Tôi đặc biệt tìm ra vấn đề.
Đầu tiên, hãy nhớ mã của tôi trong chế độ xem:
<% @episodes.each do |t| %>
<% if !t.episode_image.blank? %>
<li><%= image_tag(t.episode_image.image(:thumb)) %></li>
<% end %>
<li><%= t.episode_urls.first.mas_path if !t.episode_urls.first.blank?%></li>
<li><%= t.title %></li>
<% end %>
Ở đây tôi đang nhận từng tập episode_image bên trong sự lặp lại của tôi. Mặc dù tôi đã sử dụng includes trong bộ điều khiển của tôi, đã xảy ra lỗi lớn trong giản đồ bảng của tôi. Tôi không có chỉ mục cho episode_id trong episode_images của tôi bàn! . Điều này gây ra thời gian truy vấn cực kỳ cao. Tôi đã tìm thấy nó bằng cách sử dụng các báo cáo cơ sở dữ liệu của New Relic. Tất cả thời gian truy vấn khác là 0,5 mili giây hoặc 2-3 mili giây nhưng episode.episode_image đã gây ra gần 6500 mili giây!
Tôi không biết nhiều về mối quan hệ giữa thời gian truy vấn và thực thi ứng dụng nhưng khi tôi thêm chỉ mục vào episode_images của mình bảng, bây giờ tôi có thể thấy rõ ràng sự khác biệt. Nếu bạn có lược đồ cơ sở dữ liệu của mình đúng cách, bạn có thể sẽ không gặp bất kỳ vấn đề nào với việc mở rộng quy mô thông qua Heroku. Nhưng bất kỳ dyno nào cũng không thể giúp bạn với một cơ sở dữ liệu được thiết kế tồi.
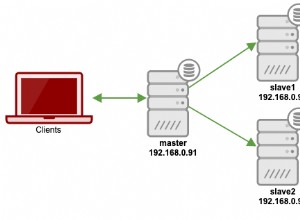
Đối với những người có thể gặp phải vấn đề tương tự, tôi muốn cho bạn biết về một số phát hiện của tôi về mối quan hệ giữa nhân viên web Heroku, công nhân Unicorn và kết nối đang hoạt động Postgresql:
Về cơ bản, Heroku cung cấp cho bạn một dyno, một loại máy ảo nhỏ có 1 lõi và 512MB ram. Bên trong máy ảo nhỏ đó, máy chủ Unicorn của bạn chạy. Unicorn có quy trình tổng thể và quy trình công nhân. Mỗi nhân viên Unicorn của bạn đều có kết nối cố định của riêng họ với máy chủ Postgresql hiện có của bạn (Đừng quên kiểm tra cái này ) Về cơ bản, nó có nghĩa là khi bạn có một Heroku dyno với 3 công nhân Unicorn đang chạy trên nó, bạn có ít nhất 4 kết nối đang hoạt động. Nếu bạn có 2 web dynos, bạn có ít nhất 8 kết nối đang hoạt động.
Giả sử bạn có một Tengu Postgres tiêu chuẩn với giới hạn 200 kết nối đồng thời. Nếu bạn có các truy vấn có vấn đề với thiết kế db không tốt thì db cũng như nhiều dynos không thể cứu bạn mà không có bộ nhớ cache ... Nếu bạn có các truy vấn chạy dài, bạn không có lựa chọn nào khác ngoài bộ nhớ đệm, tôi nghĩ vậy.
Tất cả trên đây là phát hiện của riêng tôi, nếu có bất cứ điều gì sai với chúng, xin vui lòng cảnh báo tôi bằng ý kiến của bạn.