Cơ sở dữ liệu cần phải chạy một cách tối ưu, nhưng đó không phải là một nhiệm vụ dễ dàng. Cơ sở dữ liệu INFORMATION SCHEMA có thể là vũ khí bí mật của bạn trong cuộc chiến tối ưu hóa cơ sở dữ liệu.
Chúng tôi đã quen với việc tạo cơ sở dữ liệu bằng giao diện đồ họa hoặc một loạt lệnh SQL. Điều đó hoàn toàn ổn, nhưng bạn cũng nên hiểu một chút về những gì đang diễn ra trong nền. Điều này quan trọng đối với việc tạo, bảo trì và tối ưu hóa cơ sở dữ liệu và đây cũng là một cách tốt để theo dõi những thay đổi xảy ra ở hậu trường.
Trong bài viết này, chúng ta sẽ xem xét một số truy vấn SQL có thể giúp bạn xem xét hoạt động của cơ sở dữ liệu MySQL.
Cơ sở dữ liệu INFORMATION_SCHEMA
Chúng ta đã thảo luận về INFORMATION_SCHEMA cơ sở dữ liệu trong bài viết này. Nếu bạn chưa đọc, tôi chắc chắn khuyên bạn nên làm điều đó trước khi tiếp tục.
Nếu bạn cần cập nhật lại INFORMATION_SCHEMA cơ sở dữ liệu - hoặc nếu bạn quyết định không đọc bài báo đầu tiên - đây là một số thông tin cơ bản bạn cần biết:
-
INFORMATION_SCHEMAcơ sở dữ liệu là một phần của tiêu chuẩn ANSI. Chúng tôi sẽ làm việc với MySQL, nhưng các RDBMS khác có các biến thể của chúng. Bạn có thể tìm thấy các phiên bản cho Cơ sở dữ liệu H2, HSQLDB, MariaDB, Microsoft SQL Server và PostgreSQL. - Đây là cơ sở dữ liệu theo dõi tất cả các cơ sở dữ liệu khác trên máy chủ; chúng tôi sẽ tìm thấy mô tả của tất cả các đối tượng ở đây.
- Giống như bất kỳ cơ sở dữ liệu nào khác,
INFORMATION_SCHEMAcơ sở dữ liệu chứa một số bảng liên quan và thông tin về các đối tượng khác nhau. - Bạn có thể truy vấn cơ sở dữ liệu này bằng SQL và sử dụng kết quả để:
- Giám sát trạng thái và hiệu suất cơ sở dữ liệu và
- Tự động tạo mã dựa trên kết quả truy vấn.
Bây giờ, hãy chuyển sang truy vấn cơ sở dữ liệu INFORMATION_SCHEMA. Chúng ta sẽ bắt đầu bằng cách xem xét mô hình dữ liệu mà chúng ta sẽ sử dụng.
Mô hình dữ liệu
Mô hình chúng tôi sẽ sử dụng trong bài viết này được hiển thị bên dưới.
Đây là một mô hình được đơn giản hóa cho phép chúng tôi lưu trữ thông tin về lớp học, người hướng dẫn, sinh viên và các chi tiết liên quan khác. Hãy xem qua các bảng một cách ngắn gọn.
Chúng tôi sẽ lưu trữ danh sách giảng viên trong lecturer bàn. Đối với mỗi giảng viên, chúng tôi sẽ ghi lại một first_name và một last_name .
class bảng liệt kê tất cả các lớp học mà chúng tôi có trong trường của chúng tôi. Đối với mỗi bản ghi trong bảng này, chúng tôi sẽ lưu trữ class_name , ID của giảng viên, một start_date theo kế hoạch và end_date và bất kỳ class_details bổ sung nào . Vì đơn giản, tôi sẽ giả định rằng chúng tôi chỉ có một giảng viên mỗi lớp.
Các lớp học thường được tổ chức như một chuỗi các bài giảng. Họ thường yêu cầu một hoặc nhiều kỳ thi. Chúng tôi sẽ lưu trữ danh sách các bài giảng và bài kiểm tra có liên quan trong lecture và exam những cái bàn. Cả hai sẽ có ID của lớp liên quan và start_time dự kiến và end_time .
Bây giờ chúng tôi cần học sinh cho các lớp học của chúng tôi. Danh sách tất cả học sinh được lưu trữ trong student bàn. Một lần nữa, chúng tôi sẽ chỉ lưu trữ first_name và last_name của mỗi học sinh.
Điều cuối cùng chúng ta cần làm là theo dõi các hoạt động của học sinh. Chúng tôi sẽ lưu trữ danh sách mọi lớp học mà học sinh đã đăng ký, hồ sơ chuyên cần của học sinh và kết quả thi của họ. Mỗi bảng trong số ba bảng còn lại - on_class , on_lecture và on_exam - sẽ có một tham chiếu đến học sinh và một tham chiếu đến bảng thích hợp. Chỉ on_exam bảng sẽ có một giá trị bổ sung:lớp.
Vâng, mô hình này rất đơn giản. Chúng tôi có thể thêm nhiều thông tin chi tiết khác về sinh viên, giảng viên và lớp học. Chúng tôi có thể lưu trữ các giá trị lịch sử khi các bản ghi được cập nhật hoặc xóa. Tuy nhiên, mô hình này sẽ đủ cho các mục đích của bài viết này.
Tạo cơ sở dữ liệu
Chúng tôi đã sẵn sàng tạo cơ sở dữ liệu trên máy chủ cục bộ của mình và kiểm tra những gì đang xảy ra bên trong nó. Chúng tôi sẽ xuất mô hình (trong Vertabelo) bằng cách sử dụng “Generate SQL script " cái nút.
Sau đó, chúng tôi sẽ tạo cơ sở dữ liệu trên phiên bản MySQL Server. Tôi đã gọi cơ sở dữ liệu của mình “classes_and_students ”.
Điều tiếp theo chúng ta cần làm là chạy một tập lệnh SQL đã được tạo trước đó.
Bây giờ chúng ta có cơ sở dữ liệu với tất cả các đối tượng của nó (bảng, khóa chính và khóa ngoài, khóa thay thế).
Kích thước cơ sở dữ liệu
Sau khi tập lệnh chạy, dữ liệu về “classes and students ”Cơ sở dữ liệu được lưu trữ trong INFORMATION_SCHEMA cơ sở dữ liệu. Dữ liệu này nằm trong nhiều bảng khác nhau. Tôi sẽ không liệt kê tất cả lại ở đây; chúng tôi đã làm điều đó trong bài viết trước.
Hãy xem cách chúng ta có thể sử dụng SQL chuẩn trên cơ sở dữ liệu này. Tôi sẽ bắt đầu với một truy vấn rất quan trọng:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Chúng tôi chỉ truy vấn INFORMATION_SCHEMA.TABLES bàn ở đây. Bảng này sẽ cung cấp cho chúng tôi quá đủ thông tin chi tiết về tất cả các bảng trên máy chủ. Xin lưu ý rằng tôi chỉ lọc các bảng từ "classes_and_students "cơ sở dữ liệu sử dụng SET trong dòng đầu tiên và sau đó sử dụng giá trị này trong truy vấn. Hầu hết các bảng chứa các cột TABLE_NAME và TABLE_SCHEMA , biểu thị bảng và lược đồ / cơ sở dữ liệu mà dữ liệu này thuộc về.
Truy vấn này sẽ trả về kích thước hiện tại của cơ sở dữ liệu của chúng tôi và không gian trống dành cho cơ sở dữ liệu của chúng tôi. Đây là kết quả thực tế:

Như mong đợi, kích thước của cơ sở dữ liệu trống của chúng tôi nhỏ hơn 1 MB và không gian trống dự trữ lớn hơn nhiều.
Kích thước và thuộc tính của bảng
Điều thú vị tiếp theo cần làm là xem kích thước của các bảng trong cơ sở dữ liệu của chúng tôi. Để làm như vậy, chúng tôi sẽ sử dụng truy vấn sau:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
Truy vấn gần như giống với truy vấn trước, với một ngoại lệ:kết quả được nhóm ở cấp bảng.
Đây là hình ảnh của kết quả được trả về bởi truy vấn này:
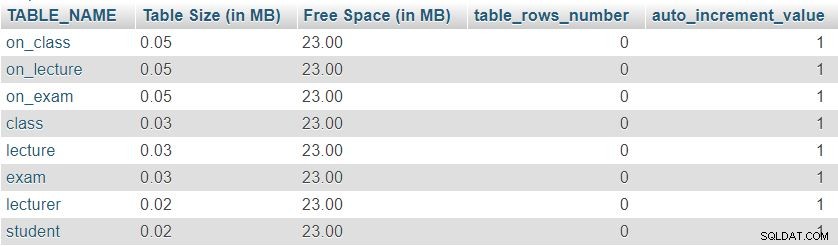
Đầu tiên, chúng ta có thể nhận thấy rằng tất cả tám bảng đều có “Kích thước bảng” tối thiểu dành riêng cho định nghĩa bảng, bao gồm các cột, khóa chính và chỉ mục. “Không gian trống” được phân bổ đồng đều giữa tất cả các bảng.
Chúng tôi cũng có thể thấy số hàng hiện có trong mỗi bảng và giá trị hiện tại của auto_increment tài sản cho mỗi bảng. Vì tất cả các bảng hoàn toàn trống nên chúng tôi không có dữ liệu và auto_increment được đặt thành 1 (một giá trị sẽ được chỉ định cho hàng được chèn tiếp theo).
Khóa chính
Mỗi bảng phải có một giá trị khóa chính được xác định, vì vậy bạn nên kiểm tra xem điều này có đúng với cơ sở dữ liệu của chúng ta hay không. Một cách để làm điều này là nối danh sách tất cả các bảng với danh sách các ràng buộc. Điều này sẽ cung cấp cho chúng tôi thông tin chúng tôi cần.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
Chúng tôi cũng đã sử dụng INFORMATION_SCHEMA.COLUMNS bảng trong truy vấn này. Trong khi phần đầu tiên của truy vấn sẽ chỉ trả về tất cả các bảng trong cơ sở dữ liệu, phần thứ hai (sau LEFT JOIN ) sẽ đếm số lượng PRI trong các bảng này. Chúng tôi đã sử dụng LEFT JOIN bởi vì chúng tôi muốn xem liệu một bảng có 0 PRI trong COLUMNS hay không bảng.
Như mong đợi, mỗi bảng trong cơ sở dữ liệu của chúng tôi chứa chính xác một cột khóa chính (PRI).
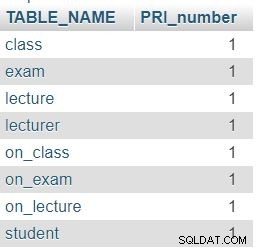
"Quần đảo"?
“Đảo” là các bảng hoàn toàn tách biệt với phần còn lại của mô hình. Chúng xảy ra khi một bảng không chứa khóa ngoại và không được tham chiếu trong bất kỳ bảng nào khác. Điều này thực sự không nên xảy ra trừ khi có một lý do thực sự chính đáng, ví dụ:khi bảng chứa tham số hoặc lưu trữ kết quả hoặc báo cáo bên trong mô hình.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Ý tưởng đằng sau truy vấn này là gì? Chà, chúng tôi đang sử dụng INFORMATION_SCHEMA.KEY_COLUMN_USAGE bảng để kiểm tra xem bất kỳ cột nào trong bảng là tham chiếu đến bảng khác hoặc nếu bất kỳ cột nào được sử dụng làm tham chiếu trong bất kỳ bảng nào khác. Phần đầu tiên của truy vấn chọn tất cả các bảng. Sau LEFT JOIN đầu tiên, chúng tôi đếm số lần bất kỳ cột nào từ bảng này được sử dụng làm tham chiếu. Sau THAM GIA TRÁI thứ hai, chúng tôi đếm số lần bất kỳ cột nào từ bảng này được tham chiếu đến bất kỳ bảng nào khác.
Kết quả trả về là:
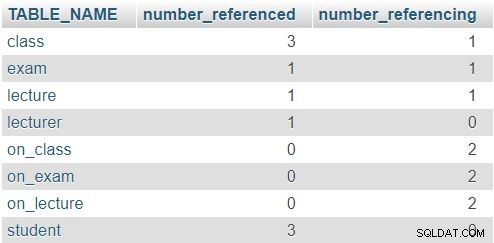
Trong hàng cho class bảng, số 3 và 1 cho biết bảng này đã được tham chiếu ba lần (trong lecture , exam và on_class bảng) và nó chứa một thuộc tính tham chiếu đến một bảng khác (lecturer_id ). Các bảng khác cũng theo một mô hình tương tự, mặc dù con số thực tế tất nhiên sẽ khác. Quy tắc ở đây là không hàng nào phải có số 0 trong cả hai cột.
Thêm hàng
Cho đến nay, mọi thứ đã diễn ra như mong đợi. Chúng tôi đã nhập thành công mô hình dữ liệu của mình từ Vertabelo vào Máy chủ MySQL cục bộ. Tất cả các bảng đều chứa các khóa, giống như chúng ta muốn và tất cả các bảng đều có liên quan đến nhau - không có "đảo" nào trong mô hình của chúng tôi.
Bây giờ, chúng tôi sẽ chèn một số hàng trong bảng của mình và sử dụng các truy vấn đã được trình bày trước đó để theo dõi những thay đổi trong cơ sở dữ liệu của chúng tôi.
Sau khi thêm 1.000 hàng trong bảng giảng viên, chúng tôi sẽ chạy lại truy vấn từ “Table Sizes and Properties " tiết diện. Nó sẽ trả về kết quả sau:
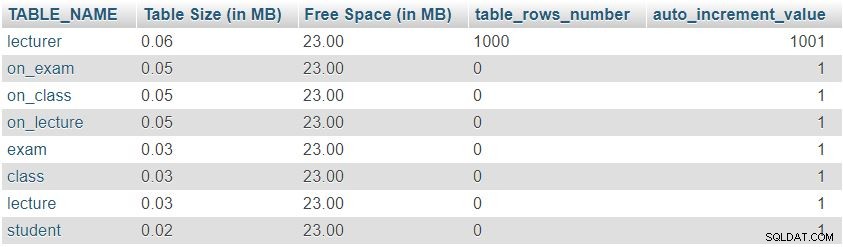
Chúng ta có thể dễ dàng nhận thấy rằng số lượng hàng và giá trị auto_increment đã thay đổi như mong đợi, nhưng không có thay đổi đáng kể nào về kích thước bảng.
Đây chỉ là một ví dụ thử nghiệm; trong các tình huống thực tế, chúng tôi sẽ nhận thấy những thay đổi đáng kể. Số lượng hàng sẽ thay đổi đáng kể trong các bảng do người dùng điền hoặc các quy trình tự động (tức là các bảng không phải là từ điển). Kiểm tra kích thước và giá trị trong các bảng như vậy là một cách rất tốt để nhanh chóng tìm và sửa hành vi không mong muốn.
Bạn muốn chia sẻ?
Làm việc với cơ sở dữ liệu là một mục tiêu không ngừng để đạt được hiệu suất tối ưu. Để thành công hơn trong việc theo đuổi đó, bạn nên sử dụng bất kỳ công cụ nào có sẵn. Hôm nay, chúng tôi đã thấy một số truy vấn hữu ích trong cuộc chiến của chúng tôi để đạt được hiệu suất tốt hơn. Bạn đã tìm thấy bất cứ điều gì khác hữu ích? Bạn đã chơi với INFORMATION_SCHEMA chưa cơ sở dữ liệu trước đây? Chia sẻ kinh nghiệm của bạn trong phần bình luận bên dưới.