SQLAlchemy giúp bạn làm việc với cơ sở dữ liệu bằng Python. Trong bài đăng này, chúng tôi cho bạn biết mọi thứ bạn cần biết để bắt đầu với mô-đun này.
Trong bài trước, chúng ta đã nói về cách sử dụng Python trong quy trình ETL. Chúng tôi tập trung vào việc hoàn thành công việc bằng cách thực thi các thủ tục được lưu trữ và truy vấn SQL. Trong bài viết này và bài viết tiếp theo, chúng tôi sẽ sử dụng một cách tiếp cận khác. Thay vì viết mã SQL, chúng tôi sẽ sử dụng bộ công cụ SQLAlchemy. Bạn cũng có thể sử dụng bài viết này một cách riêng biệt, như một phần giới thiệu nhanh về cách cài đặt và sử dụng SQLAlchemy.
Sẵn sàng? Hãy bắt đầu.
SQLAlchemy là gì?
Python nổi tiếng với số lượng và sự đa dạng của các mô-đun. Các mô-đun này làm giảm đáng kể thời gian viết mã của chúng tôi vì chúng thực hiện các quy trình cần thiết để đạt được một nhiệm vụ cụ thể. Có sẵn một số mô-đun làm việc với dữ liệu, bao gồm cả SQLAlchemy.
Để mô tả SQLAlchemy, tôi sẽ sử dụng một trích dẫn từ SQLAlchemy.org:
SQLAlchemy là bộ công cụ Python SQL và Object Relational Mapper cung cấp cho các nhà phát triển ứng dụng toàn bộ sức mạnh và tính linh hoạt của SQL.
Nó cung cấp một bộ đầy đủ về tính bền bỉ cấp doanh nghiệp nổi tiếng các mẫu, được thiết kế để truy cập cơ sở dữ liệu hiệu quả và hiệu suất cao, được điều chỉnh thành ngôn ngữ miền Pythonic và đơn giản.
Phần quan trọng nhất ở đây là một chút về ORM (trình ánh xạ quan hệ đối tượng), giúp chúng ta coi các đối tượng cơ sở dữ liệu là đối tượng Python chứ không phải danh sách.
Trước khi chúng ta đi xa hơn với SQLAlchemy, hãy tạm dừng và nói về ORM.
Ưu và nhược điểm của việc sử dụng ORM
So với SQL thô, ORM có những ưu và nhược điểm - và hầu hết những điều này cũng áp dụng cho SQLAlchemy.
Nội dung tốt:
- Tính di động của mã. ORM quan tâm đến sự khác biệt về cú pháp giữa các cơ sở dữ liệu.
- Chỉ một ngôn ngữ là cần thiết để xử lý cơ sở dữ liệu của bạn. Mặc dù, thành thật mà nói, đây không phải là động lực chính để sử dụng ORM.
- ORM đơn giản hóa mã của bạn , ví dụ. họ quan tâm đến các mối quan hệ và coi chúng như đồ vật, điều này thật tuyệt nếu bạn đã quen với OOP.
- Bạn có thể thao tác dữ liệu của mình trong chương trình .
Thật không may, mọi thứ đi kèm với một cái giá. Chuyện không hay về ORM:
- Trong một số trường hợp, ORM có thể chậm .
- Viết truy vấn phức tạp thậm chí có thể trở nên phức tạp hơn hoặc có thể dẫn đến các truy vấn chậm. Nhưng đây không phải là trường hợp khi sử dụng SQLAlchemy.
- Nếu bạn biết rõ về DBMS của mình, thì thật lãng phí thời gian để tìm hiểu cách viết cùng một nội dung trong ORM.
Bây giờ chúng ta đã xử lý chủ đề đó, hãy quay lại với SQLAlchemy.
Trước khi chúng ta bắt đầu ...
… Chúng ta hãy nhắc nhở bản thân về mục tiêu của bài viết này. Nếu bạn chỉ quan tâm đến việc cài đặt SQLAlchemy và cần hướng dẫn nhanh về cách thực hiện các lệnh đơn giản, bài viết này sẽ làm được điều đó. Tuy nhiên, các lệnh được trình bày trong bài viết này sẽ được sử dụng trong bài viết tiếp theo để thực hiện quy trình ETL và thay thế mã SQL (thủ tục được lưu trữ) và Python mà chúng tôi đã trình bày trong các bài viết trước.
Được rồi, bây giờ chúng ta hãy bắt đầu ngay từ đầu:với việc cài đặt SQLAlchemy.
Cài đặt SQLAlchemy
1. Kiểm tra xem mô-đun đã được cài đặt chưa
Để sử dụng mô-đun Python, bạn phải cài đặt nó (nghĩa là nếu nó chưa được cài đặt trước đó). Một cách để kiểm tra mô-đun nào đã được cài đặt là sử dụng lệnh này trong Python Shell:
help('modules')
Để kiểm tra xem một mô-đun cụ thể đã được cài đặt hay chưa, chỉ cần thử nhập mô-đun đó. Sử dụng các lệnh sau:
import sqlalchemy sqlalchemy.__version__
Nếu SQLAlchemy đã được cài đặt, thì dòng đầu tiên sẽ thực thi thành công. import là một lệnh Python tiêu chuẩn được sử dụng để nhập các mô-đun. Nếu mô-đun chưa được cài đặt, Python sẽ tạo ra một lỗi - thực sự là một danh sách các lỗi, bằng văn bản màu đỏ - mà bạn không thể bỏ lỡ :)
Lệnh thứ hai trả về phiên bản hiện tại của SQLAlchemy. Kết quả trả về như hình bên dưới:

Chúng tôi cũng sẽ cần một mô-đun khác và đó là PyMySQL . Đây là một thư viện máy khách MySQL nhẹ thuần-Python. Mô-đun này hỗ trợ mọi thứ chúng ta cần để làm việc với cơ sở dữ liệu MySQL, từ chạy các truy vấn đơn giản đến các hành động cơ sở dữ liệu phức tạp hơn. Chúng tôi có thể kiểm tra xem nó có tồn tại hay không bằng cách sử dụng help('modules') , như đã mô tả trước đây, hoặc sử dụng hai câu lệnh sau:
import pymysql pymysql.__version__
Tất nhiên, đây là những lệnh giống như chúng tôi đã sử dụng để kiểm tra xem SQLAlchemy đã được cài đặt hay chưa.
Điều gì sẽ xảy ra nếu SQLAlchemy hoặc PyMySQL chưa được cài đặt?
Nhập các mô-đun đã cài đặt trước đó không khó. Nhưng điều gì sẽ xảy ra nếu các mô-đun bạn cần chưa được cài đặt?
Một số mô-đun có gói cài đặt, nhưng chủ yếu bạn sẽ sử dụng lệnh pip để cài đặt chúng. PIP là một công cụ Python được sử dụng để cài đặt và gỡ cài đặt các mô-đun. Cách dễ nhất để cài đặt mô-đun (trong HĐH Windows) là:
- Sử dụng Command Prompt -> Run -> cmd .
- Định vị cho thư mục Python cd C:\ ... \ Python \ Python37 \ Scripts .
- Chạy lệnh pip
install(trong trường hợp của chúng tôi, chúng tôi sẽ chạypip install pyMySQLvàpip install sqlAlchemy.
PIP cũng có thể được sử dụng để gỡ cài đặt mô-đun hiện có. Để làm điều đó, bạn nên sử dụng pip uninstall .
2. Kết nối với Cơ sở dữ liệu
Mặc dù cài đặt mọi thứ cần thiết để sử dụng SQLAlchemy là điều cần thiết, nhưng nó không thú vị lắm. Nó cũng không thực sự là một phần của những gì chúng tôi quan tâm. Chúng tôi thậm chí còn chưa kết nối với cơ sở dữ liệu mà chúng tôi muốn sử dụng. Chúng tôi sẽ giải quyết vấn đề đó ngay bây giờ:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Sử dụng tập lệnh ở trên, chúng tôi sẽ thiết lập kết nối với cơ sở dữ liệu nằm trên máy chủ cục bộ của chúng tôi, subscription_live cơ sở dữ liệu.
( Lưu ý: Thay thế
Hãy xem qua tập lệnh, từng lệnh.
import sqlalchemy from sqlalchemy.engine import create_engine
Hai dòng này nhập mô-đun của chúng tôi và create_engine chức năng.
Tiếp theo, chúng tôi sẽ thiết lập kết nối với cơ sở dữ liệu nằm trên máy chủ của chúng tôi.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
Hàm create_engine tạo công cụ và sử dụng .connect() , kết nối với cơ sở dữ liệu. create_engine hàm sử dụng các tham số sau:
dialect+driver://username:password@host:port/database
Trong trường hợp của chúng tôi, phương ngữ là mysql , trình điều khiển là pymysql (đã được cài đặt trước đó) và các biến còn lại dành riêng cho (các) máy chủ và cơ sở dữ liệu mà chúng tôi muốn kết nối.
( Lưu ý: Nếu bạn đang kết nối cục bộ, hãy sử dụng localhost thay vì địa chỉ IP “cục bộ” của bạn, 127.0.0.1 và cổng thích hợp :3306 .)

Kết quả của lệnh print(engine_live.table_names()) được hiển thị trong hình trên. Đúng như mong đợi, chúng tôi nhận được danh sách tất cả các bảng từ cơ sở dữ liệu hoạt động / trực tiếp của chúng tôi.
3. Chạy lệnh SQL bằng SQLAlchemy
Trong phần này, chúng tôi sẽ phân tích các lệnh SQL quan trọng nhất, kiểm tra cấu trúc bảng và thực hiện tất cả bốn lệnh DML:CHỌN, CHÈN, CẬP NHẬT và XÓA.
Chúng ta sẽ thảo luận riêng về các câu lệnh được sử dụng trong tập lệnh này. Xin lưu ý rằng chúng tôi đã xem qua phần kết nối của tập lệnh này và chúng tôi đã liệt kê các tên bảng. Có những thay đổi nhỏ trong dòng này:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Chúng tôi vừa nhập mọi thứ chúng tôi sẽ sử dụng từ SQLAlchemy.
Bảng và cấu trúc
Chúng tôi sẽ chạy tập lệnh bằng cách nhập lệnh sau vào Python Shell:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Kết quả là tập lệnh được thực thi. Bây giờ chúng ta hãy phân tích phần còn lại của tập lệnh.
SQLAlchemy nhập thông tin liên quan đến bảng, cấu trúc và quan hệ. Để làm việc với thông tin đó, có thể hữu ích khi kiểm tra danh sách các bảng (và các cột của chúng) trong cơ sở dữ liệu:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Thao tác này chỉ trả về danh sách tất cả các bảng từ cơ sở dữ liệu được kết nối.
Lưu ý: table_names() phương thức trả về một danh sách các tên bảng cho động cơ đã cho. Bạn có thể in toàn bộ danh sách hoặc lặp lại nó bằng cách sử dụng một vòng lặp (như bạn có thể làm với bất kỳ danh sách nào khác).
Tiếp theo, chúng tôi sẽ trả về danh sách tất cả các thuộc tính từ bảng đã chọn. Phần có liên quan của tập lệnh và kết quả được hiển thị bên dưới:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
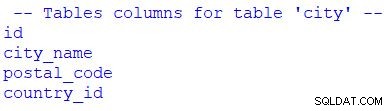
Bạn có thể thấy rằng tôi đã sử dụng for để lặp qua tập kết quả. Chúng tôi có thể thay thế table_city.c với table_city.columns .
Lưu ý: Quá trình tải mô tả cơ sở dữ liệu và tạo siêu dữ liệu trong SQLAlchemy được gọi là phản chiếu.
Lưu ý: MetaData là đối tượng lưu giữ thông tin về các đối tượng trong cơ sở dữ liệu, vì vậy các bảng trong cơ sở dữ liệu cũng được liên kết với đối tượng này. Nói chung, đối tượng này lưu trữ thông tin về lược đồ cơ sở dữ liệu trông như thế nào. Bạn sẽ sử dụng nó như một đầu mối liên hệ khi bạn muốn thực hiện các thay đổi đối với hoặc nhận thông tin chi tiết về lược đồ DB.
Lưu ý: Các thuộc tính autoload = True và autoload_with = engine_live nên được sử dụng để đảm bảo rằng các thuộc tính bảng sẽ được tải lên (nếu chúng chưa được tải lên).
CHỌN
Tôi không nghĩ mình cần giải thích mức độ quan trọng của câu lệnh SELECT :) Vì vậy, giả sử bạn có thể sử dụng SQLAlchemy để viết câu lệnh SELECT. Nếu bạn đã quen với cú pháp MySQL, sẽ mất một thời gian để thích nghi; Tuy nhiên, mọi thứ đều khá logic. Nói một cách đơn giản nhất có thể, tôi muốn nói rằng câu lệnh SELECT được cắt nhỏ và một số phần bị bỏ qua, nhưng mọi thứ vẫn theo thứ tự như cũ.
Bây giờ chúng ta hãy thử một vài câu lệnh SELECT.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
Câu lệnh đầu tiên là câu lệnh SELECT đơn giản trả về tất cả các giá trị từ bảng đã cho. Cú pháp của câu lệnh này rất đơn giản:Tôi đã đặt tên của bảng trong select() . Xin lưu ý rằng tôi đã:
- Đã chuẩn bị báo cáo -
stmt = select([table_city]. - Đã in báo cáo bằng
print(stmt), cho chúng tôi một ý tưởng hay về câu lệnh vừa được thực thi. Điều này cũng có thể được sử dụng để gỡ lỗi. - In kết quả bằng
print(connection_live.execute(stmt).fetchall()). - Lặp qua kết quả và in từng bản ghi.
Lưu ý: Bởi vì chúng tôi cũng đã tải các ràng buộc khóa chính và khóa ngoại vào SQLAlchemy, câu lệnh SELECT lấy danh sách các đối tượng bảng làm đối số và tự động thiết lập các mối quan hệ nếu cần.
Kết quả được hiển thị trong hình dưới đây:

Python sẽ tìm nạp tất cả các thuộc tính từ bảng và lưu trữ chúng trong đối tượng. Như hình minh họa, chúng ta có thể sử dụng đối tượng này để thực hiện các thao tác bổ sung. Kết quả cuối cùng trong tuyên bố của chúng tôi là danh sách tất cả các thành phố từ city bảng.
Bây giờ, chúng tôi đã sẵn sàng cho một truy vấn phức tạp hơn. Tôi vừa thêm một mệnh đề ORDER BY .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Lưu ý: asc() phương thức thực hiện sắp xếp tăng dần so với đối tượng mẹ, sử dụng các cột đã xác định làm tham số.
Danh sách trả về vẫn vậy, nhưng bây giờ nó được sắp xếp theo giá trị id, theo thứ tự tăng dần. Điều quan trọng cần lưu ý là chúng tôi chỉ mới thêm .order_by( cho truy vấn SELECT trước đó. .order_by(...) phương thức cho phép chúng ta thay đổi thứ tự của tập kết quả được trả về, giống như cách chúng ta sử dụng trong truy vấn SQL. Do đó, các tham số phải tuân theo logic SQL, sử dụng tên cột hoặc thứ tự cột và ASC hoặc DESC.
Tiếp theo, chúng tôi sẽ thêm WHERE vào câu lệnh SELECT của chúng tôi.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Lưu ý: .where() được sử dụng để kiểm tra một điều kiện mà chúng tôi đã sử dụng làm đối số. Chúng tôi cũng có thể sử dụng .filter() phương pháp này tốt hơn trong việc lọc các điều kiện phức tạp hơn.
Một lần nữa, .where một phần chỉ được nối với câu lệnh SELECT của chúng ta. Lưu ý rằng chúng tôi đã đặt điều kiện bên trong dấu ngoặc. Bất kỳ điều kiện nào trong ngoặc đều được kiểm tra theo cách tương tự như điều kiện sẽ được kiểm tra trong phần WHERE của câu lệnh SELECT. Điều kiện bình đẳng được kiểm tra bằng cách sử dụng ==thay vì =.
Điều cuối cùng chúng tôi sẽ thử với SELECT là kết hợp hai bảng. Trước tiên, hãy xem mã và kết quả của nó.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Có hai phần quan trọng trong câu lệnh trên:
-
select([table_city.columns.city_name, table_country.columns.country_name])xác định cột nào sẽ được trả về trong kết quả của chúng tôi. -
.select_from(table_city.join(table_country))xác định điều kiện tham gia / bảng. Lưu ý rằng chúng tôi không phải viết ra điều kiện tham gia đầy đủ, bao gồm cả các khóa. Điều này là do SQLAlchemy “biết” cách hai bảng này được kết hợp với nhau, vì các quy tắc khóa chính và khóa ngoại được nhập trong nền.
CHÈN / CẬP NHẬT / XÓA
Đây là ba lệnh DML còn lại mà chúng tôi sẽ đề cập trong bài viết này. Mặc dù cấu trúc của chúng có thể rất phức tạp, nhưng các lệnh này thường đơn giản hơn nhiều. Mã được sử dụng được trình bày bên dưới.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Mẫu giống nhau được sử dụng cho cả ba câu lệnh:chuẩn bị câu lệnh, in và thực thi câu lệnh, và in kết quả sau mỗi câu lệnh để chúng ta có thể xem điều gì đã thực sự xảy ra trong cơ sở dữ liệu. Lưu ý một lần nữa rằng các phần của câu lệnh được coi là các đối tượng (.values (), .where ()).

Chúng tôi sẽ sử dụng kiến thức này trong bài viết sắp tới để xây dựng toàn bộ tập lệnh ETL bằng SQLAlchemy.
Tiếp theo:SQLAlchemy trong quy trình ETL
Hôm nay chúng ta đã phân tích cách thiết lập SQLAlchemy và cách thực hiện các lệnh DML đơn giản. Trong bài viết tiếp theo, chúng tôi sẽ sử dụng kiến thức này để viết quy trình ETL hoàn chỉnh bằng SQLAlchemy.
Bạn có thể tải xuống tập lệnh hoàn chỉnh, được sử dụng trong bài viết này tại đây.