Hai lỗ hổng bảo mật nghiêm trọng (mã có tên Meltdown và Spectre) đã được tiết lộ vài tuần trước. Các thử nghiệm ban đầu cho thấy tác động đến hiệu suất của việc giảm nhẹ (được thêm vào trong nhân) có thể lên tới ~ 30% đối với một số khối lượng công việc, tùy thuộc vào tốc độ cuộc gọi tổng hợp.
Những ước tính ban đầu đó phải được thực hiện nhanh chóng, và do đó, dựa trên số lượng thử nghiệm hạn chế. Hơn nữa, các bản sửa lỗi trong nhân được phát triển và cải thiện theo thời gian và giờ đây chúng tôi cũng có retpoline mà sẽ giải quyết Spectre v2. Bài đăng này trình bày dữ liệu từ các bài kiểm tra kỹ lưỡng hơn, hy vọng cung cấp các ước tính đáng tin cậy hơn cho khối lượng công việc PostgreSQL điển hình.
So với đánh giá ban đầu về các bản sửa lỗi Meltdown mà Simon đã đăng lại vào ngày 10 tháng 1, dữ liệu được trình bày trong bài đăng này chi tiết hơn nhưng nhìn chung kết quả phù hợp được trình bày trong bài đăng đó.
Bài đăng này tập trung vào khối lượng công việc PostgreSQL và mặc dù nó có thể hữu ích cho các hệ thống khác có tỷ lệ chuyển đổi ngữ cảnh / syscall cao, nhưng chắc chắn bằng cách nào đó nó không được áp dụng phổ biến. Nếu bạn quan tâm đến lời giải thích tổng quát hơn về các lỗ hổng và đánh giá tác động, Brendan Gregg đã xuất bản một bài báo về KPTI / KAISER Meltdown Initial Performance Regressions một vài ngày trước. Trên thực tế, có thể hữu ích nếu bạn đọc trước và sau đó tiếp tục với bài đăng này.
Lưu ý: Bài đăng này không nhằm mục đích ngăn cản bạn cài đặt các bản sửa lỗi, nhưng để cung cấp cho bạn một số ý tưởng về tác động của hiệu suất có thể là gì. Bạn nên cài đặt tất cả các bản sửa lỗi để môi trường của bạn an toàn và sử dụng bài đăng này để quyết định xem bạn có thể cần nâng cấp phần cứng, v.v.
Chúng tôi sẽ thực hiện những bài kiểm tra nào?
Chúng ta sẽ xem xét hai loại khối lượng công việc cơ bản thông thường - OLTP (giao dịch đơn giản nhỏ) và OLAP (truy vấn phức tạp xử lý lượng lớn dữ liệu). Hầu hết các hệ thống PostgreSQL có thể được mô hình hóa dưới dạng kết hợp của hai loại khối lượng công việc này.
Đối với OLTP, chúng tôi đã sử dụng pgbench, một công cụ đo điểm chuẩn nổi tiếng được cung cấp cùng với PostgreSQL. Chúng tôi đã thử nghiệm cả ở chế độ chỉ đọc (-S ) và đọc-ghi (-N ), với ba tỷ lệ khác nhau - phù hợp với shared_buffers, vào RAM và lớn hơn RAM.
Đối với trường hợp OLAP, chúng tôi đã sử dụng điểm chuẩn dbt-3, khá gần với TPC-H, với hai kích thước dữ liệu khác nhau - 10GB phù hợp với RAM và 50GB lớn hơn RAM (xem xét chỉ mục, v.v.).
Tất cả các con số được trình bày đến từ một máy chủ với 2x Xeon E5-2620v4, 64GB RAM và Intel SSD 750 (400GB). Hệ thống đang chạy Gentoo với kernel 4.15.3, được biên dịch với GCC 7.3 (cần thiết để kích hoạt retpoline đầy đủ khắc phục). Các bài kiểm tra tương tự cũng được thực hiện trên hệ thống cũ hơn / nhỏ hơn với CPU i5-2500k, RAM 8GB và SSD Intel S3700 6x (trong RAID-0). Nhưng hành vi và kết luận khá giống nhau, vì vậy chúng tôi sẽ không trình bày dữ liệu ở đây.
Như chúng tôi gọi, các tập lệnh / kết quả hoàn chỉnh cho cả hai hệ thống đều có sẵn tại github.
Bài đăng này nói về tác động hiệu suất của việc giảm thiểu, vì vậy chúng ta đừng tập trung vào con số tuyệt đối và thay vào đó hãy xem xét hiệu suất liên quan đến hệ thống chưa được vá (không có giảm thiểu hạt nhân). Tất cả các biểu đồ trong phần OLTP đều hiển thị
(throughput with patches) / (throughput without patches)
Chúng tôi kỳ vọng các con số từ 0% đến 100%, với giá trị càng cao càng tốt (tác động giảm nhẹ thấp hơn), 100% nghĩa là “không ảnh hưởng”.
Lưu ý: Trục y bắt đầu ở 75%, để làm cho sự khác biệt rõ ràng hơn.
OLTP / chỉ đọc
Đầu tiên, hãy xem kết quả cho pgbench chỉ đọc, được thực thi bởi lệnh này
pgbench -n -c 16 -j 16 -S -T 1800 test
và được minh họa bằng biểu đồ sau:
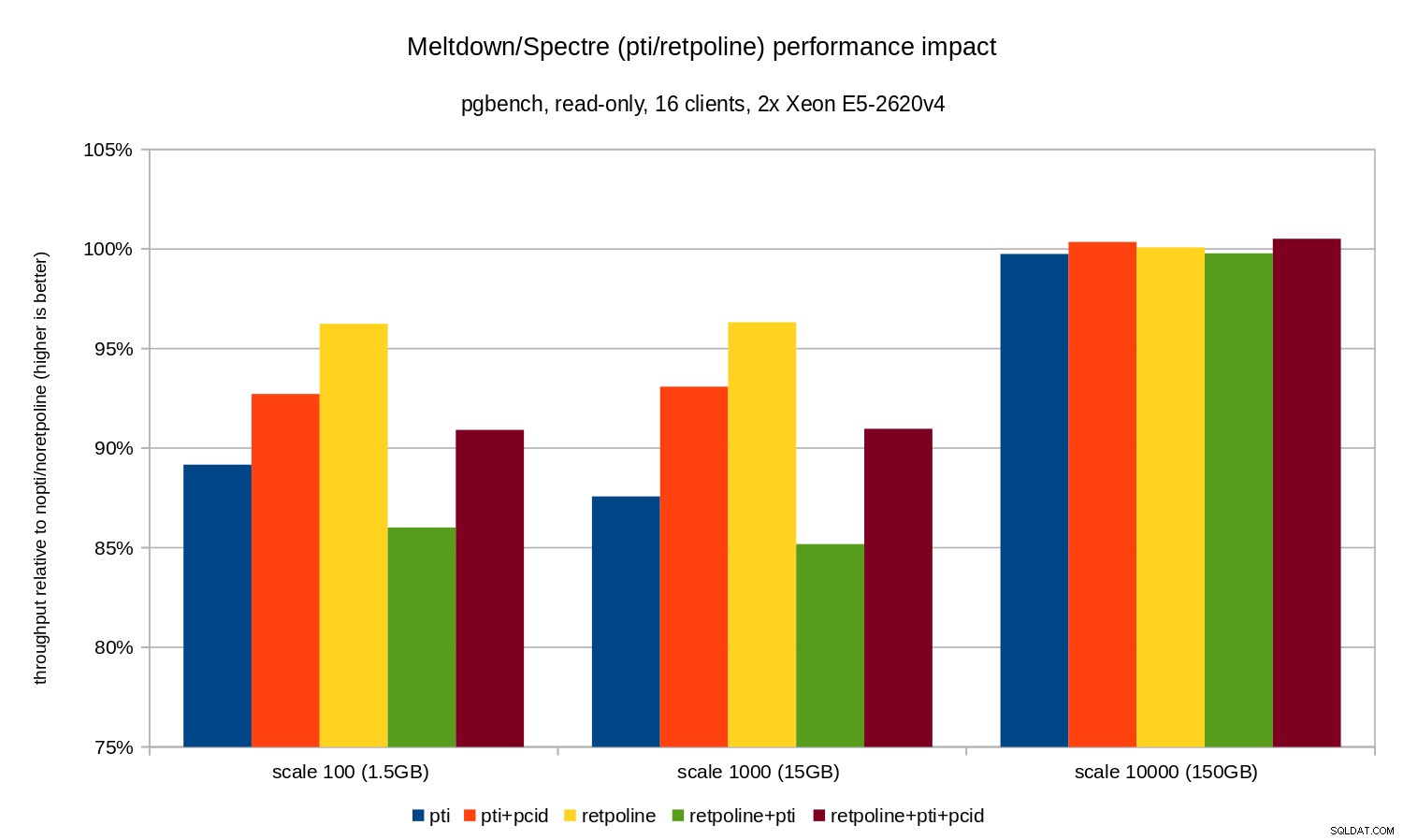
Như bạn có thể thấy, tác động hiệu suất của pti đối với tỷ lệ vừa với bộ nhớ là khoảng 10-12% và gần như không thể đo lường khi khối lượng công việc bị ràng buộc I / O. Hơn nữa, hồi quy giảm đáng kể (hoặc biến mất hoàn toàn) khi pcid được kích hoạt. Điều này nhất quán với tuyên bố rằng PCID hiện là một tính năng bảo mật / hiệu suất quan trọng trên x86. Tác động của retpoline nhỏ hơn nhiều - dưới 4% trong trường hợp xấu nhất, có thể dễ dàng do tiếng ồn.
OLTP / đọc-ghi
Các bài kiểm tra đọc-ghi được thực hiện bởi một pgbench lệnh tương tự như lệnh này:
pgbench -n -c 16 -j 16 -N -T 3600 test
Thời lượng đủ dài để bao gồm nhiều điểm kiểm tra và -N được sử dụng để loại bỏ tranh chấp về khóa trên các hàng trong bảng nhánh (nhỏ). Hiệu suất tương đối được minh họa bằng biểu đồ này:
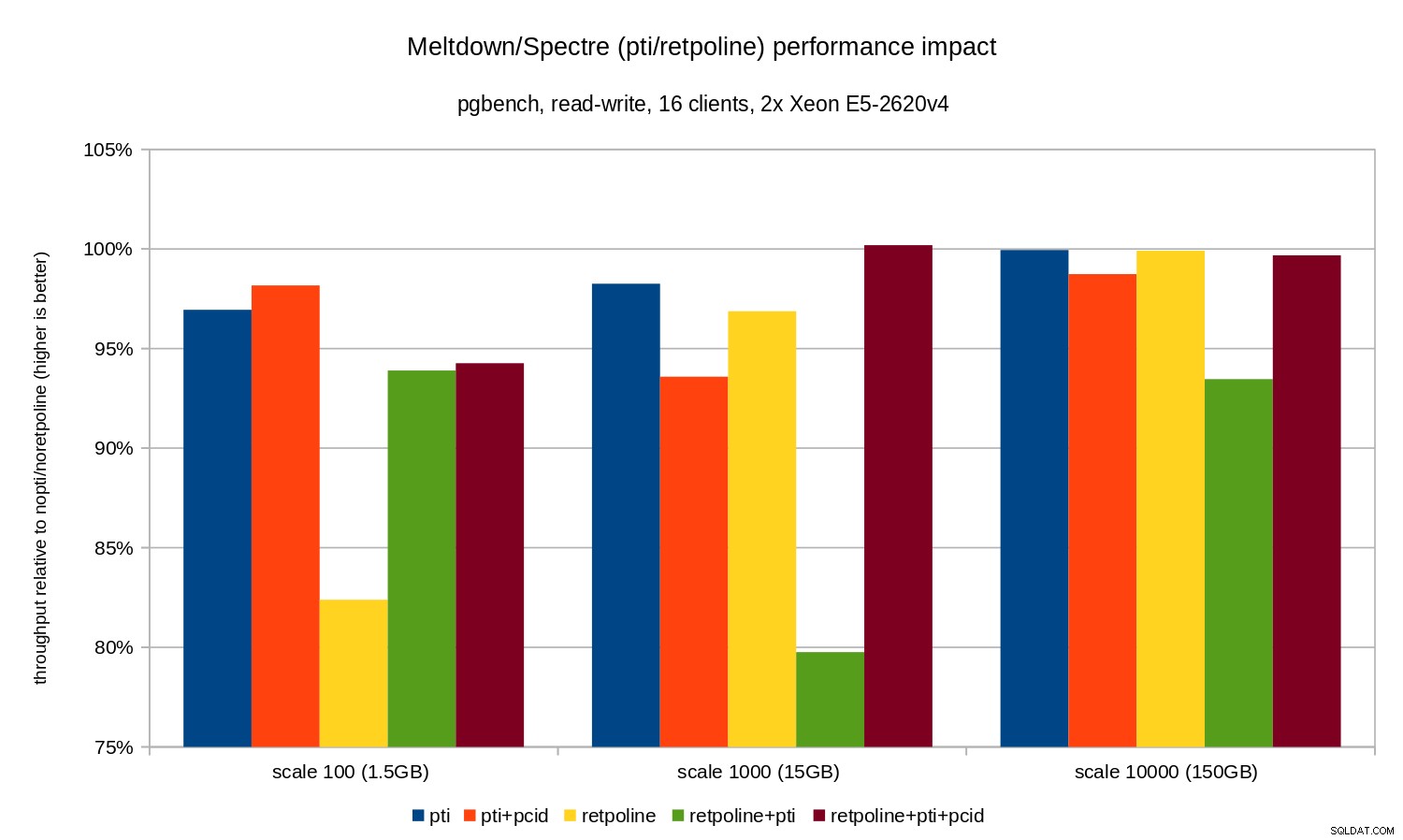
Các hồi quy nhỏ hơn một chút so với trường hợp chỉ đọc - ít hơn 8% mà không có pcid và ít hơn 3% với pcid đã được kích hoạt. Đây là hệ quả tự nhiên của việc dành nhiều thời gian hơn để thực hiện I / O trong khi ghi dữ liệu vào WAL, xả bộ đệm đã sửa đổi trong khi kiểm tra, v.v.
Tuy nhiên, có hai điều kỳ lạ. Thứ nhất, tác động của retpoline lớn bất ngờ (gần 20%) đối với thang điểm 100 và điều tương tự cũng xảy ra đối với retpoline+pti trên quy mô 1000. Nguyên nhân chưa rõ ràng và sẽ yêu cầu điều tra bổ sung.
OLAP
Khối lượng công việc phân tích được mô hình hóa bởi điểm chuẩn dbt-3. Đầu tiên, hãy xem kết quả quy mô 10GB, phù hợp hoàn toàn với RAM (bao gồm tất cả các chỉ mục, v.v.). Tương tự với OLTP, chúng tôi không thực sự quan tâm đến số tuyệt đối, trong trường hợp này sẽ là thời lượng cho các truy vấn riêng lẻ. Thay vào đó, chúng tôi sẽ xem xét sự chậm lại so với nopti/noretpoline , đó là:
(duration without patches) / (duration with patches)
Giả sử việc giảm nhẹ dẫn đến giảm tốc độ, chúng tôi sẽ nhận được các giá trị từ 0% đến 100%, trong đó 100% có nghĩa là "không có tác động". Kết quả như sau:
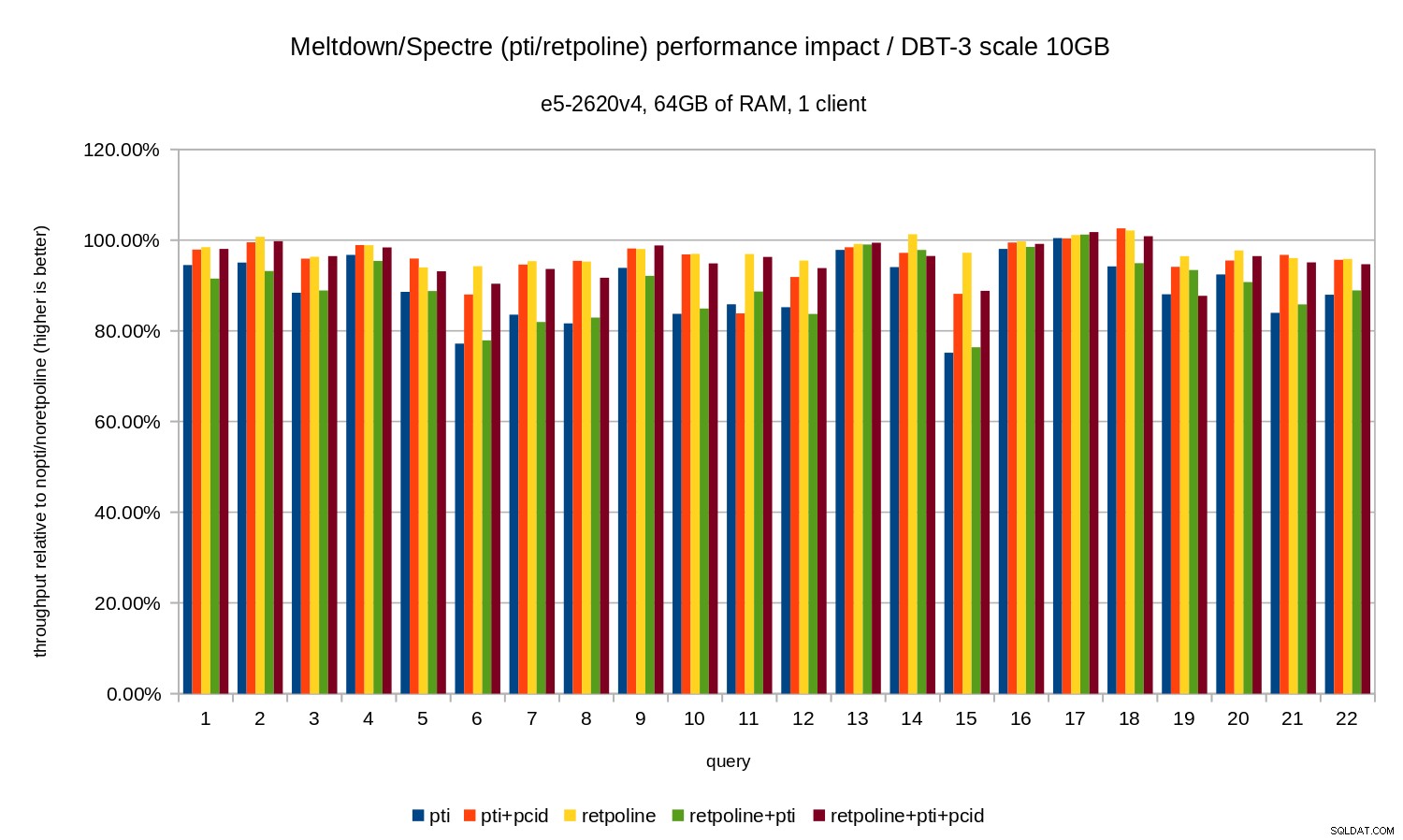
Đó là, không có pcid hồi quy thường nằm trong phạm vi 10-20%, tùy thuộc vào truy vấn. Và với pcid hồi quy giảm xuống dưới 5% (và thường gần bằng 0%). Một lần nữa, điều này khẳng định tầm quan trọng của pcid tính năng.
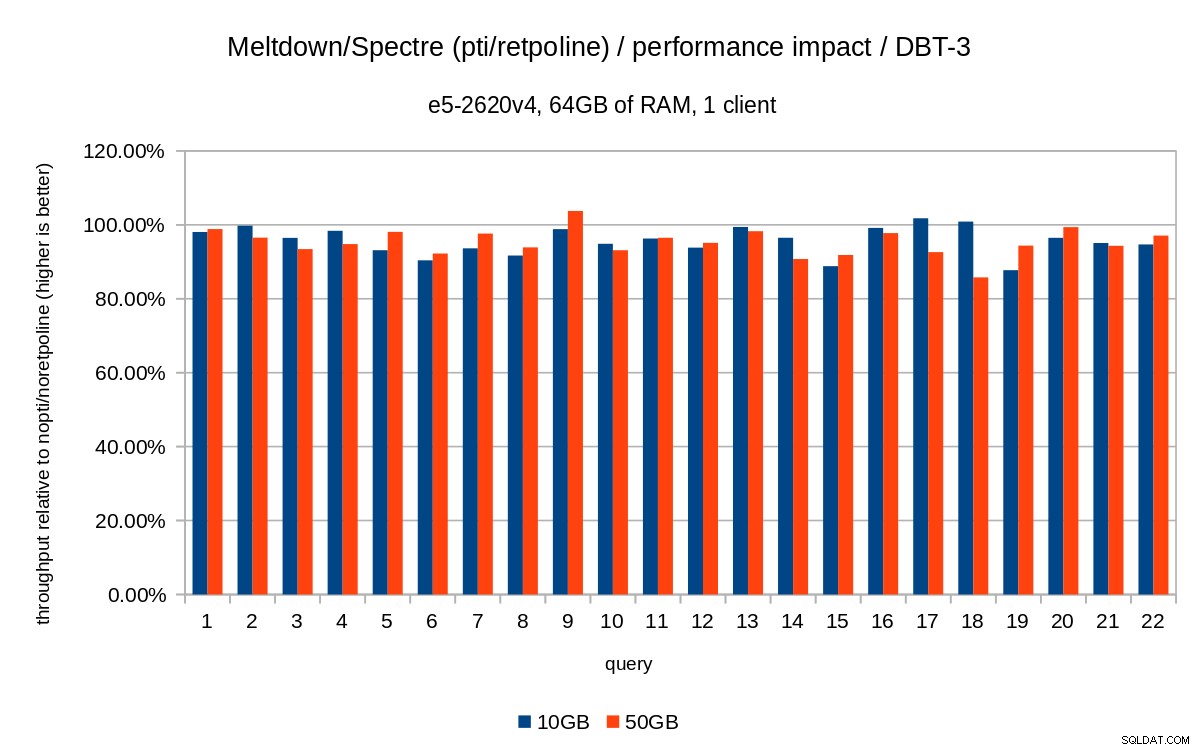
Đối với tập dữ liệu 50GB (khoảng 120GB với tất cả các chỉ mục, v.v.), tác động như sau:
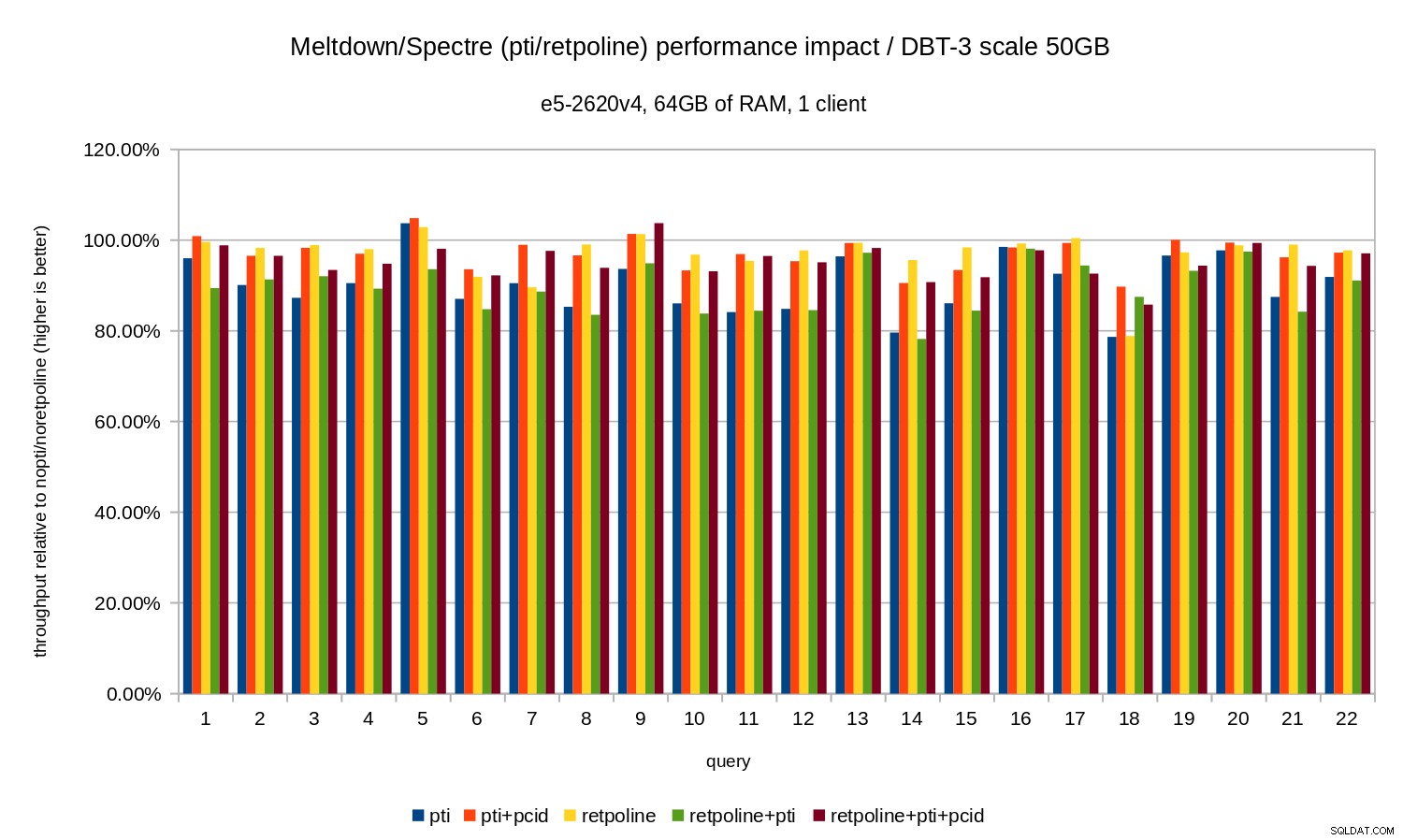
Vì vậy, giống như trong trường hợp 10GB, các hồi quy dưới 20% và pcid giảm đáng kể chúng - gần bằng 0% trong hầu hết các trường hợp.
Các biểu đồ trước đó hơi lộn xộn - có 22 truy vấn và 5 chuỗi dữ liệu, hơi quá nhiều so với một biểu đồ duy nhất. Vì vậy, đây là biểu đồ chỉ cho thấy tác động đối với cả ba tính năng (pti , pcid và retpoline ), cho cả hai kích thước tập dữ liệu.
Kết luận
Tóm tắt ngắn gọn kết quả:
-
retpolinecó rất ít tác động đến hiệu suất - OLTP - hồi quy khoảng 10-15% mà không có
pcidvà khoảng 1-5% vớipcid. - OLAP - hồi quy lên đến 20% mà không có
pcidvà khoảng 1-5% vớipcid. - Đối với khối lượng công việc ràng buộc I / O (ví dụ:OLTP với tập dữ liệu lớn nhất), Meltdown có tác động không đáng kể.
Tác động dường như thấp hơn nhiều so với ước tính ban đầu cho thấy (30%), ít nhất là đối với khối lượng công việc đã thử nghiệm. Nhiều hệ thống đang hoạt động ở 70-80% CPU vào thời kỳ cao điểm và 30% sẽ bão hòa hoàn toàn dung lượng CPU. Nhưng trên thực tế, tác động dường như dưới 5%, ít nhất là khi pcid tùy chọn được sử dụng.
Đừng hiểu sai ý tôi, mức giảm 5% vẫn là một sự thụt lùi nghiêm trọng. Đó chắc chắn là điều chúng tôi sẽ quan tâm trong quá trình phát triển PostgreSQL, ví dụ:khi đánh giá tác động của các bản vá được đề xuất. Nhưng đó là điều mà các hệ thống hiện có sẽ xử lý tốt - nếu mức sử dụng CPU tăng 5% giúp hệ thống của bạn vượt qua ví dụ, bạn sẽ gặp sự cố ngay cả khi không có Meltdown / Spectre.
Rõ ràng, đây không phải là phần cuối của các bản sửa lỗi Meltdown / Spectre. Các nhà phát triển hạt nhân vẫn đang làm việc để cải thiện các biện pháp bảo vệ và bổ sung các biện pháp bảo vệ mới, đồng thời Intel và các nhà sản xuất CPU khác đang làm việc trên các bản cập nhật vi mã. Và không phải chúng ta biết về tất cả các biến thể có thể có của lỗ hổng bảo mật, vì các nhà nghiên cứu đã cố gắng tìm ra các biến thể mới của các cuộc tấn công.
Vì vậy, sẽ còn nhiều điều nữa và sẽ rất thú vị khi xem tác động đến hiệu suất sẽ như thế nào.



