Dựa trên một số giả định (sự không rõ ràng trong câu hỏi), tôi đề nghị:
SELECT upper(trim(t.full_name)) AS teacher
, m.study_month
, r.room_code AS room
, count(s.room_id) AS study_count
FROM teachers t
CROSS JOIN generate_series(date_trunc('month', now() - interval '12 month') -- 12!
, date_trunc('month', now())
, interval '1 month') m(study_month)
CROSS JOIN rooms r
LEFT JOIN ( -- parentheses!
studies s
JOIN teacher_contacts tc ON tc.id = s.teacher_contact_id -- INNER JOIN!
) ON tc.teacher_id = t.id
AND s.study_dt >= m.study_month
AND s.study_dt < m.study_month + interval '1 month' -- sargable!
AND s.room_id = r.id
GROUP BY t.id, m.study_month, r.id -- id is PK of respective tables
ORDER BY t.id, m.study_month, r.id;
Những điểm chính
-
Xây dựng một lưới của tất cả các kết hợp mong muốn với
CROSS JOIN. Và sau đóLEFT JOINvào các hàng hiện có. Có liên quan: -
Trong trường hợp của bạn, đó là sự kết hợp của một số bảng, vì vậy tôi sử dụng dấu ngoặc đơn trong
FROMdanh sách đếnLEFT JOINđến kết quả trong tổng sốINNER JOINtrong ngoặc đơn. Nó sẽ không chính xác thànhLEFT JOINcho từng bảng riêng biệt, bởi vì bạn sẽ bao gồm các lần truy cập vào các trận đấu từng phần và nhận được số lượng có thể không chính xác. -
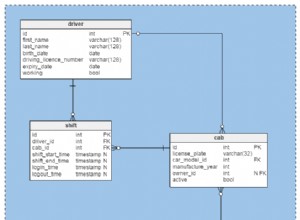
Giả sử tính toàn vẹn của tham chiếu và làm việc trực tiếp với các cột PK, chúng tôi không cần bao gồm
roomsvàteachersở phía bên trái lần thứ hai. Nhưng chúng tôi vẫn có sự kết hợp của hai bảng (studiesvàteacher_contacts). Vai trò củateacher_contactskhông rõ ràng đối với tôi. Thông thường, tôi mong đợi mối quan hệ giữa cácstudiesvàteacherstrực tiếp. Có thể được đơn giản hóa hơn nữa ... -
Chúng ta cần đếm một cột không rỗng ở phía bên trái để có được số lượng mong muốn. Thích
count(s.room_id) -
Để duy trì tốc độ này cho các bảng lớn, hãy đảm bảo rằng các vị từ của bạn là sargable . Và thêm các chỉ mục phù hợp .
-
Cột
teachershầu như không (đáng tin cậy) là duy nhất. Hoạt động với một ID duy nhất, tốt nhất là PK (nhanh hơn và đơn giản hơn). Tôi vẫn đang sử dụngteacherđể đầu ra phù hợp với kết quả mong muốn của bạn. Có thể là khôn ngoan nếu bao gồm một ID duy nhất, vì tên có thể trùng lặp. -
Bạn muốn:
Vì vậy, hãy bắt đầu với
date_trunc('month', now() - interval '12 month'(không phải 13). Điều đó làm tròn phần bắt đầu đã có và thực hiện những gì bạn muốn - chính xác hơn truy vấn ban đầu của bạn.
Vì bạn đã đề cập đến hiệu suất chậm, tùy thuộc vào định nghĩa bảng thực tế và phân phối dữ liệu, việc tổng hợp trước và tham gia sau có thể nhanh hơn , như trong câu trả lời có liên quan này:
SELECT upper(trim(t.full_name)) AS teacher
, m.mon AS study_month
, r.room_code AS room
, COALESCE(s.ct, 0) AS study_count
FROM teachers t
CROSS JOIN generate_series(date_trunc('month', now() - interval '12 month') -- 12!
, date_trunc('month', now())
, interval '1 month') mon
CROSS JOIN rooms r
LEFT JOIN ( -- parentheses!
SELECT tc.teacher_id, date_trunc('month', s.study_dt) AS mon, s.room_id, count(*) AS ct
FROM studies s
JOIN teacher_contacts tc ON s.teacher_contact_id = tc.id
WHERE s.study_dt >= date_trunc('month', now() - interval '12 month') -- sargable
GROUP BY 1, 2, 3
) s ON s.teacher_id = t.id
AND s.mon = m.mon
AND s.room_id = r.id
ORDER BY 1, 2, 3;
Về nhận xét kết thúc của bạn:
Rất có thể bạn có thể sử dụng dạng hai tham số của crosstab() để tạo ra kết quả mong muốn của bạn một cách trực tiếp và với hiệu suất tuyệt vời và không cần bắt đầu truy vấn trên. Cân nhắc: