Trong khi điều chỉnh postgresql.conf , bạn có thể nhận thấy có một tùy chọn được gọi là full_page_writes . Nhận xét bên cạnh nó cho biết điều gì đó về việc viết một phần trang và mọi người thường đặt nó thành on - đó là một điều tốt, như tôi sẽ giải thích sau trong bài đăng này. Tuy nhiên, sẽ rất hữu ích nếu bạn hiểu toàn bộ trang viết có tác dụng gì, vì tác động đến hiệu suất có thể khá đáng kể.
Không giống như bài viết trước của tôi về điều chỉnh trạm kiểm soát, đây không phải là hướng dẫn cách điều chỉnh máy chủ. Thực sự thì không có nhiều thứ bạn có thể chỉnh sửa, nhưng tôi sẽ chỉ cho bạn cách một số quyết định cấp ứng dụng (ví dụ:lựa chọn loại dữ liệu) có thể tương tác với việc viết toàn trang.
Viết một phần / Trang bị rách
Vì vậy, toàn trang viết về những gì? Như nhận xét trong postgresql.conf cho biết đó là một cách để khôi phục sau khi ghi một phần trang - PostgreSQL sử dụng các trang 8kB (theo mặc định), nhưng các phần khác của ngăn xếp sử dụng các kích thước phân đoạn khác nhau. Hệ thống tệp Linux thường sử dụng các trang 4kB (có thể sử dụng các trang nhỏ hơn, nhưng 4kB là tối đa trên x86) và ở cấp độ phần cứng, các ổ đĩa cũ sử dụng các cung 512B trong khi các thiết bị mới thường ghi dữ liệu ở các phần lớn hơn (thường là 4kB hoặc thậm chí 8kB) .
Vì vậy, khi PostgreSQL viết trang 8kB, các lớp khác của ngăn xếp lưu trữ có thể chia nó thành các phần nhỏ hơn, được quản lý riêng biệt. Điều này đưa ra một vấn đề liên quan đến tính nguyên tử viết. Trang PostgreSQL 8kB có thể được chia thành hai trang hệ thống tệp 4kB và sau đó thành các sector 512B. Bây giờ, điều gì sẽ xảy ra nếu máy chủ gặp sự cố (mất điện, lỗi hạt nhân,…)?
Ngay cả khi máy chủ sử dụng hệ thống lưu trữ được thiết kế để đối phó với những lỗi như vậy (SSD có tụ điện, bộ điều khiển RAID có pin,…), hạt nhân đã chia dữ liệu thành các trang 4kB. Vì vậy, có thể cơ sở dữ liệu đã ghi trang dữ liệu 8kB, nhưng chỉ một phần trong số đó được đưa vào đĩa trước khi gặp sự cố.
Tại thời điểm này, bạn có thể nghĩ rằng đây chính xác là lý do tại sao chúng tôi có nhật ký giao dịch (WAL), và bạn đã đúng! Vì vậy, sau khi khởi động máy chủ, cơ sở dữ liệu sẽ đọc WAL (kể từ điểm kiểm tra hoàn thành cuối cùng) và áp dụng lại các thay đổi để đảm bảo các tệp dữ liệu đã hoàn tất. Đơn giản.
Nhưng có một điểm khó khăn - quá trình khôi phục không áp dụng các thay đổi một cách mù quáng, nó thường cần đọc các trang dữ liệu, v.v. Giả sử rằng trang chưa bị khóa theo một cách nào đó, chẳng hạn như do bị ghi một phần. Điều này có vẻ hơi mâu thuẫn với bản thân, bởi vì để sửa lỗi dữ liệu, chúng tôi giả định rằng không có dữ liệu nào bị hỏng.
Viết toàn trang là một cách giải quyết vấn đề hóc búa này - khi sửa đổi một trang lần đầu tiên sau một điểm kiểm tra, toàn bộ trang sẽ được viết thành WAL. Điều này đảm bảo rằng trong quá trình khôi phục, bản ghi WAL đầu tiên chạm vào một trang sẽ chứa toàn bộ trang, loại bỏ nhu cầu đọc trang - có thể bị hỏng - từ tệp dữ liệu.
Ghi khuếch đại
Tất nhiên, hệ quả tiêu cực của việc này là kích thước WAL tăng lên - việc thay đổi một byte duy nhất trên trang 8kB sẽ ghi toàn bộ vào WAL. Việc ghi toàn trang chỉ xảy ra ở lần ghi đầu tiên sau một điểm kiểm tra, vì vậy việc làm cho các điểm kiểm tra ít thường xuyên hơn là một cách để cải thiện tình hình - thông thường, có một "loạt" ngắn của toàn trang được viết sau một điểm kiểm tra, và sau đó tương đối ít lần viết toàn trang. cho đến khi kết thúc một trạm kiểm soát.
UUID so với khóa BIGSERIAL
Nhưng có một số tương tác không mong muốn với các quyết định thiết kế được thực hiện ở cấp ứng dụng. Giả sử chúng ta có một bảng đơn giản với khóa chính, BIGSERIAL hoặc UUID và chúng tôi chèn dữ liệu vào đó. Sẽ có sự khác biệt về số lượng WAL được tạo (giả sử chúng ta chèn cùng một số hàng)?
Có vẻ hợp lý khi mong đợi cả hai trường hợp tạo ra cùng một lượng WAL, nhưng như các biểu đồ sau minh họa, có một sự khác biệt rất lớn trong thực tế.
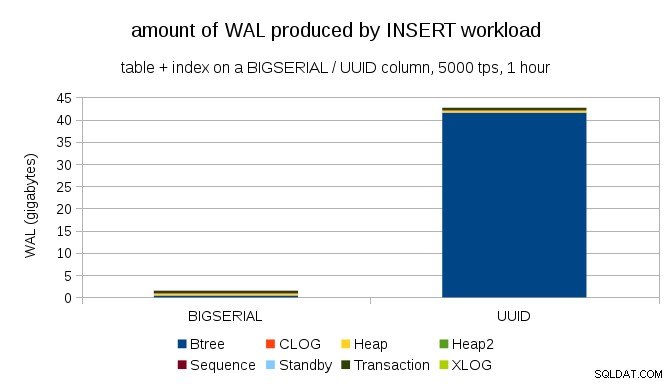
Điều này cho thấy lượng WAL được tạo ra trong 1 giờ chuẩn, được điều chỉnh đến 5000 lần chèn mỗi giây. Với BIGSERIAL khóa chính này tạo ra ~ 2GB WAL, trong khi với UUID hơn 40GB. Đó là một sự khác biệt đáng kể và khá rõ ràng là hầu hết WAL được liên kết với chỉ mục sao lưu khóa chính. Hãy xem như các loại bản ghi WAL.
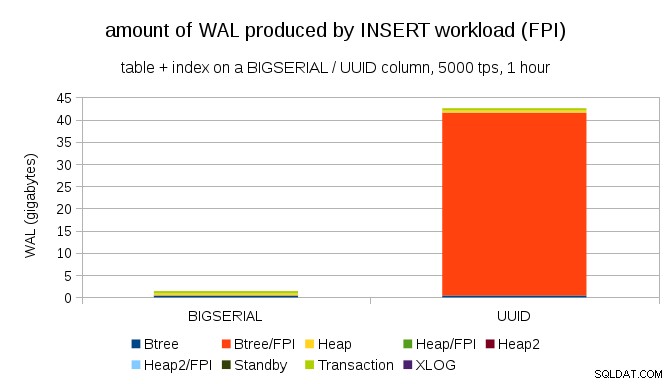
Rõ ràng, phần lớn các bản ghi là hình ảnh toàn trang (FPI), tức là kết quả của việc ghi toàn trang. Nhưng tại sao điều này lại xảy ra?
Tất nhiên, điều này là do UUID vốn có ngẫu nhiên. Với BIGSERIAL mới là tuần tự, và do đó, được chèn vào các trang lá giống nhau trong chỉ mục btree. Vì chỉ sửa đổi đầu tiên đối với một trang kích hoạt việc viết toàn trang, nên chỉ một phần nhỏ các bản ghi WAL là FPI. Với UUID đó là trường hợp hoàn toàn khác, về couse - các giá trị hoàn toàn không tuần tự, trên thực tế, mỗi lần chèn có khả năng chạm vào trang lá chỉ mục lá hoàn toàn mới (giả sử chỉ mục đủ lớn).
Cơ sở dữ liệu không thể làm được gì nhiều - khối lượng công việc về bản chất đơn giản là ngẫu nhiên, kích hoạt nhiều lần viết toàn trang.
Không khó để có được bộ khuếch đại ghi tương tự ngay cả với BIGSERIAL tất nhiên. Nó chỉ yêu cầu khối lượng công việc khác nhau - ví dụ:với UPDATE khối lượng công việc, cập nhật ngẫu nhiên các bản ghi với sự phân bố đồng đều, biểu đồ như sau:
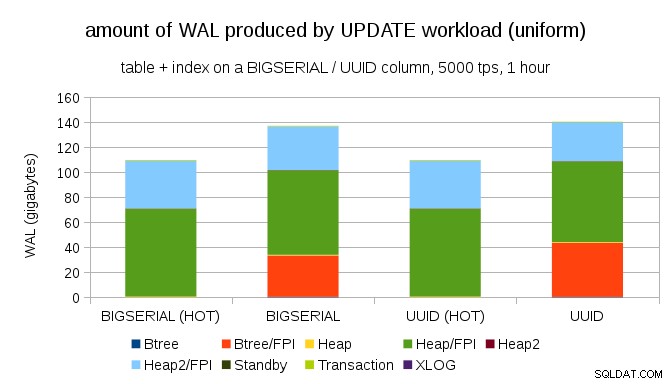
Đột nhiên, sự khác biệt giữa các kiểu dữ liệu không còn - việc truy cập là ngẫu nhiên trong cả hai trường hợp, dẫn đến lượng WAL được tạo ra gần như chính xác. Một sự khác biệt khác là hầu hết WAL được liên kết với “heap”, tức là các bảng, chứ không phải chỉ mục. Các trường hợp "HOT" được thiết kế để cho phép tối ưu hóa HOT UPDATE (tức là cập nhật mà không cần phải chạm vào chỉ mục), điều này giúp loại bỏ khá nhiều lưu lượng truy cập WAL liên quan đến chỉ mục.
Nhưng bạn có thể tranh luận rằng hầu hết các ứng dụng không cập nhật toàn bộ tập dữ liệu. Thông thường, chỉ một tập hợp nhỏ dữ liệu là "hoạt động" - mọi người chỉ truy cập các bài đăng từ vài ngày qua trên diễn đàn thảo luận, các đơn đặt hàng chưa được giải quyết trong một cửa hàng điện tử, v.v. Điều đó thay đổi kết quả như thế nào?
Rất may, pgbench hỗ trợ phân phối không đồng nhất và ví dụ:với phân phối theo cấp số nhân chạm vào 1% tập con dữ liệu ~ 25% thời gian, biểu đồ trông như thế này:
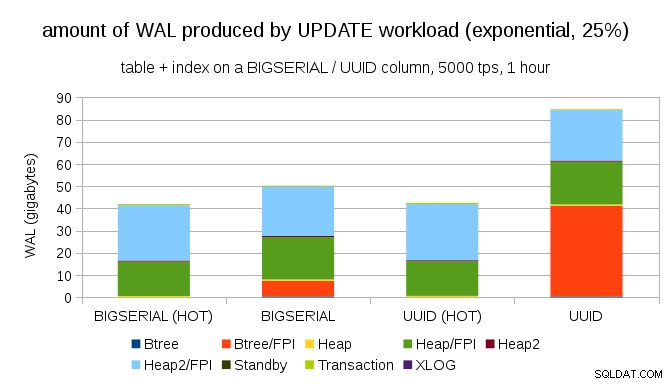
Và sau khi làm cho phân phối bị lệch nhiều hơn, hãy chạm vào tập hợp con 1% ~ 75% thời gian:
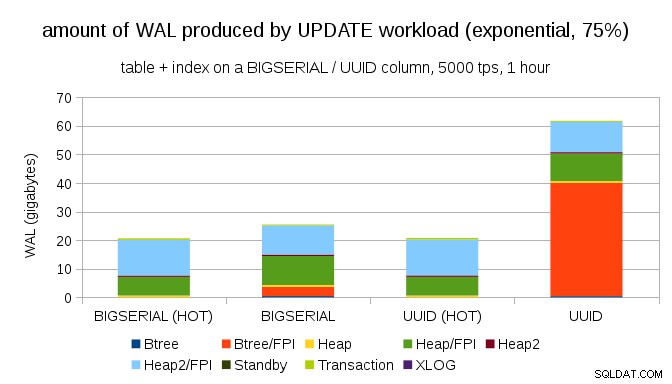
Điều này một lần nữa cho thấy sự khác biệt lớn giữa việc lựa chọn loại dữ liệu và tầm quan trọng của việc điều chỉnh các bản cập nhật HOT.
trang 8kB và 4kB
Một câu hỏi thú vị là chúng ta có thể tiết kiệm bao nhiêu lưu lượng WAL bằng cách sử dụng các trang nhỏ hơn trong PostgreSQL (yêu cầu biên dịch một gói tùy chỉnh). Trong trường hợp tốt nhất, nó có thể tiết kiệm tới 50% WAL, nhờ chỉ ghi các trang 4kB thay vì 8kB. Đối với khối lượng công việc có UPDATE được phân phối đồng đều, nó trông giống như sau:
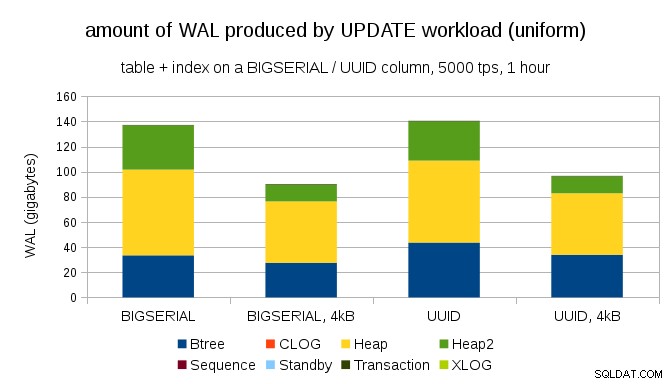
Vì vậy, mức tiết kiệm không chính xác là 50%, nhưng việc giảm từ ~ 140GB xuống ~ 90GB vẫn khá đáng kể.
Chúng ta có cần viết toàn trang không?
Sau khi giải thích về sự nguy hiểm của việc viết từng phần thì có vẻ hơi nực cười, nhưng có thể tắt tính năng viết toàn trang có thể là một lựa chọn khả thi, ít nhất là trong một số trường hợp.
Đầu tiên, tôi tự hỏi liệu các hệ thống tệp Linux hiện đại có còn dễ bị ghi một phần không? Tham số đã được giới thiệu trong PostgreSQL 8.1 được phát hành vào năm 2005, vì vậy có lẽ một số cải tiến hệ thống tệp được giới thiệu kể từ đó khiến điều này không thành vấn đề. Có lẽ không phổ biến cho khối lượng công việc tùy ý, nhưng có thể giả sử một số điều kiện bổ sung (ví dụ:sử dụng kích thước trang 4kB trong PostgreSQL) sẽ là đủ? Ngoài ra, PostgreSQL không bao giờ chỉ ghi đè một tập con của trang 8kB - toàn bộ trang luôn được viết ra.
Gần đây, tôi đã thực hiện rất nhiều thử nghiệm để cố gắng kích hoạt ghi một phần và tôi chưa thể gây ra một trường hợp nào. Tất nhiên, đó không thực sự là bằng chứng cho thấy vấn đề không tồn tại. Nhưng ngay cả khi đó vẫn là sự cố, tổng kiểm tra dữ liệu có thể đủ bảo vệ (nó sẽ không khắc phục được sự cố, nhưng ít nhất sẽ cho bạn biết có một trang bị hỏng).
Thứ hai, nhiều hệ thống ngày nay dựa vào các bản sao sao chép trực tuyến - thay vì đợi máy chủ khởi động lại sau sự cố phần cứng (có thể mất nhiều thời gian) và sau đó dành nhiều thời gian hơn để thực hiện khôi phục, các hệ thống chỉ cần chuyển sang chế độ chờ nóng. Nếu cơ sở dữ liệu trên cơ sở dữ liệu chính bị lỗi bị xóa (và sau đó được sao chép từ cơ sở dữ liệu chính mới), việc ghi từng phần không phải là vấn đề.
Nhưng tôi đoán nếu chúng tôi bắt đầu đề xuất điều đó, thì "Tôi không biết dữ liệu bị hỏng như thế nào, tôi vừa đặt full_page_writes =tắt trên hệ thống!" sẽ trở thành một trong những câu phổ biến nhất ngay trước khi chết đối với các DBA (cùng với câu "Tôi đã nhìn thấy con rắn này trên reddit, nó không độc.").
Tóm tắt
Bạn không thể làm gì nhiều để điều chỉnh trực tiếp các bài viết trên toàn trang. Đối với hầu hết khối lượng công việc, hầu hết các lần ghi toàn trang xảy ra ngay sau một điểm kiểm tra, và sau đó biến mất cho đến điểm kiểm tra tiếp theo. Vì vậy, điều quan trọng là phải điều chỉnh các điểm kiểm tra để không xảy ra quá thường xuyên.
Một số quyết định cấp ứng dụng có thể làm tăng tính ngẫu nhiên của việc ghi vào bảng và chỉ mục - ví dụ:các giá trị UUID vốn dĩ là ngẫu nhiên, biến khối lượng công việc INSERT thậm chí đơn giản thành các bản cập nhật chỉ mục ngẫu nhiên. Lược đồ được sử dụng trong các ví dụ khá tầm thường - trong thực tế sẽ có chỉ mục phụ, khóa ngoại, v.v. Nhưng việc sử dụng khóa chính BIGSERIAL bên trong (và giữ UUID làm khóa thay thế) ít nhất sẽ làm giảm độ khuếch đại ghi.
Tôi thực sự muốn thảo luận về nhu cầu viết toàn trang trên các nhân / hệ thống tệp hiện tại. Rất tiếc, tôi không tìm thấy nhiều tài nguyên, vì vậy nếu bạn có thông tin liên quan, hãy cho tôi biết.