Dự đoán đơn
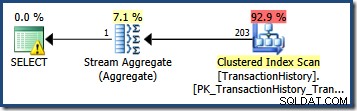
Việc ước tính số hàng đủ điều kiện bởi một vị từ truy vấn thường rất đơn giản. Khi một vị từ thực hiện một phép so sánh đơn giản giữa một cột và một giá trị vô hướng, rất có thể là công cụ ước lượng số lượng sẽ có thể lấy được ước tính chất lượng tốt từ biểu đồ thống kê. Ví dụ:truy vấn AdventureWorks sau tạo ra ước tính chính xác chính xác về 203 hàng (giả sử không có thay đổi nào đối với dữ liệu kể từ khi thống kê được tạo):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
Nhìn vào biểu đồ thống kê cho TransactionDate , rõ ràng để xem ước tính này đến từ đâu:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
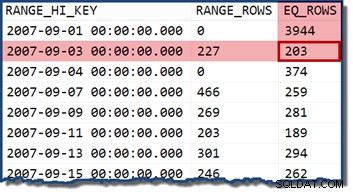
Nếu chúng tôi thay đổi truy vấn để chỉ định một ngày nằm trong nhóm biểu đồ, công cụ ước tính số lượng sẽ giả định các giá trị được phân phối đồng đều. Sử dụng ngày 2007-09-02 ước tính 227 hàng (từ RANGE_ROWS lối vào). Như một lưu ý phụ thú vị, ước tính vẫn ở 227 hàng bất kể phần thời gian nào mà chúng tôi có thể thêm vào giá trị ngày (TransactionDate cột là một datetime kiểu dữ liệu).
Nếu chúng tôi thử truy vấn lại với ngày 2007-09-05 hoặc 2007-09-06 (cả hai đều nằm trong khoảng 2007-09-04 và 2007-09-07 các bước biểu đồ), công cụ ước tính cardinality giả định 466 RANGE_ROWS được chia đều giữa hai giá trị, ước tính 233 hàng trong cả hai trường hợp.
Có nhiều chi tiết khác để ước tính số lượng cho các vị từ đơn giản, nhưng những điều ở trên sẽ là một phần bổ sung cho các mục đích hiện tại của chúng tôi.
Các vấn đề của nhiều dự đoán
Khi một truy vấn chứa nhiều hơn một vị từ cột, việc ước tính số lượng sẽ trở nên khó khăn hơn. Hãy xem xét truy vấn sau với hai vị từ đơn giản (mỗi vị từ dễ ước lượng một mình):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; Các phạm vi giá trị cụ thể trong truy vấn được chọn có chủ ý để cả hai vị từ xác định chính xác các hàng giống nhau. Chúng tôi có thể dễ dàng sửa đổi các giá trị truy vấn để tạo ra bất kỳ số lượng chồng chéo nào, bao gồm cả sự chồng chéo. Hãy tưởng tượng bây giờ bạn là công cụ ước tính bản số:bạn sẽ lấy ước tính bản số như thế nào cho truy vấn này?
Vấn đề khó hơn so với những gì nó có thể xảy ra lúc đầu. Theo mặc định, SQL Server tự động tạo thống kê cột đơn trên cả hai cột vị ngữ. Chúng tôi cũng có thể tạo thống kê nhiều cột theo cách thủ công. Điều này có cung cấp cho chúng tôi đủ thông tin để tạo ra một ước tính tốt cho các giá trị cụ thể này không? Còn về trường hợp chung chung hơn, trong đó có thể có bất kỳ mức độ chồng chéo?
Sử dụng hai đối tượng thống kê một cột, chúng ta có thể dễ dàng lấy được ước tính cho mỗi vị từ bằng phương pháp biểu đồ được mô tả trong phần trước. Đối với các giá trị cụ thể trong truy vấn ở trên, biểu đồ cho thấy rằng TransactionID phạm vi dự kiến sẽ khớp với 68412,4 hàng và TransactionDate phạm vi dự kiến sẽ khớp với 68,413 hàng. (Nếu biểu đồ hoàn hảo, hai con số này sẽ hoàn toàn giống nhau.)
Những gì biểu đồ không thể cho chúng tôi biết có bao nhiêu từ hai tập hợp hàng này sẽ là các hàng giống nhau . Tất cả những gì chúng ta có thể nói dựa trên thông tin biểu đồ là ước tính của chúng ta phải nằm trong khoảng từ 0 (hoàn toàn không trùng lặp) đến 68412,4 hàng (hoàn toàn chồng chéo).
Việc tạo thống kê nhiều cột không cung cấp hỗ trợ nào cho truy vấn này (hoặc cho các truy vấn phạm vi nói chung). Thống kê nhiều cột vẫn chỉ tạo biểu đồ trên cột được đặt tên đầu tiên, về cơ bản sao chép biểu đồ được liên kết với một trong các thống kê được tạo tự động. Mật độ bổ sung thông tin được cung cấp bởi thống kê nhiều cột có thể hữu ích để cung cấp thông tin về trường hợp trung bình cho các truy vấn chứa nhiều vị từ bình đẳng, nhưng chúng không giúp ích được gì cho chúng tôi ở đây.
Để tạo ra một ước tính với mức độ tin cậy cao, chúng tôi cần SQL Server cung cấp thông tin tốt hơn về phân phối dữ liệu - một cái gì đó giống như một đa chiều biểu đồ thống kê. Theo như tôi biết, hiện tại không có công cụ cơ sở dữ liệu thương mại nào cung cấp một cơ sở như thế này, mặc dù một số tài liệu kỹ thuật đã được xuất bản về chủ đề này (bao gồm cả tài liệu Nghiên cứu của Microsoft sử dụng sự phát triển nội bộ của SQL Server 2000).
Nếu không biết bất kỳ điều gì về các mối tương quan và chồng chéo dữ liệu cho các phạm vi giá trị cụ thể, không rõ chúng ta nên tiến hành như thế nào để tạo ra một ước tính tốt cho truy vấn của mình. Vì vậy, SQL Server làm gì ở đây?
SQL Server 7 - 2012
Công cụ ước tính bản số trong các phiên bản SQL Server này thường giả định rằng các giá trị của các thuộc tính khác nhau trong một bảng được phân phối hoàn toàn độc lập với nhau. Giả định về tính độc lập này hiếm khi phản hồi chính xác dữ liệu thực, nhưng nó có lợi thế là thực hiện các phép tính đơn giản hơn.
VÀ Tính chọn lọc
Sử dụng giả định về tính độc lập, hai vị từ được kết nối bằng AND (được gọi là kết hợp ) với các vùng chọn lọc S 1 và S 2 , dẫn đến tính chọn lọc kết hợp của:
(S1 * S2)
Trong trường hợp thuật ngữ này không quen thuộc với bạn, hãy tính chọn lọc là một số từ 0 đến 1, đại diện cho phần nhỏ của các hàng trong bảng chuyển vị ngữ. Ví dụ:nếu một vị từ chọn 12 hàng từ bảng 100 hàng, độ chọn lọc là (12/100) =0,12.
Trong ví dụ của chúng tôi, TransactionHistory bảng chứa tổng cộng 113.443 hàng. Vị từ trên TransactionID được ước tính (từ biểu đồ) để đủ điều kiện 68.412,4 hàng, do đó, độ chọn lọc là (68.412,4 / 113.443) hoặc khoảng 0,603055 . Vị từ trên TransactionDate được ước tính tương tự để có độ chọn lọc là (68,413 / 113,443) =khoảng 0,603061 .
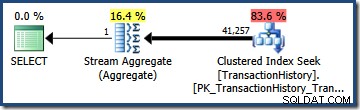
Nhân hai độ chọn lọc (sử dụng công thức ở trên) cho ước tính độ chọn lọc kết hợp là 0,363679 . Nhân độ chọn lọc này với số lượng của bảng (113,443) cho kết quả ước tính cuối cùng là 41,256,8 hàng:
HOẶC Tính chọn lọc
Hai vị từ được kết nối bằng OR (a disjunction ) với các vùng chọn lọc S 1 và S 2 , dẫn đến tính chọn lọc kết hợp của:
(S1 + S2) – (S1 * S2)
Trực giác đằng sau công thức là cộng hai vùng chọn lọc, sau đó trừ ước lượng cho kết hợp của chúng (sử dụng công thức trước). Rõ ràng là chúng ta có thể có hai vị từ, mỗi vị từ có độ chọn lọc 0,8, nhưng chỉ cần cộng chúng lại với nhau sẽ tạo ra độ chọn lọc kết hợp không thể thực hiện được là 1,6. Mặc dù giả định về tính độc lập, chúng ta phải nhận ra rằng hai vị từ có thể trùng lặp, do đó, để tránh tính hai lần, độ chọn lọc ước tính của kết hợp sẽ bị trừ đi.
Chúng tôi có thể dễ dàng sửa đổi ví dụ đang chạy của mình để sử dụng OR :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
Thay thế các lựa chọn vị từ thành OR công thức cung cấp độ chọn lọc kết hợp của:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Nhân với số hàng trong bảng, tính chọn lọc này cho chúng tôi ước tính số lượng cuối cùng là 95.568,6 :
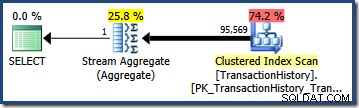
Không ước tính ( 41,257 cho AND truy vấn; 95.569 cho OR truy vấn) đặc biệt tốt vì cả hai đều dựa trên giả định mô hình hóa không khớp với phân phối dữ liệu rất tốt. Cả hai truy vấn thực sự trả về 68,413 hàng (vì các vị từ xác định chính xác các hàng giống nhau).
Cờ theo dõi 4137 - Tính chọn lọc tối thiểu
Đối với SQL Server 2008 (R1) đến 2012, Microsoft đã phát hành bản sửa lỗi thay đổi cách tính chọn lọc cho AND case (vị ngữ liên từ) thôi. Bài viết Cơ sở Kiến thức trong liên kết đó không chứa nhiều chi tiết, nhưng hóa ra bản sửa lỗi thay đổi công thức chọn lọc được sử dụng. Thay vì nhân các độ chọn lọc riêng lẻ, ước tính bản số cho các vị từ liên hợp giờ chỉ sử dụng độ chọn lọc thấp nhất.
Để kích hoạt hành vi đã thay đổi, cần có cờ theo dõi được hỗ trợ 4137. Một bài báo trong Cơ sở Kiến thức riêng biệt tài liệu rằng cờ theo dõi này cũng được hỗ trợ để sử dụng cho mỗi truy vấn thông qua QUERYTRACEON gợi ý:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
OPTION (QUERYTRACEON 4137); Với cờ này đang hoạt động, ước tính số lượng sử dụng độ chọn lọc tối thiểu của hai vị từ, dẫn đến ước tính là 68.412,4 hàng:
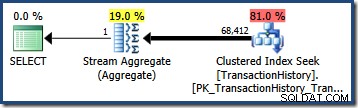
Điều này xảy ra gần như hoàn hảo cho truy vấn của chúng tôi vì các vị từ thử nghiệm của chúng tôi có tương quan chính xác (và các ước tính thu được từ biểu đồ cơ sở cũng rất tốt).
Rất hiếm khi các vị từ có tương quan hoàn hảo như thế này với dữ liệu thực, nhưng cờ theo dõi có thể hữu ích trong một số trường hợp. Lưu ý rằng hành vi chọn lọc tối thiểu sẽ áp dụng cho tất cả các liên từ (AND ) các vị từ trong truy vấn; không có cách nào để chỉ định hành vi ở cấp độ chi tiết hơn.
Không có cờ theo dõi tương ứng để ước tính sai lệch (OR ) các vị từ sử dụng độ chọn lọc tối thiểu.
SQL Server 2014
Tính toán chọn lọc trong SQL Server 2014 hoạt động giống như các phiên bản trước (và cờ theo dõi 4137 hoạt động như trước đây) nếu mức tương thích cơ sở dữ liệu được đặt thấp hơn 120 hoặc nếu cờ theo dõi 9481 đang hoạt động. Đặt mức độ tương thích cơ sở dữ liệu là chính thức cách sử dụng ước tính cardinality trước năm 2014 trong SQL Server 2014. Cờ theo dõi 9481 có hiệu quả để thực hiện điều tương tự như tại thời điểm viết bài và cũng hoạt động với QUERYTRACEON , mặc dù nó không được ghi lại để làm như vậy. Không có cách nào để biết hành vi RTM của cờ này sẽ như thế nào.
Nếu công cụ ước tính bản số mới đang hoạt động, SQL Server 2014 sử dụng một công thức mặc định khác để kết hợp các vị từ liên từ và liên kết. Mặc dù không có tài liệu, công thức chọn lọc cho các liên từ đã được phát hiện và ghi lại nhiều lần. Phần đầu tiên tôi nhớ đã thấy là trong bài đăng trên blog tiếng Bồ Đào Nha này và phần tiếp theo hai được phát hành sau đó vài tuần. Tóm lại, cách tiếp cận năm 2014 đối với các vị từ liên hợp là sử dụng lũy thừa theo cấp số nhân: đưa ra một bảng với số lượng C và các vị từ chọn lọc S 1 , S 2 , S 3 … S n , trong đó S 1 là lựa chọn tốt nhất và S n ít nhất:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
Ước tính được tính toán vị từ chọn lọc nhất nhân với số lượng bảng, nhân với căn bậc hai của vị từ chọn lọc nhất tiếp theo, v.v. Với mỗi độ chọn lọc mới sẽ thu được thêm một căn bậc hai.
Nhắc lại rằng độ chọn lọc là một số trong khoảng từ 0 đến 1, rõ ràng là việc áp dụng căn bậc hai sẽ di chuyển số gần hơn đến 1. Hiệu quả là tính đến tất cả các vị từ trong ước tính cuối cùng, nhưng để giảm tác động của các vị từ ít chọn lọc hơn. nhanh chóng. Có thể cho rằng ý tưởng này có nhiều logic hơn là theo giả định về tính độc lập , nhưng nó vẫn là một công thức cố định - nó không thay đổi dựa trên mức độ tương quan dữ liệu thực tế.
Công cụ ước tính số lượng năm 2014 sử dụng công thức dự phòng theo cấp số nhân cho cả hai các vị từ liên từ và liên kết, mặc dù công thức được sử dụng trong liên từ (OR ) trường hợp vẫn chưa được lập thành văn bản (chính thức hoặc cách khác).
Cờ theo dõi tính chọn lọc của SQL Server 2014
Cờ theo dõi 4137 (để sử dụng độ chọn lọc tối thiểu) không hoạt động trong SQL Server 2014, nếu công cụ ước tính bản số mới được sử dụng khi biên dịch truy vấn. Thay vào đó, có một cờ theo dõi mới 9471 . Khi cờ này hoạt động, tính chọn lọc tối thiểu được sử dụng để ước tính nhiều liên kết và liên kết các vị ngữ. Đây là sự thay đổi so với hành vi 4137, chỉ ảnh hưởng đến các vị từ liên từ.
Tương tự, cờ theo dõi 9472 có thể được chỉ định để giả định độc lập cho nhiều vị từ, như các phiên bản trước đã làm. Cờ này khác với 9481 (để sử dụng công cụ ước tính số lượng trước năm 2014) vì dưới 9472 công cụ ước tính số lượng vị trí mới sẽ vẫn được sử dụng, chỉ có công thức chọn lọc cho nhiều vị từ bị ảnh hưởng.
Cả 9471 và 9472 đều không được ghi lại vào thời điểm viết bài (mặc dù chúng có thể ở RTM).
Một cách thuận tiện để xem giả định tính chọn lọc nào đang được sử dụng trong SQL Server 2014 (với công cụ ước tính số lượng mới đang hoạt động) là kiểm tra đầu ra gỡ lỗi tính toán chọn lọc được tạo ra khi cờ theo dõi 2363 và 3604 đang hoạt động. Phần cần tìm liên quan đến công cụ tính chọn lọc kết hợp các bộ lọc, tại đây bạn sẽ thấy một trong những phần sau, tùy thuộc vào giả định nào đang được sử dụng:
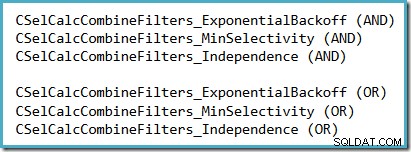
Không có triển vọng thực tế nào rằng 2363 sẽ được ghi nhận hoặc hỗ trợ.
Lời kết
Không có gì kỳ diệu về sự lùi lại theo cấp số nhân, tính chọn lọc tối thiểu hoặc tính độc lập. Mỗi cách tiếp cận thể hiện (cực kỳ) đơn giản hóa giả định có thể hoặc không thể tạo ra ước tính có thể chấp nhận được cho bất kỳ truy vấn hoặc phân phối dữ liệu cụ thể nào.
Ở một số khía cạnh, dự phòng theo cấp số nhân đại diện cho sự thỏa hiệp giữa hai thái cực của độc lập và tính chọn lọc tối thiểu . Mặc dù vậy, điều quan trọng là không được kỳ vọng vô lý về nó. Cho đến khi một cách chính xác hơn được tìm thấy để ước tính độ chọn lọc cho nhiều vị từ (với các đặc điểm hoạt động hợp lý), điều quan trọng là phải nhận thức được các giới hạn của mô hình và đề phòng các lỗi ước tính (tiềm ẩn) cho phù hợp.
Các cờ theo dõi khác nhau cung cấp một số kiểm soát đối với giả định nào được sử dụng, nhưng tình hình vẫn chưa hoàn hảo. Đối với một điều, mức độ chi tiết tốt nhất mà cờ có thể được áp dụng là một truy vấn duy nhất - hành vi ước tính không thể được chỉ định ở cấp vị từ. Nếu bạn có một truy vấn trong đó một số vị từ có tương quan và những vị từ khác độc lập, các cờ theo dõi có thể không giúp bạn nhiều nếu không cấu trúc lại truy vấn theo cách này hay cách khác. Tương tự, một truy vấn có vấn đề có thể có các tương quan vị từ không được mô hình hóa tốt bởi bất kỳ tùy chọn có sẵn nào.
Việc sử dụng đặc biệt cờ theo dõi yêu cầu các quyền tương tự như DBCC TRACEON - cụ thể là sysadmin . Điều đó có thể tốt cho thử nghiệm cá nhân, nhưng đối với sản xuất, hãy sử dụng hướng dẫn gói sử dụng QUERYTRACEON gợi ý là một lựa chọn tốt hơn. Với hướng dẫn kế hoạch, không cần có thêm quyền nào để thực hiện truy vấn (tất nhiên, mặc dù các quyền nâng cao được yêu cầu để tạo hướng dẫn kế hoạch).