Mặc dù lý tưởng nhất là có phần lớn các truy vấn được hỗ trợ bởi các chỉ mục không phân biệt, nhưng một số hệ thống cho phép các truy vấn đặc biệt từ người dùng và những hệ thống khác có các truy vấn có thể không thường xuyên nên họ không đảm bảo các chỉ mục hỗ trợ. Đối với bảng SalesOrderHeader, người dùng có thể chạy truy vấn sau để tìm các đơn đặt hàng từ tháng 12 năm 2012 cần giao vào cuối năm nhưng không thực hiện được, đối với một nhóm khách hàng cụ thể và có TotalDue lớn hơn $ 1000:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOTHỐNG KÊ IO ĐẦU RA
Bảng 'Big_SalesOrderHeader'. Số lần quét 9, đọc logic 2711220, đọc vật lý 8386, đọc trước 2662400, đọc logic lob 0, đọc vật lý lob 0, đọc trước lob đọc 0.
Bảng 'Part_SalesOrderHeader'. Quét đếm 9, đọc logic 248128, đọc vật lý 0, đọc trước 243792, đọc logic lob 0, đọc vật lý lob 0, đọc trước lob đọc 0.
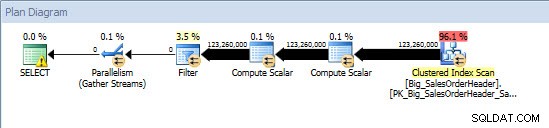
Truy vấn Ad-Hoc - Bảng không phân vùng
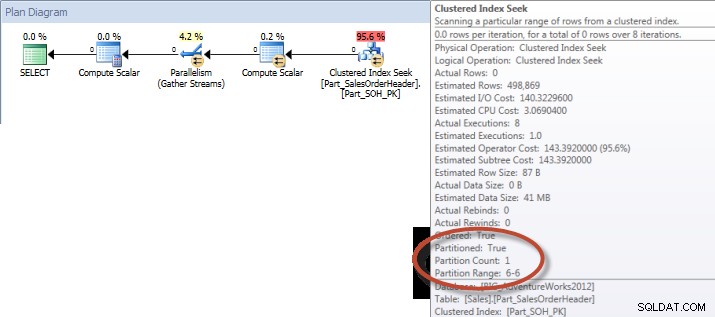
Truy vấn Ad-Hoc - Bảng được phân vùng
Đối với bảng không được phân vùng, truy vấn yêu cầu quét toàn bộ đối với chỉ mục được phân nhóm, nhưng đối với bảng được phân vùng, truy vấn thực hiện tìm kiếm chỉ mục của chỉ mục được phân nhóm, vì công cụ đã sử dụng loại bỏ phân vùng và chỉ đọc dữ liệu mà nó thực sự cần. Trong ví dụ này, đó là sự khác biệt đáng kể về I / O và tùy thuộc vào phần cứng, có thể là sự khác biệt đáng kể về thời gian thực thi. Truy vấn có thể được tối ưu hóa bằng cách thêm chỉ mục thích hợp, nhưng thường không khả thi để lập chỉ mục cho mọi độc thân truy vấn. Đặc biệt, đối với các giải pháp cho phép truy vấn đặc biệt, công bằng mà nói rằng bạn không bao giờ biết người dùng sẽ làm gì. Một truy vấn có thể chạy một lần và không bao giờ chạy lại, và việc tạo chỉ mục sau khi thực tế là vô ích. Do đó, khi thay đổi từ bảng không được phân vùng sang bảng được phân vùng, điều quan trọng là phải áp dụng cùng nỗ lực và cách tiếp cận như điều chỉnh chỉ mục thông thường; bạn muốn xác minh rằng các chỉ mục thích hợp tồn tại để hỗ trợ phần lớn các truy vấn.
Hiệu suất và Căn chỉnh chỉ mục
Một yếu tố bổ sung cần xem xét khi tạo chỉ mục cho bảng được phân vùng là có căn chỉnh chỉ mục hay không. Các chỉ mục phải được căn chỉnh với bảng nếu bạn định chuyển dữ liệu vào và ra khỏi các phân vùng. Tạo chỉ mục không phân biệt trên bảng được phân vùng sẽ tạo chỉ mục được căn chỉnh theo mặc định, trong đó cột phân vùng được thêm dưới dạng cột được bao gồm vào chỉ mục.
Chỉ mục không căn chỉnh được tạo bằng cách chỉ định một lược đồ phân vùng khác hoặc một nhóm tệp khác. Cột phân vùng có thể là một phần của chỉ mục dưới dạng cột chính hoặc cột được bao gồm, nhưng nếu lược đồ phân vùng của bảng không được sử dụng hoặc một nhóm tệp khác được sử dụng, chỉ mục sẽ không được căn chỉnh.
Chỉ mục được căn chỉnh được phân vùng giống như bảng - dữ liệu sẽ tồn tại trong các cấu trúc riêng biệt - và do đó có thể xảy ra loại bỏ phân vùng. Chỉ mục không được đánh dấu tồn tại dưới dạng một cấu trúc vật lý và có thể không cung cấp lợi ích mong đợi cho một truy vấn, tùy thuộc vào vị từ. Hãy xem xét một truy vấn có tính doanh số bán hàng theo số tài khoản, được nhóm theo tháng:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Nếu bạn không quen với việc phân vùng, bạn có thể tạo một chỉ mục như thế này để hỗ trợ truy vấn (lưu ý rằng nhóm tệp CHÍNH được chỉ định):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Chỉ mục này không được căn chỉnh, ngay cả khi nó bao gồm Ngày đặt hàng vì nó là một phần của khóa chính. Các cột cũng được bao gồm nếu chúng tôi tạo chỉ mục được căn chỉnh, nhưng lưu ý sự khác biệt về cú pháp:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Chúng tôi có thể xác minh những cột nào tồn tại trong chỉ mục bằng cách sử dụng sp_helpindex của Kimberly Tripp:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex for Sales.Part_SalesOrderHeader
Khi chúng tôi chạy truy vấn của mình và buộc nó sử dụng chỉ mục không căn chỉnh, toàn bộ chỉ mục sẽ được quét. Mặc dù Ngày đặt hàng là một phần của chỉ mục, nhưng nó không phải là cột đứng đầu vì vậy công cụ phải kiểm tra giá trị Ngày đặt hàng cho mọi Số tài khoản để xem liệu nó có nằm trong khoảng từ ngày 1 tháng 1 năm 2013 đến ngày 31 tháng 7 năm 2013 hay không:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);THỐNG KÊ IO ĐẦU RA
Bảng 'Bàn làm việc'. Quét đếm 0, đọc lôgic 0, đọc vật lý 0, đọc trước đọc 0, lôgic đọc 0, đọc dữ liệu vật lý 0, đọc trước hành động đọc 0.
Bảng 'Part_SalesOrderHeader'. Quét đếm 9, đọc logic 786861, đọc vật lý 1, đọc trước 770929, đọc logic lob 0, đọc vật lý lob 0, đọc trước lob đọc 0.
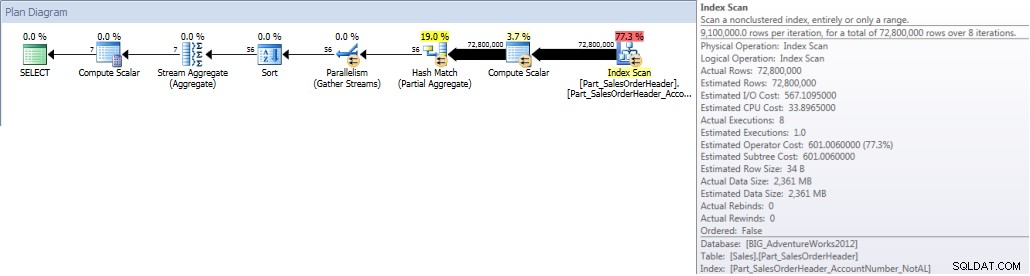
Tổng tài khoản theo tháng (tháng 1 - tháng 7 năm 2013) Sử dụng Non- NCI được căn chỉnh (bắt buộc)
Ngược lại, khi truy vấn buộc phải sử dụng chỉ mục được căn chỉnh, có thể sử dụng loại bỏ phân vùng và yêu cầu ít I / Os hơn, ngay cả khi OrderDate không phải là cột đứng đầu trong chỉ mục.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);THỐNG KÊ IO ĐẦU RA
Bảng 'Bàn làm việc'. Quét đếm 0, đọc lôgic 0, đọc vật lý 0, đọc trước đọc 0, lôgic đọc 0, đọc dữ liệu vật lý 0, đọc trước hành động đọc 0.
Bảng 'Part_SalesOrderHeader'. Quét đếm 9, đọc logic 456258, đọc vật lý 16, đọc trước 453241, đọc logic lob 0, đọc vật lý lob 0, đọc trước lob đọc 0.
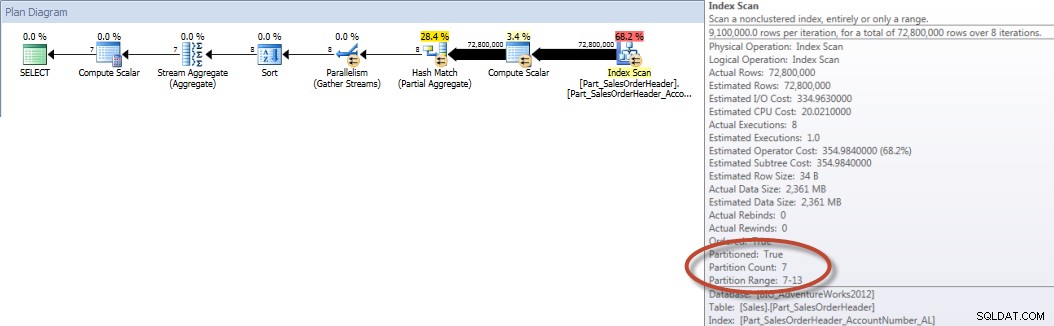
Tổng tài khoản theo tháng (tháng 1 - tháng 7 năm 2013) Sử dụng NCI được căn chỉnh (bắt buộc)
Tóm tắt
Quyết định thực hiện phân vùng là một trong những quyết định cần được cân nhắc và lập kế hoạch thích hợp. Dễ dàng quản lý, cải thiện khả năng mở rộng và tính khả dụng và giảm chặn là những lý do phổ biến để phân vùng bảng. Cải thiện hiệu suất truy vấn không phải là lý do để sử dụng phân vùng, mặc dù nó có thể là một tác dụng phụ có lợi trong một số trường hợp. Về hiệu suất, điều quan trọng là đảm bảo rằng kế hoạch triển khai của bạn bao gồm việc xem xét hiệu suất truy vấn. Xác nhận rằng các chỉ mục của bạn tiếp tục hỗ trợ thích hợp các truy vấn của bạn sau khi bảng được phân vùng và xác minh rằng các truy vấn sử dụng các chỉ mục được phân nhóm và không phân nhóm được hưởng lợi từ việc loại bỏ phân vùng nếu có.