Thỉnh thoảng, tôi thấy ai đó bày tỏ yêu cầu tạo một số ngẫu nhiên cho một khóa. Thông thường, điều này là để tạo một số loại CustomerID thay thế hoặc UserID là một số duy nhất trong một số phạm vi, nhưng không được cấp tuần tự và do đó khó đoán hơn nhiều so với IDENTITY giá trị.
NEWID() giải quyết vấn đề phỏng đoán, nhưng hình phạt hiệu suất thường là một sự phá vỡ thỏa thuận, đặc biệt là khi được phân cụm:các khóa rộng hơn nhiều so với số nguyên và việc tách trang do các giá trị không theo trình tự. NEWSEQUENTIALID() giải quyết vấn đề tách trang, nhưng vẫn là một chìa khóa rất rộng và giới thiệu lại vấn đề mà bạn có thể đoán giá trị tiếp theo (hoặc các giá trị được cấp gần đây) với một số mức độ chính xác.
Do đó, họ muốn có một kỹ thuật để tạo ra một và số nguyên duy nhất. Tự tạo một số ngẫu nhiên không khó bằng cách sử dụng các phương pháp như RAND() hoặc CHECKSUM(NEWID()) . Vấn đề xảy ra khi bạn phải phát hiện va chạm. Hãy xem nhanh một cách tiếp cận điển hình, giả sử chúng ta muốn giá trị CustomerID từ 1 đến 1.000.000:
DECLARE @rc INT =0, @CustomerID INT =ABS (CHECKSUM (NEWID ()))% 1000000 + 1; - hoặc ABS (CHUYỂN ĐỔI (INT, CRYPT_GEN_RANDOM (3)))% 1000000 + 1; - hoặc CONVERT (INT, RAND () * 1000000) + 1; WHILE @rc =0BEGIN NẾU KHÔNG TỒN TẠI (CHỌN 1 TỪ dbo.Customers WHERE CustomerID =@CustomerID) BẮT ĐẦU CHÈN dbo.Customer (CustomerID) CHỌN @CustomerID; BỘ @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS (CHECKSUM (NEWID ()))% 1000000 + 1, @rc =0; KẾT THÚC
Khi bảng lớn hơn, không chỉ việc kiểm tra các bản sao trở nên đắt hơn, mà tỷ lệ tạo một bản sao của bạn cũng tăng lên. Vì vậy, cách tiếp cận này có vẻ hiệu quả khi bàn nhỏ, nhưng tôi nghi ngờ rằng nó sẽ ngày càng tổn thương nhiều hơn theo thời gian.
Một cách tiếp cận khác
Tôi là một fan hâm mộ lớn của bảng phụ; Tôi đã viết công khai về các bảng lịch và bảng số trong một thập kỷ, và sử dụng chúng lâu hơn nữa. Và đây là một trường hợp mà tôi nghĩ rằng một bảng được điền sẵn có thể thực sự hữu ích. Tại sao lại dựa vào việc tạo các số ngẫu nhiên trong thời gian chạy và xử lý các bản sao tiềm ẩn, khi bạn có thể điền trước tất cả các giá trị đó và biết - chắc chắn 100%, nếu bạn bảo vệ các bảng của mình khỏi DML trái phép - giá trị tiếp theo bạn chọn chưa bao giờ có được sử dụng trước đây?
TẠO BẢNG dbo.RandomNumbers1 (RowID INT, Value INT, --UNIQUE, PRIMARY KEY (RowID, Value));; WITH x AS (SELECT TOP (1000000) s1. [Object_id] FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1. [Object_id]) INSERT dbo.RandomNumbers (RowID, Value) SELECT r =ROW_NUMBER ( ) HẾT (ORDER BY [object_id]), n =ROW_NUMBER () HẾT (ORDER BY NEWID ()) FROM xORDER BY r;
Tập hợp này mất 9 giây để tạo (trong máy ảo trên máy tính xách tay) và chiếm khoảng 17 MB trên đĩa. Dữ liệu trong bảng trông giống như sau:
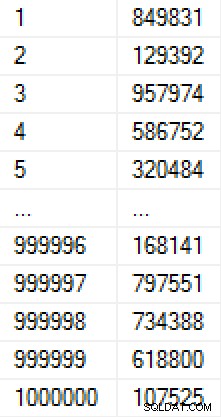
(Nếu chúng tôi lo lắng về cách các con số được điền, chúng tôi có thể thêm một ràng buộc duy nhất vào cột Giá trị, điều này sẽ làm cho bảng có 30 MB. Nếu chúng tôi áp dụng nén trang, nó sẽ là 11 MB hoặc 25 MB, tương ứng. )
Tôi đã tạo một bản sao khác của bảng và điền nó với các giá trị giống nhau để tôi có thể thử nghiệm hai phương pháp khác nhau để lấy giá trị tiếp theo:
TẠO BẢNG dbo.RandomNumbers2 (RowID INT, Giá trị INT, - KHÓA CHÍNH DUY NHẤT (RowID, Giá trị)); CHÈN dbo.RandomNumbers2 (RowID, Giá trị) CHỌN RowID, Giá trị TỪ dbo.RandomNumbers1;
Bây giờ, bất cứ lúc nào chúng ta muốn một số ngẫu nhiên mới, chúng ta có thể chỉ cần bật một số ra khỏi chồng các số hiện có và xóa nó. Điều này giúp chúng tôi không phải lo lắng về các bản sao và cho phép chúng tôi lấy các số - bằng cách sử dụng chỉ mục được phân nhóm - thực sự đã có theo thứ tự ngẫu nhiên. (Nói một cách chính xác, chúng tôi không phải xóa những con số khi chúng tôi sử dụng chúng; chúng tôi có thể thêm một cột để cho biết liệu một giá trị đã được sử dụng hay chưa - điều này sẽ giúp khôi phục và sử dụng lại giá trị đó dễ dàng hơn trong trường hợp Khách hàng sau đó bị xóa hoặc xảy ra sự cố bên ngoài giao dịch này nhưng trước khi chúng được tạo đầy đủ.)
DECLARE @holding TABLE (CustomerID INT); DELETE TOP (1) dbo.RandomNumbers1OUTPUT bị xóa.Value INTO @holding; CHÈN dbo.Customers (CustomerID, ... các cột khác ...) CHỌN CustomerID, ... các thông số khác ... FROM @holding;
Tôi đã sử dụng một biến bảng để giữ đầu ra trung gian, vì có nhiều hạn chế khác nhau với DML có thể kết hợp có thể khiến không thể chèn trực tiếp vào bảng Khách hàng từ DELETE (ví dụ, sự hiện diện của khóa ngoại). Tuy nhiên, thừa nhận rằng không phải lúc nào cũng có thể thực hiện được, tôi cũng muốn thử nghiệm phương pháp này:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT bị xóa.Value, ... các thông số khác ... INTO dbo.Customers (CustomerID, ... các cột khác ...);
Lưu ý rằng cả hai giải pháp này đều không thực sự đảm bảo thứ tự ngẫu nhiên, đặc biệt nếu bảng số ngẫu nhiên có các chỉ mục khác (chẳng hạn như chỉ mục duy nhất trên cột Giá trị). Không có cách nào để xác định đơn đặt hàng cho một DELETE sử dụng TOP; từ tài liệu:
Vì vậy, nếu bạn muốn đảm bảo đặt hàng ngẫu nhiên, bạn có thể làm như sau:
DECLARE @holding TABLE (CustomerID INT);; WITH x AS (SELECT TOP (1) Value FROM dbo.RandomNumbers2 ORDER BY RowID) DELETE x OUTPUT bị xóa.Value INTO @holding; CHÈN dbo.Customers (CustomerID, ... các cột khác ...) CHỌN CustomerID, ... các thông số khác ... FROM @holding;
Một xem xét khác ở đây là, đối với các thử nghiệm này, các bảng Khách hàng có một khóa chính được phân nhóm trên cột CustomerID; điều này chắc chắn sẽ dẫn đến việc tách trang khi bạn chèn các giá trị ngẫu nhiên. Trong thế giới thực, nếu bạn có yêu cầu này, bạn có thể sẽ nhóm trên một cột khác.
Lưu ý rằng tôi cũng đã bỏ qua các giao dịch và xử lý lỗi ở đây, nhưng những điều này cũng nên được xem xét đối với mã sản xuất.
Kiểm tra hiệu suất
Để rút ra một số so sánh hiệu suất thực tế, tôi đã tạo năm thủ tục được lưu trữ, đại diện cho các tình huống sau (tốc độ thử nghiệm, phân phối và tần suất va chạm của các phương pháp ngẫu nhiên khác nhau, cũng như tốc độ sử dụng bảng số ngẫu nhiên được xác định trước):
- Tạo thời gian chạy bằng
CHECKSUM(NEWID()) - Tạo thời gian chạy bằng
CRYPT_GEN_RANDOM() - Tạo thời gian chạy bằng
RAND() - Bảng số được xác định trước với biến bảng
- Bảng số được xác định trước với chèn trực tiếp
Họ sử dụng bảng ghi nhật ký để theo dõi thời lượng và số lần va chạm:
TẠO BẢNG dbo.CustomerLog (LogID INT IDENTITY (1,1) KHÓA CHÍNH, pid INT, va chạm INT, thời lượng INT - micro giây);
Mã cho các thủ tục sau (bấm để hiển thị / ẩn):
/ * Runtime sử dụng CHECKSUM (NEWID ()) * / TẠO THỦ TỤC [dbo]. [AddCustomer_Runtime_Checksum] ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2 (7) =SYSDATETIME (), @duration INT, @CustomerID INT =ABS (CHECKSUM (NEWID ()))% 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BẮT ĐẦU NẾU KHÔNG TỒN TẠI (CHỌN 1 TỪ dbo.Customers_Runtime_Checksum WHERE CustomerID =@CustomerID) BẮT ĐẦU CHÈN dbo.Customers_Runtime_Checksum (CustomerID) CHỌN @CustomerID; BỘ @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS (CHECKSUM (NEWID ()))% 1000000 + 1, @collisions + =1, @rc =0; END END SELECT @duration =DATEDIFF (MICROSECOND, @start, CONVERT (DATETIME2 (7), SYSDATETIME ())); INSERT dbo.CustomerLog (pid, va chạm, thời lượng) CHỌN 1, @collisions, @duration; ENDGO / * thời gian chạy bằng CRYPT_GEN_RANDOM () * / CREATE PROCEDURE [dbo]. [AddCustomer_Runtime_CryptGen] ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2 (7) =SYSDATETIME (), @duration INT, @CustomerID INT =ABS (CONVERT (INT, CRYPT_GEN_RANDOM (3)))% 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BẮT ĐẦU NẾU KHÔNG TỒN TẠI (CHỌN 1 TỪ dbo.Customers_Runtime_CryptGen WHERE CustomerID =@CustomerID) BẮT ĐẦU CHÈN dbo.Customers_Runtime_CryptGen (CustomerID) CHỌN @CustomerID; BỘ @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS (CONVERT (INT, CRYPT_GEN_RANDOM (3)))% 1000000 + 1, @collisions + =1, @rc =0; END END SELECT @duration =DATEDIFF (MICROSECOND, @start, CONVERT (DATETIME2 (7), SYSDATETIME ())); INSERT dbo.CustomerLog (pid, va chạm, thời lượng) CHỌN 2, @collisions, @duration; ENDGO / * thời gian chạy bằng cách sử dụng RAND () * / TẠO THỦ TỤC [dbo]. [AddCustomer_Runtime_Rand] ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2 (7) =SYSDATETIME (), @duration INT, @CustomerID INT =CONVERT (INT, RAND () * 1000000) + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BẮT ĐẦU NẾU KHÔNG TỒN TẠI (CHỌN 1 TỪ dbo.Customers_Runtime_Rand WHERE CustomerID =@CustomerID) BẮT ĐẦU CHÈN dbo.Customers_Runtime_Rand (CustomerID) CHỌN @CustomerID; BỘ @rc =1; END ELSE BEGIN SELECT @CustomerID =CONVERT (INT, RAND () * 1000000) + 1, @collisions + =1, @rc =0; END END SELECT @duration =DATEDIFF (MICROSECOND, @start, CONVERT (DATETIME2 (7), SYSDATETIME ())); INSERT dbo.CustomerLog (pid, va chạm, thời lượng) CHỌN 3, @collisions, @duration; ENDGO / * được xác định trước bằng cách sử dụng một biến bảng * / TẠO QUY TRÌNH [dbo]. [AddCustomer_Predefined_TableVariable] ASBEGIN ĐẶT SỐ KHOẢN BẬT; DECLARE @start DATETIME2 (7) =SYSDATETIME (), @duration INT; BẢNG KHAI BÁO @holding (CustomerID INT); DELETE TOP (1) dbo.RandomNumbers1 OUTPUT bị xóa.Value INTO @holding; CHÈN dbo.Customers_Predefined_TableVariable (CustomerID) CHỌN ID Khách hàng TỪ @holding; SELECT @duration =DATEDIFF (MICROSECOND, @start, CONVERT (DATETIME2 (7), SYSDATETIME ())); CHÈN dbo.CustomerLog (pid, thời lượng) CHỌN 4, @duration; ENDGO / * được xác định trước bằng cách sử dụng chèn trực tiếp * / CREATE PROCEDURE [dbo]. [AddCustomer_Predefined_Direct] ASBEGIN ĐẶT SỐ KHOẢN BẬT; DECLARE @start DATETIME2 (7) =SYSDATETIME (), @duration INT; DELETE TOP (1) dbo.RandomNumbers2 OUTPUT bị xóa.Value INTO dbo.Customers_Predefined_Direct; SELECT @duration =DATEDIFF (MICROSECOND, @start, CONVERT (DATETIME2 (7), SYSDATETIME ())); CHÈN dbo.CustomerLog (pid, thời lượng) CHỌN 5, @duration; ENDGO
Và để kiểm tra điều này, tôi sẽ chạy mỗi thủ tục được lưu trữ 1.000.000 lần:
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Pred 10000Không có gì ngạc nhiên khi các phương pháp sử dụng bảng số ngẫu nhiên được xác định trước mất nhiều thời gian hơn một chút * khi bắt đầu thử nghiệm *, vì chúng phải thực hiện cả I / O đọc và ghi. Hãy nhớ rằng những con số này tính bằng micro giây , đây là thời lượng trung bình cho mỗi thủ tục, ở các khoảng thời gian khác nhau trong suốt quá trình (tính trung bình trong 10.000 lần thực thi đầu tiên, 10.000 lần thực thi giữa, 10.000 lần thực thi cuối cùng và 1.000 lần thực thi cuối cùng):
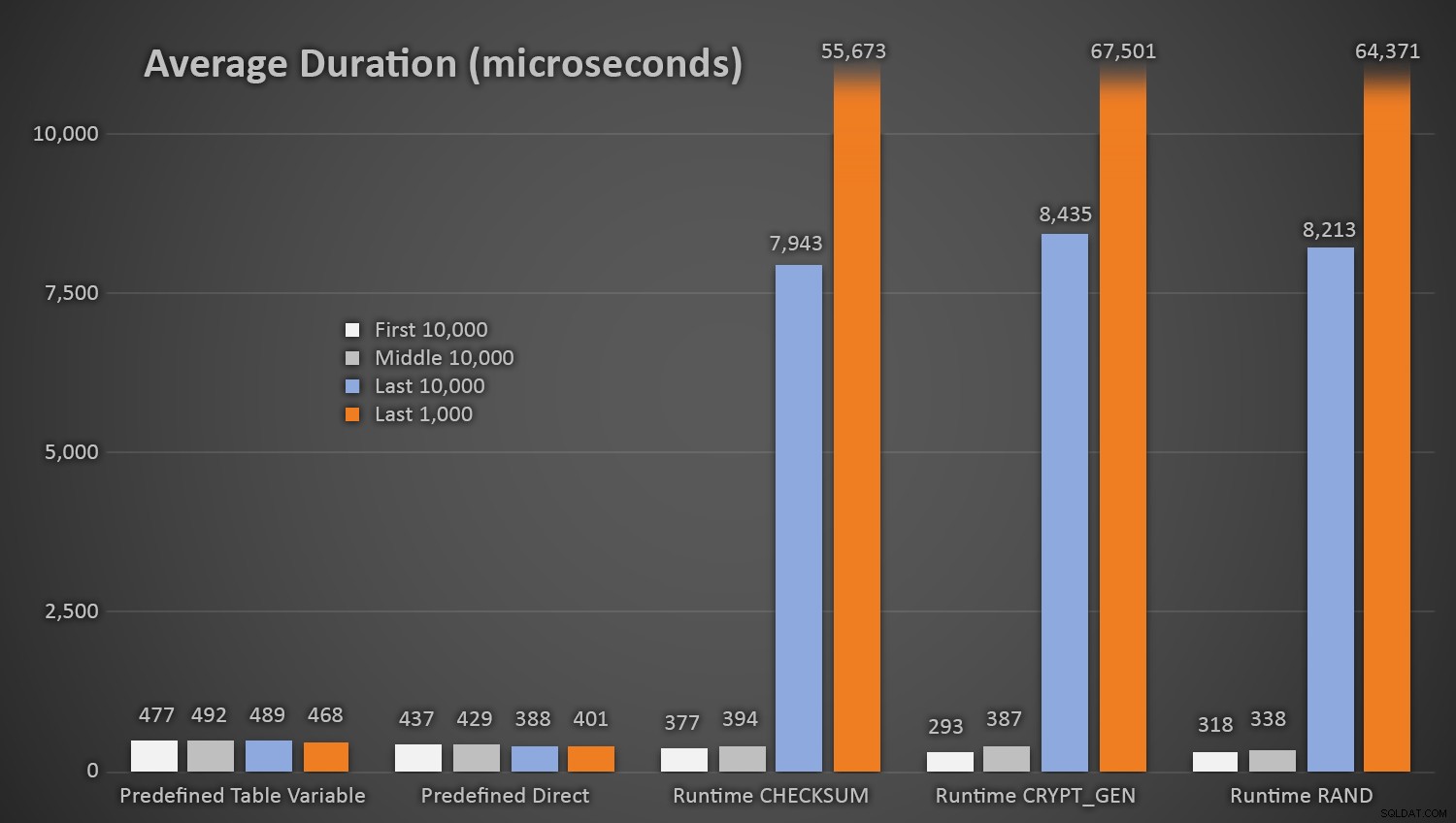
Thời lượng trung bình (tính bằng micro giây) của tạo ngẫu nhiên bằng cách sử dụng các phương pháp tiếp cận khác nhauĐiều này hoạt động tốt cho tất cả các phương pháp khi có ít hàng trong bảng Khách hàng, nhưng khi bảng ngày càng lớn hơn, chi phí kiểm tra số ngẫu nhiên mới so với dữ liệu hiện có bằng cách sử dụng các phương pháp thời gian chạy tăng lên đáng kể, cả hai do I tăng lên. / O và cũng do số lần va chạm tăng lên (buộc bạn phải thử đi thử lại). So sánh thời lượng trung bình khi đếm xung đột trong các phạm vi sau (và hãy nhớ rằng mẫu này chỉ ảnh hưởng đến các phương thức thời gian chạy):
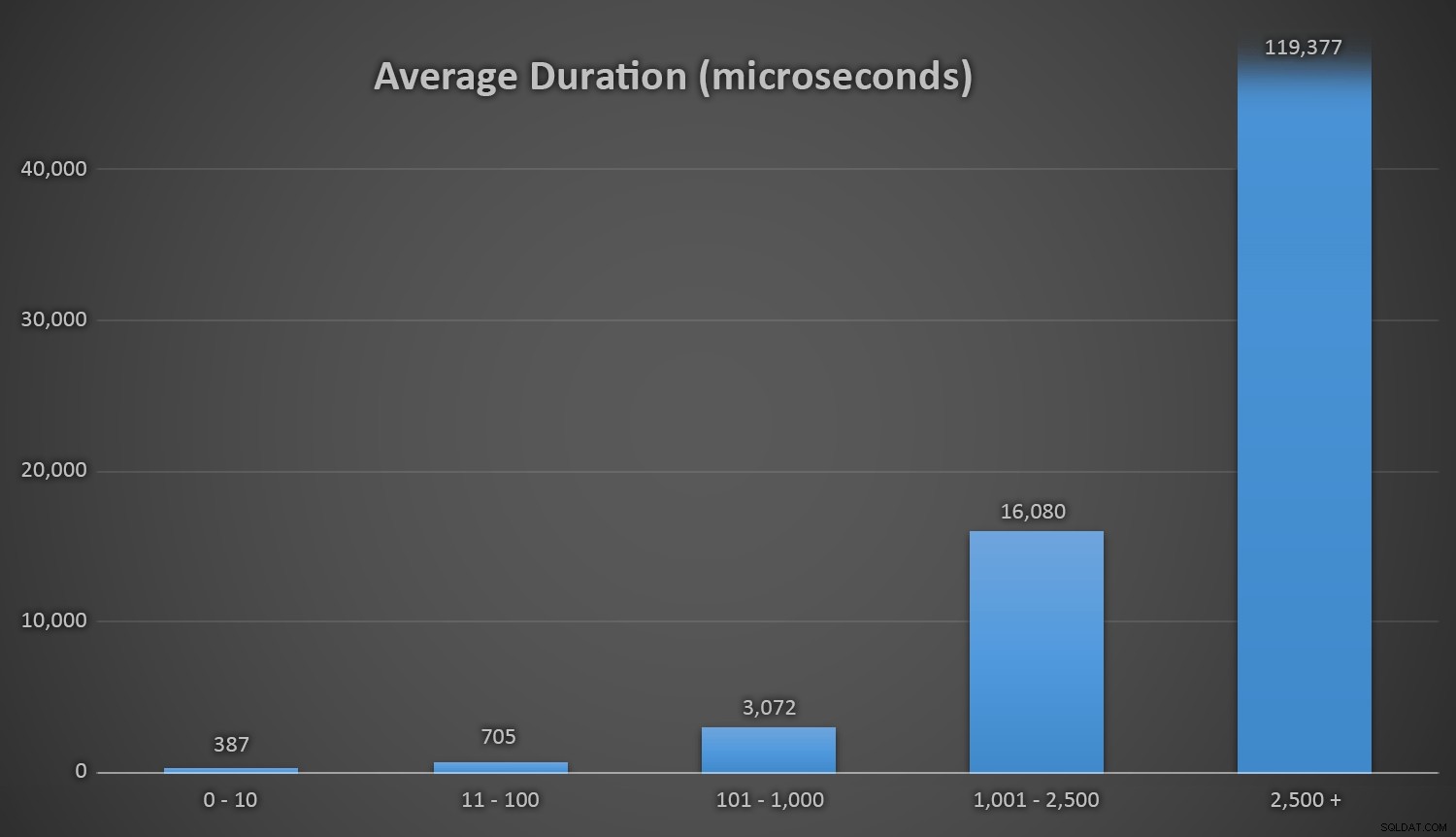
Thời lượng trung bình (tính bằng micro giây) trong các phạm vi va chạm khác nhauTôi ước gì có một cách đơn giản để vẽ biểu đồ thời gian dựa trên số lần va chạm. Tôi sẽ để lại cho bạn mẩu tin nhỏ này:trong ba lần chèn cuối cùng, các phương thức thời gian chạy sau phải thực hiện nhiều lần thử này trước khi cuối cùng chúng tình cờ tìm thấy ID duy nhất cuối cùng mà chúng đang tìm kiếm và đây là thời gian mất bao lâu:
| Số lần va chạm | Thời lượng (micro giây) | ||
|---|---|---|---|
| CHECKSUM (NEWID ()) | Hàng thứ 3 đến hàng cuối cùng | 63.545 | 639.358 |
| Hàng thứ 2 đến hàng cuối cùng | 164.807 | 1.605.695 | |
| Hàng cuối cùng | 30.630 | 296.207 | |
| CRYPT_GEN_RANDOM () | Hàng thứ 3 đến hàng cuối cùng | 219.766 | 2.229.166 |
| Hàng thứ 2 đến hàng cuối cùng | 255.463 | 2.681.468 | |
| Hàng cuối cùng | 136.342 | 1.434.725 | |
| RAND () | Hàng thứ 3 đến hàng cuối cùng | 129.764 | 1.215.994 |
| Hàng thứ 2 đến hàng cuối cùng | 220.195 | 2.088.992 | |
| Hàng cuối cùng | 440.765 | 4,161,925 | |
Thời lượng và xung đột quá mức ở gần cuối dòng
Điều thú vị là không phải lúc nào hàng cuối cùng cũng là hàng mang lại số lần va chạm cao nhất, vì vậy đây có thể trở thành một vấn đề thực sự từ lâu trước khi bạn sử dụng hết 999.000 giá trị trở lên.
Một cân nhắc khác
Bạn có thể muốn xem xét thiết lập một số loại cảnh báo hoặc thông báo khi bảng Số ngẫu nhiên bắt đầu thấp hơn một số hàng (tại thời điểm đó, bạn có thể điền lại bảng bằng một tập hợp mới từ 1.000.001 - 2.000.000, chẳng hạn). Bạn sẽ phải làm điều gì đó tương tự nếu bạn đang tạo các số ngẫu nhiên - nếu bạn đang giữ nó trong phạm vi 1 - 1.000.000, thì bạn phải thay đổi mã để tạo các số từ một phạm vi khác khi bạn ' đã sử dụng hết những giá trị đó.
Nếu bạn đang sử dụng phương pháp số ngẫu nhiên trong thời gian chạy, thì bạn có thể tránh tình trạng này bằng cách liên tục thay đổi kích thước nhóm mà từ đó bạn rút ra một số ngẫu nhiên (điều này cũng sẽ ổn định và giảm đáng kể số lần va chạm). Ví dụ:thay vì:
DECLARE @CustomerID INT =ABS (CHECKSUM (NEWID ()))% 1000000 + 1;
Bạn có thể căn cứ vào tổng số hàng đã có trong bảng:
DECLARE @total INT =1000000 + ISNULL ((SELECT SUM (row_count) FROM sys.dm_db_partition_stats WHERE [object_id] =OBJECT_ID ('dbo.Customers') AND index_id =1), 0);
Bây giờ lo lắng thực sự duy nhất của bạn là khi bạn tiếp cận giới hạn trên cho INT …
Lưu ý:Gần đây tôi cũng đã viết một mẹo về điều này tại MSSQLTips.com.