Như bạn có thể đã lưu ý từ blog trước của tôi, vài tháng trước đã bận rộn trong việc cập nhật Postgres-XL với bản phát hành 9.5 mới nhất của PostgreSQL. Khi chúng tôi đã có một phiên bản Postgres-XL 9.5 khá ổn định, chúng tôi đã chuyển sự chú ý sang đo lường hiệu suất của phiên bản Postgres-XL hoàn toàn mới này. Sự lựa chọn điểm chuẩn của chúng tôi phần lớn bị ảnh hưởng bởi công việc đang diễn ra trong dự án AXLE, được tài trợ bởi Liên minh Châu Âu theo thỏa thuận tài trợ 318633. Vì chúng tôi đang sử dụng TPC BENCHMARK ™ H để đo lường hiệu suất của tất cả các công việc khác được thực hiện trong dự án này, chúng tôi quyết định sử dụng cùng một điểm chuẩn để đánh giá Postgres-XL. Nó cũng phù hợp với Postgres-XL vì TPC-H cố gắng đo lường khối lượng công việc OLAP, điều mà Postgres-XL nên làm tốt.
1. Thiết lập cụm Postgres-XL
Khi điểm chuẩn đã được quyết định, một thách thức lớn khác là tìm kiếm các nguồn lực phù hợp để kiểm tra. Chúng tôi không có quyền truy cập vào một nhóm lớn các máy vật lý. Vì vậy, chúng tôi đã làm những gì hầu hết sẽ làm. Chúng tôi đã quyết định sử dụng Amazon AWS để thiết lập cụm Postgres-XL. AWS cung cấp nhiều loại phiên bản, với mỗi loại phiên bản cung cấp tính toán hoặc sức mạnh IO khác nhau.
Trang này trên AWS hiển thị các loại phiên bản có sẵn khác nhau, tài nguyên có sẵn và giá của chúng cho các khu vực khác nhau. Cần lưu ý rằng giá cả và tình trạng sẵn có có thể khác nhau giữa các khu vực, vì vậy điều quan trọng là bạn phải kiểm tra tất cả các khu vực. Vì Postgres-XL yêu cầu độ trễ thấp và thông lượng cao giữa các thành phần của nó, điều quan trọng là phải khởi tạo tất cả các phiên bản trong cùng một khu vực. Đối với TPC-H 3TB của chúng tôi, chúng tôi đã quyết định sử dụng cụm 16 nút dữ liệu của các phiên bản AWS i2.xlarge. Các phiên bản này có 4 vCPU, 30GB RAM và 800GB SSD, đủ dung lượng lưu trữ để giữ tất cả các bảng được phân phối, các bảng được sao chép (chiếm nhiều dung lượng hơn khi kích thước của cụm ngày càng tăng), các chỉ mục trên chúng và vẫn để lại đủ dung lượng trống trong vùng bảng tạm thời cho CREATE INDEX và các truy vấn khác.
2. Thiết lập điểm chuẩn
2.1 TPC Benchmark ™ H
Điểm chuẩn chứa 22 truy vấn với mục đích kiểm tra khối lượng lớn dữ liệu, thực hiện các truy vấn có mức độ phức tạp cao và đưa ra câu trả lời cho các câu hỏi kinh doanh quan trọng. Chúng tôi muốn lưu ý rằng thông số kỹ thuật TPC Benchmark ™ H hoàn chỉnh liên quan đến nhiều bài kiểm tra như tải, công suất và thông lượng các bài kiểm tra. Đối với thử nghiệm của chúng tôi, chúng tôi chỉ chạy các truy vấn riêng lẻ chứ không chạy bộ thử nghiệm hoàn chỉnh. TPC Benchmark ™ H bao gồm một tập hợp các truy vấn nghiệp vụ được thiết kế để thực hiện các chức năng của hệ thống theo cách đại diện cho các ứng dụng phân tích nghiệp vụ phức tạp. Các truy vấn này được đưa ra trong bối cảnh thực tế, mô tả hoạt động của nhà cung cấp bán buôn để giúp người đọc liên hệ trực quan với các thành phần của điểm chuẩn.
2.2 Đối tượng cơ sở dữ liệu, mối quan hệ và đặc điểm
Các thành phần của cơ sở dữ liệu TPC-H được định nghĩa bao gồm tám bảng riêng biệt và riêng lẻ (Bảng cơ sở). Mối quan hệ giữa các cột của các bảng này được minh họa trong sơ đồ sau. 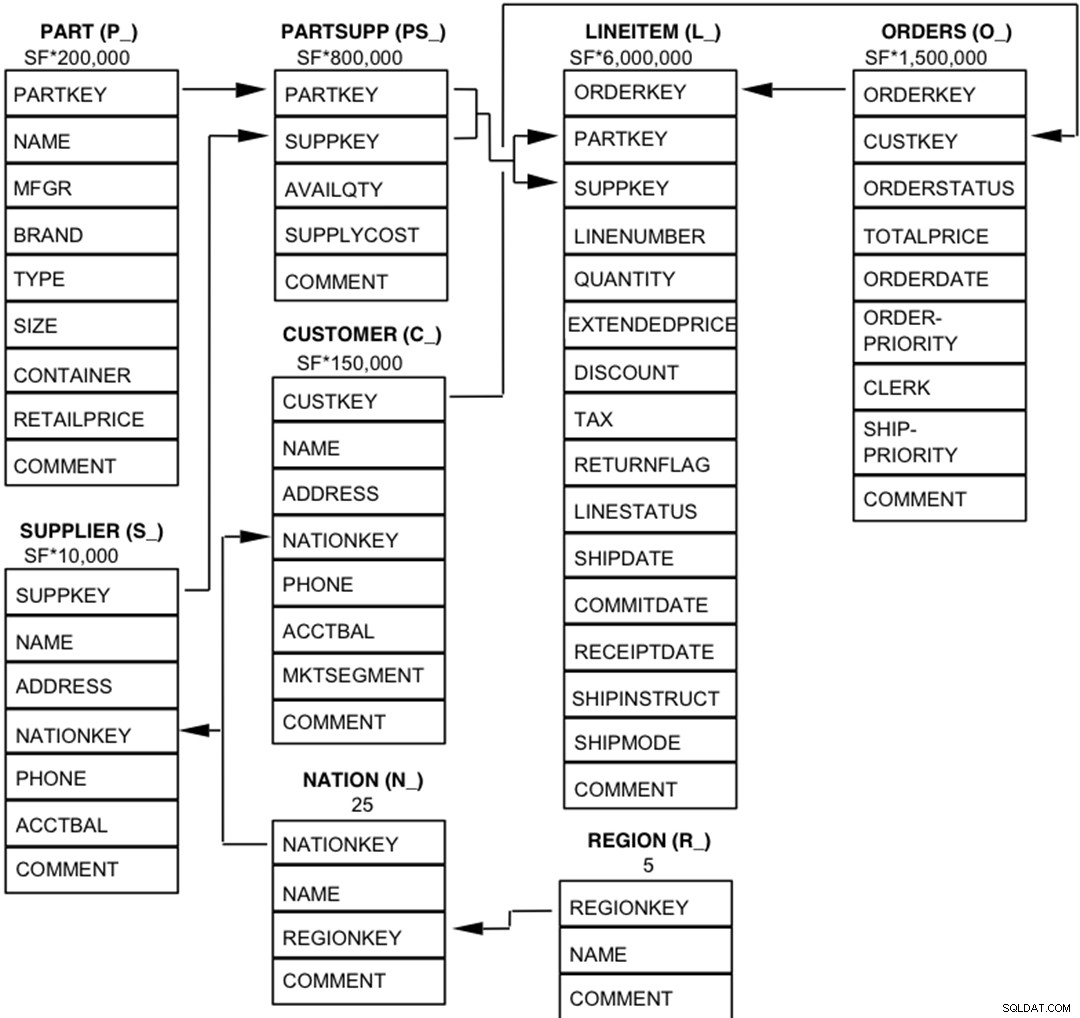 Chú giải :
Chú giải :
-
- Dấu ngoặc đơn theo sau mỗi tên bảng chứa tiền tố của tên cột cho bảng đó;
-
- Các mũi tên trỏ theo hướng của mối quan hệ một-nhiều giữa các bảng
- Số / công thức bên dưới mỗi tên bảng biểu thị số lượng (số hàng) của bảng. Một số được tính theo yếu tố SF, Hệ số tỷ lệ, để có được kích thước cơ sở dữ liệu đã chọn. Cardinality cho bảng LINEITEM là gần đúng
2.3 Phân phối dữ liệu cho Postgres-XL
Chúng tôi đã phân tích tất cả 22 truy vấn trong điểm chuẩn và đưa ra chiến lược phân phối dữ liệu sau cho các bảng khác nhau trong điểm chuẩn.
| Tên bảng | Chiến lược Phân phối |
| LINEITEM | HASH (l_orderkey) |
| ĐƠN HÀNG | HASH (o_orderkey) |
| PHẦN | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| KHÁCH HÀNG | ĐƯỢC THAY THẾ |
| NHÀ CUNG CẤP | ĐƯỢC THAY THẾ |
| TOÀN QUỐC | ĐƯỢC THAY THẾ |
| VÙNG | ĐƯỢC THAY THẾ |
Lưu ý rằng LINEITEM và ORDERS là các bảng lớn nhất trong điểm chuẩn thường được kết hợp trên ORDERKEY. Vì vậy, rất có ý nghĩa khi sắp xếp các bảng này trên ORDERKEY. Tương tự như vậy, PART và PARTSUPP thường được tham gia trên PARTKEY và do đó chúng được xếp chung vào cột PARTKEY. Phần còn lại của các bảng được sao chép để đảm bảo rằng chúng có thể được kết hợp cục bộ khi cần thiết.
3. Kết quả điểm chuẩn
3.1 Kiểm tra tải
Chúng tôi đã so sánh kết quả thu được bằng cách chạy Kiểm tra tải TPC-H 3TB trên PostgreSQL 9.6 với cụm Postgres-XL 16 nút. Các biểu đồ sau đây chứng minh các đặc tính hiệu suất của Postgres-XL.
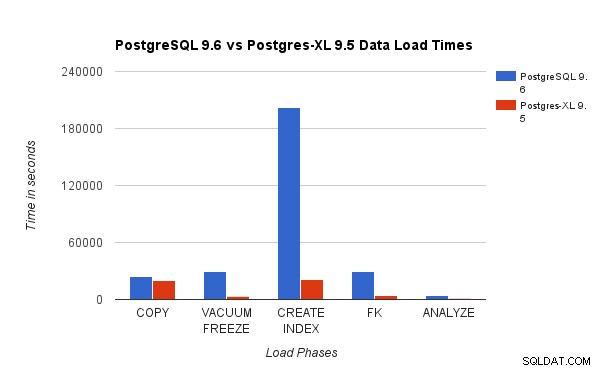 Biểu đồ trên cho thấy thời gian cần thiết để hoàn thành các giai đoạn khác nhau của Kiểm tra tải với PostgreSQL và Postgres-XL. Như đã thấy, Postgres-XL hoạt động tốt hơn một chút đối với COPY và tốt hơn rất nhiều đối với tất cả các trường hợp khác. Lưu ý :Chúng tôi nhận thấy rằng bộ điều phối yêu cầu nhiều năng lượng tính toán trong giai đoạn COPY, đặc biệt khi nhiều luồng COPY đang chạy đồng thời. Để giải quyết vấn đề đó, trình điều phối đã được chạy trên phiên bản AWS được tối ưu hóa tính toán với 16 vCPU. Ngoài ra, chúng tôi cũng có thể chạy nhiều điều phối viên và phân phối tải tính toán giữa chúng.
Biểu đồ trên cho thấy thời gian cần thiết để hoàn thành các giai đoạn khác nhau của Kiểm tra tải với PostgreSQL và Postgres-XL. Như đã thấy, Postgres-XL hoạt động tốt hơn một chút đối với COPY và tốt hơn rất nhiều đối với tất cả các trường hợp khác. Lưu ý :Chúng tôi nhận thấy rằng bộ điều phối yêu cầu nhiều năng lượng tính toán trong giai đoạn COPY, đặc biệt khi nhiều luồng COPY đang chạy đồng thời. Để giải quyết vấn đề đó, trình điều phối đã được chạy trên phiên bản AWS được tối ưu hóa tính toán với 16 vCPU. Ngoài ra, chúng tôi cũng có thể chạy nhiều điều phối viên và phân phối tải tính toán giữa chúng.
3.2 Kiểm tra nguồn
Chúng tôi cũng so sánh thời gian chạy truy vấn cho điểm chuẩn 3TB trên PostgreSQL 9.6 và Postgres-XL 9.5. Biểu đồ sau đây cho thấy các đặc điểm hiệu suất của việc thực thi truy vấn trên hai thiết lập.
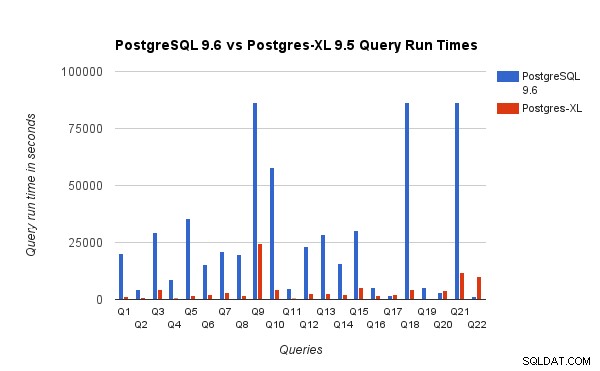 Chúng tôi nhận thấy rằng các truy vấn trung bình chạy nhanh hơn khoảng 6,4 lần trên Postgres-XL và ít nhất 25% các truy vấn cho thấy sự cải thiện gần như tuyến tính về hiệu suất, nói cách khác, chúng hoạt động nhanh hơn gần 16 lần trên cụm 16 nút Postgres-XL này. Hơn nữa, ít nhất 50% các truy vấn cho thấy hiệu suất được cải thiện gấp 10 lần. Chúng tôi đã phân tích thêm các hiệu suất truy vấn và kết luận rằng các truy vấn được phân vùng tốt trên tất cả các nút dữ liệu có sẵn, như vậy, có sự trao đổi dữ liệu tối thiểu giữa các nút và không có các lệnh gọi thực thi từ xa lặp lại, mở rộng quy mô rất tốt trong Postgres-XL. Các truy vấn như vậy thường có nút Quét truy vấn con từ xa ở trên cùng và cây con bên dưới nút được thực hiện song song trên một hoặc nhiều nút. Nó cũng phổ biến khi có một số nút khác như nút Giới hạn hoặc nút Tổng hợp trên đầu nút Quét truy vấn con từ xa. Ngay cả những truy vấn như vậy cũng hoạt động rất tốt trên Postgres-XL. Truy vấn Q1 là một ví dụ về truy vấn sẽ mở rộng quy mô rất tốt với Postgres-XL. Mặt khác, các truy vấn yêu cầu trao đổi nhiều bộ giá trị giữa datanode-datanode và / hoặc điều phối viên-datanode có thể không hoạt động tốt trong Postgres-XL. Tương tự, các truy vấn yêu cầu nhiều kết nối nút chéo, cũng có thể hiển thị hiệu suất kém. Ví dụ, bạn sẽ nhận thấy rằng hiệu suất của Q22 kém hơn so với một máy chủ PostgreSQL một nút. Khi chúng tôi phân tích kế hoạch truy vấn cho Q22, chúng tôi quan sát thấy rằng có ba cấp độ của các nút Quét truy vấn con từ xa lồng nhau trong kế hoạch truy vấn, trong đó mỗi nút mở ra số lượng kết nối bằng nhau đến các nút dữ liệu. Hơn nữa, Nest Loop Anti Join có mối quan hệ bên trong với nút Quét truy vấn con từ xa cấp cao nhất và do đó đối với mỗi bộ của quan hệ bên ngoài, nó phải thực thi một truy vấn con từ xa. Điều này dẫn đến hiệu suất thực thi truy vấn kém.
Chúng tôi nhận thấy rằng các truy vấn trung bình chạy nhanh hơn khoảng 6,4 lần trên Postgres-XL và ít nhất 25% các truy vấn cho thấy sự cải thiện gần như tuyến tính về hiệu suất, nói cách khác, chúng hoạt động nhanh hơn gần 16 lần trên cụm 16 nút Postgres-XL này. Hơn nữa, ít nhất 50% các truy vấn cho thấy hiệu suất được cải thiện gấp 10 lần. Chúng tôi đã phân tích thêm các hiệu suất truy vấn và kết luận rằng các truy vấn được phân vùng tốt trên tất cả các nút dữ liệu có sẵn, như vậy, có sự trao đổi dữ liệu tối thiểu giữa các nút và không có các lệnh gọi thực thi từ xa lặp lại, mở rộng quy mô rất tốt trong Postgres-XL. Các truy vấn như vậy thường có nút Quét truy vấn con từ xa ở trên cùng và cây con bên dưới nút được thực hiện song song trên một hoặc nhiều nút. Nó cũng phổ biến khi có một số nút khác như nút Giới hạn hoặc nút Tổng hợp trên đầu nút Quét truy vấn con từ xa. Ngay cả những truy vấn như vậy cũng hoạt động rất tốt trên Postgres-XL. Truy vấn Q1 là một ví dụ về truy vấn sẽ mở rộng quy mô rất tốt với Postgres-XL. Mặt khác, các truy vấn yêu cầu trao đổi nhiều bộ giá trị giữa datanode-datanode và / hoặc điều phối viên-datanode có thể không hoạt động tốt trong Postgres-XL. Tương tự, các truy vấn yêu cầu nhiều kết nối nút chéo, cũng có thể hiển thị hiệu suất kém. Ví dụ, bạn sẽ nhận thấy rằng hiệu suất của Q22 kém hơn so với một máy chủ PostgreSQL một nút. Khi chúng tôi phân tích kế hoạch truy vấn cho Q22, chúng tôi quan sát thấy rằng có ba cấp độ của các nút Quét truy vấn con từ xa lồng nhau trong kế hoạch truy vấn, trong đó mỗi nút mở ra số lượng kết nối bằng nhau đến các nút dữ liệu. Hơn nữa, Nest Loop Anti Join có mối quan hệ bên trong với nút Quét truy vấn con từ xa cấp cao nhất và do đó đối với mỗi bộ của quan hệ bên ngoài, nó phải thực thi một truy vấn con từ xa. Điều này dẫn đến hiệu suất thực thi truy vấn kém.
4. Một vài bài học AWS
Trong khi đo điểm chuẩn cho Postgres-XL, chúng tôi đã học được một số bài học về cách sử dụng AWS. Chúng tôi nghĩ rằng chúng sẽ hữu ích cho bất kỳ ai đang muốn sử dụng / thử nghiệm Postgres-XL trên AWS.
- AWS cung cấp một số loại phiên bản khác nhau. Bạn phải đánh giá cẩn thận khối lượng công việc và dung lượng lưu trữ cần thiết trước khi chọn một loại phiên bản cụ thể.
- Hầu hết các phiên bản được tối ưu hóa cho bộ nhớ đều có các đĩa tạm thời được gắn vào chúng. Bạn không cần phải trả thêm bất kỳ khoản nào cho những đĩa đó, chúng được gắn vào phiên bản và thường hoạt động tốt hơn EBS. Nhưng bạn phải gắn kết chúng một cách rõ ràng để có thể sử dụng chúng. Tuy nhiên, hãy nhớ rằng dữ liệu được lưu trữ trên các đĩa này không phải là vĩnh viễn và sẽ bị xóa sạch nếu phiên bản bị dừng. Vì vậy, hãy đảm bảo rằng bạn đã chuẩn bị sẵn sàng để xử lý tình huống đó. Vì chúng tôi chủ yếu sử dụng AWS để đo điểm chuẩn nên chúng tôi quyết định sử dụng các đĩa tạm thời này.
- Nếu bạn đang sử dụng EBS, hãy đảm bảo rằng bạn chọn IOPS được cấp phép thích hợp. Giá trị quá thấp sẽ gây ra IO rất chậm, nhưng giá trị rất cao có thể làm tăng đáng kể hóa đơn AWS của bạn, đặc biệt là khi xử lý số lượng lớn các nút.
- Đảm bảo rằng bạn bắt đầu các phiên bản trong cùng một khu vực để giảm độ trễ và cải thiện thông lượng cho các kết nối giữa chúng.
- Đảm bảo rằng bạn định cấu hình các phiên bản để chúng sử dụng mạng riêng tư để nói chuyện với nhau.
- Xem xét các trường hợp tại chỗ. Chúng tương đối rẻ hơn. Vì AWS có thể chấm dứt các phiên bản giao ngay theo ý muốn, chẳng hạn như nếu giá giao ngay cao hơn giá thầu tối đa của bạn, hãy chuẩn bị cho điều đó. Postgres-XL có thể không sử dụng được một phần hoặc hoàn toàn tùy thuộc vào nút nào bị kết thúc. AWS hỗ trợ một khái niệm về nhóm_hộp_cấp. Nếu nhiều trường hợp được nhóm trong cùng một nhóm_bộ_hình_hình, nếu AWS quyết định chấm dứt một phiên bản, tất cả các phiên bản sẽ bị chấm dứt.
5. Kết luận
Chúng tôi có thể cho thấy, thông qua các điểm chuẩn khác nhau, Postgres-XL có thể mở rộng quy mô thực sự tốt cho một nhóm lớn các truy vấn phức tạp trong thế giới thực. Những điểm chuẩn này giúp chúng tôi chứng minh khả năng của Postgres-XL như một giải pháp hiệu quả cho khối lượng công việc OLAP. Các thử nghiệm của chúng tôi cũng cho thấy rằng có một số vấn đề về hiệu suất với Postgres-XL, đặc biệt là đối với các cụm rất lớn và khi người lập kế hoạch đưa ra một lựa chọn sai về một kế hoạch. Chúng tôi cũng quan sát thấy rằng khi có rất nhiều kết nối đồng thời đến một nút dữ liệu, hiệu suất sẽ xấu đi. Chúng tôi sẽ tiếp tục giải quyết những vấn đề về hiệu suất này. Chúng tôi cũng muốn kiểm tra khả năng của Postgres-XL như một giải pháp OLTP bằng cách sử dụng khối lượng công việc thích hợp.