Trong hai bài trước của loạt bài này, chúng ta đã thảo luận về cách sử dụng Python và SQLAlchemy để thực hiện quy trình ETL. Hôm nay chúng ta sẽ làm tương tự, nhưng lần này sử dụng Python và SQL Alchemy không có lệnh SQL ở dạng văn bản. Điều này sẽ cho phép chúng tôi sử dụng SQLAlchemy bất kể công cụ cơ sở dữ liệu mà chúng tôi được kết nối. Vì vậy, hãy bắt đầu.
Hôm nay chúng ta sẽ thảo luận về cách thực hiện quy trình ETL bằng Python và SQLAlchemy. Chúng tôi sẽ tạo một tập lệnh để trích xuất dữ liệu hàng ngày từ cơ sở dữ liệu hoạt động của chúng tôi, chuyển đổi nó và sau đó tải vào kho dữ liệu của chúng tôi.
Đây là bài viết thứ ba trong loạt bài này. Nếu bạn chưa đọc hai bài viết đầu tiên (Sử dụng Python và MySQL trong Quy trình ETL và SQLAlchemy), tôi thực sự khuyến khích bạn làm như vậy trước khi tiếp tục.
Toàn bộ loạt bài này là phần tiếp theo của loạt bài kho dữ liệu của chúng tôi:
- Tạo DWH, Phần thứ nhất:Mô hình dữ liệu kinh doanh đăng ký
- Tạo DWH, Phần hai:Mô hình dữ liệu kinh doanh đăng ký
- Tạo kho dữ liệu, Phần 3:Mô hình dữ liệu kinh doanh đăng ký
Được rồi, bây giờ chúng ta hãy bắt đầu vào chủ đề của ngày hôm nay. Trước tiên, hãy xem xét các mô hình dữ liệu.
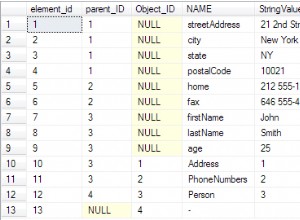
Mô hình dữ liệu
Mô hình dữ liệu cơ sở dữ liệu hoạt động (trực tiếp)
Mô hình dữ liệu DWH
Đây là hai mô hình dữ liệu mà chúng tôi sẽ sử dụng. Để biết thêm thông tin về kho dữ liệu (DWH), hãy xem các bài viết sau:
- Giản đồ Ngôi sao
- Lược đồ bông tuyết
- Lược đồ ngôi sao so với Lược đồ bông tuyết
Tại sao sử dụng SQLAlchemy?
Toàn bộ ý tưởng đằng sau SQLAlchemy là sau khi chúng tôi nhập cơ sở dữ liệu, chúng tôi không cần mã SQL cụ thể cho công cụ cơ sở dữ liệu liên quan. Thay vào đó, chúng ta có thể nhập các đối tượng vào SQLAlchemy và sử dụng cú pháp SQLAlchemy cho các câu lệnh. Điều đó sẽ cho phép chúng tôi sử dụng cùng một ngôn ngữ bất kể chúng tôi được kết nối với công cụ cơ sở dữ liệu nào. Ưu điểm chính ở đây là nhà phát triển không cần quan tâm đến sự khác biệt giữa các công cụ cơ sở dữ liệu khác nhau. Chương trình SQLAlchemy của bạn sẽ hoạt động giống hệt nhau (với những thay đổi nhỏ) nếu bạn chuyển sang một công cụ cơ sở dữ liệu khác.
Tôi đã quyết định chỉ sử dụng các lệnh SQLAlchemy và danh sách Python để giao tiếp với bộ nhớ tạm thời và giữa các cơ sở dữ liệu khác nhau. Lý do chính đằng sau quyết định này là 1) danh sách Python nổi tiếng và 2) mã có thể đọc được đối với những người không có kỹ năng Python.
Điều này không có nghĩa là SQLAlchemy là hoàn hảo. Nó có những hạn chế nhất định mà chúng ta sẽ thảo luận sau. Bây giờ, chúng ta hãy xem mã bên dưới:

Chạy tập lệnh và kết quả
Đây là lệnh Python được sử dụng để gọi tập lệnh của chúng tôi. Tập lệnh kiểm tra dữ liệu trong cơ sở dữ liệu hoạt động, so sánh các giá trị với DWH và nhập các giá trị mới. Trong ví dụ này, chúng tôi đang cập nhật các giá trị trong hai bảng thứ nguyên và một bảng dữ kiện; tập lệnh trả về kết quả đầu ra thích hợp. Toàn bộ tập lệnh được viết để bạn có thể chạy nó nhiều lần trong ngày. Nó sẽ xóa dữ liệu "cũ" cho ngày đó và thay thế bằng dữ liệu mới.
Hãy phân tích toàn bộ tập lệnh, bắt đầu từ phần trên cùng.
Nhập SQLAlchemy
Điều đầu tiên chúng tôi cần làm là nhập các mô-đun mà chúng tôi sẽ sử dụng trong tập lệnh. Thông thường, bạn sẽ nhập các mô-đun của mình khi viết tập lệnh. Trong hầu hết các trường hợp, bạn sẽ không biết chính xác mô-đun nào bạn sẽ cần ngay từ đầu.
from datetime import date # import SQLAlchemy from sqlalchemy import create_engine, select, MetaData, Table, and_, func, case
Chúng tôi đã nhập datetime của Python mô-đun, cung cấp cho chúng ta các lớp hoạt động với ngày tháng.
Tiếp theo, chúng ta có sqlalchemy mô-đun. Chúng tôi sẽ không nhập toàn bộ mô-đun, chỉ nhập những thứ chúng tôi cần - một số thứ cụ thể cho SQLAlchemy (create_engine , MetaData , Table ), một số phần câu lệnh SQL (select , and_ , case ) và func , cho phép chúng tôi sử dụng các hàm như count () và sum () .
Kết nối với Cơ sở dữ liệu
Chúng tôi sẽ cần kết nối với hai cơ sở dữ liệu trên máy chủ của mình. Chúng tôi có thể kết nối với nhiều cơ sở dữ liệu hơn (MySQL, SQL Server hoặc bất kỳ cơ sở dữ liệu nào khác) từ các máy chủ khác nhau nếu cần. Trong trường hợp này, cả hai cơ sở dữ liệu đều là cơ sở dữ liệu MySQL và được lưu trữ trên máy cục bộ của tôi.
# connect to databases
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
engine_dwh = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_dwh')
connection_dwh = engine_dwh.connect()
metadata = MetaData(bind=None)
Chúng tôi đã tạo hai công cụ và hai kết nối. Tôi sẽ không đi vào chi tiết ở đây vì chúng tôi đã giải thích một chút về vấn đề này trong bài viết trước.
Đang cập nhật dim_time Kích thước
Mục tiêu:Chèn ngày hôm qua nếu ngày đó chưa được chèn vào bảng.
Trong tập lệnh của mình, chúng tôi sẽ cập nhật hai bảng thứ nguyên với các giá trị mới. Phần còn lại của chúng theo cùng một mô hình, vì vậy chúng tôi sẽ chỉ xem xét vấn đề này một lần; chúng ta không cần phải viết lại mã gần giống nhau vài lần nữa.
Ý tưởng rất đơn giản. Chúng tôi sẽ luôn chạy tập lệnh để chèn dữ liệu mới cho ngày hôm qua. Do đó, chúng ta cần kiểm tra xem ngày đó có được chèn vào bảng thứ nguyên hay không. Nếu nó đã ở đó, chúng tôi sẽ không làm gì cả; nếu không, chúng tôi sẽ thêm nó. Hãy xem mã để cập nhật dim_time bảng.
Trước tiên, chúng tôi sẽ kiểm tra xem ngày đó có tồn tại hay không. Nếu nó không tồn tại, chúng tôi sẽ thêm nó. Chúng tôi bắt đầu với việc lưu trữ ngày hôm qua trong một biến. Trong Python, bạn làm theo cách này:
yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = str(yesterday)
Dòng đầu tiên lấy ngày hiện tại, chuyển nó thành giá trị số, lấy giá trị đó trừ đi 1 và chuyển giá trị số đó thành một ngày ( hôm qua =hôm nay - 1 ). Dòng thứ hai lưu trữ ngày tháng ở định dạng văn bản.
Tiếp theo, chúng tôi sẽ kiểm tra xem ngày đã có trong cơ sở dữ liệu chưa:
table_dim_time = Table('dim_time', metadata, autoload = True, autoload_with = engine_dwh)
stmt = select([table_dim_time]).where(table_dim_time.columns.time_date == yesterday_str)
result = connection_dwh.execute(stmt).fetchall()
date_exists = len(result)
Sau khi tải bảng, chúng tôi sẽ chạy một truy vấn sẽ trả về tất cả các hàng từ bảng thứ nguyên trong đó giá trị ngày / giờ bằng ngày hôm qua. Kết quả có thể có 0 (không có ngày như vậy trong bảng) hoặc 1 hàng (ngày đã có trong bảng).
Nếu ngày chưa có trong bảng, chúng tôi sẽ sử dụng lệnh insert () để thêm ngày:
if date_exists == 0:
print("New value added.")
stmt = table_dim_time.insert().values(time_date=yesterday, time_year=yesterday.year, time_month=yesterday.month, time_week=yesterday.isocalendar()[1], time_weekday=yesterday.weekday())
connection_dwh.execute(stmt)
else:
print("No new values.")
Một điều mới ở đây mà tôi muốn lưu ý là cách sử dụng. .year , .month , .isocalendar()[1] và .weekday để có được thời gian hẹn hò.
Đang cập nhật dim_city Kích thước
Mục tiêu:Chèn các thành phố mới nếu có (tức là so sánh danh sách các thành phố trong cơ sở dữ liệu trực tiếp với danh sách các thành phố trong DWH và thêm những thành phố còn thiếu).
Đang cập nhật dim_time kích thước khá đơn giản. Chúng tôi chỉ đơn giản là kiểm tra xem một ngày có trong bảng hay không và chèn nó vào nếu nó chưa có ở đó. Để kiểm tra một giá trị trong cơ sở dữ liệu DWH, chúng tôi đã sử dụng một biến Python ( hôm qua ). Chúng tôi sẽ sử dụng lại quy trình đó, nhưng lần này là với các danh sách.
Vì không có cách nào dễ dàng để kết hợp các bảng từ các cơ sở dữ liệu khác nhau trong một truy vấn SQLAlchemy duy nhất, chúng tôi không thể sử dụng phương pháp được nêu trong Phần 1 của loạt bài này. Do đó, chúng tôi sẽ cần một đối tượng để lưu trữ các giá trị cần thiết để giao tiếp giữa hai cơ sở dữ liệu này. Tôi đã quyết định sử dụng danh sách vì chúng phổ biến và chúng thực hiện công việc.
Đầu tiên, chúng tôi sẽ tải country và city bảng từ cơ sở dữ liệu trực tiếp vào các đối tượng có liên quan.
# dim_city
print("\nUpdating... dim_city")
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
table_dim_city = Table('dim_city', metadata, autoload = True, autoload_with = engine_dwh)
Tiếp theo, chúng tôi sẽ tải dim_city bảng từ DWH thành một danh sách:
# load whole dwh table in the list stmt = select([table_dim_city]); table_dim_city_list = connection_dwh.execute(stmt).fetchall()
Sau đó, chúng tôi sẽ thực hiện tương tự đối với các giá trị từ cơ sở dữ liệu trực tiếp. Chúng tôi sẽ tham gia các bảng country và city vì vậy chúng tôi có tất cả dữ liệu cần thiết trong danh sách này:
# load all live values in the list stmt = select([table_city.columns.city_name, table_city.columns.postal_code, table_country.columns.country_name])\ .select_from(table_city\ .join(table_country)) table_city_list = connection_live.execute(stmt).fetchall()
Bây giờ chúng ta sẽ lặp lại danh sách chứa dữ liệu từ cơ sở dữ liệu trực tiếp. Đối với mỗi bản ghi, chúng tôi sẽ so sánh các giá trị (city_name , postal_code và country_name ). Nếu chúng tôi không tìm thấy những giá trị như vậy, chúng tôi sẽ thêm một bản ghi mới vào dim_city bảng.
# loop through live_db table
# for each record test if it is missing in the dwh table
new_values_added = 0
for city in table_city_list:
id = -1;
for dim_city in table_dim_city_list:
if city[0] == dim_city[1] and city[1] == dim_city[2] and city[2] == dim_city[3]:
id = dim_city[0]
if id == -1:
stmt = table_dim_city.insert().values(city_name=city[0], postal_code=city[1], country_name=city[2])
connection_dwh.execute(stmt)
new_values_added = 1
if new_values_added == 0:
print("No new values.")
else:
print("New value(s) added.")
Để xác định xem giá trị đã có trong DWH chưa, chúng tôi đã thử nghiệm kết hợp các thuộc tính phải là duy nhất. (Khóa chính từ cơ sở dữ liệu trực tiếp không giúp chúng tôi nhiều ở đây.) Chúng tôi có thể sử dụng mã tương tự để cập nhật các từ điển khác. Đó không phải là giải pháp đẹp nhất, nhưng nó vẫn là một giải pháp khá thanh lịch. Và nó sẽ làm chính xác những gì chúng ta cần.
Cập nhật fact_customer_subscribe Bảng
Mục tiêu:Nếu chúng tôi có dữ liệu cũ cho ngày hôm qua, hãy xóa dữ liệu đó trước. Thêm dữ liệu của ngày hôm qua vào DWH - bất kể chúng tôi đã xóa nội dung nào đó ở bước trước đó hay chưa.
Sau khi cập nhật tất cả các bảng thứ nguyên, chúng ta nên cập nhật bảng dữ kiện. Trong tập lệnh của chúng tôi, chúng tôi sẽ chỉ cập nhật một bảng dữ kiện. Lý do tương tự như trong phần trước:cập nhật các bảng khác sẽ tuân theo cùng một mẫu, vì vậy chúng tôi chủ yếu sẽ lặp lại mã.
Trước khi chèn giá trị vào bảng dữ kiện, chúng ta cần biết giá trị của các khóa liên quan từ bảng thứ nguyên. Để làm điều đó, chúng tôi sẽ tải lại các thứ nguyên vào danh sách và so sánh chúng với các giá trị từ cơ sở dữ liệu trực tiếp.
Điều đầu tiên chúng tôi sẽ làm là tải khách hàng và fact_customer_subscribed bảng thành các đối tượng:
# fact_customer_subscribed
print("\nUpdating... fact_customer_subscribed")
table_customer = Table('customer', metadata, autoload = True, autoload_with = engine_live)
table_fact_customer_subscribed = Table('fact_customer_subscribed', metadata, autoload = True, autoload_with = engine_dwh)
Bây giờ, chúng tôi sẽ cần tìm các khóa cho thứ nguyên thời gian liên quan. Vì chúng tôi luôn chèn dữ liệu cho ngày hôm qua, chúng tôi sẽ tìm kiếm ngày đó trong dim_time bảng và sử dụng ID của nó. Truy vấn trả về 1 hàng và ID ở vị trí đầu tiên (chỉ mục bắt đầu từ 0, vì vậy đó là result[0][0] ):
# find key for the dim_time dimension stmt = select([table_dim_time]).where(table_dim_time.columns.time_date == yesterday) result = connection_dwh.execute(stmt).fetchall() dim_time_id = result[0][0]
Vào thời điểm đó, chúng tôi sẽ xóa tất cả các bản ghi được liên kết khỏi bảng dữ kiện:
# delete any existing data in the fact table for that time dimension value stmt = table_fact_customer_subscribed.delete().where(table_fact_customer_subscribed.columns.dim_time_id == dim_time_id) connection_dwh.execute(stmt)
Được rồi, bây giờ chúng ta có ID của thứ nguyên thời gian được lưu trữ trong dim_time_id Biến đổi. Điều này thật dễ dàng vì chúng tôi chỉ có thể có một giá trị thứ nguyên thời gian. Câu chuyện sẽ khác đối với chiều thành phố. Trước tiên, chúng tôi sẽ tải tất cả các giá trị chúng ta cần - các giá trị mô tả duy nhất thành phố (không phải ID) và các giá trị tổng hợp:
# prepare data for insert
stmt = select([table_city.columns.city_name, table_city.columns.postal_code, table_country.columns.country_name, func.sum(case([(table_customer.columns.active == 1, 1)], else_=0)).label('total_active'), func.sum(case([(table_customer.columns.active == 0, 1)], else_=0)).label('total_inactive'), func.sum(case([(and_(table_customer.columns.active == 1, func.date(table_customer.columns.time_updated) == yesterday), 1)], else_=0)).label('daily_new'), func.sum(case([(and_(table_customer.columns.active == 0, func.date(table_customer.columns.time_updated) == yesterday), 1)], else_=0)).label('daily_canceled')])\
.select_from(table_customer\
.join(table_city)\
.join(table_country))\
.group_by(table_city.columns.city_name, table_city.columns.postal_code, table_country.columns.country_name)
Có một số điều tôi muốn nhấn mạnh về truy vấn ở trên:
-
func.sum(...)là SUM (...) từ "SQL tiêu chuẩn". -
case(...)cú pháp sử dụngand_trước các điều kiện chứ không phải giữa chúng. -
.label(...)các chức năng giống như bí danh SQL AS. - Chúng tôi đang sử dụng
\để chuyển sang dòng tiếp theo và tăng khả năng đọc của truy vấn. (Tin tôi đi, nó khá khó đọc nếu không có dấu gạch chéo - Tôi đã thử nó :)) -
.group_by(...)đóng vai trò là GROUP BY của SQL.
Tiếp theo, chúng tôi sẽ lặp lại mọi bản ghi được trả về bằng cách sử dụng truy vấn trước đó. Đối với mỗi bản ghi, chúng tôi sẽ so sánh các giá trị xác định duy nhất một thành phố (city_name , postal_code , country_name ) với các giá trị được lưu trữ trong danh sách được tạo từ DWH dim_city bàn. Nếu cả ba giá trị đều khớp, chúng tôi sẽ lưu trữ ID từ danh sách và sử dụng ID đó khi chèn dữ liệu mới. Bằng cách này, đối với mọi bản ghi, chúng tôi sẽ có ID cho cả hai thứ nguyên:
# loop through all new records
# use time dimension
# for each record find key for city dimension
# insert row
new_values = connection_live.execute(stmt).fetchall()
for new_value in new_values:
dim_city_id = -1;
for dim_city in table_dim_city_list:
if new_value[0] == dim_city[1] and new_value[1] == dim_city[2] and new_value[2] == dim_city[3]:
dim_city_id = dim_city[0]
if dim_city_id > 0:
stmt_insert = table_fact_customer_subscribed.insert().values(dim_city_id=dim_city_id, dim_time_id=dim_time_id, total_active=new_value[3], total_inactive=new_value[4], daily_new=new_value[5], daily_canceled=new_value[6])
connection_dwh.execute(stmt_insert)
dim_city_id = -1
print("Completed.")
Và thế là xong. Chúng tôi đã cập nhật DWH của mình. Tập lệnh sẽ dài hơn nhiều nếu chúng tôi cập nhật tất cả các bảng thứ nguyên và dữ kiện. Độ phức tạp cũng sẽ lớn hơn khi một bảng dữ kiện có liên quan đến nhiều bảng thứ nguyên hơn. Trong trường hợp đó, chúng tôi cần một cho vòng lặp cho mỗi bảng thứ nguyên.
Điều này không hoạt động!
Tôi đã rất thất vọng khi viết kịch bản này và sau đó phát hiện ra rằng những thứ như thế này sẽ không hoạt động:
stmt = select([table_city.columns.city_name])\ .select_from(table_city\ .outerjoin(table_dim_city, table_city.columns.city_name == table_dim_city.columns.city_name))\ .where(table_dim_city.columns.id.is_(None))
Trong ví dụ này, tôi đang cố gắng sử dụng các bảng từ hai cơ sở dữ liệu khác nhau. Nếu chúng tôi thiết lập hai kết nối riêng biệt, kết nối đầu tiên sẽ không "nhìn thấy" các bảng từ một kết nối khác. Nếu chúng tôi kết nối trực tiếp với máy chủ chứ không phải với cơ sở dữ liệu, chúng tôi sẽ không thể tải bảng.
Cho đến khi điều này thay đổi (hy vọng sẽ sớm xảy ra), bạn sẽ cần sử dụng một số loại cấu trúc (ví dụ như những gì chúng tôi đã làm hôm nay) để giao tiếp giữa hai cơ sở dữ liệu. Điều này làm phức tạp mã, vì bạn cần thay thế một truy vấn duy nhất bằng hai danh sách và lồng nhau for vòng lặp.
Chia sẻ suy nghĩ của bạn về SQLAlchemy và Python
Đây là bài viết cuối cùng trong loạt bài này. Nhưng ai biết được? Có thể chúng tôi sẽ thử một cách tiếp cận khác trong các bài viết sắp tới, vì vậy hãy chú ý theo dõi. Trong thời gian chờ đợi, hãy chia sẻ suy nghĩ của bạn về SQLAlchemy và Python kết hợp với cơ sở dữ liệu. Bạn nghĩ chúng tôi thiếu điều gì trong bài viết này? Bạn sẽ thêm gì? Hãy cho chúng tôi biết trong phần bình luận bên dưới.
Bạn có thể tải xuống tập lệnh hoàn chỉnh mà chúng tôi đã sử dụng trong bài viết này tại đây.
Và đặc biệt cảm ơn Dirk J Bosman (@dirkjobosman), người đã đề xuất loạt bài viết này.