Xin lưu ý:Các phần của blog chứa các tài liệu tham khảo và ví dụ từ "CÔNG BỐ SN SÀNG CỦA POSTGRESQL MỨC ĐỘ BẢO HIỂM" của CyberTec, một công ty cung cấp hỗ trợ, tư vấn và đào tạo cho PostgreSQL.
Các tổ chức xử lý các loại dữ liệu khác nhau bao gồm thông tin rất quan trọng cần được lưu trữ trong cơ sở dữ liệu. Bảo mật là một khía cạnh quan trọng cần xem xét để đảm bảo dữ liệu nhạy cảm như hồ sơ y tế và các giao dịch tài chính không bị rơi vào tay những người có hành vi bất chính. Trong nhiều năm, các nhà phát triển đưa ra nhiều biện pháp để cải thiện tính toàn vẹn và bảo vệ dữ liệu. Một trong những kỹ thuật được sử dụng nhiều nhất là mã hóa để ngăn chặn vi phạm dữ liệu.
Dù bạn có thể đã sử dụng các biện pháp bảo vệ phức tạp, một số người vẫn có thể truy cập vào hệ thống của bạn. Mã hóa là một lớp bảo mật bổ sung. PostgreSQL cung cấp mã hóa ở các cấp độ khác nhau bên cạnh việc cung cấp tính linh hoạt trong việc bảo vệ dữ liệu khỏi bị tiết lộ do quản trị viên không đáng tin cậy, kết nối mạng không an toàn và máy chủ cơ sở dữ liệu bị đánh cắp. PostgreSQL cung cấp các tùy chọn mã hóa khác nhau như:
- Xác thực máy chủ SSL
- Mã hóa dữ liệu trên một mạng
- Mã hóa phân vùng dữ liệu
- Mã hóa cho các cột cụ thể
- Mã hóa lưu trữ mật khẩu
- Mã hóa phía máy khách
Tuy nhiên, bạn sử dụng chiến lược mã hóa càng phức tạp thì khả năng bạn bị khóa dữ liệu của mình càng lớn. Bên cạnh đó, quá trình đọc sẽ không chỉ khó khăn mà còn đòi hỏi nhiều tài nguyên để truy vấn và giải mã. Tùy chọn mã hóa bạn chọn phụ thuộc vào bản chất của dữ liệu bạn đang xử lý về độ nhạy. Sơ đồ dưới đây minh họa quy trình tổng thể của mã hóa và giải mã dữ liệu trong các giao dịch máy chủ.
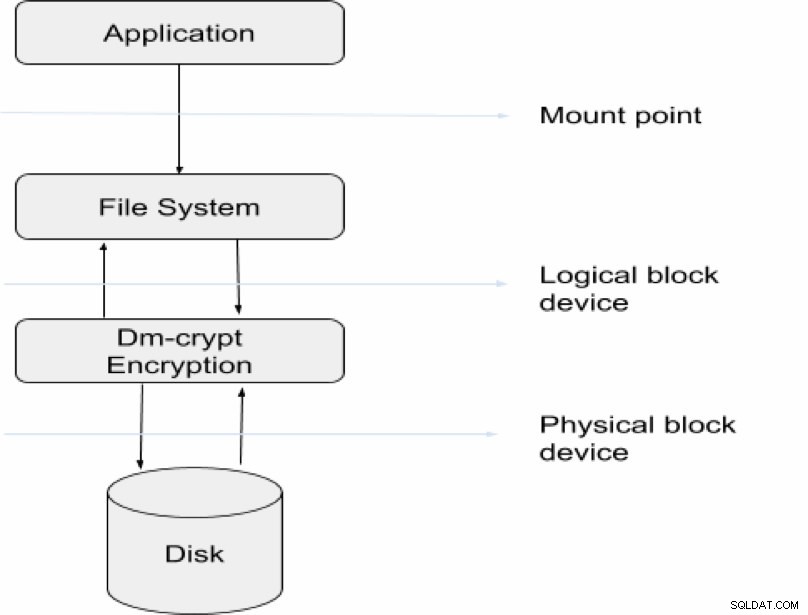
Bài viết này thảo luận về các cách khác nhau trong đó doanh nghiệp có thể bảo mật thông tin nhạy cảm nhưng điểm quan tâm chính sẽ là mã hóa mức cá thể đã được đề cập trước đó.
Mã hóa
Mã hóa là thực hành mã hóa dữ liệu để dữ liệu không còn ở định dạng ban đầu và không thể đọc được. Có 2 loại dữ liệu liên quan đến cơ sở dữ liệu:dữ liệu ở trạng thái nghỉ và dữ liệu đang chuyển động. Khi dữ liệu được lưu trữ trong cơ sở dữ liệu, nó được coi là dữ liệu ở trạng thái nghỉ. Mặt khác, nếu một máy khách, ví dụ, gửi một yêu cầu đến cơ sở dữ liệu, nếu một số dữ liệu được trả lại và cần đến máy khách, thì nó được gọi là dữ liệu đang chuyển động. Hai loại dữ liệu khác nhau cần được bảo vệ bằng công nghệ tương tự. Ví dụ:nếu một ứng dụng được phát triển mà người dùng cần gửi mật khẩu, mật khẩu này sẽ không được lưu trữ trong cơ sở dữ liệu dưới dạng văn bản thuần túy. Có một số quy trình mã hóa được sử dụng để thay đổi văn bản thuần túy này thành một số chuỗi khác trước khi lưu trữ. Bên cạnh đó, nếu người dùng cần sử dụng mật khẩu này chẳng hạn cho hệ thống đăng nhập, thì chúng tôi cần một cách so sánh mật khẩu sẽ được gửi trong quá trình giải mã.
Mã hóa cơ sở dữ liệu có thể được thực hiện theo nhiều cách khác nhau nhưng nhiều nhà phát triển không tính đến mức độ truyền tải. Tuy nhiên, các cách tiếp cận khác nhau cũng có liên quan đến những cạm bẫy khác nhau giữa thời gian truy cập dữ liệu bị chậm lại, đặc biệt là khi bộ nhớ ảo đang được truy cập nhiều.
Mã hóa dữ liệu ở chế độ nghỉ
Dữ liệu ở trạng thái nghỉ có nghĩa là dữ liệu không hoạt động được lưu trữ vật lý trên đĩa. Khi nói đến việc lưu trữ cơ sở dữ liệu trong môi trường đám mây, nơi nhà cung cấp dịch vụ đám mây có toàn quyền truy cập vào cơ sở hạ tầng, mã hóa có thể là một biện pháp tốt để duy trì quyền kiểm soát dữ liệu. Một số chiến lược mã hóa bạn có thể sử dụng được thảo luận bên dưới.
Mã hóa toàn bộ đĩa (FDE)
Khái niệm đằng sau FDE nói chung là bảo vệ mọi tệp và bộ lưu trữ tạm thời có thể chứa các phần dữ liệu. Nó khá hiệu quả, đặc biệt là khi bạn gặp khó khăn khi chọn những gì bạn muốn bảo vệ hoặc đúng hơn là nếu bạn không muốn bỏ sót một tệp. Ưu điểm chính của chiến lược này là nó không yêu cầu sự chú ý đặc biệt từ phía người dùng cuối sau khi có quyền truy cập vào hệ thống. Tuy nhiên, cách tiếp cận này có một số cạm bẫy. Chúng bao gồm:
- Quá trình mã hóa và giải mã làm chậm thời gian truy cập dữ liệu tổng thể.
- Dữ liệu có thể không được bảo vệ khi hệ thống đang bật vì thông tin sẽ được giải mã và sẵn sàng để đọc. Do đó, bạn cần thực hiện một số chiến lược mã hóa khác, chẳng hạn như mã hóa dựa trên tệp.
Mã hóa dựa trên tệp
Trong trường hợp này, các tệp hoặc thư mục được mã hóa bởi chính hệ thống tệp mật mã có thể xếp chồng. Trong PostgreSQL, chúng tôi thường sử dụng phương pháp pg_crypto như đã thảo luận trong bài viết này.
Một số ưu điểm của mã hóa hệ thống tệp bao gồm:
- Kiểm soát hành động có thể được thực thi thông qua việc sử dụng mật mã khóa công khai
- Quản lý riêng biệt các tệp được mã hóa để sao lưu các tệp đã thay đổi riêng lẻ ngay cả ở dạng được mã hóa, thay vì sao lưu toàn bộ ổ được mã hóa.
Tuy nhiên, đây không phải là một phương pháp mã hóa đáng tin cậy mà bạn có thể sử dụng cho dữ liệu nhóm của mình. Lý do là, một số giải pháp mã hóa dựa trên tệp có thể để lại phần còn lại của các tệp được mã hóa mà kẻ tấn công có thể khôi phục. Do đó, phương pháp kết hợp tốt nhất là kết hợp điều này với mã hóa toàn bộ ổ đĩa.
Mã hóa mức phiên bản
Mức phiên bản sử dụng bộ đệm để tất cả các tệp tạo nên cụm PostgreSQL được lưu trữ trên đĩa dưới dạng mã hóa dữ liệu lúc nghỉ. Sau đó, chúng được trình bày dưới dạng khối giải mã khi chúng được đọc từ đĩa vào bộ đệm chia sẻ. Sau khi ghi các khối này vào đĩa từ bộ đệm được chia sẻ, chúng lại được mã hóa tự động. Cơ sở dữ liệu lần đầu tiên được khởi tạo bằng mã hóa bằng lệnh initdb. Thứ hai, trong quá trình khởi động, khóa mã hóa được máy chủ tìm nạp theo một trong hai cách này; thông qua tham số pgcrypto.keysetup_command hoặc thông qua một biến môi trường.
Tải xuống Báo cáo chính thức hôm nay Quản lý &Tự động hóa PostgreSQL với ClusterControlTìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng PostgreSQLTải xuống Báo cáo chính thứcThiết lập mã hóa mức phiên bản
Một bản tóm tắt nhỏ về cách bạn có thể thiết lập mã hóa mức phiên bản được nêu trong các bước bên dưới:
- Kiểm tra xem bạn đã cài đặt “Contrib” hay không bằng cách sử dụng lệnh rpm -qa | grep Contrib cho Hệ điều hành dựa trên RedHat hoặc dpkg -l | grep Contrib cho Hệ điều hành Debian. Nếu nó không có trong danh sách, hãy cài đặt nó bằng apt-get install postgresql-Contrib nếu bạn đang sử dụng môi trường Dựa trên Debian hoặc cài đặt postgresql-Contrib nếu bạn đang sử dụng RedHat.
- Xây dựng mã PostgreSQL.
- Khởi tạo cụm bằng cách thiết lập khóa mã hóa và chạy lệnh he initdb
read -sp "Postgres passphrase: " PGENCRYPTIONKEY export PGENCRYPTIONKEY=$PGENCRYPTIONKEY initdb –data-encryption pgcrypto --data-checksums -D cryptotest - Khởi động máy chủ bằng lệnh
$ postgres -D /usr/local/pgsql/data - Đặt biến môi trường PGENCRYPTIONKEY bằng lệnh:
Bạn cũng có thể đặt khóa thông qua quy trình đọc khóa tùy chỉnh và an toàn hơn thông qua lệnh “pgcrypto.keysetup_command” tham số postgresql.conf đã đề cập ở trên.export PGENCRYPTIONKEY=topsecret pg_ctl -D cryptotest start
Kỳ vọng về Hiệu suất
Mã hóa luôn phải trả giá bằng hiệu suất, vì không có tùy chọn nào mà không phải trả phí. Nếu khối lượng công việc của bạn theo định hướng IO, bạn có thể mong đợi hiệu suất giảm đáng kể nhưng điều này có thể không đúng. Đôi khi trên phần cứng máy chủ thông thường, nếu tập dữ liệu ít được chia sẻ trong bộ đệm hoặc thời gian lưu lại trong bộ đệm nhỏ, thì hiệu suất có thể không đáng kể.
Sau khi thực hiện mã hóa cơ sở dữ liệu của mình, tôi đã chạy một số thử nghiệm nhỏ để kiểm tra xem mã hóa có thực sự ảnh hưởng đến hiệu suất hay không và kết quả được lập bảng bên dưới.
| Khối lượng công việc | Không có mã hóa | Có mã hóa | Chi phí hiệu suất |
|---|---|---|---|
| Thao tác chèn hàng loạt | 26 giây | 68 giây | 161% |
| Đọc-ghi phù hợp với bộ đệm dùng chung (theo tỷ lệ 1:3) | 3200TPS | 3068TPS | 4,13% |
| Chỉ đọc từ bộ đệm được chia sẻ | 2234 TPS | 2219 TPS | 0,68% |
| Chỉ đọc không phù hợp với bộ đệm được chia sẻ | 1845 TP | 1434 TPS | 22,28% |
| Đọc-ghi không phù hợp với bộ đệm dùng chung theo tỷ lệ 1:3 | 3422 TPS | 2545 TPS | 25,6% |
Như được mô tả trong bảng trên, chúng ta có thể thấy rằng hiệu suất là phi tuyến tính vì nó đôi khi tăng từ 161% đến 0,7%. Đây là một dấu hiệu đơn giản cho thấy hiệu suất mã hóa là khối lượng công việc cụ thể bên cạnh việc nhạy cảm với số lượng trang được di chuyển giữa bộ đệm được chia sẻ và đĩa. Điều này cũng có thể ảnh hưởng đến sức mạnh của CPU tùy thuộc vào khối lượng công việc liên quan. Mã hóa mức phiên bản là một tùy chọn khá khả thi và là cách tiếp cận đơn giản nhất cho một số môi trường.
Kết luận
Mã hóa dữ liệu là một công việc quan trọng, đặc biệt là đối với thông tin nhạy cảm trong quản lý cơ sở dữ liệu. Có một số tùy chọn có sẵn để mã hóa dữ liệu liên quan đến PostgreSQL. Khi xác định sử dụng phương pháp tiếp cận nào, điều quan trọng là phải hiểu dữ liệu, kiến trúc ứng dụng và việc sử dụng dữ liệu vì mã hóa đi kèm với chi phí hiệu suất. Bằng cách này, bạn sẽ có thể hiểu:khi nào thì kích hoạt mã hóa, dữ liệu của bạn bị lộ ở đâu và ở đâu là an toàn, đâu là phương pháp mã hóa tốt nhất để sử dụng.