Trong bài viết cuối cùng của chúng tôi về con trỏ trong PostgreSQL, chúng tôi đã nói về xpressions có thể ommon (CTE). Hôm nay, chúng tôi tiếp tục khám phá các lựa chọn thay thế mới cho con trỏ bằng cách sử dụng một tính năng ít được biết đến của PostgreSQL.
Chúng tôi sẽ sử dụng dữ liệu mà chúng tôi đã nhập trong bài viết trước (được liên kết ở trên). Tôi sẽ đợi một lát để bạn làm theo quy trình tại đó.
Hiểu chưa? Được rồi.
Dữ liệu là một biểu đồ phân loại của thế giới tự nhiên. Xin nhắc lại từ sinh học trung học cơ bản, dữ liệu đó được Carl Linnaeus sắp xếp thành Vương quốc, Ngành, Lớp, Thứ tự, Gia đình, Chi và Loài. Tất nhiên, khoa học đã tiến rất nhanh trong 250 năm qua, vì vậy biểu đồ phân loại có độ sâu 21 bậc. Chúng tôi tìm thấy cây phân cấp trong một bảng (không có gì đáng ngạc nhiên) được gọi là itis.hierarchy .
Chủ đề của bài viết này là cách sử dụng ltrees trong PostgreSQL. Cụ thể, cách sử dụng chúng để duyệt một tập bản ghi phức tạp rất hiệu quả. Theo nghĩa đó, chúng ta có thể coi chúng là một đại diện khác cho con trỏ.
Dữ liệu không được sắp xếp (rất tiếc cho chúng tôi) ở định dạng ltree, vì vậy chúng tôi sẽ biến đổi nó một chút vì lợi ích của bài viết.
Trước tiên, bạn sẽ phải cài đặt ltree trong cơ sở dữ liệu mà bạn đang sử dụng để theo dõi bài viết này. Tất nhiên, bạn cần phải là một siêu người dùng để cài đặt các tiện ích mở rộng.
TẠO MỞ RỘNG NẾU KHÔNG TỒN TẠI ltree;
Bây giờ chúng tôi sẽ sử dụng tiện ích mở rộng này để cung cấp một số tra cứu rất hiệu quả. Chúng tôi sẽ cần chuyển đổi dữ liệu thành một bảng tra cứu. Để thực hiện chuyển đổi này, chúng tôi sẽ sử dụng kỹ thuật CTE mà chúng tôi đã đề cập trong bài viết trước. Đồng thời, chúng ta sẽ thêm các tên Latinh và tên tiếng Anh vào cây phân loại. Điều này sẽ giúp chúng tôi tra cứu các mục theo số, tên Latinh hoặc tên tiếng Anh.
- Chúng tôi cần một chức năng trợ giúp nhỏ để loại bỏ các tên nhãn bất hợp pháp.CREATE HOẶC THAY THẾ CHỨC NĂNG dải_label (văn bản nhãn) RETURNS TEXTAS $$ - đảm bảo tất cả các ký tự trong nhãn đều hợp pháp CHỌN CHỌN regexp_replace (regexp_replace (regexp_replace (regexp_replace (- loại bỏ bất kỳ thứ gì không phải alnum (vâng, điều này có thể chính xác hơn) thelabel), '[^ [:alnum:]]', '_', 'g'), - hợp nhất các dấu gạch dưới '_ +', '_', 'g'), - dấu gạch dưới ở đầu / cuối dải '^ _ *', '', 'g'), '_ * $', '', 'g'); $$ LANGUAGE sql; TẠO CHẾ ĐỘ XEM VẬT LIỆU itis.world_view ASWITH RECURSIVE world AS (- Bắt đầu với các vương quốc cơ bản CHỌN h1.tsn, h1.parent_tsn, h1.tsn ::text numeric_taxonomy, - Không có gì đảm bảo rằng sẽ có tên văn bản COALESCE (l1.completename, h1.tsn ::text, '') ::text latin_taxonomy, - và một lần nữa không đảm bảo tên tiếng Anh thông dụng COALESCE (v1.vernacular_name, low (l1.completename), h1. tsn ::text, 'una') ::text english_taxonomy FROM itis.hierarchy h1 LEFT JOIN itis.longnames l1 ON h1.tsn =l1.tsn LEFT JOIN itis.vernaculars v1 ON (h1.tsn, 'English') =( v1.tsn, v1.language) WHERE h1.parent_tsn =0 UNION TẤT CẢ CHỌN h1.tsn, h1.parent_tsn, w1.numeric_taxonomy || '.' || h1.tsn, w1.latin_taxonomy || '.' || COALESCE (strip_label (l1.completename), h1.tsn ::text, 'una'), w1.english_taxonomy || '.' || strip_label (COALESCE (v1.vernacular_name, low (l1.completename), h1.tsn ::text, 'una')) TỪ itis.hie rarchy h1 JOIN world w1 ON h1.parent_tsn =w1.tsn LEFT JOIN itis.longnames l1 ON h1.tsn =l1.tsn LEFT JOIN - chỉ cần thay đổi cài đặt này thành "itis.vernaculars v1" để cho phép nhiều ngôn ngữ và tất cả các ngôn ngữ. (Hàng triệu bản ghi.) (SELECT tsn, min (vernacular_name) vernacular_name FROM itis.vernaculars WHERE language ='English' GROUP BY tsn) v1 ON (h1.tsn) =(v1.tsn)) CHỌN w2.tsn, w2. arent_tsn, w2.numeric_taxonomy ::ltree, w2.latin_taxonomy ::ltree latin_taxonomy, w2.english_taxonomy ::ltree english_taxonomyFROM world w2ORDER BY w2.numeric_taxonomyWITH NO DATA;
Hãy dừng lại một chút và ngửi hương hoa trong câu hỏi này. Đối với người mới bắt đầu, chúng tôi đã tạo nó mà không điền bất kỳ dữ liệu nào. Điều này giúp chúng tôi có cơ hội giải quyết bất kỳ vấn đề cú pháp nào trước khi tạo ra nhiều dữ liệu vô ích. Chúng tôi đang sử dụng tính chất lặp đi lặp lại của biểu thức bảng chung để kết hợp một cấu trúc khá sâu ở đây và chúng tôi có thể dễ dàng mở rộng nó để bao gồm nhiều ngôn ngữ hơn bằng cách thêm dữ liệu vào bảng vernaculars. Chế độ xem cụ thể hóa cũng có một số đặc điểm hiệu suất thú vị. Nó sẽ cắt bớt và xây dựng lại bảng bất cứ khi nào REFRESH MATERIALIZED VIEW được gọi là.
Điều chúng tôi sẽ làm tiếp theo là làm mới thế giới quan của chúng tôi. Chủ yếu là vì thỉnh thoảng làm điều đó là tốt cho sức khỏe. Nhưng trong trường hợp này, những gì nó thực sự làm là điền vào chế độ xem vật thể hóa với dữ liệu từ itis lược đồ.
REFRESH MATERIALIZED VIEW itis.world_view; Quá trình này sẽ mất vài phút để tạo hơn 600 nghìn hàng từ dữ liệu.
Một số hàng đầu tiên sẽ giống như sau:
┌────────────┬─────────┬───────────────────────────────────────────────────────────────────────────────┐
│ parent_tsn │ tsn │ english_taxonomy │
├────────────┼─────────┼───────────────────────────────────────────────────────────────────────────────┤
│ 768374 │ 1009037 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.gastrosericus.gastrosericus…│
│ │ │…_xanthophilus │
│ 768374 │ 1009038 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.gastrosericus.gastrosericus…│
│ │ │…_zoyphion │
│ 768374 │ 1009039 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.gastrosericus.gastrosericus…│
│ │ │…_zyx │
│ 768216 │ 768387 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.holotachysphex │
│ 768387 │ 1009040 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.holotachysphex.holotachysph…│
│ │ │…ex_holognathus │
└────────────┴─────────┴───────────────────────────────────────────────────────────────────────────────┘ Trong một phương pháp phân loại, biểu đồ sẽ trông giống như sau:
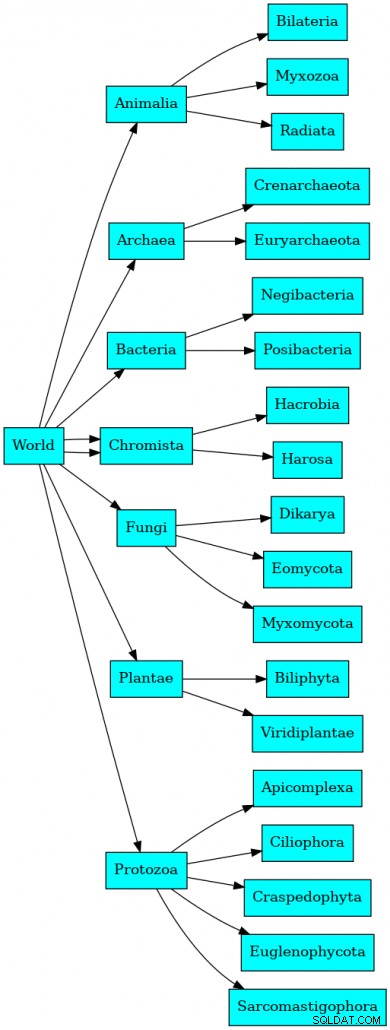
Tất nhiên, nó thực sự sẽ sâu 21 cấp và tổng cộng hơn 600 nghìn bản ghi.
Bây giờ chúng ta đến phần thú vị! ltrees cung cấp một cách để thực hiện một số truy vấn rất phức tạp trên một hệ thống phân cấp. Trợ giúp cho điều đó có trong tài liệu PostgreSQL, vì vậy chúng tôi sẽ không đi sâu vào vấn đề này ở đây. Để hiểu (rất nhanh), mỗi đoạn của ltree được gọi là một nhãn. Vì vậy, ltree kingdom.phylum.class.order.family.genus.species có 7 nhãn.
Các truy vấn chống lại một ltree sử dụng một ký hiệu đặc biệt giống như các biểu thức chính quy ở một dạng giới hạn.
Dưới đây là một ví dụ đơn giản:Animalia.*.Homo_sapiens
Vì vậy, một truy vấn để tìm kiếm loài người trên thế giới sẽ như thế này:
SELECT tsn, parent_tsn, latin_taxonomy, english_taxonomy
FROM itis.world_view WHERE latin_taxonomy ~ 'Animalia.*.Homo_sapiens'; Kết quả mong đợi:
┌────────┬────────────┬────────────────────────────────────────────────┬─────────────────────────────────────────────┐
│ tsn │ parent_tsn │ latin_taxonomy │ english_taxonomy │
├────────┼────────────┼────────────────────────────────────────────────┼─────────────────────────────────────────────┤
│ 180092 │ 180091 │ Animalia.Bilateria.Deuterostomia.Chordata.Vert…│ animals.bilateria.deuterostomia.chordates.v…│
│ │ │…ebrata.Gnathostomata.Tetrapoda.Mammalia.Theria…│…ertebrates.gnathostomata.tetrapoda.mammals.…│
│ │ │….Eutheria.Primates.Haplorrhini.Simiiformes.Hom…│…theria.eutheria.primates.haplorrhini.simiif…│
│ │ │…inoidea.Hominidae.Homininae.Homo.Homo_sapiens │…ormes.hominoidea.Great_Apes.African_apes.ho…│
│ │ │ │…minoids.Human │
└────────┴────────────┴────────────────────────────────────────────────┴─────────────────────────────────────────────┘ Tất nhiên, PostgreSQL sẽ không bao giờ bỏ qua điều này. Có một tập hợp rộng rãi các toán tử, Chỉ mục, Phép biến đổi và Ví dụ.
Hãy xem qua một loạt các khả năng mà kỹ thuật này mở ra.
Bây giờ hãy tưởng tượng kỹ thuật này được áp dụng cho các kiểu dữ liệu phức tạp khác như số bộ phận, số nhận dạng phương tiện, hóa đơn cấu trúc vật liệu hoặc bất kỳ hệ thống phân loại nào khác. Không cần thiết phải hiển thị cấu trúc này cho người dùng cuối vì đường cong học tập phức tạp nghiêm ngặt để sử dụng nó trực tiếp. Nhưng hoàn toàn có thể xây dựng một màn hình “tra cứu” dựa trên một cấu trúc như thế này, rất mạnh mẽ và che giấu sự phức tạp của việc triển khai.
Đối với bài viết tiếp theo của chúng tôi trong loạt bài này, chúng tôi sẽ khám phá việc sử dụng các ngôn ngữ plug in. Trong bối cảnh tìm kiếm các lựa chọn thay thế cho con trỏ trong PostgreSQL, chúng tôi sẽ sử dụng ngôn ngữ mà chúng tôi lựa chọn để mô hình hóa dữ liệu theo cách phù hợp nhất cho nhu cầu của chúng tôi. Hẹn gặp lại các bạn lần sau!