[Phần 1 | Phần 2 | Phần 3]
Trong phần 1 của loạt bài này, tôi đã thử một số cách để nén bảng 1TB. Mặc dù tôi đã đạt được kết quả tốt trong lần thử đầu tiên, nhưng tôi muốn xem liệu tôi có thể cải thiện hiệu suất trong phần 2. Ở đó, tôi đã phác thảo một vài điều tôi nghĩ có thể là các vấn đề về hiệu suất và đặt ra cách tôi sẽ phân vùng bảng đích tốt hơn. để nén columnstore tối ưu. Tôi đã:
- phân vùng bảng thành 8 phân vùng (một phân vùng cho mỗi nhân);
- đặt tệp dữ liệu của mỗi phân vùng vào nhóm tệp riêng của nó; và,
- đặt nén lưu trữ trên tất cả trừ phân vùng "đang hoạt động".
Tôi vẫn cần phải làm cho nó để mỗi bộ lập lịch ghi riêng vào phân vùng riêng của nó.
Trước tiên, tôi cần thực hiện các thay đổi đối với bảng lô mà tôi đã tạo. Tôi cần một cột để lưu trữ số lượng hàng được thêm vào mỗi đợt (loại kiểm tra độ tỉnh táo tự kiểm tra) và thời gian bắt đầu / kết thúc để đo lường tiến độ.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Tiếp theo, tôi cần tạo một bảng để cung cấp mối quan hệ - chúng tôi không bao giờ muốn nhiều hơn một quá trình chạy trên bất kỳ bộ lập lịch nào, ngay cả khi điều đó có nghĩa là mất một khoảng thời gian để thử lại logic. Vì vậy, chúng tôi cần một bảng sẽ theo dõi bất kỳ phiên nào trên một bộ lập lịch cụ thể và ngăn việc xếp chồng:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Ý tưởng là tôi sẽ có tám phiên bản của một ứng dụng (SQLQueryS Stress) mà mỗi phiên bản sẽ chạy trên một bộ lập lịch chuyên dụng, chỉ xử lý dữ liệu dành cho một phân vùng / nhóm tệp / tệp dữ liệu cụ thể, ~ 100 triệu hàng cùng một lúc (nhấp để phóng to) :
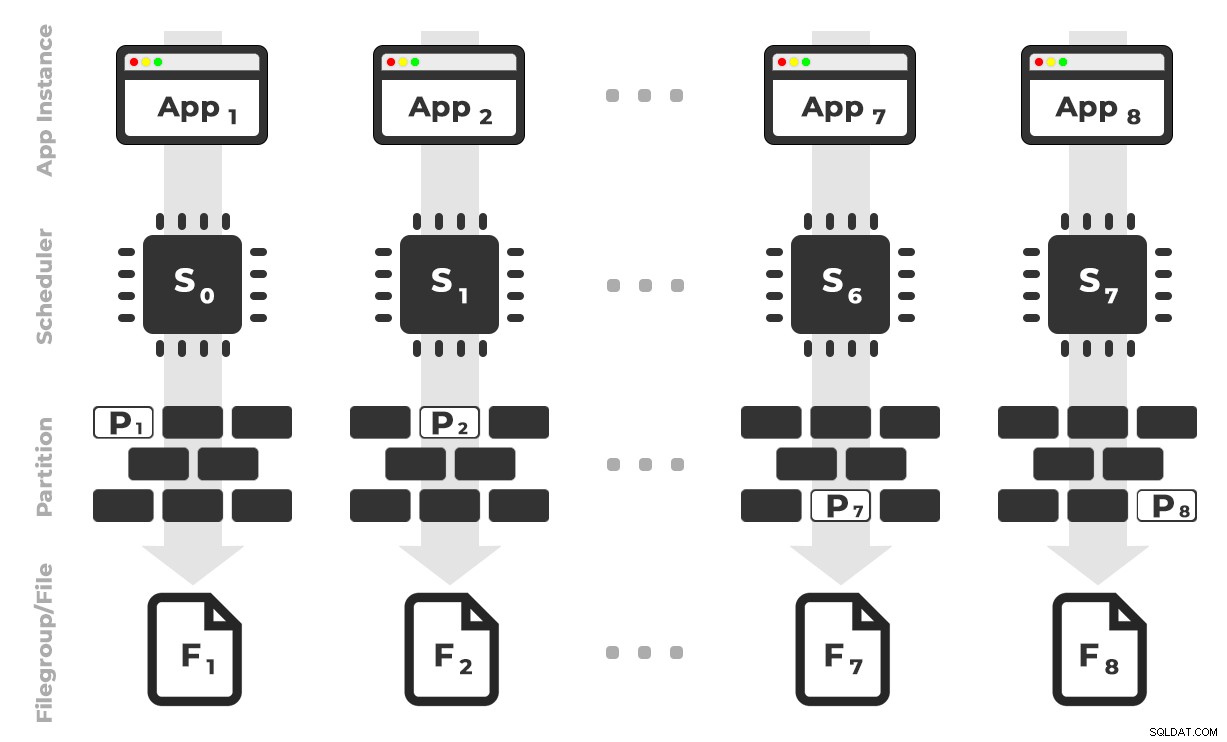 Ứng dụng 1 nhận bộ lập lịch 0 và ghi vào phân vùng 1 trên nhóm tệp 1, v.v. …
Ứng dụng 1 nhận bộ lập lịch 0 và ghi vào phân vùng 1 trên nhóm tệp 1, v.v. …
Tiếp theo, chúng ta cần một thủ tục được lưu trữ sẽ cho phép mỗi phiên bản của ứng dụng dự trữ thời gian trên một bộ lập lịch duy nhất. Như tôi đã đề cập trong một bài viết trước, đây không phải là ý tưởng ban đầu của tôi (và tôi sẽ không bao giờ tìm thấy nó trong hướng dẫn đó nếu không có Joe Obbish). Đây là quy trình tôi đã tạo trong Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Đơn giản, phải không? Kích hoạt 8 phiên bản SQLQueryS Stress và đưa lô này vào từng phiên bản:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
 Sự song hành của người đàn ông đáng thương
Sự song hành của người đàn ông đáng thương
Ngoại trừ nó không đơn giản như vậy, vì việc phân công người lập lịch giống như một hộp sôcôla. Phải mất nhiều lần thử để đưa từng phiên bản của ứng dụng vào bộ lập lịch dự kiến; Tôi sẽ kiểm tra các ngoại lệ trên bất kỳ phiên bản nhất định nào của ứng dụng và thay đổi PartitionID khớp. Đây là lý do tại sao tôi sử dụng nhiều hơn một lần lặp (nhưng tôi vẫn chỉ muốn một luồng cho mỗi trường hợp). Ví dụ:phiên bản này của ứng dụng được mong đợi ở trên bộ lập lịch 3, nhưng nó lại có bộ lập lịch 4:
 Nếu lúc đầu bạn không thành công…
Nếu lúc đầu bạn không thành công…
Tôi đã thay đổi 3s trong cửa sổ truy vấn thành 4s và thử lại. Nếu tôi nhanh trí, bài tập của người lập lịch đã đủ "dính" để nó nhận ngay và bắt đầu làm việc ngay. Nhưng tôi không phải lúc nào cũng đủ nhanh, vì vậy việc bắt đầu giống như một cái chết. Tôi có thể đã nghĩ ra một thói quen thử lại / lặp lại tốt hơn để làm cho công việc ít thủ công hơn ở đây và rút ngắn độ trễ để tôi biết ngay nó có hoạt động hay không, nhưng điều này đủ tốt cho nhu cầu của tôi. Một lời khuyên khác từ ông Obbish.
Giám sát
Trong khi bản sao có liên quan đang chạy, tôi có thể nhận được gợi ý về trạng thái hiện tại bằng hai truy vấn sau:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Nếu tôi làm đúng mọi thứ, cả hai truy vấn sẽ trả về 8 hàng và hiển thị thời lượng và số lần đọc logic tăng dần. Các kiểu chờ sẽ thay đổi giữa PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD và thỉnh thoảng RESERVED_MEMORY_ALLOCATION_EXT. Khi một lô kết thúc (tôi có thể xem lại những điều này bằng cách bỏ ghi chú -- AND EndTime IS NULL , Tôi sẽ xác nhận rằng RowsAdded = RowsInRange .
Sau khi hoàn thành tất cả 8 phiên bản SQLQueryS Stress, tôi chỉ có thể thực hiện SELECT INTO <newtable> FROM dbo.BatchQueue để ghi lại kết quả cuối cùng để phân tích sau này.
Thử nghiệm khác
Ngoài việc sao chép dữ liệu vào chỉ mục columnstore được phân nhóm được phân vùng đã tồn tại, bằng cách sử dụng mối quan hệ, tôi cũng muốn thử một số cách khác:
- Sao chép dữ liệu vào bảng mới mà không cố gắng kiểm soát mối quan hệ. Tôi đã loại bỏ logic mối quan hệ ra khỏi quy trình và chỉ để lại toàn bộ thứ "hy vọng-bạn-nhận-đúng-lịch-trình" cho cơ hội. Quá trình này mất nhiều thời gian hơn vì chắc chắn, việc xếp chồng lên lịch đã làm xảy ra. Ví dụ:tại thời điểm cụ thể này, bộ lập lịch 3 đang chạy hai quá trình, trong khi bộ lập lịch 0 đang nghỉ trưa:
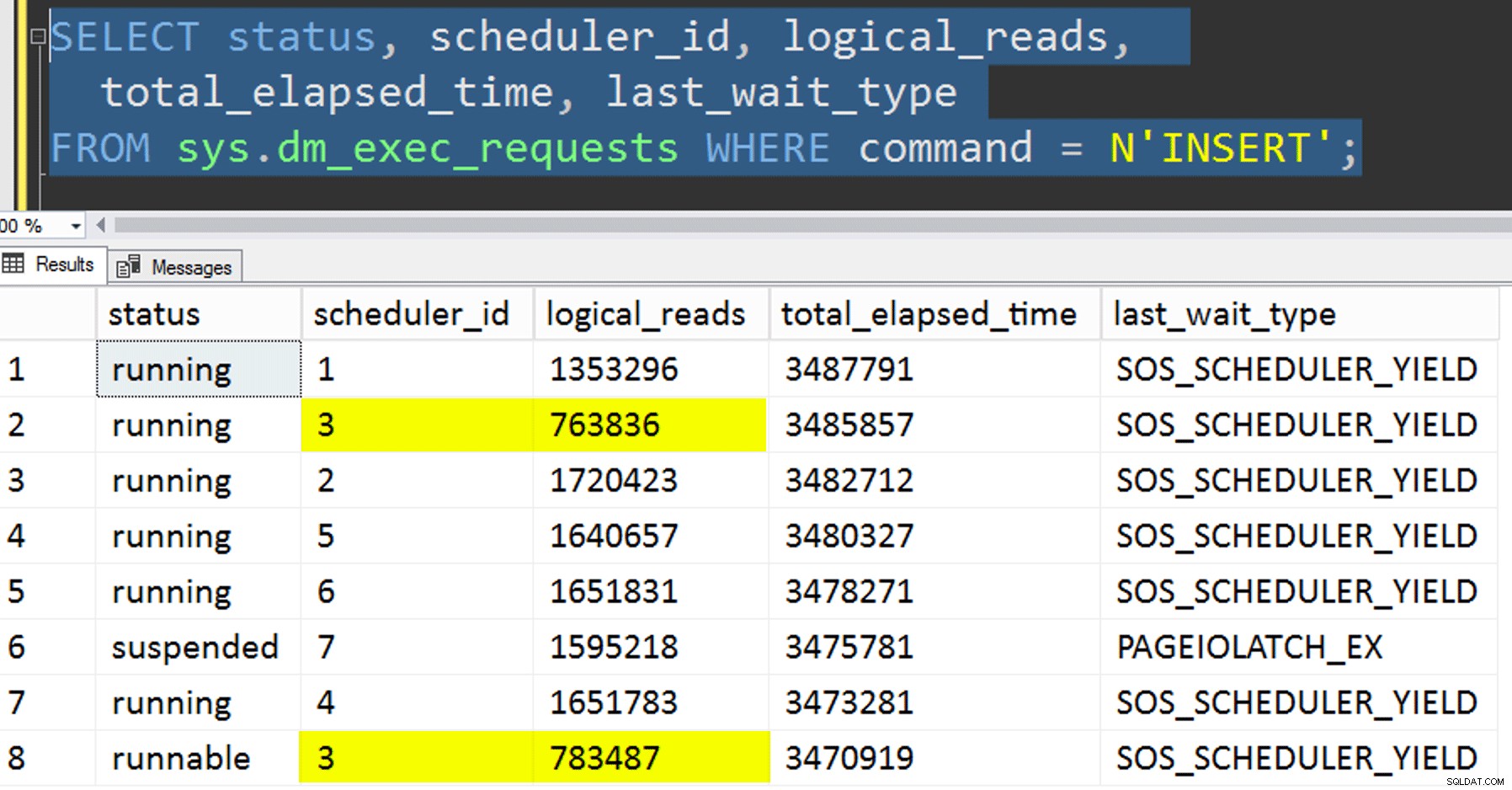 Bạn thuộc nghệ thuật nào, bộ lập lịch số 0?
Bạn thuộc nghệ thuật nào, bộ lập lịch số 0? - Đang áp dụng trang hoặc hàng nén (cả trực tuyến / ngoại tuyến) vào nguồn trước đó bản sao có liên kết (ngoại tuyến), để xem liệu nén dữ liệu trước có thể tăng tốc đích hay không. Lưu ý rằng việc sao chép cũng có thể được thực hiện trực tuyến nhưng, như
intcủa Andy Mallon thànhbigintchuyển đổi, nó đòi hỏi một số môn thể dục dụng cụ. Lưu ý rằng trong trường hợp này, chúng tôi không thể tận dụng mối quan hệ của CPU (mặc dù chúng tôi có thể nếu bảng nguồn đã được phân vùng). Tôi đã rất thông minh và đã sao lưu nguồn gốc và tạo một thủ tục để hoàn nguyên cơ sở dữ liệu về trạng thái ban đầu. Nhanh hơn và dễ dàng hơn nhiều so với việc cố gắng hoàn nguyên về một trạng thái cụ thể theo cách thủ công.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- Và cuối cùng, trước tiên, xây dựng lại chỉ mục được phân cụm trên lược đồ phân vùng, sau đó xây dựng chỉ mục phân nhóm theo nhóm trên đó. Nhược điểm của điều sau là, trong SQL Server 2017, bạn không thể chạy điều này trực tuyến… nhưng bạn sẽ có thể vào năm 2019.
Ở đây chúng ta cần loại bỏ ràng buộc PK trước tiên; bạn không thể sử dụng
Msg 1907, Cấp 16, Trạng thái 1DROP_EXISTING, vì ràng buộc duy nhất ban đầu không thể được thực thi bởi chỉ mục nhóm cột được nhóm và bạn không thể thay thế một chỉ mục được phân nhóm duy nhất bằng một chỉ mục được phân nhóm không phải là duy nhất.
Không thể tạo lại chỉ mục 'pk_tblOriginal'. Định nghĩa chỉ mục mới không khớp với ràng buộc đang được thực thi bởi chỉ mục hiện có.Tất cả những chi tiết này làm cho đây là một quy trình ba bước, chỉ là bước thứ hai trực tuyến. Bước đầu tiên tôi chỉ kiểm tra rõ ràng
OFFLINE; chạy trong ba phút, trong khiONLINETôi dừng lại sau 15 phút. Một trong những điều đó có lẽ không nên là phép toán quy mô dữ liệu trong cả hai trường hợp, nhưng tôi sẽ để điều đó vào một ngày khác.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Kết quả
Thời gian và tốc độ nén:
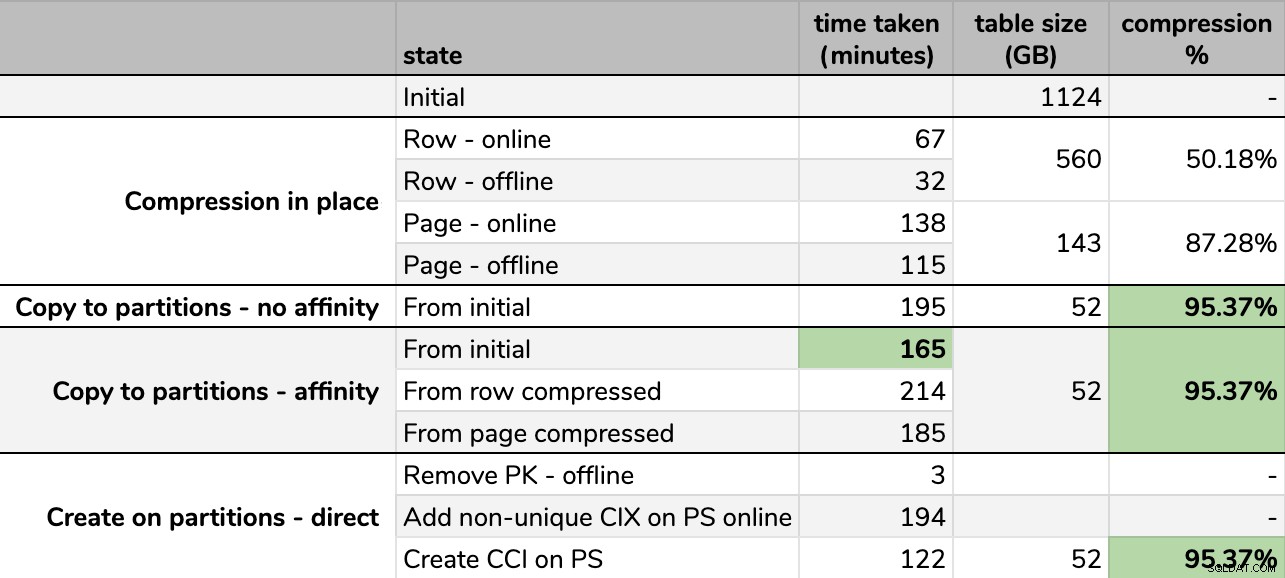 Một số tùy chọn tốt hơn các tùy chọn khác
Một số tùy chọn tốt hơn các tùy chọn khác
Lưu ý rằng tôi đã làm tròn thành GB vì sẽ có sự khác biệt nhỏ về kích thước cuối cùng sau mỗi lần chạy, ngay cả khi sử dụng cùng một kỹ thuật. Ngoài ra, thời gian cho các phương pháp mối quan hệ dựa trên trung bình bộ lập lịch riêng lẻ / thời gian chạy hàng loạt, vì một số bộ lập lịch hoàn thành nhanh hơn những bộ khác.
Thật khó để hình dung một bức tranh chính xác từ bảng tính như được hiển thị, vì một số tác vụ có các yếu tố phụ thuộc, vì vậy tôi sẽ cố gắng hiển thị thông tin dưới dạng dòng thời gian và hiển thị mức độ nén bạn nhận được so với thời gian đã sử dụng:
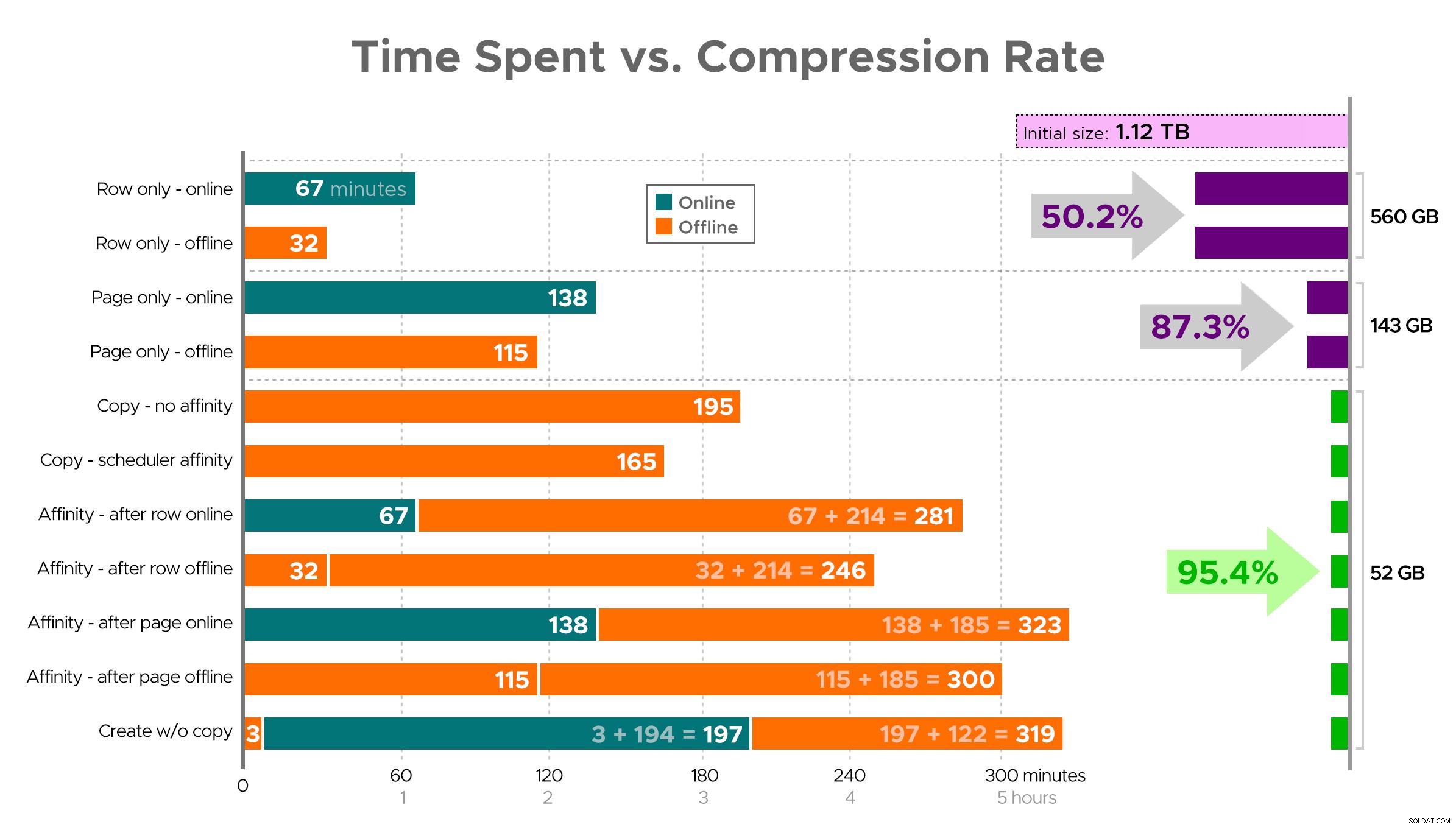 Thời gian sử dụng (phút) so với tốc độ nén
Thời gian sử dụng (phút) so với tốc độ nén
Một vài nhận xét từ kết quả, với cảnh báo rằng dữ liệu của bạn có thể nén theo cách khác (và các hoạt động trực tuyến chỉ áp dụng cho bạn nếu bạn sử dụng Enterprise Edition):
- Nếu ưu tiên của bạn là tiết kiệm dung lượng càng nhanh càng tốt , đặt cược tốt nhất của bạn là áp dụng nén hàng tại chỗ. Nếu bạn muốn giảm thiểu sự gián đoạn, hãy sử dụng trực tuyến; nếu bạn muốn tối ưu hóa tốc độ, hãy sử dụng ngoại tuyến.
- Nếu bạn muốn tối đa hóa khả năng nén mà không bị gián đoạn , bạn có thể giảm 90% dung lượng lưu trữ mà không gặp bất kỳ gián đoạn nào, bằng cách sử dụng tính năng nén trang trực tuyến.
- Nếu bạn muốn tối đa hóa khả năng nén và không bị gián đoạn , sao chép dữ liệu sang một phiên bản mới, được phân vùng của bảng, với chỉ mục chuỗi cột được phân cụm và sử dụng quy trình quan hệ được mô tả ở trên để di chuyển dữ liệu. (Và một lần nữa, bạn có thể loại bỏ sự gián đoạn này nếu bạn là người lập kế hoạch tốt hơn tôi.)
Tùy chọn cuối cùng hoạt động tốt nhất cho kịch bản của tôi, mặc dù chúng tôi sẽ vẫn phải thúc đẩy khối lượng công việc (vâng, số nhiều). Cũng xin lưu ý rằng trong SQL Server 2019, kỹ thuật này có thể không hoạt động tốt, nhưng bạn có thể xây dựng các chỉ mục columnstore theo cụm trực tuyến ở đó, vì vậy nó có thể không quan trọng lắm.
Một số cách tiếp cận này ít nhiều có thể được bạn chấp nhận, bởi vì bạn có thể ưu tiên "duy trì trạng thái sẵn sàng" hơn là "hoàn thiện càng nhanh càng tốt" hoặc "giảm thiểu việc sử dụng đĩa" so với "duy trì khả dụng" hoặc chỉ cân bằng hiệu suất đọc và ghi chi phí .
Nếu bạn muốn biết thêm chi tiết về bất kỳ khía cạnh nào của vấn đề này, chỉ cần hỏi. Tôi đã cắt bớt một số chất béo để cân bằng chi tiết với khả năng tiêu hóa, và tôi đã sai về sự cân bằng đó trước đây. Một suy nghĩ chia tay là tôi tò mò xem nó tuyến tính như thế nào - chúng ta có một bảng khác có cấu trúc tương tự có dung lượng hơn 25 TB và tôi tò mò liệu chúng ta có thể tạo ra một số tác động tương tự ở đó hay không. Cho đến lúc đó, chúc bạn vui vẻ nén!
[Phần 1 | Phần 2 | Phần 3]