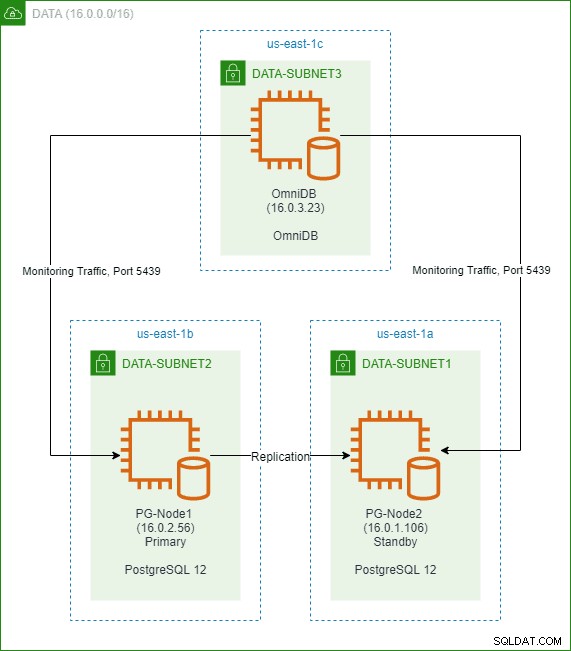
Trong phần trước của loạt bài này, chúng tôi đã tạo một cụm PostgreSQL 12 hai nút trong đám mây AWS. Chúng tôi cũng đã cài đặt và định cấu hình 2ndQuadrant OmniDB trong một nút thứ ba. Hình ảnh dưới đây cho thấy kiến trúc:
Chúng tôi có thể kết nối với cả nút chính và nút chờ từ giao diện người dùng dựa trên web của OmniDB. Sau đó, chúng tôi khôi phục cơ sở dữ liệu mẫu có tên “dvdrental” trong nút chính bắt đầu sao chép sang chế độ chờ.
Trong phần này của loạt bài, chúng ta sẽ tìm hiểu cách tạo và sử dụng bảng điều khiển giám sát trong OmniDB. Các DBA và nhóm vận hành thường thích các công cụ đồ họa hơn là các truy vấn phức tạp để kiểm tra tình trạng cơ sở dữ liệu một cách trực quan. OmniDB đi kèm với một số tiện ích quan trọng có thể dễ dàng sử dụng trong bảng điều khiển giám sát. Như chúng ta sẽ thấy ở phần sau, nó cũng cho phép người dùng viết các tiện ích giám sát của riêng họ.
Xây dựng Trang tổng quan Giám sát Hiệu suất
Hãy bắt đầu với trang tổng quan mặc định đi kèm với OmniDB.
Trong hình ảnh bên dưới, chúng tôi được kết nối với nút chính (PG-Node1). Chúng tôi nhấp chuột phải vào tên phiên bản, sau đó từ menu bật lên, chọn “Màn hình” và sau đó chọn “Trang tổng quan”.
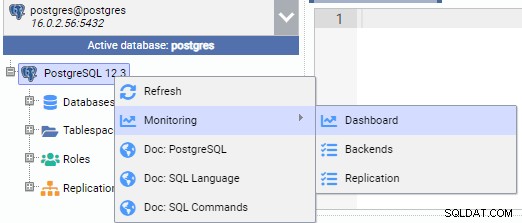
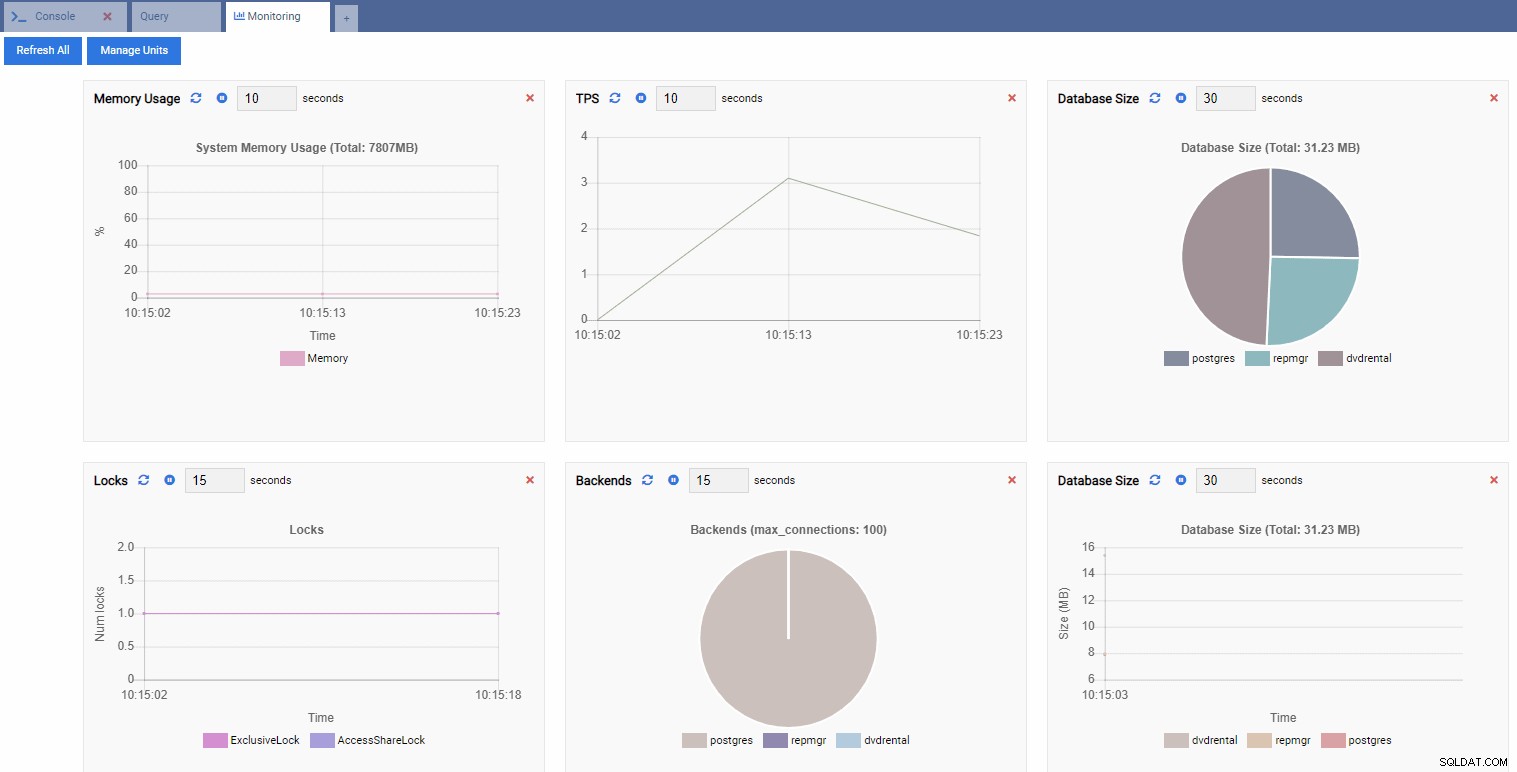
Thao tác này sẽ mở ra một trang tổng quan với một số tiện ích trong đó.
Theo thuật ngữ OmniDB, các tiện ích con hình chữ nhật trong trang tổng quan được gọi là Đơn vị giám sát . Mỗi đơn vị trong số này hiển thị một số liệu cụ thể từ phiên bản PostgreSQL mà nó được kết nối và tự động làm mới dữ liệu của nó.
Tìm hiểu các Đơn vị Giám sát
OmniDB đi kèm với bốn loại Đơn vị Giám sát:
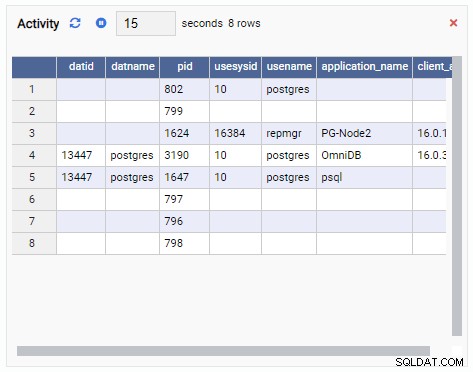
- Một Lưới là một cấu trúc dạng bảng hiển thị kết quả của một truy vấn. Ví dụ, đây có thể là đầu ra của SELECT * FROM pg_stat_replication. Lưới trông như thế này:
- Một Biểu đồ hiển thị dữ liệu ở định dạng đồ họa, như đường hoặc biểu đồ hình tròn. Khi nó làm mới, toàn bộ biểu đồ sẽ được vẽ lại trên màn hình với một giá trị mới và giá trị cũ sẽ biến mất. Với các Đơn vị giám sát này, chúng tôi chỉ có thể thấy giá trị hiện tại của chỉ số. Đây là một ví dụ về Biểu đồ:
- A Nối biểu đồ cũng là một Đơn vị giám sát loại biểu đồ, ngoại trừ khi làm mới, nó sẽ thêm giá trị mới vào chuỗi hiện có. Với Chart-Append, chúng ta có thể dễ dàng xem các xu hướng theo thời gian. Đây là một ví dụ:
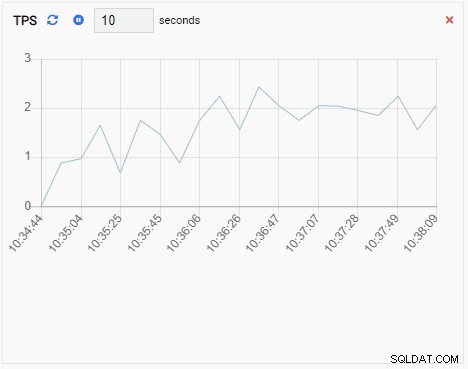
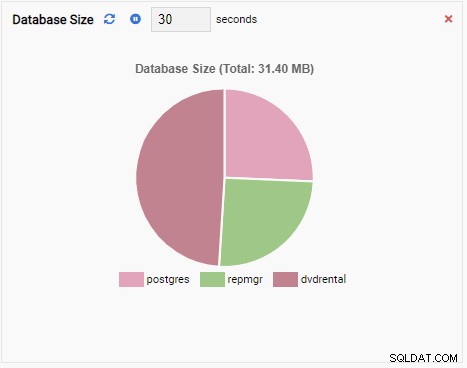
- A Biểu đồ hiển thị mối quan hệ giữa các phiên bản cụm PostgreSQL và một số liệu liên quan. Giống như Đơn vị Giám sát Biểu đồ, Đơn vị Giám sát Biểu đồ cũng làm mới giá trị cũ của nó bằng một giá trị mới. Hình ảnh bên dưới cho thấy nút hiện tại (PG-Node1) đang sao chép sang PG-Node2:
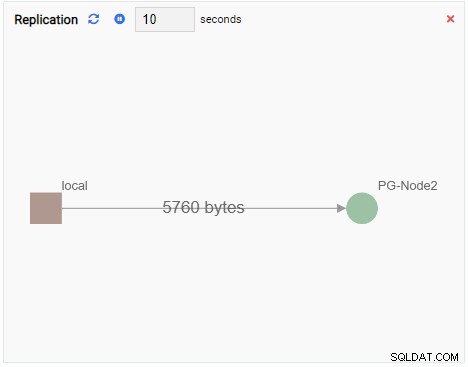
Mỗi Đơn vị Giám sát đều có một số yếu tố chung:
- Tên Đơn vị Giám sát
- Nút "làm mới" để làm mới thiết bị theo cách thủ công
- Nút "tạm dừng" để tạm thời dừng làm mới Thiết bị Giám sát
- Một hộp văn bản hiển thị khoảng thời gian làm mới hiện tại. Điều này có thể được thay đổi
- Nút "đóng" (dấu thập đỏ) để xóa Thiết bị Giám sát khỏi trang tổng quan
- Khu vực bản vẽ thực tế của Giám sát
Đơn vị giám sát được xây dựng sẵn
OmniDB đi kèm với một số Đơn vị giám sát cho PostgreSQL mà chúng tôi có thể thêm vào trang tổng quan của mình. Để truy cập các đơn vị này, chúng tôi nhấp vào nút “Quản lý Đơn vị” ở đầu trang tổng quan:
Thao tác này sẽ mở ra danh sách "Quản lý đơn vị":
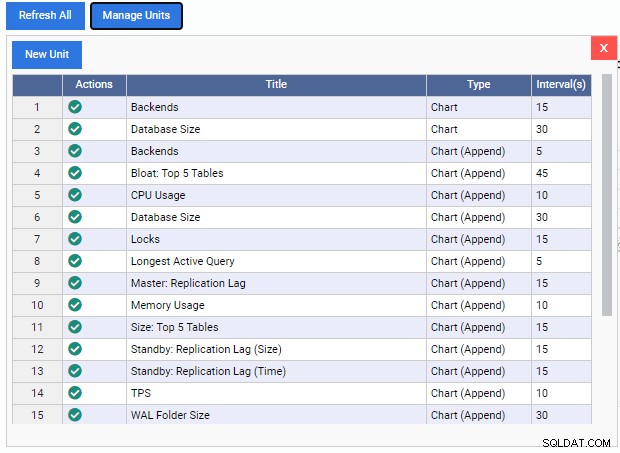
Như chúng ta có thể thấy, có rất ít Đơn vị Giám sát được xây dựng trước ở đây. Bạn có thể tải xuống miễn phí mã cho các Đơn vị giám sát này từ kho lưu trữ GitHub của 2ndQuadrant. Mỗi đơn vị được liệt kê ở đây hiển thị tên, loại (Biểu đồ, Nối biểu đồ, Biểu đồ hoặc Lưới) và tốc độ làm mới mặc định.
Để thêm Đơn vị giám sát vào trang tổng quan, chúng ta chỉ cần nhấp vào dấu tích màu xanh lục bên dưới cột “Hành động” cho đơn vị đó. Chúng tôi có thể kết hợp và kết hợp các Đơn vị giám sát khác nhau để xây dựng bảng điều khiển mà chúng tôi muốn.
Trong hình ảnh bên dưới, chúng tôi đã thêm các đơn vị sau cho trang tổng quan giám sát hiệu suất của mình và xóa mọi thứ khác:
TPS (giao dịch mỗi giây):
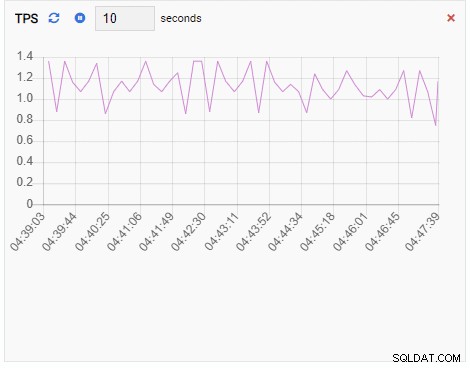
Số lượng khóa:
Số lượng phụ trợ:
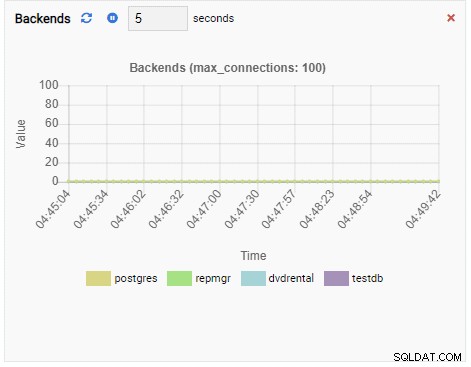
Vì phiên bản của chúng tôi không hoạt động, chúng tôi có thể thấy các giá trị TPS, Locks và Backends là tối thiểu.
Kiểm tra Trang tổng quan Giám sát
Bây giờ chúng tôi sẽ chạy pgbench trong nút chính của chúng tôi (PG-Node1). pgbench là một công cụ đo điểm chuẩn đơn giản đi kèm với PostgreSQL. Giống như hầu hết các công cụ khác cùng loại, pgbench tạo một lược đồ và bảng của hệ thống OLTP mẫu trong cơ sở dữ liệu khi nó khởi tạo. Sau đó, nó có thể mô phỏng nhiều kết nối máy khách, mỗi kết nối chạy một số giao dịch trên cơ sở dữ liệu. Trong trường hợp này, chúng tôi sẽ không đo điểm chuẩn cho nút chính của PostgreSQL; chúng tôi sẽ chỉ tạo cơ sở dữ liệu cho pgbench và xem liệu các Đơn vị giám sát bảng điều khiển của chúng tôi có nhận ra thay đổi về tình trạng hệ thống hay không.
Đầu tiên, chúng tôi đang tạo cơ sở dữ liệu cho pgbench trong nút chính:
[example@sqldat.com ~] $ psql -h PG-Node1 -U postgres -c "TẠO CƠ SỞ DỮ LIỆU testdb"; TẠO CƠ SỞ DỮ LIỆU
Tiếp theo, chúng tôi đang khởi tạo cơ sở dữ liệu “testdb” cho pgbench:
[example@sqldat.com ~] $ / usr / pgsql-12 / bin / pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbdropping the old table ... create table ... Đang tạo dữ liệu ... 100000 trong số 2000000 bộ dữ liệu (5%) đã hoàn thành (trôi qua 0,02 giây, còn lại 0,43 giây) 200000 trong số 2000000 bộ dữ liệu (10%) đã hoàn thành (trôi qua 0,05 giây, còn lại 0,41 giây) …… 2000000 trong số 2000000 bộ dữ liệu (100%) đã xong (trôi qua 1,84 giây, còn lại 0,00 giây) hút bụi ... tạo khóa chính ... xong.
Với cơ sở dữ liệu được khởi tạo, bây giờ chúng ta bắt đầu quá trình tải thực tế. Trong đoạn mã bên dưới, chúng tôi yêu cầu pgbench bắt đầu với 50 kết nối máy khách đồng thời dựa trên cơ sở dữ liệu testdb, mỗi kết nối chạy 100000 giao dịch trên các bảng của nó. Kiểm tra tải sẽ chạy trên hai chuỗi.
[example@sqldat.com ~] $ / usr / pgsql-12 / bin / pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbstarting chân không ... kết thúc. ……Nếu bây giờ chúng ta quay lại trang tổng quan OmniDB của mình, chúng ta thấy các Đơn vị giám sát đang hiển thị một số kết quả rất khác.
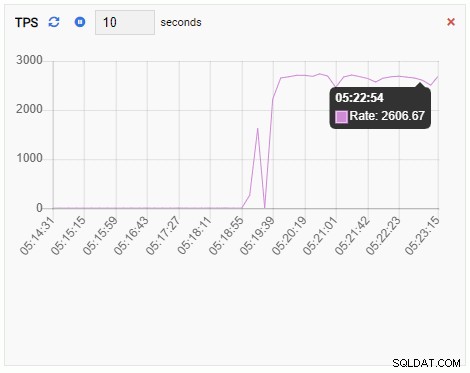
Chỉ số TPS đang cho thấy giá trị khá cao. Có một bước nhảy đột ngột từ dưới 2 lên hơn 2000:
Số lượng phụ trợ đã tăng lên. Như mong đợi, testdb có 50 kết nối chống lại nó trong khi các cơ sở dữ liệu khác không hoạt động:
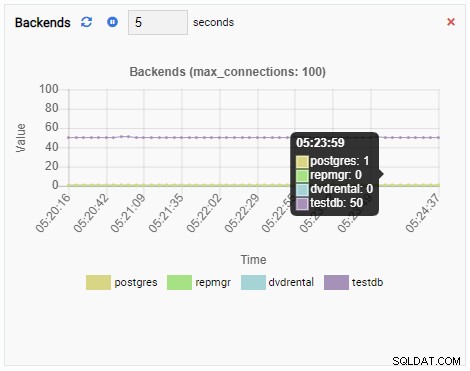
Và cuối cùng, số lượng khóa dành riêng cho hàng trong cơ sở dữ liệu testdb cũng cao:
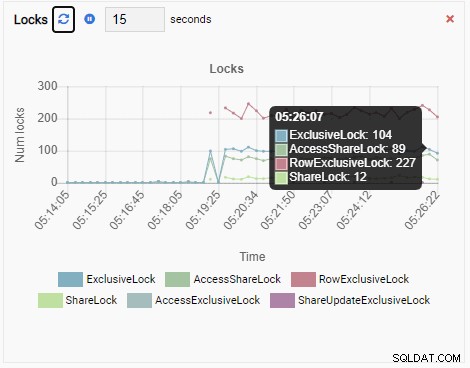
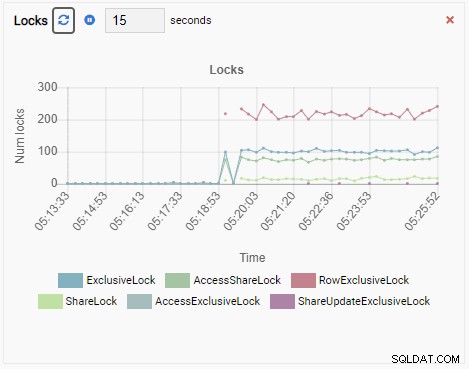
Bây giờ hãy tưởng tượng điều này. Bạn là một DBA và bạn sử dụng OmniDB để quản lý một nhóm các phiên bản PostgreSQL. Bạn nhận được một cuộc gọi để điều tra hiệu suất chậm trong một trong các trường hợp.
Sử dụng trang tổng quan như trang chúng ta vừa thấy (mặc dù nó rất đơn giản), bạn có thể dễ dàng tìm ra nguyên nhân gốc rễ. Bạn có thể kiểm tra số lượng phần mềm phụ trợ, ổ khóa, bộ nhớ khả dụng, v.v. để xem điều gì đang gây ra sự cố.
Và đó là lúc OmniDB có thể trở thành một công cụ thực sự hữu ích.
Tạo đơn vị giám sát tùy chỉnh
Đôi khi chúng tôi sẽ cần tạo các Đơn vị Giám sát của riêng mình. Để viết Đơn vị giám sát mới, chúng tôi nhấp vào nút “Đơn vị mới” trong danh sách “Quản lý đơn vị”. Thao tác này sẽ mở ra một tab mới với khung trống để viết mã:
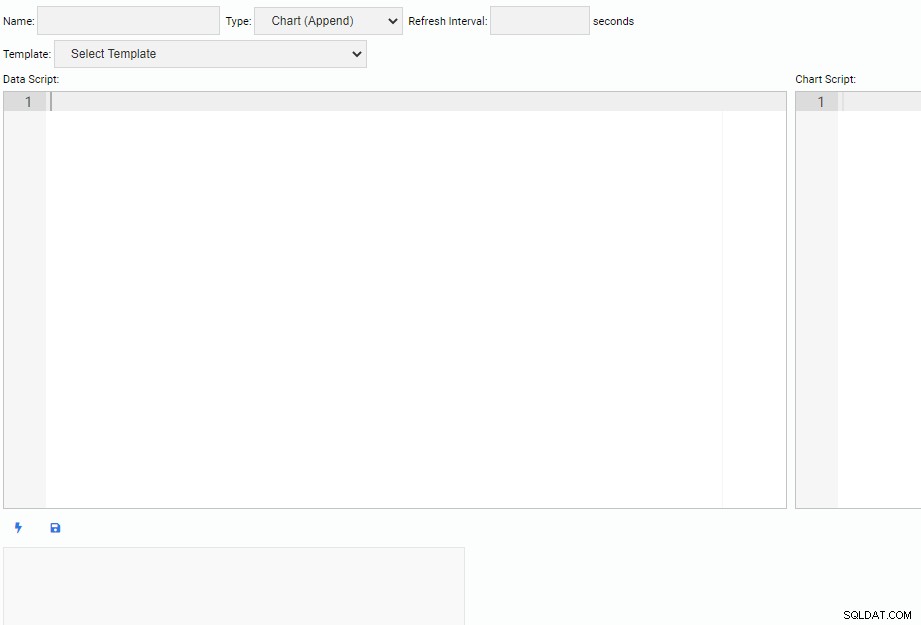
Ở đầu màn hình, chúng ta phải chỉ định tên cho Đơn vị giám sát của mình, chọn loại của nó và chỉ định khoảng thời gian làm mới mặc định của nó. Chúng tôi cũng có thể chọn một đơn vị hiện có làm mẫu.
Dưới phần tiêu đề, có hai hộp văn bản. Trình chỉnh sửa “Tập lệnh dữ liệu” là nơi chúng tôi viết mã để lấy dữ liệu cho Đơn vị giám sát của chúng tôi. Mỗi khi một đơn vị được làm mới, mã tập lệnh dữ liệu sẽ chạy. Trình chỉnh sửa “Tập lệnh biểu đồ” là nơi chúng tôi viết mã để vẽ đơn vị thực tế. Điều này được chạy khi đơn vị được vẽ lần đầu tiên.
Tất cả mã tập lệnh dữ liệu được viết bằng Python. Đối với Đơn vị giám sát loại biểu đồ, OmniDB cần tập lệnh biểu đồ được viết trong Chart.js.
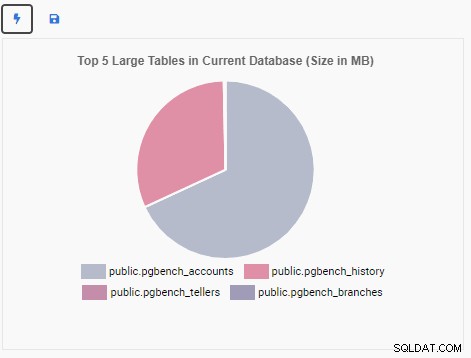
Bây giờ chúng tôi sẽ tạo một Đơn vị Giám sát để hiển thị 5 bảng lớn hàng đầu trong cơ sở dữ liệu hiện tại. Dựa trên cơ sở dữ liệu được chọn trong OmniDB, Đơn vị Giám sát sẽ thay đổi cách hiển thị của nó để phản ánh tên của năm bảng lớn nhất trong cơ sở dữ liệu đó.
Để viết một Unit mới, tốt nhất là bắt đầu với một mẫu hiện có và sửa đổi mã của nó. Điều này sẽ tiết kiệm cả thời gian và công sức. Trong hình ảnh sau đây, chúng tôi đã đặt tên cho Đơn vị Giám sát của mình là “5 Bàn lớn hàng đầu”. Chúng tôi đã chọn nó thuộc loại Biểu đồ (Không có Nối) và cung cấp tốc độ làm mới là 30 giây. Chúng tôi cũng đã dựa trên Đơn vị Giám sát của chúng tôi dựa trên mẫu Kích thước Cơ sở dữ liệu:
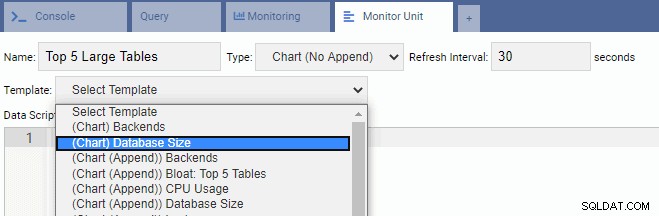
Hộp văn bản Tập lệnh Dữ liệu được tự động điền mã cho Đơn vị Giám sát Kích thước Cơ sở dữ liệu:
from datetime import datetimefrom random import randintdatabases =connect.Query ('' 'SELECT d.datname AS datname, round (pg_catalog.pg_database_size (d.datname) /1048576.0,2) AS kích thước TỪ pg_catalog.pg_database d WHERE d. tên dữ liệu không có trong ('template0', 'template1') '' ') data =[] color =[] label =[] cho db trong cơ sở dữ liệu.Rows:data.append (db ["size"]) color.append ( "rgb (" + str (randint (125, 225)) + "," + str (randint (125, 225)) + "," + str (randint (125, 225)) + ")") label.append (db ["datname"]) total_size =connection.ExecuteScalar ('' 'SELECT round (sum (pg_catalog.pg_database_size (datname) /1048576.0), 2) TỪ pg_catalog.pg_database KHÔNG PHẢI datistemplate' '') result ={"nhãn ":label," datasets ":[{" data ":data," backgroundColor ":color," label ":" Dataset 1 "}]," title ":" Kích thước Cơ sở dữ liệu (Tổng:"+ str (total_size) + "MB)"}Và hộp văn bản Tập lệnh Biểu đồ cũng được điền bằng mã:
total_size =connect.ExecuteScalar ('' 'SELECT round (sum (pg_catalog.pg_database_size (datname) /1048576.0), 2) TỪ pg_catalog.pg_database KHÔNG PHẢI datistemplate' '') result ={"type":"pie" , "Data":Không có, "options":{"responsive":True, "title":{"display":True, "text":"Database Size (Total:" + str (total_size) + "MB)" }}}Chúng ta có thể sửa đổi Tập lệnh Dữ liệu để có được 5 bảng lớn hàng đầu trong cơ sở dữ liệu. Trong tập lệnh bên dưới, chúng tôi đã giữ hầu hết mã gốc, ngoại trừ câu lệnh SQL:
from datetime import datetimefrom random import randinttables =connect.Query ('' 'SELECT nspname ||'. '|| relname AS "tablename", round (pg_catalog.pg_total_relation_size (c.oid) /1048576.0,2) AS " table_size "TỪ pg_class C TRÁI THAM GIA pg_namespace N BẬT (N.oid =C.relnamespace) TẠI ĐÂU nspname KHÔNG CÓ TRONG ('pg_catalog', 'information_schema') VÀ C.relkind <> 'i' VÀ nspname! ~ '^ pg_toast' ORDER BY 2 DESC LIMIT 5; '' ') data =[] color =[] label =[] cho bảng trong các bảng.Rows:data.append (table ["table_size"]) color.append ("rgb (" + str (randint (125, 225)) + "," + str (randint (125, 225)) + "," + str (randint (125, 225)) + ")") label.append (table ["tên bảng" " ]) result ={"label":label, "datasets":[{"data":data, "backgroundColor":color, "label":"Top 5 Bảng Lớn"}]}Ở đây, chúng tôi đang nhận kích thước kết hợp của mỗi bảng và các chỉ mục của nó trong cơ sở dữ liệu hiện tại. Chúng tôi đang sắp xếp các kết quả theo thứ tự giảm dần và chọn năm hàng trên cùng.
Tiếp theo, chúng tôi đang điền ba mảng Python bằng cách lặp qua tập kết quả.
Cuối cùng, chúng tôi đang xây dựng một chuỗi JSON dựa trên các giá trị của mảng.
Trong hộp văn bản Tập lệnh Biểu đồ, chúng tôi đã sửa đổi mã để loại bỏ lệnh SQL ban đầu. Ở đây, chúng tôi chỉ xác định khía cạnh thẩm mỹ của biểu đồ. Chúng tôi đang xác định biểu đồ là loại hình tròn và cung cấp tiêu đề cho nó:
result ={"type":"pie", "data":Không có, "tùy chọn":{"responsive":True, "title":{"display":True, "text":"Top 5 Large Các bảng trong Cơ sở dữ liệu Hiện tại (Kích thước tính bằng MB) "}}}Bây giờ chúng ta có thể kiểm tra thiết bị bằng cách nhấp vào biểu tượng tia chớp. Điều này sẽ hiển thị Đơn vị giám sát mới trong khu vực bản vẽ xem trước:
Tiếp theo, chúng tôi lưu đơn vị bằng cách nhấp vào biểu tượng đĩa. Một hộp thông báo xác nhận đơn vị đã được lưu:

Bây giờ chúng tôi quay lại trang tổng quan giám sát của mình và thêm Đơn vị giám sát mới:
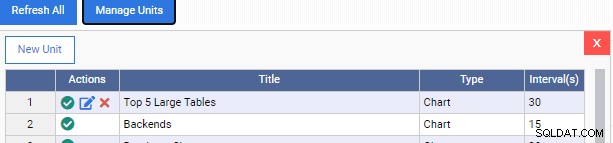
Lưu ý cách chúng tôi có thêm hai biểu tượng trong cột "Hành động" cho Đơn vị Giám sát tùy chỉnh của chúng tôi. Một là để chỉnh sửa nó, cái kia là để xóa nó khỏi OmniDB.
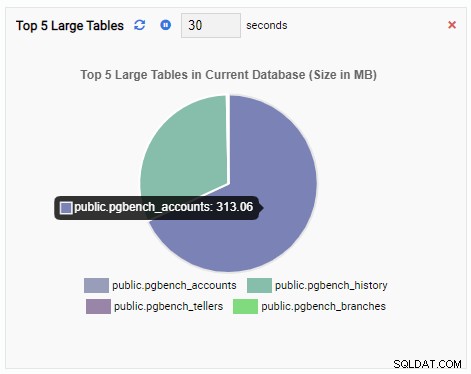
Đơn vị Giám sát “5 bảng lớn hàng đầu” hiện hiển thị năm bảng lớn nhất trong cơ sở dữ liệu hiện tại:
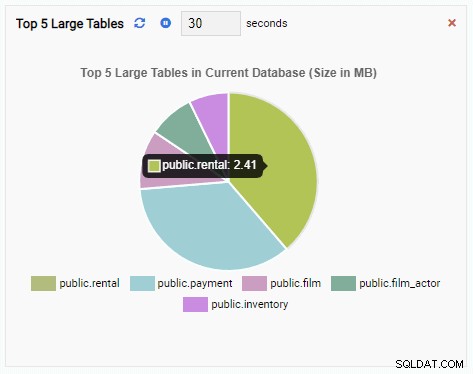
Nếu chúng tôi đóng trang tổng quan, chuyển sang cơ sở dữ liệu khác từ ngăn điều hướng và mở lại trang tổng quan, chúng tôi sẽ thấy Đơn vị giám sát đã thay đổi để phản ánh các bảng của cơ sở dữ liệu đó:
Lời cuối cùng
Phần này kết thúc loạt bài gồm hai phần của chúng tôi về OmniDB. Như chúng ta đã thấy, OmniDB có một số Đơn vị giám sát tiện lợi mà DBA PostgreSQL sẽ thấy hữu ích cho việc theo dõi hiệu suất. Chúng tôi đã thấy cách chúng tôi có thể sử dụng các đơn vị này để xác định các tắc nghẽn tiềm ẩn trong máy chủ. Chúng tôi cũng đã biết cách tạo các đơn vị tùy chỉnh của riêng mình. Người đọc được khuyến khích tạo và thử nghiệm Đơn vị giám sát hiệu suất cho khối lượng công việc cụ thể của họ. 2ndQuadrant hoan nghênh mọi đóng góp cho repo GitHub của Đơn vị giám sát OmniDB.