Để vận hành bất kỳ cơ sở dữ liệu nào một cách hiệu quả, bạn cần có cái nhìn sâu sắc về hiệu suất cơ sở dữ liệu. Điều này có thể không rõ ràng khi mọi thứ đang diễn ra tốt đẹp, nhưng ngay khi có sự cố, quyền truy cập thông tin có thể là công cụ giúp chẩn đoán chính xác và nhanh chóng vấn đề.
Tất cả cơ sở dữ liệu cung cấp một số dữ liệu trạng thái nội bộ cho người dùng. Trong MySQL, bạn có thể lấy dữ liệu này chủ yếu bằng cách chạy 'HIỂN THỊ TÌNH TRẠNG' và 'HIỂN THỊ TÌNH TRẠNG TOÀN CẦU', bằng cách thực thi 'TÌNH TRẠNG KỸ THUẬT HIỂN THỊ', kiểm tra bảng information_schema và trong các phiên bản mới hơn, bằng cách truy vấn bảng performance_schema.

Các phương pháp này không thuận tiện trong hoạt động hàng ngày, do đó sự phổ biến của các giải pháp theo dõi và xu hướng khác nhau. Các công cụ như Nagios / Icinga được thiết kế để theo dõi máy chủ / dịch vụ và cảnh báo khi dịch vụ nằm ngoài phạm vi chấp nhận được. Các công cụ khác như Cacti và Munin cung cấp giao diện đồ họa về thông tin máy chủ / dịch vụ và cung cấp bối cảnh lịch sử cho hiệu suất và cách sử dụng. ClusterControl kết hợp hai loại giám sát này, vì vậy chúng ta sẽ xem xét thông tin mà nó trình bày và cách chúng ta nên giải thích nó.
Nếu bạn đang sử dụng Galera Cluster (MySQL Galera Cluster theo Codership hoặc MariaDB Cluster hoặc Percona XtraDB Cluster), bạn có thể nhận thấy phần sau trong tab "Tổng quan" của ClusterControl:
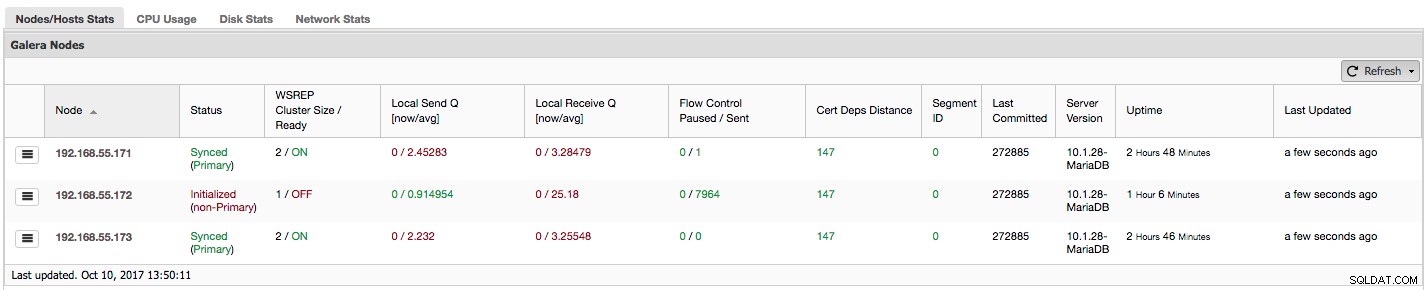
Hãy xem từng bước chúng ta có loại dữ liệu nào ở đây.
Cột đầu tiên chứa danh sách các nút có địa chỉ IP của chúng - không có nhiều điều khác để nói về nó.
Cột thứ hai thú vị hơn - nó mô tả trạng thái nút ( wsrep_local_state_comment tình trạng). Một nút có thể ở các trạng thái khác nhau:
- Đã khởi tạo - Nút đang hoạt động, nhưng nó không phải là một phần của một cụm. Nó có thể được gây ra, chẳng hạn như do sự cố mạng;
- Tham gia - Nút đang trong quá trình tham gia cụm và nó đang nhận hoặc yêu cầu chuyển trạng thái từ một trong các nút khác;
- Nhà tài trợ / Đã hủy bỏ - Nút đóng vai trò là nhà tài trợ cho một số nút khác đang tham gia cụm;
- Đã tham gia - Nút được tham gia vào cụm nhưng nó bận bắt kịp các bộ ghi đã cam kết;
- Đã đồng bộ hóa - Nút đang hoạt động bình thường.
Trong cùng một cột trong ngoặc là trạng thái cụm ( wsrep_cluster_status tình trạng). Nó có thể có ba trạng thái riêng biệt:
- Chính - Giao tiếp giữa các nút đang hoạt động và số đại biểu hiện có (phần lớn các nút có sẵn)
- Không phải Chính - Nút là một phần của cụm nhưng vì lý do nào đó, nó mất liên lạc với phần còn lại của cụm. Do đó, nút này được coi là không hoạt động và nó sẽ không chấp nhận các truy vấn
- Đã ngắt kết nối - Nút không thể thiết lập giao tiếp nhóm.
"WSREP Cluster Size / Ready" cho chúng ta biết về kích thước cụm khi nút nhìn thấy nó và liệu nút có sẵn sàng chấp nhận các truy vấn hay không. Các thành phần không phải chính tạo một cụm có kích thước bằng 1 và tính sẵn sàng của wsrep đang TẮT.
Hãy xem ảnh chụp màn hình ở trên và xem nó nói gì với chúng ta về Galera. Chúng ta có thể thấy ba nút. Hai trong số chúng (192.168.55.171 và 192.168.55.173) hoàn toàn ổn, chúng đều ở trạng thái "Đồng bộ hóa" và cụm ở trạng thái "Chính". Cụm hiện tại bao gồm hai nút. Nút 192.168.55.172 được "Khởi tạo" và nó tạo thành thành phần "không phải Chính". Điều đó có nghĩa là nút này bị mất kết nối với cụm - rất có thể là một số loại sự cố mạng (trên thực tế, chúng tôi đã sử dụng iptables để chặn lưu lượng truy cập đến nút này từ cả 192.168.55.171 và 192.168.55.173).
Tại thời điểm này, chúng tôi phải dừng lại một chút và mô tả cách Galera Cluster hoạt động trong nội bộ. Chúng tôi sẽ không đi vào quá nhiều chi tiết vì nó không nằm trong phạm vi của bài đăng blog này nhưng cần có một số kiến thức để hiểu tầm quan trọng của dữ liệu được trình bày trong các cột tiếp theo.
Galera là một cụm đa tổng thể "ảo" đồng bộ. Điều đó có nghĩa là bạn nên mong đợi dữ liệu được chuyển giữa các nút "hầu như" cùng một lúc (không còn vấn đề khó chịu với nô lệ bị trễ) và bạn có thể ghi vào bất kỳ nút nào trong một cụm (không còn vấn đề khó chịu với việc thúc đẩy nô lệ làm chủ ). Để thực hiện điều đó, Galera sử dụng các bộ ghi - tập hợp nguyên tử của các thay đổi được sao chép trên toàn bộ cụm. Một bộ ghi có thể chứa một số thay đổi hàng và thông tin cần thiết bổ sung như dữ liệu liên quan đến khóa.
Khi một máy khách đưa ra COMMIT, nhưng trước khi MySQL thực sự cam kết bất cứ điều gì, một bộ ghi được tạo và gửi đến tất cả các nút trong cụm để chứng nhận. Tất cả các nút kiểm tra xem liệu có thể thực hiện các thay đổi hay không (vì các thay đổi có thể ảnh hưởng đến việc ghi khác được thực hiện, trong khi chờ đợi, trực tiếp trên một nút khác). Nếu có, dữ liệu thực sự được MySQL cam kết, nếu không, quá trình khôi phục được thực thi.
Điều quan trọng cần nhớ là thực tế là các nút, tương tự như nô lệ trong sao chép thông thường, có thể hoạt động khác nhau - một số có thể có phần cứng tốt hơn những nút khác, một số có thể được tải nhiều hơn những nút khác. Tuy nhiên, Galera yêu cầu họ xử lý các bản ghi một cách ngắn gọn và nhanh chóng, để duy trì đồng bộ hóa "ảo". Phải có một cơ chế có thể hạn chế việc sao chép và cho phép các nút chậm hơn theo kịp phần còn lại của cụm.
Hãy cùng xem các cột "Gửi nội bộ Q [bây giờ / avg]" và "Nhận nội bộ Q [bây giờ / trung bình]". Mỗi nút có một hàng đợi cục bộ để gửi và nhận các tập ghi. Nó cho phép song song một số dữ liệu ghi và hàng đợi không thể được xử lý cùng một lúc nếu nút không thể theo kịp lưu lượng truy cập. Trong HIỂN THỊ TRẠNG THÁI TOÀN CẦU, chúng ta có thể tìm thấy tám bộ đếm mô tả cả hai hàng đợi, bốn bộ đếm cho mỗi hàng đợi:
- wsrep_local_send_queue - trạng thái hiện tại của hàng đợi gửi
- wsrep_local_send_queue_min - tối thiểu kể từ TRẠNG THÁI FLUSH
- wsrep_local_send_queue_max - tối đa kể từ TRẠNG THÁI FLUSH
- wsrep_local_send_queue_avg - trung bình kể từ TRẠNG THÁI FLUSH
- wsrep_local_recv_queue - trạng thái hiện tại của hàng đợi nhận
- wsrep_local_recv_queue_min - tối thiểu kể từ TRẠNG THÁI FLUSH
- wsrep_local_recv_queue_max - tối đa kể từ TRẠNG THÁI FLUSH
- wsrep_local_recv_queue_avg - trung bình kể từ TRẠNG THÁI FLUSH
Các chỉ số trên được thống nhất giữa các nút trong ClusterControl -> Hiệu suất -> Trạng thái DB:
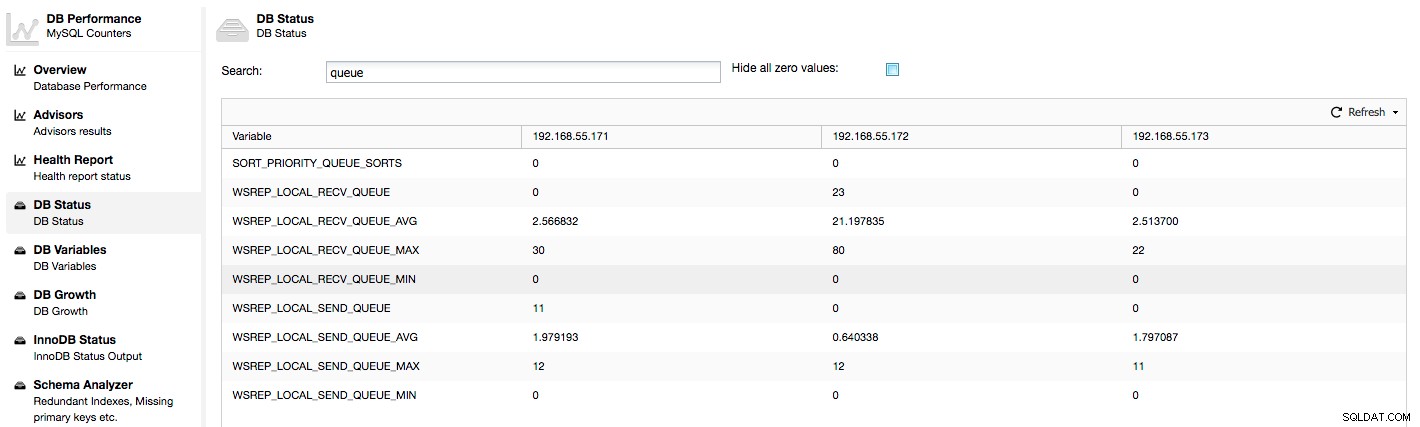
ClusterControl hiển thị các bộ đếm "bây giờ" và "trung bình", vì chúng có ý nghĩa nhất dưới dạng một số duy nhất (bạn cũng có thể tạo đồ thị tùy chỉnh dựa trên các biến mô tả trạng thái hiện tại của hàng đợi). Khi chúng tôi thấy rằng một trong các hàng đợi đang tăng lên, điều này có nghĩa là nút đó không thể theo kịp với quá trình sao chép và các nút khác sẽ phải chạy chậm lại để cho phép nó bắt kịp. Chúng tôi khuyên bạn nên điều tra khối lượng công việc của nút nhất định đó - kiểm tra danh sách quy trình để biết một số truy vấn đang chạy dài, kiểm tra thống kê hệ điều hành như mức sử dụng CPU và khối lượng công việc I / O. Có thể cũng có thể phân phối lại một số lưu lượng truy cập từ nút đó đến phần còn lại của cụm.
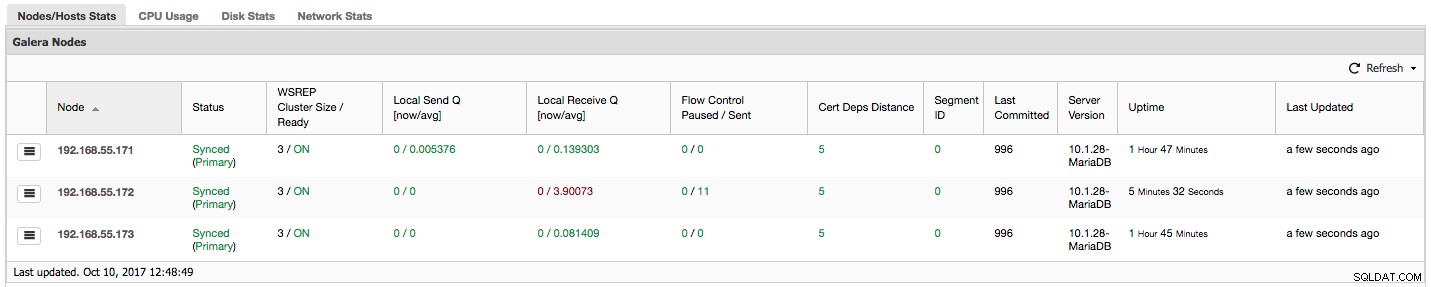
"Kiểm soát luồng bị tạm dừng" hiển thị thông tin về phần trăm thời gian một nút nhất định phải tạm dừng sao chép vì tải quá nặng. Khi một nút không thể theo kịp khối lượng công việc, nó sẽ gửi các gói Điều khiển luồng đến các nút khác, thông báo cho họ biết rằng họ nên giảm tốc độ gửi các bản ghi. Trong ảnh chụp màn hình của chúng tôi, chúng tôi có giá trị ‘0,30’ cho nút 192.168.55.172. Điều này có nghĩa là gần 30% thời gian nút này phải tạm dừng quá trình sao chép vì nó không thể theo kịp tỷ lệ chứng nhận bộ ghi do các nút khác yêu cầu (hoặc đơn giản hơn, quá nhiều lần ghi đã ảnh hưởng đến nó!). Như chúng ta có thể thấy, "Nhận cục bộ Q [avg]" cũng chỉ cho chúng ta thực tế này.
Cột tiếp theo, "Điều khiển luồng đã gửi" cung cấp cho chúng tôi thông tin về số lượng gói Điều khiển luồng mà một nút nhất định được gửi đến cụm. Một lần nữa, chúng tôi thấy rằng chính nút 192.168.55.172 đang làm chậm cụm.
Chúng ta có thể làm gì với thông tin này? Hầu hết, chúng ta nên điều tra xem điều gì đang xảy ra trong nút chậm. Kiểm tra việc sử dụng CPU, kiểm tra hiệu suất I / O và số liệu thống kê mạng. Bước đầu tiên này giúp đánh giá loại vấn đề mà chúng ta đang gặp phải.
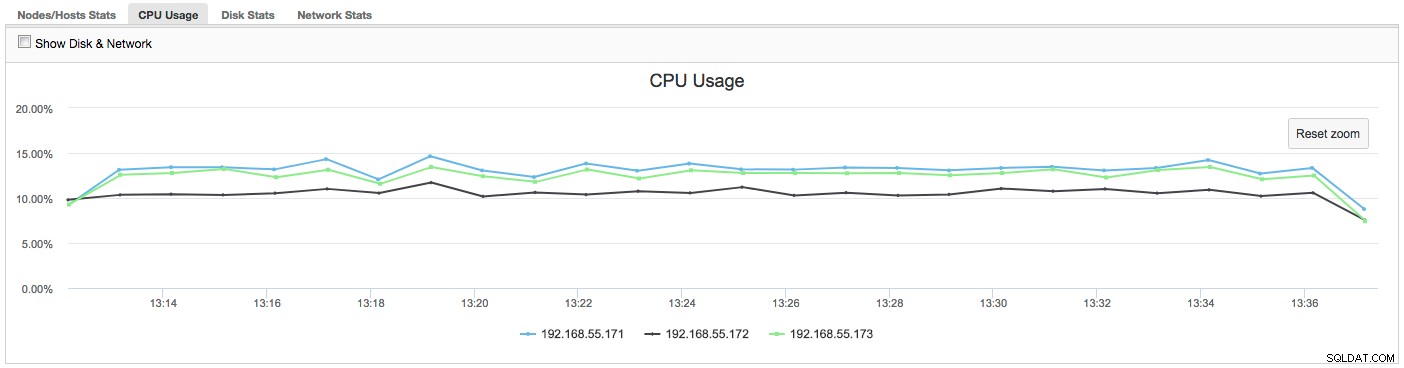
Trong trường hợp này, khi chúng tôi chuyển sang tab Sử dụng CPU, rõ ràng là việc sử dụng CPU rộng rãi đang gây ra sự cố của chúng tôi. Bước tiếp theo sẽ là xác định thủ phạm bằng cách xem PROCESSLIST (Trình theo dõi truy vấn -> Truy vấn đang chạy -> lọc theo 192.168.55.172) để kiểm tra các truy vấn vi phạm:
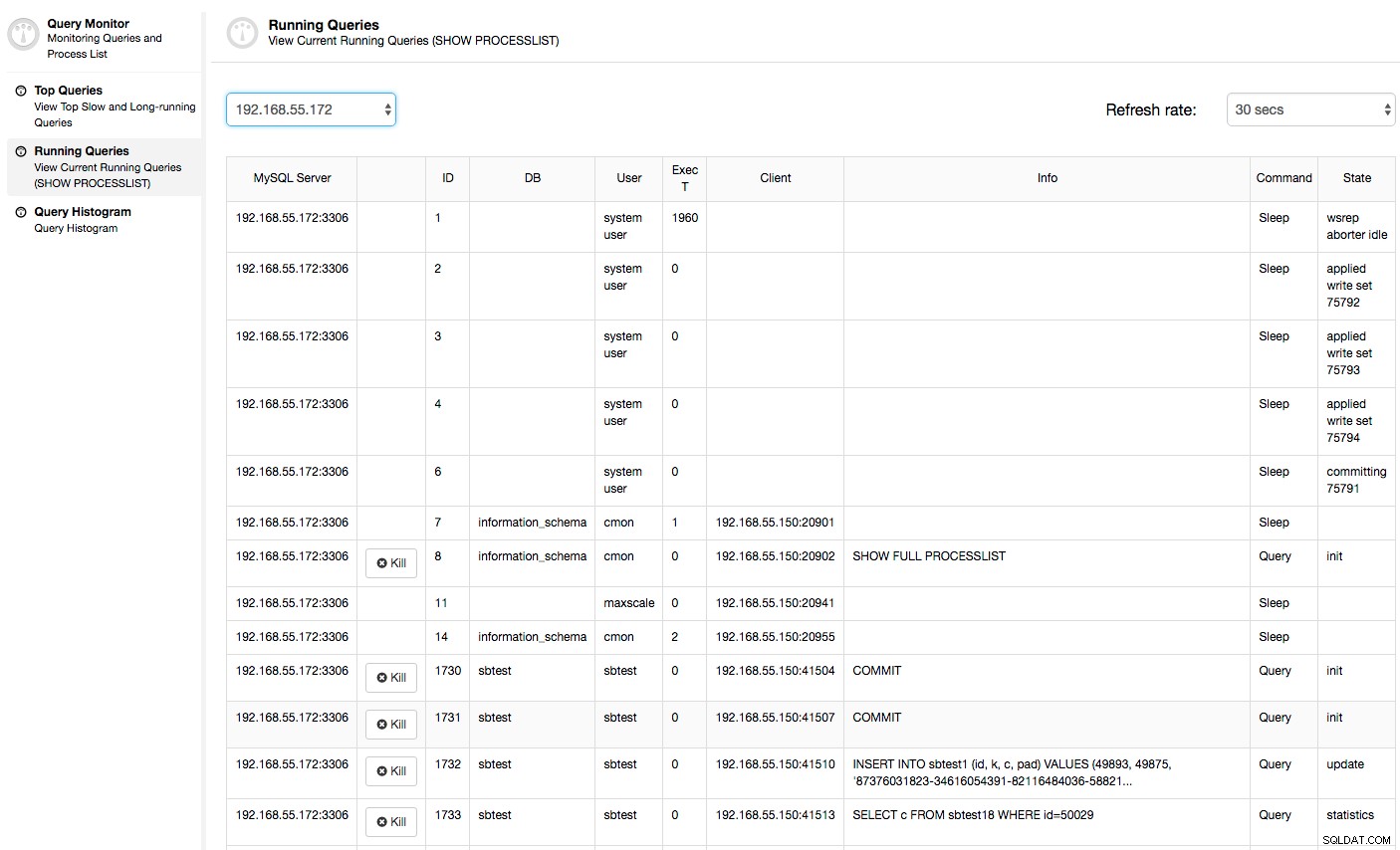
Hoặc, kiểm tra các quy trình trên nút từ phía hệ điều hành (Nút -> 192.168.55.172 -> Trên cùng) để xem tải có phải do thứ gì đó bên ngoài Galera / MySQL gây ra hay không.
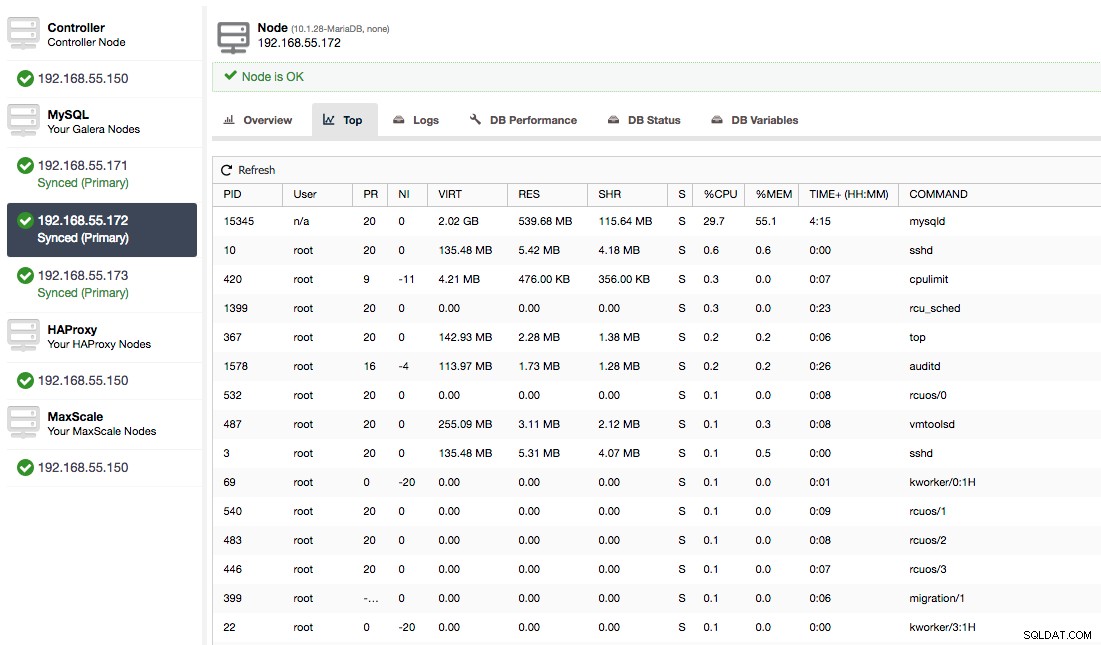
Trong trường hợp này, chúng tôi đã thực thi lệnh mysqld thông qua cpulimit, để mô phỏng việc sử dụng CPU chậm đặc biệt cho quy trình mysqld bằng cách giới hạn nó ở mức 30% trong số 400% CPU khả dụng (máy chủ có 4 lõi).
Cột "Khoảng cách Cert Deps" cung cấp cho chúng ta thông tin về trung bình có bao nhiêu bộ ghi có thể được áp dụng song song. Đôi khi, các tập viết có thể được thực thi cùng một lúc - Galera tận dụng lợi thế này bằng cách sử dụng nhiều wsrep_slave_threads để áp dụng các bản ghi. Cột này cung cấp cho bạn một số ý tưởng về số lượng chủ đề phụ mà bạn có thể sử dụng trên khối lượng công việc của mình. Cần lưu ý rằng không có ích lợi gì khi thiết lập wsrep_slave_threads biến thành các giá trị cao hơn bạn thấy trong cột này hoặc trong wsrep_cert_deps_distance biến trạng thái, dựa trên cột "Cert Deps Distance". Một lưu ý quan trọng khác - không có điểm nào trong việc cài đặt wsrep_slave_threads biến thành nhiều hơn số lõi mà CPU của bạn có.
"ID phân đoạn" - cột này sẽ yêu cầu giải thích thêm. Phân đoạn là một tính năng mới được thêm vào Galera 3.0. Trước phiên bản này, các tập ghi đã được trao đổi giữa tất cả các nút. Giả sử chúng ta có hai trung tâm dữ liệu:
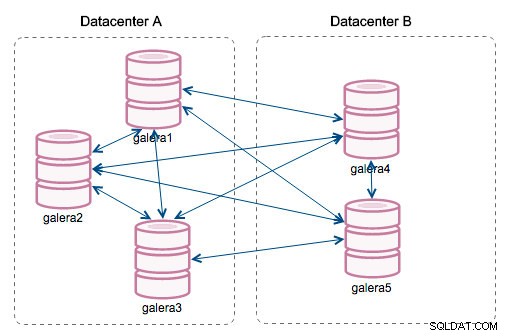
Loại trò chuyện này hoạt động tốt trên các mạng cục bộ nhưng WAN thì lại là một câu chuyện khác - chứng nhận bị chậm lại do độ trễ tăng lên, phát sinh thêm chi phí do băng thông mạng được sử dụng để truyền các bản ghi giữa mọi thành viên trong cụm.
Với sự ra đời của "Phân đoạn", mọi thứ đã thay đổi. Bạn có thể chỉ định một nút cho một phân đoạn bằng cách sửa đổi wsrep_provider_options và thêm "gmcast.segment =x" (0, 1, 2) vào đó. Các nút có cùng số phân đoạn được coi là chúng nằm trong cùng một trung tâm dữ liệu, được kết nối bằng mạng cục bộ. Biểu đồ của chúng tôi sau đó trở nên khác:
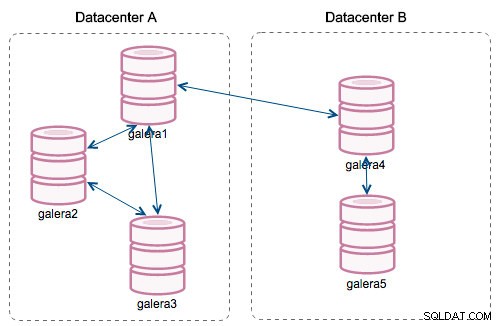
Sự khác biệt chính là không còn giao tiếp giữa mọi người với tất cả mọi người. Trong mỗi phân đoạn, vâng - nó vẫn là cơ chế giống nhau nhưng cả hai phân đoạn chỉ giao tiếp thông qua một kết nối duy nhất giữa hai nút đã chọn. Trong trường hợp thời gian chết, kết nối này sẽ tự động chuyển đổi dự phòng. Kết quả là, chúng tôi nhận được ít cuộc trò chuyện mạng hơn và sử dụng ít băng thông hơn giữa các trung tâm dữ liệu từ xa. Vì vậy, về cơ bản, cột "ID phân đoạn" cho chúng ta biết phân đoạn nào mà một nút được chỉ định.
Cột "Đã cam kết cuối cùng" cung cấp cho chúng ta thông tin về số thứ tự của bộ ghi được thực thi lần cuối trên một nút nhất định. Nó có thể hữu ích trong việc xác định nút nào là nút mới nhất nếu có nhu cầu khởi động cụm.
Phần còn lại của các cột là tự giải thích:Phiên bản máy chủ, thời gian hoạt động của nút và thời điểm cập nhật trạng thái.
Như bạn có thể thấy, phần "Nút Galera" của "Số liệu thống kê về nút / máy chủ" trong tab "Tổng quan" cho bạn hiểu khá tốt về tình trạng của cụm - cho dù nó có tạo thành thành phần "Chính" hay không, có bao nhiêu nút hoạt động tốt. , có bất kỳ vấn đề hiệu suất nào với một số nút không và nếu có, nút nào đang làm chậm cụm.
Bộ dữ liệu này rất hữu ích khi bạn vận hành cụm Galera của mình, vì vậy hy vọng rằng không còn bay mù mịt nữa :-)



