Chào mừng bạn đến với phần thứ ba - và cuối cùng - của loạt blog này, khám phá cách hiệu suất PostgreSQL phát triển trong những năm qua. Phần đầu tiên xem xét khối lượng công việc OLTP, được thể hiện bằng các bài kiểm tra pgbench. Phần thứ hai xem xét các truy vấn phân tích / BI, sử dụng một tập hợp con của điểm chuẩn TPC-H truyền thống (về cơ bản là một phần của bài kiểm tra công suất).
Và phần cuối cùng này xem xét tìm kiếm toàn văn bản, tức là khả năng lập chỉ mục và tìm kiếm với lượng lớn dữ liệu văn bản. Cơ sở hạ tầng giống nhau (đặc biệt là các chỉ mục) có thể hữu ích cho việc lập chỉ mục dữ liệu bán cấu trúc như tài liệu JSONB, v.v. nhưng đó không phải là điều mà điểm chuẩn này tập trung vào.
Nhưng trước tiên, hãy xem lịch sử tìm kiếm toàn văn trong PostgreSQL, có vẻ như là một tính năng kỳ lạ để thêm vào RDBMS, theo truyền thống nhằm mục đích lưu trữ dữ liệu có cấu trúc trong các hàng và cột.
Lịch sử tìm kiếm toàn văn
Khi Postgres có nguồn mở vào năm 1996, nó không có bất cứ thứ gì mà chúng ta có thể gọi là tìm kiếm toàn văn. Nhưng những người bắt đầu sử dụng Postgres muốn thực hiện các tìm kiếm thông minh trong tài liệu văn bản và các truy vấn LIKE là không đủ tốt. Họ muốn có thể giải thích các thuật ngữ bằng cách sử dụng từ điển, bỏ qua các từ dừng, sắp xếp các tài liệu phù hợp theo mức độ liên quan, sử dụng các chỉ mục để thực hiện các truy vấn đó và nhiều thứ khác. Những điều bạn không thể làm một cách hợp lý với các toán tử SQL truyền thống.
May mắn thay, một số người trong số đó cũng là nhà phát triển nên họ đã bắt đầu làm việc này - và họ có thể làm được điều này nhờ PostgreSQL có sẵn dưới dạng mã nguồn mở trên toàn thế giới. Đã có rất nhiều người đóng góp cho việc tìm kiếm toàn văn trong những năm qua, nhưng ban đầu nỗ lực này được dẫn đầu bởi Oleg Bartunov và Teodor Sigaev, được thể hiện trong bức ảnh sau đây. Cả hai vẫn là những người đóng góp lớn cho PostgreSQL, làm việc trên tìm kiếm toàn văn bản, lập chỉ mục, hỗ trợ JSON và nhiều tính năng khác.

Teodor Sigaev và Oleg Bartunov
Ban đầu, chức năng này được phát triển như một mô-đun “đóng góp” bên ngoài (ngày nay chúng ta thường nói đó là một phần mở rộng) có tên là “tsearch”, được phát hành vào năm 2002. Sau đó, tính năng này đã được tsearch2 cải thiện đáng kể theo nhiều cách và trong PostgreSQL 8.3 (phát hành vào năm 2008) điều này đã được tích hợp hoàn toàn vào lõi PostgreSQL (tức là không cần cài đặt bất kỳ tiện ích mở rộng nào, mặc dù các tiện ích mở rộng này vẫn được cung cấp để tương thích ngược).
Đã có nhiều cải tiến kể từ đó (và công việc vẫn tiếp tục, ví dụ:hỗ trợ các loại dữ liệu như JSONB, truy vấn bằng jsonpath, v.v.). nhưng các plugin này đã giới thiệu hầu hết các chức năng toàn văn mà chúng ta có trong PostgreSQL hiện nay - từ điển, khả năng lập chỉ mục và truy vấn toàn văn bản, v.v.
Điểm chuẩn
Không giống như điểm chuẩn OLTP / TPC-H, tôi không biết bất kỳ điểm chuẩn toàn văn nào có thể được coi là "tiêu chuẩn ngành" hoặc được thiết kế cho nhiều hệ thống cơ sở dữ liệu. Hầu hết các điểm chuẩn mà tôi biết đều được sử dụng với một cơ sở dữ liệu / sản phẩm duy nhất và thật khó để chuyển chúng một cách có ý nghĩa, vì vậy tôi phải đi theo một lộ trình khác và viết điểm chuẩn toàn văn của riêng mình.
Cách đây nhiều năm, tôi đã viết archie - một vài tập lệnh python cho phép tải xuống các kho lưu trữ danh sách gửi thư PostgreSQL và tải các thư đã phân tích cú pháp vào cơ sở dữ liệu PostgreSQL mà sau đó có thể được lập chỉ mục và tìm kiếm. Ảnh chụp nhanh hiện tại của tất cả các kho lưu trữ có ~ 1 triệu hàng và sau khi tải nó vào cơ sở dữ liệu, bảng có dung lượng khoảng 9,5 GB (không tính chỉ mục).
Đối với các truy vấn, tôi có thể tạo một số truy vấn ngẫu nhiên, nhưng tôi không chắc điều đó sẽ thực tế đến mức nào. May mắn thay, một vài năm trước, tôi đã có được một mẫu gồm 33 nghìn lượt tìm kiếm thực tế từ trang web PostgreSQL (tức là những thứ mà mọi người thực sự tìm kiếm trong kho lưu trữ của cộng đồng). Không chắc tôi có thể nhận được bất cứ điều gì thực tế / đại diện hơn.
Sự kết hợp của hai phần đó (tập dữ liệu + truy vấn) có vẻ như là một chuẩn mực tốt. Chúng tôi có thể chỉ cần tải dữ liệu và chạy các tìm kiếm với các loại truy vấn toàn văn khác nhau với các loại chỉ mục khác nhau.
Truy vấn
Có nhiều dạng truy vấn toàn văn bản khác nhau - truy vấn có thể chỉ cần chọn tất cả các hàng phù hợp, nó có thể xếp hạng kết quả (sắp xếp chúng theo mức độ liên quan), chỉ trả lại một số nhỏ hoặc kết quả phù hợp nhất, v.v. Tôi đã chạy điểm chuẩn với nhiều các loại truy vấn, nhưng trong bài đăng này, tôi sẽ trình bày kết quả cho hai truy vấn đơn giản mà tôi nghĩ đại diện cho hành vi tổng thể khá độc đáo.
- CHỌN id, chủ đề TỪ tin nhắn WHERE body_tsvector @@ $ 1
- CHỌN id, chủ đề TỪ tin nhắn TẠI ĐÂY body_tsvector @@ $ 1
ĐẶT HÀNG BẰNG ts_rank (body_tsvector, $ 1) MÔ TẢ GIỚI HẠN 100
Truy vấn đầu tiên chỉ trả về tất cả các hàng phù hợp, trong khi truy vấn thứ hai trả về 100 kết quả phù hợp nhất (đây là thứ mà bạn có thể sẽ sử dụng cho các tìm kiếm của người dùng).
Tôi đã thử nghiệm với nhiều loại truy vấn khác, nhưng cuối cùng tất cả chúng đều hoạt động theo cách tương tự như một trong hai loại truy vấn này.
Chỉ mục
Mỗi thư có hai phần chính mà chúng ta có thể tìm kiếm - chủ đề và nội dung. Mỗi người trong số họ có một cột tsvector riêng biệt và được lập chỉ mục riêng. Các chủ đề thông báo ngắn hơn nhiều so với nội dung, vì vậy các chỉ mục sẽ nhỏ hơn một cách tự nhiên.
PostgreSQL có hai loại chỉ mục hữu ích cho tìm kiếm toàn văn bản - GIN và GiST. Sự khác biệt chính được giải thích trong tài liệu, nhưng trong ngắn hạn:
- Chỉ mục GIN tìm kiếm nhanh hơn
- Chỉ mục GiST bị mất, tức là yêu cầu kiểm tra lại trong quá trình tìm kiếm (và vì vậy sẽ chậm hơn)
Chúng tôi từng tuyên bố rằng chỉ mục GiST rẻ hơn để cập nhật (đặc biệt là với nhiều phiên đồng thời), nhưng điều này đã bị xóa khỏi tài liệu một thời gian trước, do những cải tiến trong mã lập chỉ mục.
Điểm chuẩn này không kiểm tra hành vi với các bản cập nhật - nó chỉ tải bảng mà không có chỉ mục toàn văn, xây dựng chúng trong một lần và sau đó thực hiện 33k truy vấn trên dữ liệu. Điều đó có nghĩa là tôi không thể đưa ra bất kỳ tuyên bố nào về cách các loại chỉ mục đó xử lý các cập nhật đồng thời dựa trên điểm chuẩn này, nhưng tôi tin rằng các thay đổi trong tài liệu phản ánh nhiều cải tiến GIN gần đây.
Điều này cũng khá phù hợp với trường hợp sử dụng của kho lưu trữ danh sách gửi thư, nơi chúng tôi chỉ chắp thêm các email mới một lần (một vài bản cập nhật, hầu như không viết đồng thời). Nhưng nếu ứng dụng của bạn thực hiện nhiều cập nhật đồng thời, bạn sẽ cần phải tự đánh giá tiêu chuẩn đó.
Phần cứng
Tôi đã làm điểm chuẩn trên hai máy giống nhau như trước đây, nhưng kết quả / kết luận gần giống nhau, vì vậy tôi sẽ chỉ trình bày các con số từ máy nhỏ hơn, tức là
- CPU i5-2500K (4 lõi / luồng)
- RAM 8GB
- 6 x 100GB SSD RAID0
- kernel 5.6.15, hệ thống tệp ext4
Trước đây tôi đã đề cập đến tập dữ liệu có gần 10GB khi tải, vì vậy nó lớn hơn RAM. Nhưng các chỉ số vẫn nhỏ hơn RAM, đó là điều quan trọng đối với điểm chuẩn.
Kết quả
Được rồi, đã đến lúc cho một số con số và biểu đồ. Tôi sẽ trình bày kết quả cho cả tải và truy vấn dữ liệu, trước tiên với GIN và sau đó với chỉ mục GiST.
GIN / tải dữ liệu
Tôi nghĩ rằng tải không phải là đặc biệt thú vị. Thứ nhất, hầu hết nó (phần màu xanh) không liên quan gì đến toàn văn, bởi vì nó xảy ra trước khi hai chỉ mục được tạo. Phần lớn thời gian này được dành để phân tích cú pháp thư, xây dựng lại chuỗi thư, duy trì danh sách thư trả lời, v.v. Một số mã này được triển khai trong các trình kích hoạt PL / pgSQL, một số được triển khai bên ngoài cơ sở dữ liệu. Một phần có khả năng liên quan đến toàn văn là xây dựng tsvectors, nhưng không thể tách biệt thời gian dành cho việc đó.
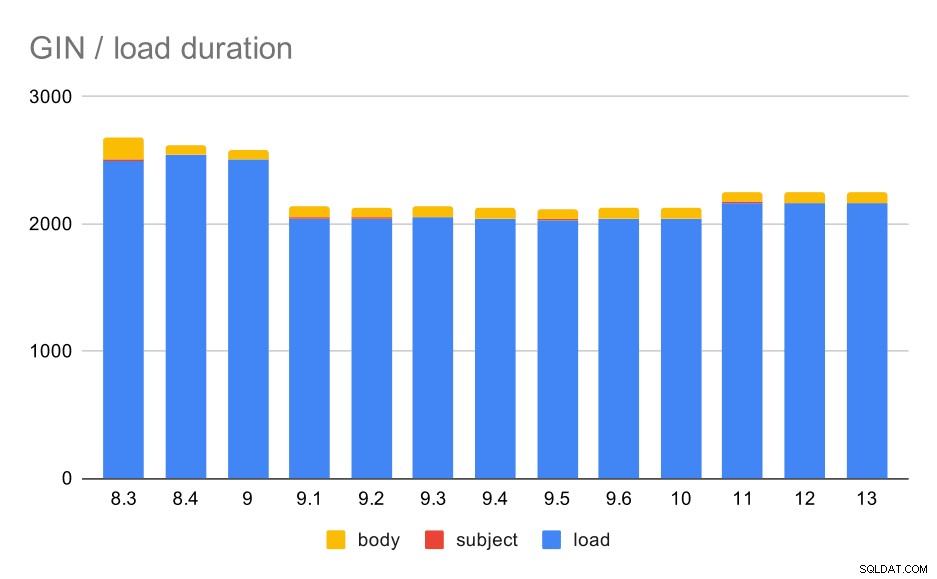
Hoạt động tải dữ liệu với bảng và các chỉ mục GIN.
Bảng sau đây hiển thị dữ liệu nguồn cho biểu đồ này - các giá trị là thời lượng tính bằng giây. LOAD bao gồm phân tích cú pháp các kho lưu trữ mbox (từ một tập lệnh Python), chèn vào một bảng và các tác vụ bổ sung khác nhau (xây dựng lại chuỗi e-mail, v.v.). CHỈ SỐ SUBJECT / BODY đề cập đến việc tạo chỉ mục GIN toàn văn trên các cột chủ đề / nội dung sau khi dữ liệu được tải.
| TẢI | SUBJECT INDEX | CHỈ SỐ CƠ THỂ | |
| 8,3 | 2501 | 8 | 173 |
| 8,4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9,6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Rõ ràng, hiệu suất khá ổn định - đã có một sự cải thiện khá đáng kể (khoảng 20%) giữa 9.0 và 9.1. Tôi không chắc thay đổi nào có thể chịu trách nhiệm cho sự cải tiến này - không có nội dung nào trong ghi chú phát hành 9.1 có vẻ liên quan rõ ràng. Cũng có một sự cải thiện rõ ràng trong việc xây dựng các chỉ số GIN trong 8.4, giúp giảm một nửa thời gian. Đó là tốt, tất nhiên. Thật thú vị, tôi cũng không thấy bất kỳ mục ghi chú phát hành nào có liên quan rõ ràng cho việc này.
Còn về kích thước của các chỉ mục GIN thì sao? Có nhiều sự thay đổi hơn, ít nhất là cho đến ngày 9.4, tại thời điểm đó, kích thước của các chỉ mục giảm từ ~ 1GB xuống chỉ còn khoảng 670MB (khoảng 30%).
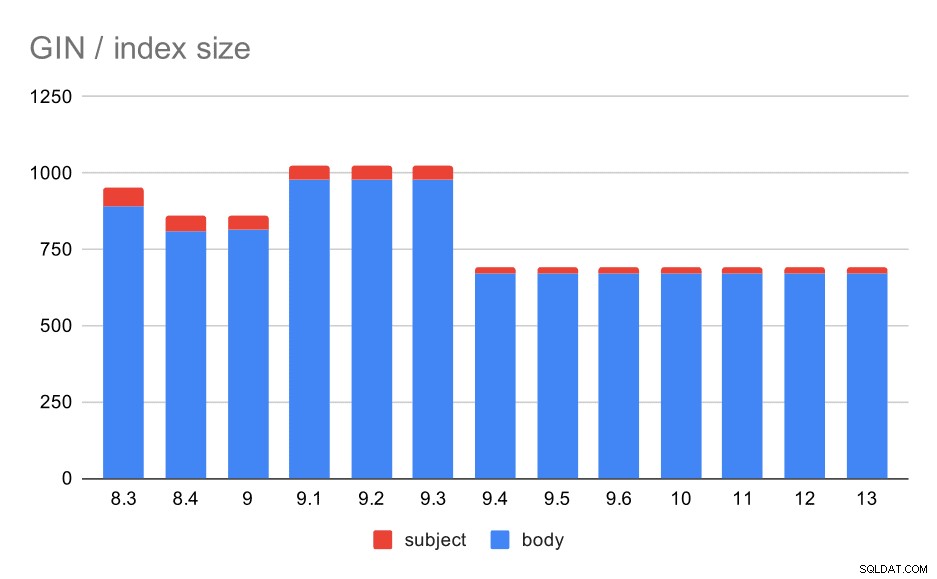
Kích thước của các chỉ mục GIN trên chủ đề / nội dung thư. Giá trị là megabyte.
Bảng sau đây cho thấy kích thước của các chỉ mục GIN trên nội dung thư và chủ đề. Các giá trị tính bằng megabyte.
| CƠ THỂ | SUBJECT | |
| 8.3 | 890 | 62 |
| 8,4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9,6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
Trong trường hợp này, tôi nghĩ chúng ta có thể yên tâm cho rằng việc tăng tốc này có liên quan đến mục này trong ghi chú phát hành 9.4:
- Giảm kích thước chỉ mục GIN (Alexander Korotkov, Heikki Linnakangas)
Sự thay đổi kích thước giữa 8,3 và 9,1 dường như là do những thay đổi trong sự thỏa mãn (cách các từ được chuyển sang dạng "cơ bản"). Ví dụ:ngoài sự khác biệt về kích thước, các truy vấn trên các phiên bản đó trả về số lượng kết quả hơi khác nhau.
GIN / truy vấn
Bây giờ, phần chính của điểm chuẩn này - hiệu suất truy vấn. Tất cả các con số được trình bày ở đây là dành cho một ứng dụng khách - chúng ta đã thảo luận về khả năng mở rộng của ứng dụng khách trong phần liên quan đến hiệu suất OLTP, các phát hiện cũng áp dụng cho các truy vấn này. (Hơn nữa, chiếc máy cụ thể này chỉ có 4 lõi, vì vậy dù sao thì chúng tôi cũng sẽ không tiến xa lắm về mặt kiểm tra khả năng mở rộng.)
CHỌN id, chủ đề TỪ tin nhắn WHERE tsvector @@ $ 1
Đầu tiên, truy vấn tìm kiếm tất cả các tài liệu phù hợp. Đối với các tìm kiếm trong cột "chủ đề", chúng tôi có thể thực hiện khoảng 800 truy vấn mỗi giây (và nó thực sự giảm một chút trong 9.1), nhưng trong 9.4, nó đột nhiên hiển thị tới 3000 truy vấn mỗi giây. Đối với cột “nội dung”, về cơ bản, cùng một câu chuyện - ban đầu là 160 truy vấn, giảm xuống còn ~ 90 truy vấn trong 9.1 và sau đó tăng lên 300 trong 9.4.
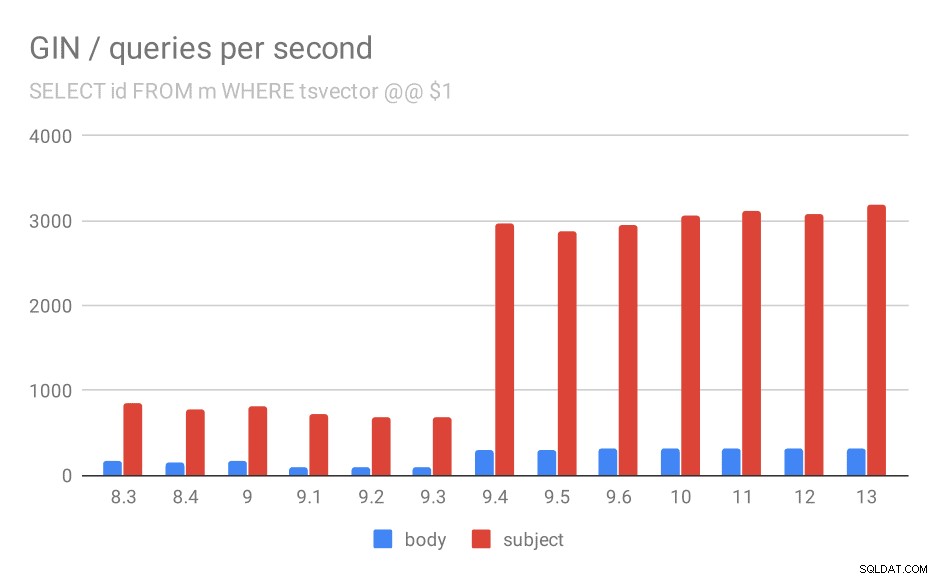
Số lượng truy vấn mỗi giây cho truy vấn đầu tiên (tìm nạp tất cả các hàng phù hợp).
Và một lần nữa, dữ liệu nguồn - các con số là thông lượng (truy vấn mỗi giây).
| CƠ THỂ | SUBJECT | |
| 8.3 | 168 | 848 |
| 8,4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9,6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Tôi nghĩ rằng chúng ta có thể yên tâm giả định rằng cải tiến trong 9.4 có liên quan đến mặt hàng này trong ghi chú phát hành:
- Cải thiện tốc độ tra cứu GIN đa khóa (Alexander Korotkov, Heikki Linnakangas)
Vì vậy, một cải tiến 9,4 khác trong GIN từ hai nhà phát triển giống nhau - rõ ràng, Alexander và Heikki đã làm rất tốt các chỉ số GIN trong bản phát hành 9,4 😉
CHỌN id, chủ đề TỪ tin nhắn TẠI ĐÓ tsvector @@ $ 1
ĐẶT HÀNG BỞI ts_rank (tsvector, $ 2) MÔ TẢ GIỚI HẠN 100
Đối với truy vấn xếp hạng kết quả theo mức độ liên quan bằng cách sử dụng ts_rank và LIMIT, hành vi tổng thể gần như hoàn toàn giống nhau, tôi nghĩ không cần phải mô tả biểu đồ chi tiết.
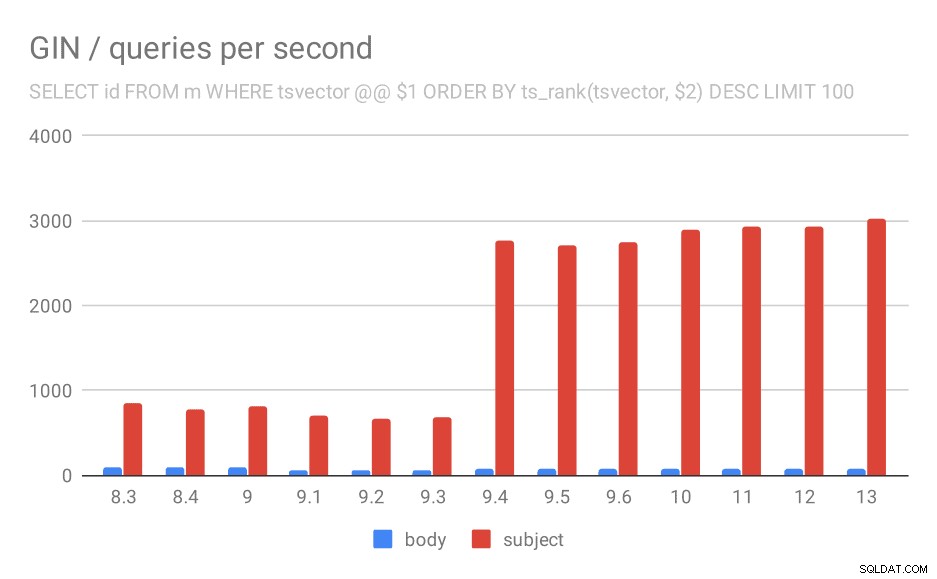
Số lượng truy vấn mỗi giây cho truy vấn thứ hai (tìm nạp các hàng có liên quan nhất).
| CƠ THỂ | SUBJECT | |
| 8.3 | 94 | 840 |
| 8,4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9,6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Tuy nhiên, có một câu hỏi - tại sao hiệu suất lại giảm từ 9,0 đến 9,1? Dường như có một sự sụt giảm khá lớn về thông lượng - khoảng 50% đối với các tìm kiếm cơ thể và 20% đối với các tìm kiếm trong các chủ đề tin nhắn. Tôi không giải thích rõ ràng chuyện gì đã xảy ra, nhưng tôi có hai nhận xét…
Thứ nhất, kích thước chỉ mục đã thay đổi - nếu bạn nhìn vào biểu đồ đầu tiên “GIN / kích thước chỉ mục” và bảng, bạn sẽ thấy chỉ mục trên nội dung thư đã tăng từ 813MB lên khoảng 977MB. Đó là một sự gia tăng đáng kể và nó có thể giải thích một số sự chậm lại. Tuy nhiên, vấn đề là chỉ mục trên các đối tượng đã không tăng lên chút nào, nhưng các truy vấn cũng chậm hơn.
Thứ hai, chúng ta có thể xem có bao nhiêu kết quả mà các truy vấn trả về. Tập dữ liệu được lập chỉ mục hoàn toàn giống nhau, vì vậy có vẻ hợp lý khi mong đợi cùng một số kết quả trong tất cả các phiên bản PostgreSQL, phải không? Chà, trên thực tế, nó trông như thế này:
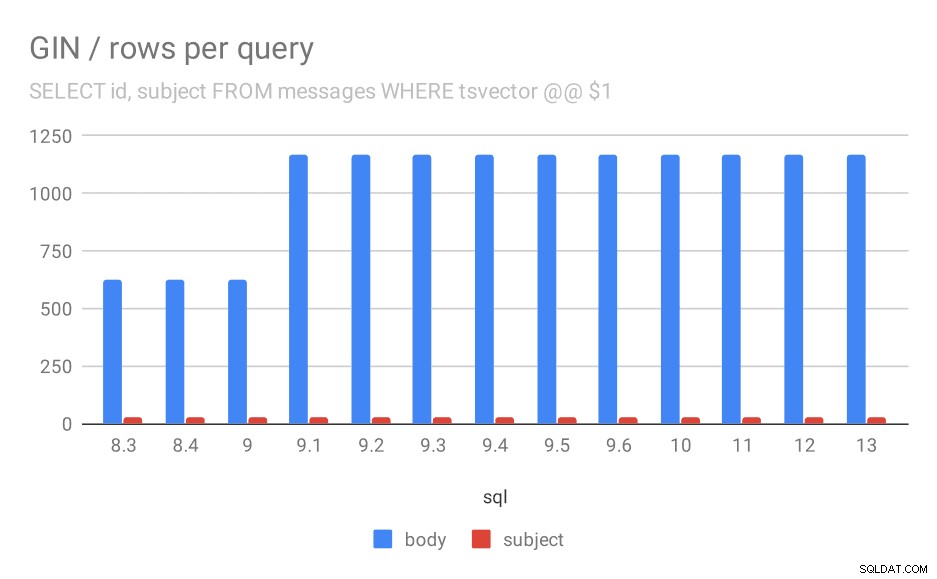
Số hàng được trả về trung bình cho một truy vấn.
| CƠ THỂ | SUBJECT | |
| 8.3 | 624 | 26 |
| 8,4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9,6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Rõ ràng, trong 9.1, số lượng kết quả trung bình cho các tìm kiếm trong nội dung thư đột nhiên tăng gấp đôi, gần như tỷ lệ thuận với tốc độ chậm lại. Tuy nhiên, số lượng kết quả cho các tìm kiếm chủ đề vẫn không đổi. Tôi không có lời giải thích tốt cho điều này, ngoại trừ việc lập chỉ mục đã thay đổi theo cách cho phép khớp với nhiều thông báo hơn, nhưng làm cho nó chậm hơn một chút. Nếu bạn có những lời giải thích hay hơn, tôi muốn nghe chúng!
GiST / tải dữ liệu
Bây giờ, một loại chỉ mục toàn văn khác - GiST. Các chỉ mục này bị mất mát, tức là yêu cầu kiểm tra lại kết quả bằng cách sử dụng các giá trị từ bảng. Vì vậy, chúng ta có thể mong đợi thông lượng thấp hơn so với các chỉ số GIN, nhưng nếu không thì cũng hợp lý khi mong đợi gần giống mẫu.
Thời gian tải thực sự khớp với GIN gần như hoàn hảo - thời gian tạo chỉ mục là khác nhau, nhưng mô hình tổng thể thì giống nhau. Tăng tốc trong 9.1, chậm lại nhỏ trong 11.
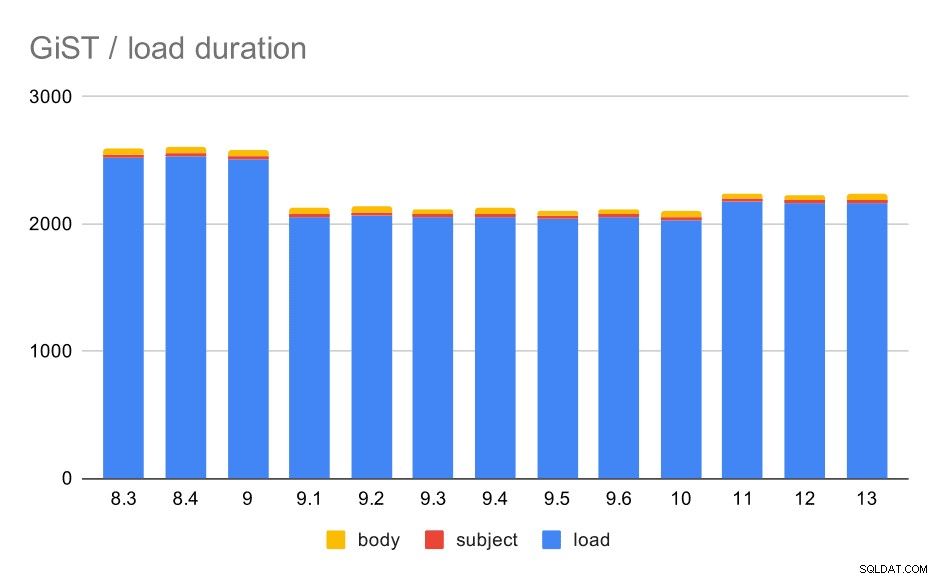
Các thao tác tải dữ liệu với một bảng và các chỉ mục GiST.
| TẢI | SUBJECT | CƠ THỂ | |
| 8.3 | 2522 | 23 | 47 |
| 8,4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9,6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Tuy nhiên, kích thước chỉ mục hầu như không đổi - không có cải tiến GiST nào tương tự như GIN trong 9.4, khiến kích thước giảm ~ 30%. Có một sự gia tăng trong 9.1, đây là một dấu hiệu khác cho thấy việc lập chỉ mục toàn văn đã thay đổi trong phiên bản đó để lập chỉ mục nhiều từ hơn.
Điều này được hỗ trợ thêm bởi số lượng kết quả trung bình với GiST giống hệt như đối với GIN (tăng 9,1).
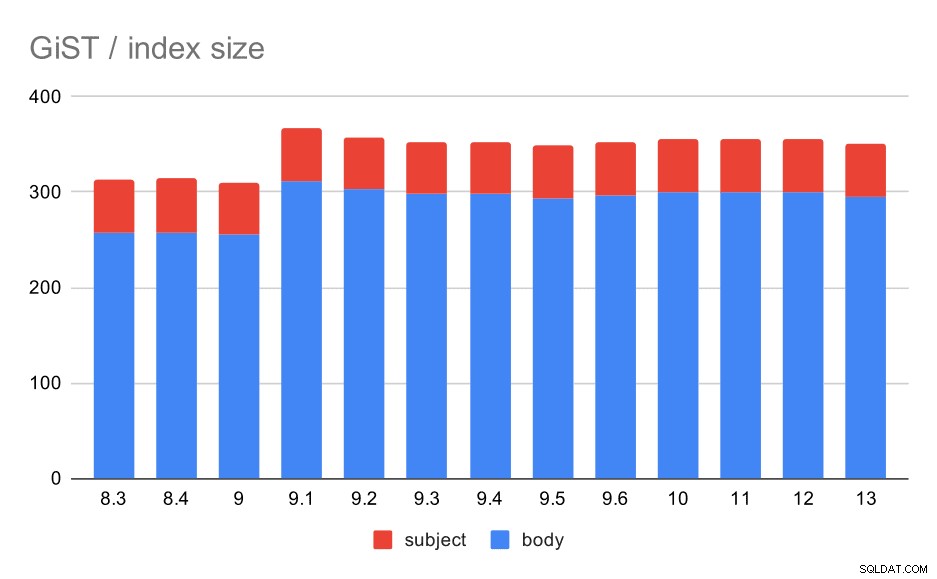
Kích thước của các chỉ mục GiST trên chủ đề / nội dung thư. Giá trị là megabyte.
| CƠ THỂ | SUBJECT | |
| 8.3 | 257 | 56 |
| 8,4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
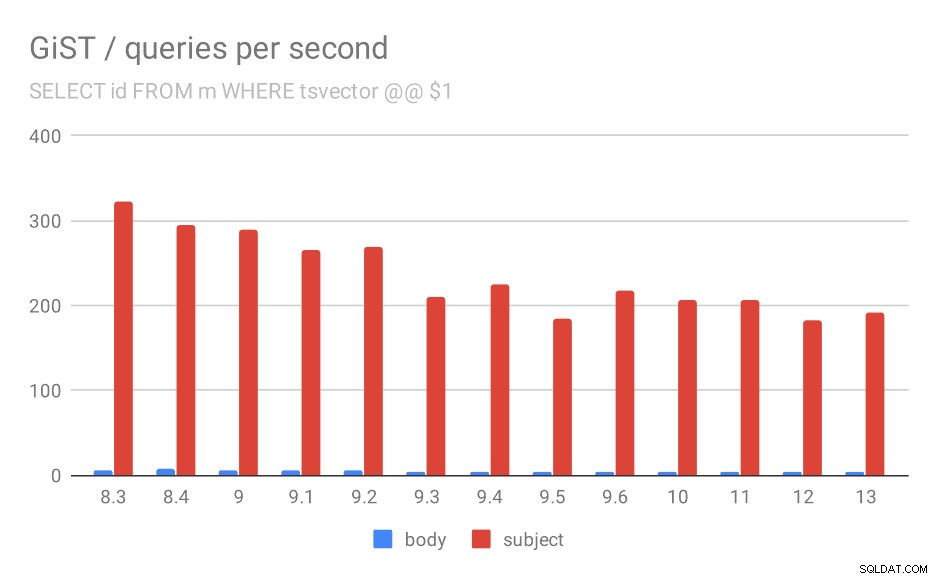
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
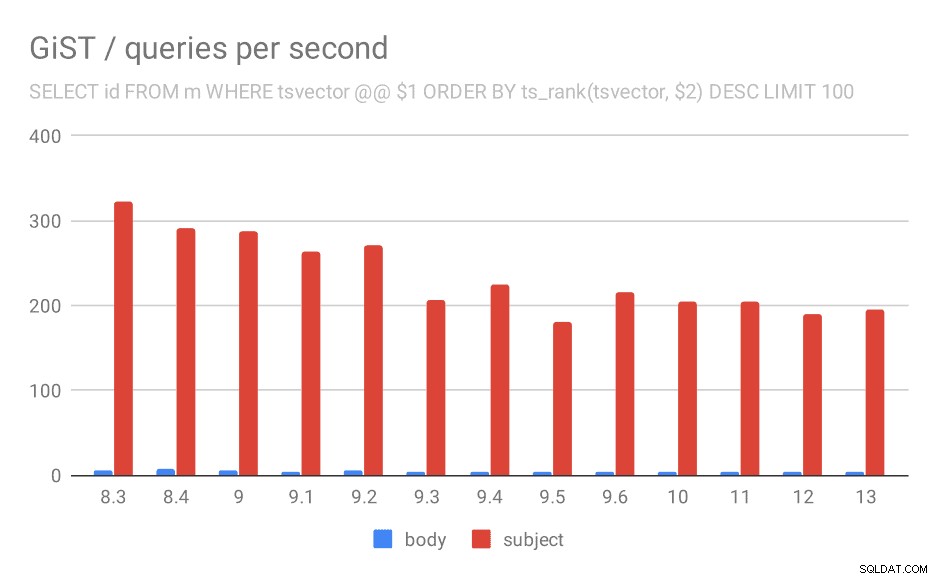
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).



