Sử dụng cụm Galera là một cách tuyệt vời để xây dựng một môi trường có tính khả dụng cao cho MySQL hoặc MariaDB. Đó là một môi trường cụm không có gì được chia sẻ có thể được mở rộng thậm chí vượt quá 12-15 nút. Tuy nhiên, Galera có một số hạn chế. Nó tỏa sáng trong môi trường có độ trễ thấp và mặc dù nó có thể được sử dụng trên mạng WAN, hiệu suất bị giới hạn bởi độ trễ mạng. Hiệu suất Galera cũng có thể bị ảnh hưởng nếu một trong các nút bắt đầu hoạt động không chính xác. Ví dụ:tải quá nhiều trên một trong các nút có thể làm chậm nó, dẫn đến việc xử lý ghi chậm hơn và điều đó sẽ ảnh hưởng đến tất cả các nút khác trong cụm. Mặt khác, bạn hoàn toàn không thể điều hành một công việc kinh doanh mà không phân tích dữ liệu của mình. Thông thường, phân tích như vậy yêu cầu chạy các truy vấn nặng, điều này hoàn toàn khác với khối lượng công việc OLTP. Trong bài đăng trên blog này, chúng ta sẽ thảo luận về một cách dễ dàng để chạy các truy vấn phân tích cho dữ liệu được lưu trữ trong Galera Cluster dành cho MySQL hoặc MariaDB, theo cách mà nó không ảnh hưởng đến hiệu suất của cụm lõi.
Làm cách nào để chạy Truy vấn phân tích trên Galera Cluster?
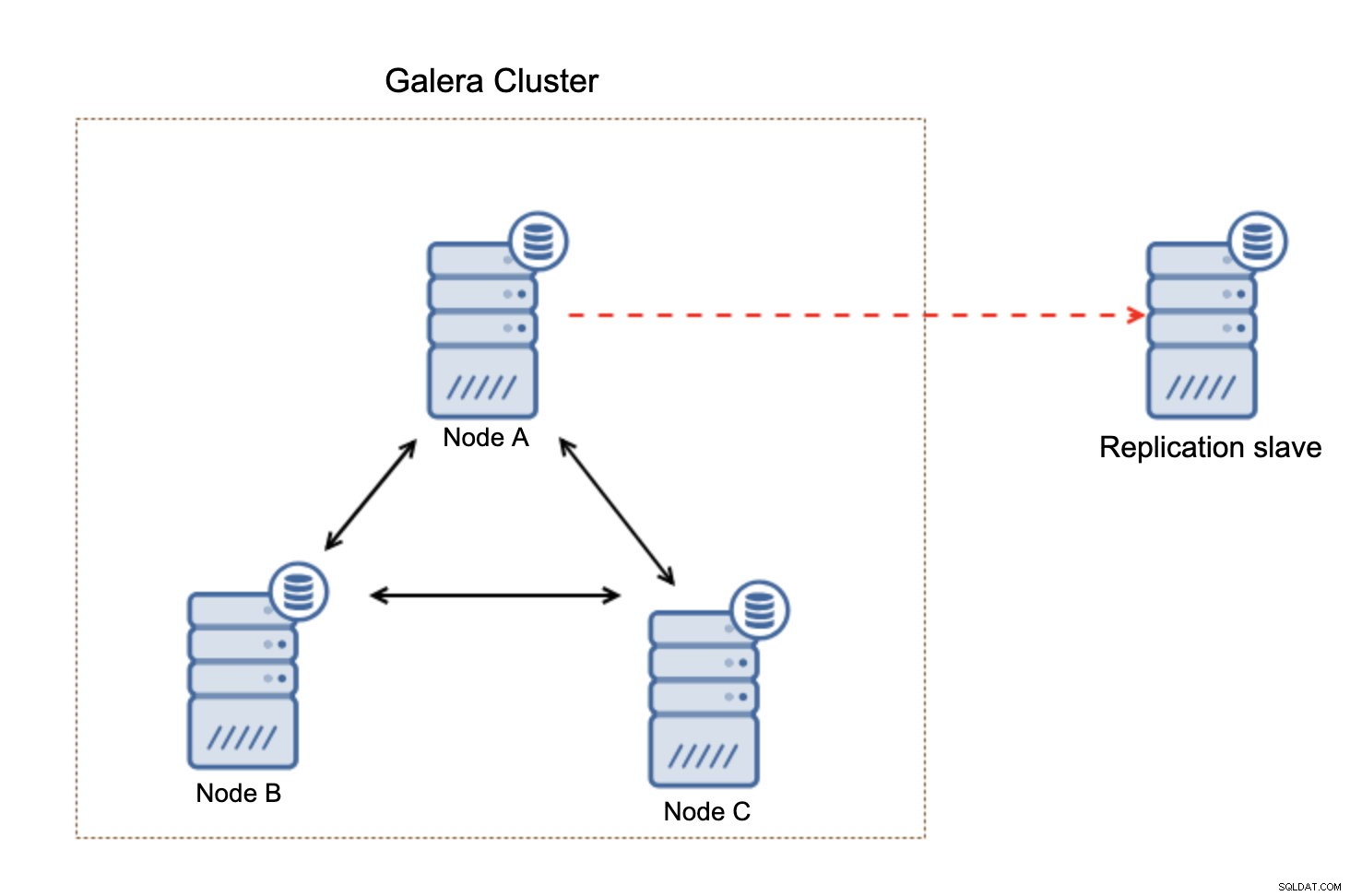
Như chúng tôi đã nêu, việc chạy các truy vấn dài trực tiếp trên một cụm Galera là có thể thực hiện được, nhưng có lẽ không phải là ý kiến hay. Phụ thuộc vào phần cứng, đây có thể là giải pháp chấp nhận được (nếu bạn sử dụng phần cứng mạnh và bạn sẽ không chạy khối lượng công việc phân tích đa luồng) nhưng ngay cả khi việc sử dụng CPU không phải là vấn đề, thực tế là một trong các nút sẽ có khối lượng công việc hỗn hợp ( OLTP và OLAP) sẽ đặt ra một số thách thức về hiệu suất. Các truy vấn OLAP sẽ loại bỏ dữ liệu cần thiết cho khối lượng công việc OLTP của bạn khỏi vùng đệm và điều này sẽ làm chậm các truy vấn OLTP của bạn. May mắn thay, có một cách đơn giản nhưng hiệu quả để tách khối lượng công việc phân tích khỏi các truy vấn thông thường - một nô lệ sao chép không đồng bộ.
Replication slave là một giải pháp rất đơn giản - tất cả những gì bạn cần chỉ là một máy chủ khác có thể được cung cấp và sao chép không đồng bộ phải được định cấu hình từ Galera Cluster tới nút đó. Với sao chép không đồng bộ, nô lệ sẽ không tác động đến phần còn lại của cụm theo bất kỳ cách nào. Không có vấn đề nếu nó được tải nhiều, sử dụng phần cứng khác (ít mạnh hơn), nó sẽ chỉ tiếp tục sao chép từ cụm lõi. Trường hợp xấu nhất là nô lệ nhân bản sẽ bắt đầu tụt lại phía sau nhưng sau đó tùy thuộc vào bạn để triển khai nhân bản đa luồng hay cuối cùng là mở rộng quy mô nô lệ nhân bản.
Khi nô lệ nhân bản đã được thiết lập và chạy, bạn nên chạy các truy vấn nặng hơn trên nó và giảm tải cụm Galera. Điều này có thể được thực hiện theo nhiều cách, tùy thuộc vào thiết lập và môi trường của bạn. Nếu bạn sử dụng ProxySQL, bạn có thể dễ dàng hướng các truy vấn đến máy chủ phân tích dựa trên máy chủ nguồn, người dùng, lược đồ hoặc thậm chí chính truy vấn đó. Nếu không, ứng dụng của bạn có thể gửi các truy vấn phân tích đến đúng máy chủ hay không.
Việc thiết lập một nô lệ sao chép không quá phức tạp nhưng nó vẫn có thể phức tạp nếu bạn không thành thạo MySQL và các công cụ như xtrabackup. Toàn bộ quá trình sẽ bao gồm việc thiết lập kho lưu trữ trên một máy chủ mới và cài đặt cơ sở dữ liệu MySQL. Sau đó, bạn sẽ phải cung cấp máy chủ lưu trữ đó bằng cách sử dụng dữ liệu từ cụm Galera. Bạn có thể sử dụng xtrabackup cho việc đó nhưng các công cụ khác như mydumper / myloader hoặc thậm chí mysqldump cũng sẽ hoạt động (miễn là bạn thực thi chúng một cách chính xác). Khi dữ liệu ở đó, bạn sẽ phải thiết lập bản sao giữa một nút Galera chính và nô lệ sao chép. Cuối cùng, bạn sẽ phải định cấu hình lại lớp proxy của mình để bao gồm nô lệ mới và định tuyến lưu lượng truy cập tới nó hoặc thực hiện các chỉnh sửa về cách ứng dụng của bạn kết nối với cơ sở dữ liệu để chuyển hướng một số tải đến nô lệ nhân bản.
Điều quan trọng cần ghi nhớ, thiết lập này không có khả năng phục hồi. Nếu nút Galera “chính” bị hỏng, liên kết sao chép sẽ bị phá vỡ và nó sẽ thực hiện một hành động thủ công để bổ sung bản sao khỏi nút chính khác trong cụm Galera.
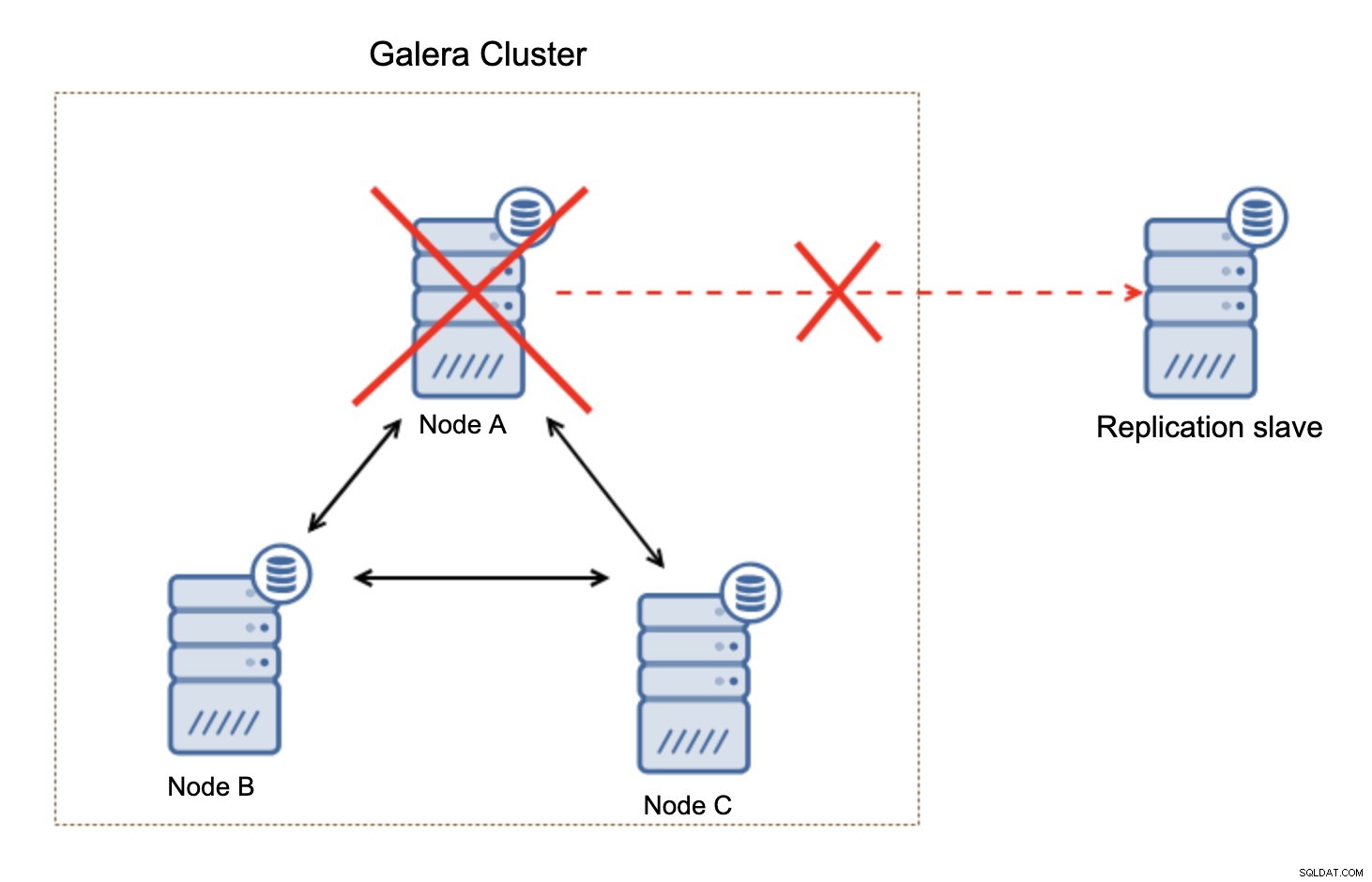
Đây không phải là vấn đề lớn, đặc biệt nếu bạn sử dụng bản sao với GTID (ID giao dịch toàn cầu) nhưng bạn phải xác định rằng bản sao bị hỏng và sau đó thực hiện thao tác thủ công.
Làm cách nào để thiết lập nô lệ không đồng bộ cho Galera Cluster bằng ClusterControl?
May mắn thay, nếu bạn sử dụng ClusterControl, toàn bộ quá trình có thể được tự động hóa và chỉ cần một vài cú nhấp chuột. Trạng thái ban đầu đã được thiết lập bằng cách sử dụng ClusterControl - một cụm Galera 3 nút với 2 nút ProxySQL và 2 nút Keepalived để có được tính khả dụng cao của cả cơ sở dữ liệu và lớp proxy.
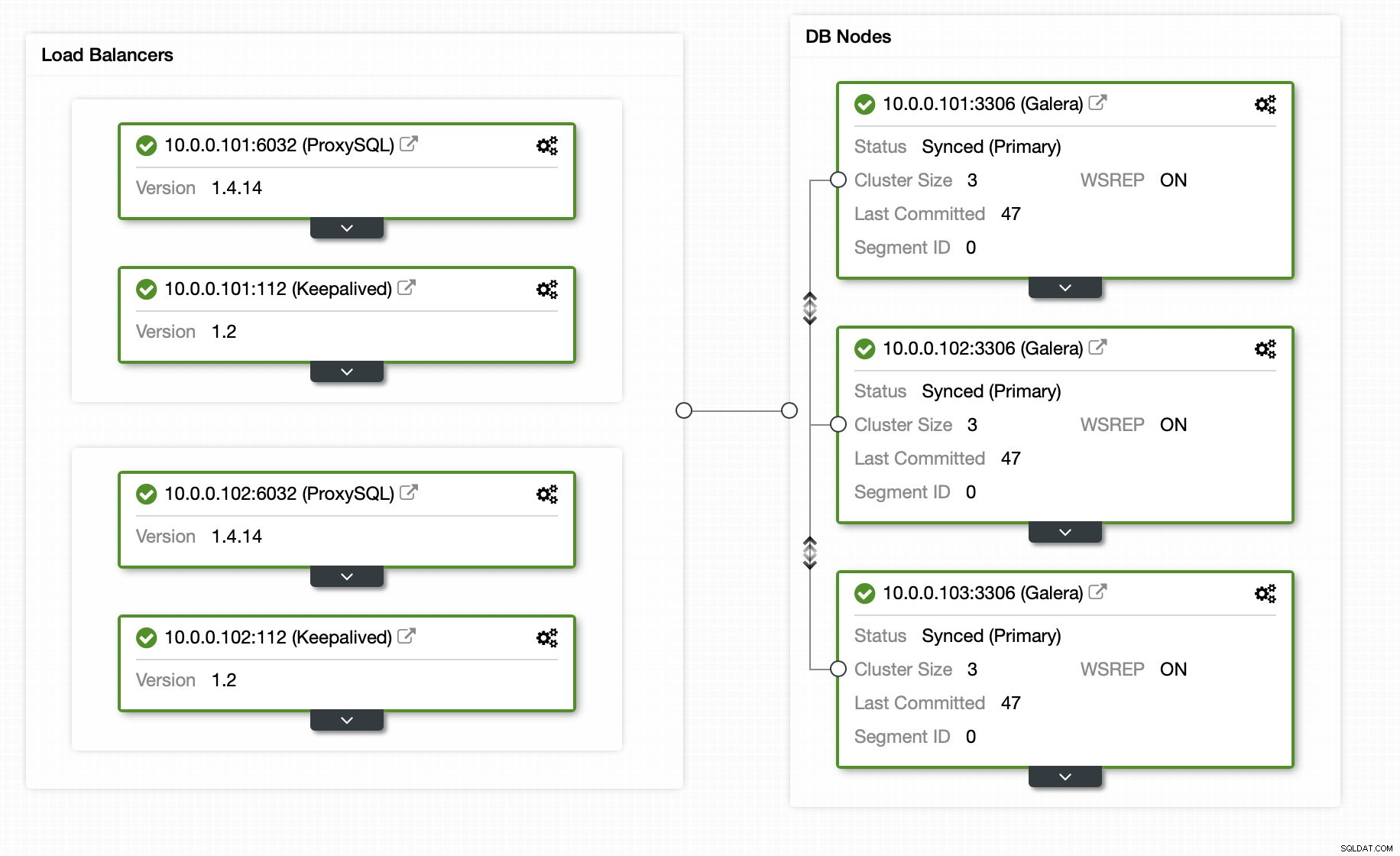
Thêm nô lệ sao chép chỉ bằng một cú nhấp chuột:
Bản sao, rõ ràng, yêu cầu các bản ghi nhị phân được kích hoạt. Nếu bạn chưa bật binlog trên các nút Galera của mình, bạn cũng có thể làm điều đó từ ClusterControl. Xin lưu ý rằng việc bật nhật ký nhị phân sẽ yêu cầu khởi động lại nút để áp dụng các thay đổi cấu hình.
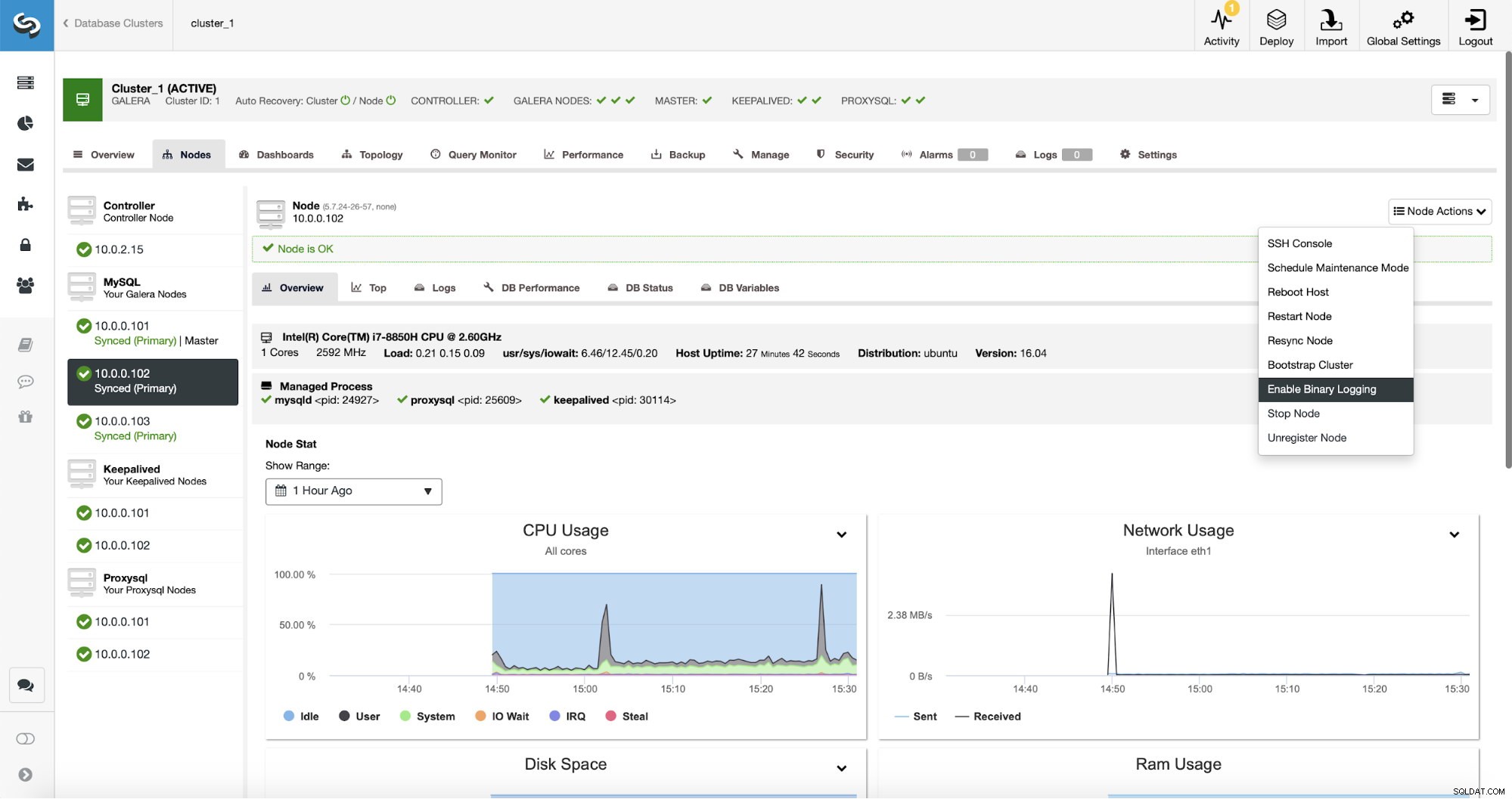
Ngay cả khi một nút trong cụm đã bật nhật ký nhị phân (được đánh dấu là “Chính” trên ảnh chụp màn hình ở trên), bạn vẫn nên bật nhật ký nhị phân trên ít nhất một nút nữa. ClusterControl có thể tự động chuyển đổi dự phòng nô lệ sao chép sau khi nó phát hiện ra rằng nút chính Galera bị lỗi, nhưng đối với điều đó, cần phải có một nút chính khác có nhật ký nhị phân được bật hoặc nó sẽ không có bất cứ điều gì để thất bại.
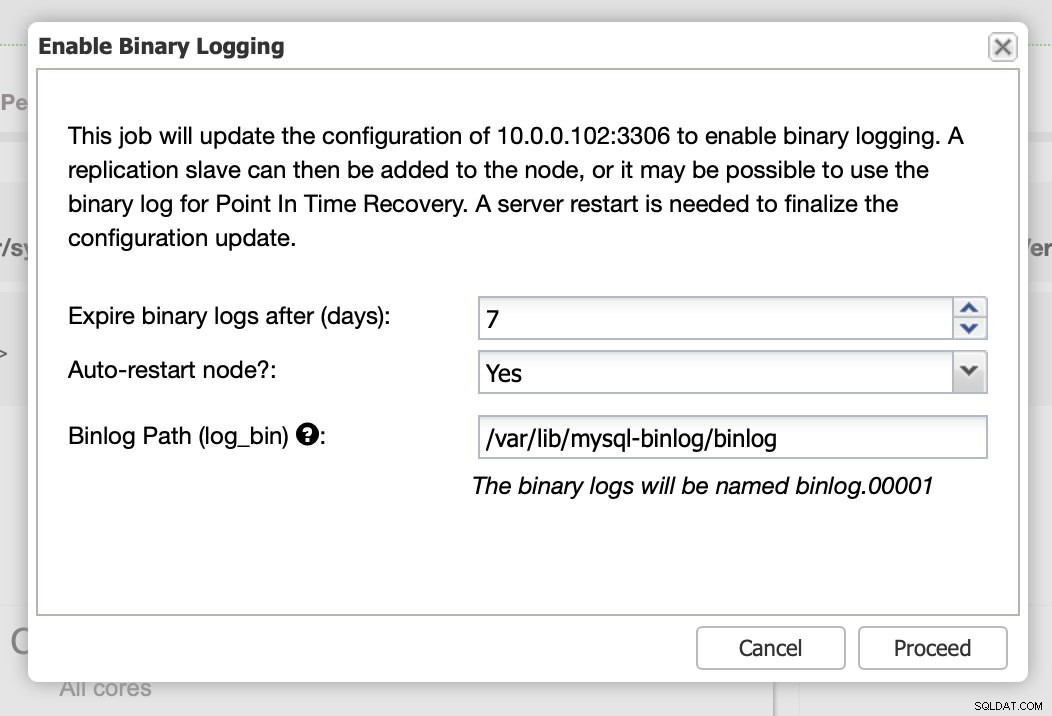
Như chúng tôi đã nêu, việc bật nhật ký nhị phân yêu cầu khởi động lại. Bạn có thể thực hiện ngay lập tức hoặc chỉ cần thực hiện thay đổi cấu hình và thực hiện khởi động lại vào lúc khác.
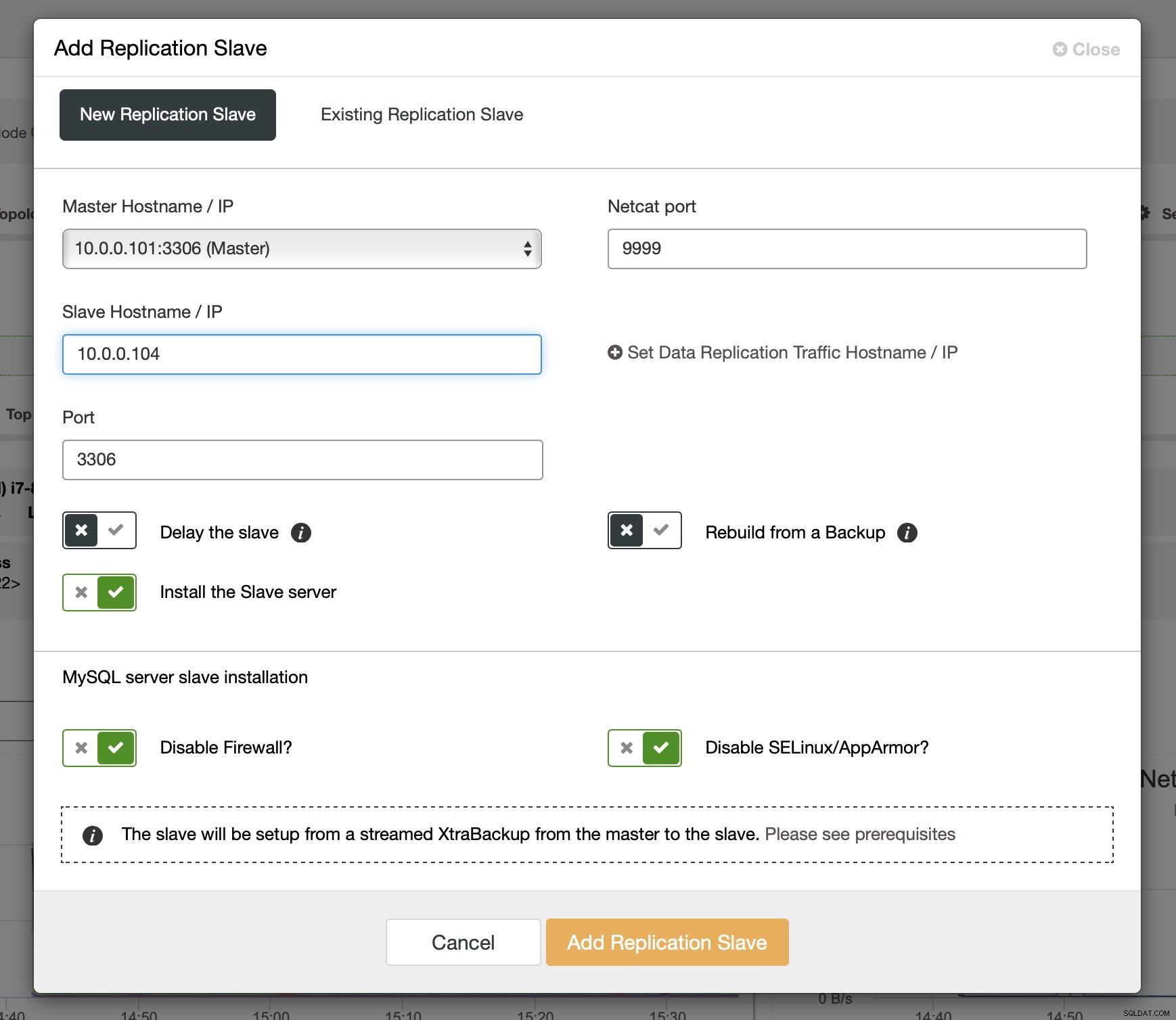
Sau khi các binlog đã được kích hoạt trên một số nút Galera, bạn có thể tiếp tục thêm nô lệ sao chép. Trong hộp thoại, bạn phải chọn máy chủ chính, chuyển tên máy chủ hoặc địa chỉ IP của máy chủ. Nếu bạn có các bản sao lưu gần đây trong tay (điều bạn nên làm), bạn có thể sử dụng một bản sao lưu để cung cấp nô lệ. Nếu không, ClusterControl sẽ cung cấp nó bằng cách sử dụng xtrabackup - tất cả dữ liệu chính gần đây sẽ được truyền trực tuyến tới máy chủ và sau đó bản sao sẽ được định cấu hình.
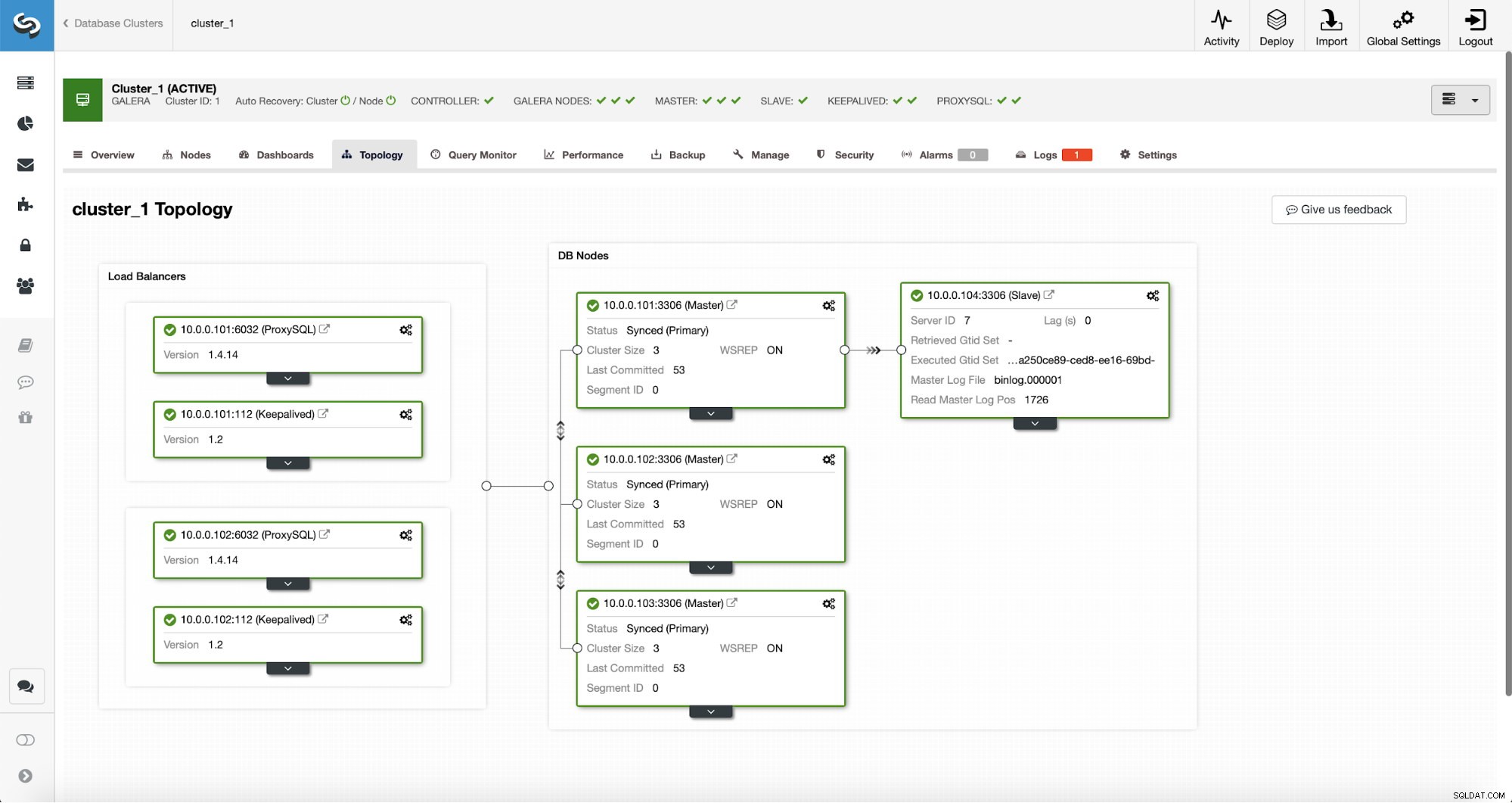
Sau khi hoàn thành công việc, một nô lệ sao chép đã được thêm vào cụm. Như đã nêu trước đó, nếu 10.0.0.101 chết, một máy chủ khác trong cụm Galera sẽ được chọn làm máy chủ và ClusterControl sẽ tự động phụ cấp 10.0.0.104 khỏi nút khác.
Khi chúng ta sử dụng ProxySQL, chúng ta cần phải cấu hình nó. Chúng tôi sẽ thêm một máy chủ mới vào ProxySQL.
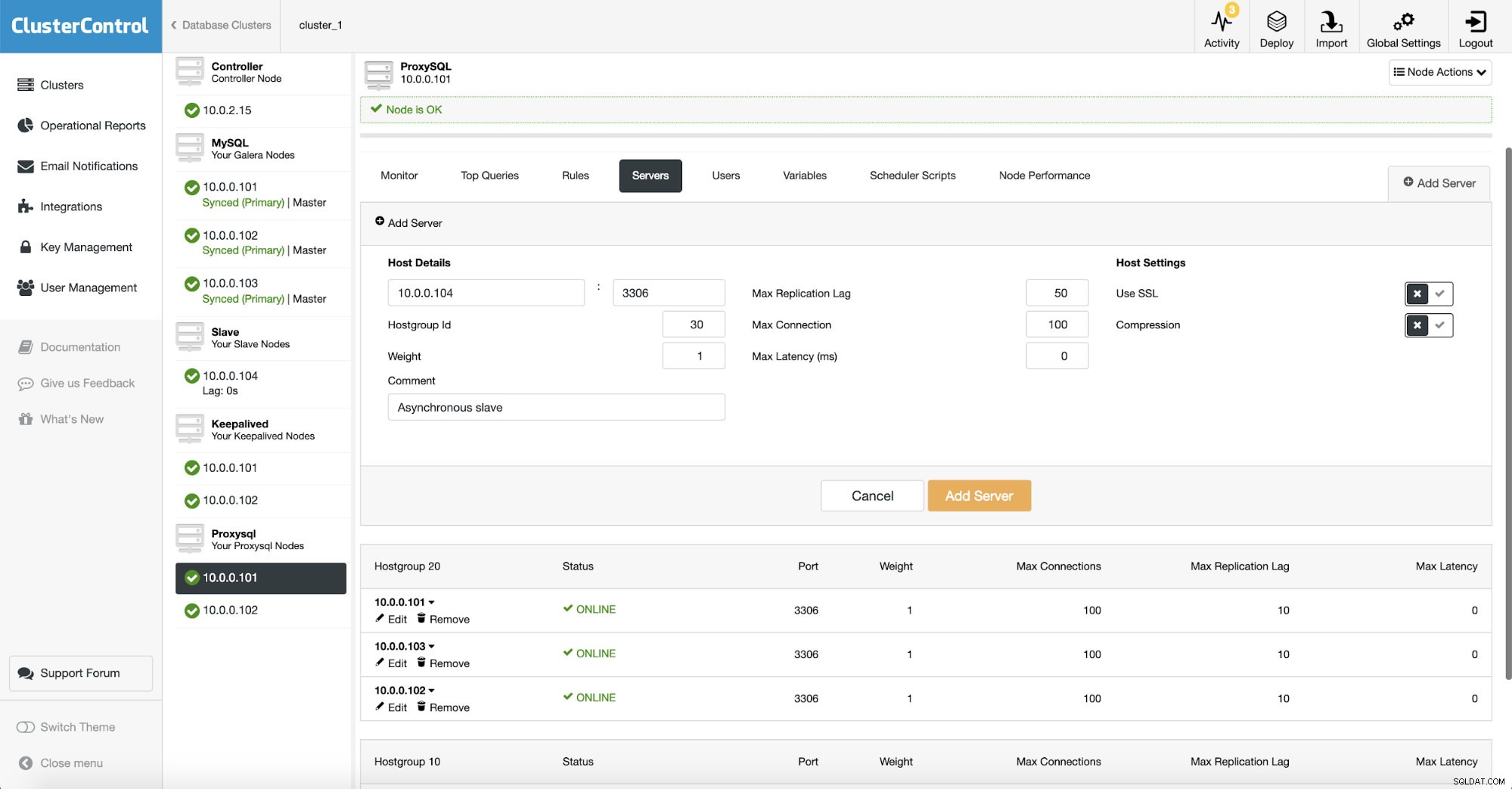
Chúng tôi đã tạo một nhóm máy chủ khác (30) nơi chúng tôi đặt nô lệ không đồng bộ của mình. Chúng tôi cũng tăng “Độ trễ sao chép tối đa” lên 50 giây so với mặc định. 10. Tùy thuộc vào yêu cầu kinh doanh của bạn mức độ trễ của nô lệ phân tích trước khi nó trở thành vấn đề.
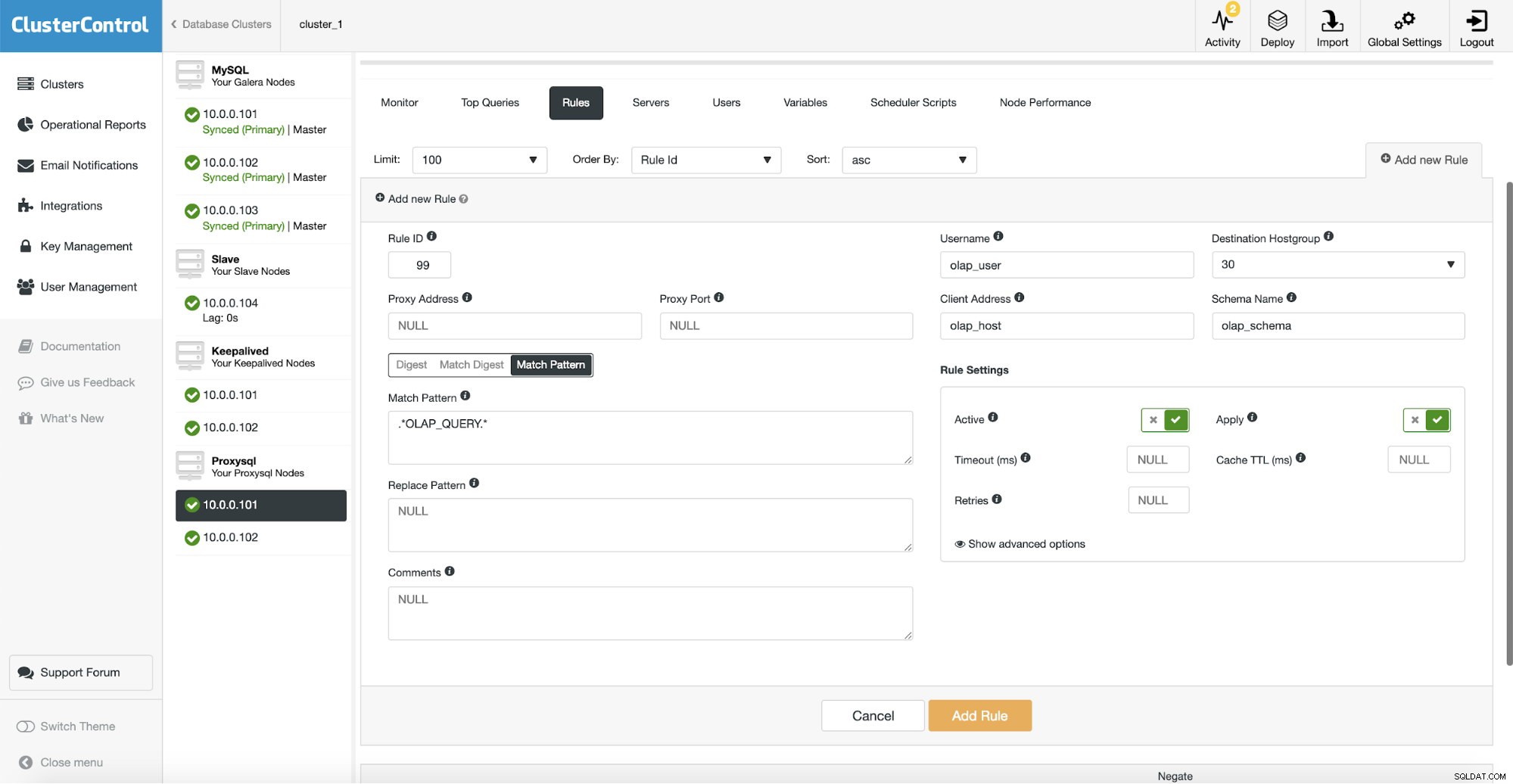
Sau đó, chúng tôi phải định cấu hình quy tắc truy vấn sẽ phù hợp với lưu lượng OLAP của chúng tôi và định tuyến nó đến nhóm máy chủ OLAP (30). Trên ảnh chụp màn hình ở trên, chúng tôi đã điền một số trường - điều này không bắt buộc. Thông thường, bạn sẽ cần sử dụng tối đa một hoặc hai trong số chúng. Ảnh chụp màn hình ở trên đóng vai trò là một ví dụ để chúng ta có thể dễ dàng thấy rằng bạn có thể so khớp các truy vấn bằng cách sử dụng lược đồ (nếu bạn có một lược đồ riêng với dữ liệu phân tích), tên máy chủ / IP (nếu truy vấn OLAP được thực thi từ một số máy chủ cụ thể), người dùng (nếu ứng dụng sử dụng người dùng cụ thể cho các truy vấn phân tích. Bạn cũng có thể đối sánh các truy vấn trực tiếp bằng cách chuyển một truy vấn đầy đủ hoặc bằng cách đánh dấu chúng bằng nhận xét SQL và để ProxySQL định tuyến tất cả các truy vấn bằng chuỗi “OLAP_QUERY” đến nhóm máy chủ phân tích của chúng tôi.
Như bạn có thể thấy, nhờ có ClusterControl, chúng tôi đã có thể triển khai một nô lệ sao chép cho Galera Cluster chỉ trong một vài cú nhấp chuột. Một số người có thể cho rằng MySQL không phải là cơ sở dữ liệu phù hợp nhất cho khối lượng công việc phân tích và chúng tôi có xu hướng đồng ý. Bạn có thể dễ dàng mở rộng thiết lập này bằng cách sử dụng ClickHouse và bằng cách thiết lập một bản sao từ nô lệ không đồng bộ sang kho dữ liệu cột ClickHouse để có hiệu suất tốt hơn nhiều cho các truy vấn phân tích. Chúng tôi đã mô tả thiết lập này trong một trong những bài đăng trên blog trước đó.