Việc triển khai một tìm kiếm thân thiện với người dùng có thể khó nhưng cũng có thể được thực hiện rất hiệu quả. Làm thế nào để tôi biết điều này? Cách đây không lâu, tôi cần triển khai công cụ tìm kiếm trên ứng dụng dành cho thiết bị di động. Ứng dụng được xây dựng trên Ionic framework và sẽ kết nối với chương trình phụ trợ CakePHP 2. Ý tưởng là hiển thị kết quả khi người dùng đang nhập. Có một số lựa chọn cho việc này, nhưng không phải tất cả chúng đều đáp ứng yêu cầu của dự án của tôi.
Để minh họa loại nhiệm vụ này bao gồm những gì, hãy tưởng tượng việc tìm kiếm các bài hát và các mối quan hệ có thể có của chúng (như nghệ sĩ, album, v.v.).
Các bản ghi sẽ phải được sắp xếp theo mức độ liên quan, điều này sẽ phụ thuộc vào việc từ tìm kiếm có khớp với các trường từ bản ghi hay từ các cột khác trong bảng liên quan hay không. Ngoài ra, việc tìm kiếm nên triển khai ít nhất một số gốc từ cơ bản. (Stemming được sử dụng để lấy dạng gốc cho một từ. "Stems", "stemmer", "stemming" và "stemmed" đều có chung một gốc:"stem".)
Cách tiếp cận được trình bày ở đây đã được thử nghiệm với hàng trăm nghìn bản ghi và có thể truy xuất kết quả hữu ích khi người dùng đang nhập.
Các sản phẩm tìm kiếm toàn văn bản cần xem xét
Có một số cách chúng tôi có thể thực hiện loại tìm kiếm này. Dự án của chúng tôi có một số hạn chế liên quan đến thời gian và tài nguyên máy chủ, vì vậy chúng tôi phải giữ cho giải pháp càng đơn giản càng tốt. Một vài ứng cử viên cuối cùng đã xuất hiện:
Elasticsearch
Elasticsearch cung cấp các tìm kiếm toàn văn bản trong một dịch vụ hướng đến tài liệu. Nó được thiết kế để quản lý lượng tải khổng lồ theo cách phân tán:nó có thể xếp hạng kết quả theo mức độ liên quan, thực hiện tổng hợp và làm việc với cách tạo từ và từ đồng nghĩa. Công cụ này dành cho các tìm kiếm trong thời gian thực. Từ trang web của họ:
Elasticsearch xây dựng các khả năng phân tán trên Apache Lucene để cung cấp khả năng tìm kiếm toàn văn bản mạnh mẽ nhất hiện có. API truy vấn mạnh mẽ, thân thiện với nhà phát triển hỗ trợ tìm kiếm đa ngôn ngữ, định vị địa lý, đề xuất ý bạn theo ngữ cảnh, tự động hoàn thành và đoạn trích kết quả.
Elasticsearch có thể hoạt động như một dịch vụ REST, phản hồi các yêu cầu http và nó có thể được thiết lập rất nhanh chóng. Tuy nhiên, việc khởi động engine như một dịch vụ đòi hỏi bạn phải có một số đặc quyền truy cập máy chủ. Và nếu nhà cung cấp dịch vụ lưu trữ của bạn không hỗ trợ Elasticsearch ngay lập tức, bạn sẽ cần cài đặt một số gói.
Điểm mấu chốt là sản phẩm này là một lựa chọn tuyệt vời nếu bạn muốn có một giải pháp tìm kiếm vững chắc. (Lưu ý:Bạn có thể cần một VPS hoặc máy chủ chuyên dụng vì các yêu cầu phần cứng khá khắt khe.)
Tượng nhân sư
Giống như Elasticsearch, Sphinx cũng cung cấp một sản phẩm tìm kiếm toàn văn bản rất vững chắc:Craigslist phục vụ hơn 300.000.000 truy vấn mỗi ngày với nó. Sphinx không cung cấp giao diện RESTful gốc. Nó được triển khai bằng C, với phần cứng nhỏ hơn Elasticsearch (được triển khai bằng Java và có thể chạy trên bất kỳ hệ điều hành nào có jvm). Bạn cũng sẽ cần quyền truy cập root vào máy chủ với một số RAM / CPU chuyên dụng để chạy Sphinx đúng cách.
Tìm kiếm toàn văn bản trong MySQL
Trước đây, các tìm kiếm toàn văn được hỗ trợ trong các công cụ MyISAM. Sau phiên bản 5.6, MySQL cũng hỗ trợ tìm kiếm toàn văn trong công cụ lưu trữ InnoDB. Đây là một tin tuyệt vời, vì nó cho phép các nhà phát triển hưởng lợi từ tính toàn vẹn tham chiếu, khả năng thực hiện giao dịch và khóa cấp hàng của InnoDB.
Về cơ bản có hai cách tiếp cận để tìm kiếm toàn văn trong MySQL:ngôn ngữ tự nhiên và chế độ boolean. (Tùy chọn thứ ba tăng cường tìm kiếm ngôn ngữ tự nhiên với truy vấn mở rộng thứ hai.)
Sự khác biệt chính giữa chế độ tự nhiên và chế độ boolean là boolean cho phép một số toán tử nhất định như một phần của tìm kiếm. Ví dụ:các toán tử boolean có thể được sử dụng nếu một từ có mức độ liên quan lớn hơn các từ khác trong truy vấn hoặc nếu một từ cụ thể phải xuất hiện trong kết quả, v.v. Cần lưu ý rằng trong cả hai trường hợp, kết quả có thể được sắp xếp theo mức độ liên quan được tính bằng MySQL trong quá trình tìm kiếm.
Đưa ra quyết định
Phù hợp nhất cho vấn đề của chúng tôi là sử dụng tìm kiếm toàn văn bản InnoDb ở chế độ boolean. Tại sao?
- Chúng tôi có rất ít thời gian để triển khai chức năng tìm kiếm.
- Tại thời điểm này, chúng tôi không có dữ liệu lớn để xử lý cũng như không có tải lớn để yêu cầu thứ gì đó như Elasticsearch hoặc Sphinx.
- Chúng tôi đã sử dụng dịch vụ lưu trữ được chia sẻ không hỗ trợ Elasticsearch hoặc Sphinx và phần cứng ở giai đoạn này khá hạn chế.
- Mặc dù chúng tôi muốn xuất phát từ trong chức năng tìm kiếm của mình, nhưng nó không phải là một công cụ phá vỡ thỏa thuận:chúng tôi có thể triển khai nó (trong các ràng buộc) bằng một số mã PHP đơn giản và chuẩn hóa dữ liệu
- Tìm kiếm toàn văn bản ở chế độ boolean có thể tìm kiếm các từ bằng ký tự đại diện (đối với gốc của từ) và sắp xếp kết quả dựa trên mức độ liên quan.
Tìm kiếm toàn văn bản ở Chế độ Boolean
Như đã đề cập trước đây, tìm kiếm ngôn ngữ tự nhiên là cách tiếp cận đơn giản nhất:chỉ cần tìm kiếm một cụm từ hoặc một từ trong các cột mà bạn đã đặt chỉ mục toàn văn và bạn sẽ nhận được kết quả được sắp xếp theo mức độ liên quan.
Trong Mẫu Vertabelo Thường hóa
Hãy xem một tìm kiếm đơn giản sẽ hoạt động như thế nào. Trước tiên, chúng tôi sẽ tạo một bảng mẫu:
- Được tạo bởi Vertabelo (https://vertabelo.com) - Ngày sửa đổi lần cuối:2016-04-25 15:01:22.153-- bảng - Bảng:nghệ sĩ NULL AUTO_INCREMENT, tên varchar (255) NOT NULL, văn bản tiểu sử KHÔNG NULL, CONSTRAINT artist_pk PRIMARY KEY (id)) ENGINE InnoDB; TẠO CHỈ SỐ FULLTEXT artist_idx_1 TRÊN các nghệ sĩ (tên); - Cuối tệp.
Ở chế độ ngôn ngữ tự nhiên
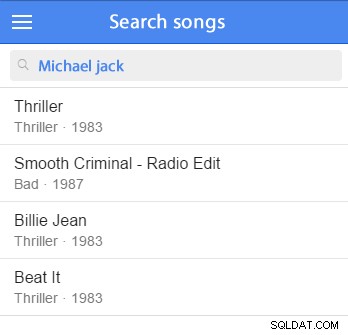
Bạn có thể chèn một số dữ liệu mẫu và bắt đầu thử nghiệm. (Sẽ rất tốt nếu bạn thêm nó vào tập dữ liệu mẫu của bạn.) Ví dụ:chúng tôi sẽ thử tìm kiếm Michael Jackson:
CHỌN * TỪ các nghệ sĩWHERE MATCH (artist.name) CHỐNG LẠI ('Michael Jackson' TRONG CHẾ ĐỘ NGÔN NGỮ TỰ NHIÊN) Truy vấn này sẽ tìm các bản ghi phù hợp với cụm từ tìm kiếm và sẽ sắp xếp các bản ghi phù hợp theo mức độ liên quan; trận đấu càng hay, càng liên quan và kết quả càng cao sẽ xuất hiện trong danh sách.
Ở chế độ boolean
Chúng ta có thể thực hiện tìm kiếm tương tự trong chế độ boolean. Nếu chúng tôi không áp dụng bất kỳ toán tử nào cho truy vấn của mình, điểm khác biệt duy nhất sẽ là kết quả không được sắp xếp theo mức độ liên quan:
CHỌN * TỪ các nghệ sĩWHERE MATCH (artist.name) LẠI ('Michael Jackson' TRONG CHẾ ĐỘ BOOLEAN) Toán tử ký tự đại diện trong chế độ boolean
Vì chúng ta muốn tìm kiếm các từ gốc và một phần, chúng ta sẽ cần toán tử ký tự đại diện (*). Toán tử này có thể được sử dụng trong tìm kiếm chế độ boolean, đó là lý do tại sao chúng tôi chọn chế độ đó.
Vì vậy, hãy giải phóng sức mạnh của tìm kiếm boolean và thử tìm kiếm một phần tên của nghệ sĩ. Chúng tôi sẽ sử dụng toán tử ký tự đại diện để khớp với bất kỳ nghệ sĩ nào có tên bắt đầu bằng ‘Mich’:
CHỌN * TỪ các nghệ sĩ TRẬN ĐẤU (tên) LẠI ('Mich *' TRONG CHẾ ĐỘ BOOLEAN) Sắp xếp theo mức độ liên quan trong chế độ boolean
Bây giờ chúng ta hãy xem mức độ liên quan được tính toán cho tìm kiếm. Điều này sẽ giúp chúng tôi hiểu cách sắp xếp mà chúng tôi sẽ thực hiện sau này với Cake:
CHỌN *, MATCH (tên) CHỐNG LẠI ('mich *' TRONG CHẾ ĐỘ BOOLEAN) NHƯ nghệ sĩ rankFROMWHERE MATCH (tên) CHỐNG LẠI ('mich *' TRONG CHẾ ĐỘ BOOLEAN) ĐẶT HÀNG THEO thứ hạng MÔ TẢ Truy vấn này truy xuất kết quả tìm kiếm và giá trị liên quan mà MySQL tính toán cho mỗi bản ghi. Trình tối ưu hóa công cụ sẽ phát hiện ra rằng chúng tôi đang chọn mức độ liên quan, vì vậy nó sẽ không bận tâm đến việc tính toán lại thứ hạng.
Tạo nguồn từ trong tìm kiếm toàn văn bản
Khi chúng tôi kết hợp gốc từ trong một tìm kiếm, tìm kiếm sẽ trở nên thân thiện hơn với người dùng. Ngay cả khi bản thân kết quả không phải là một từ, các thuật toán cố gắng tạo ra cùng một gốc cho các từ dẫn xuất. Ví dụ:từ gốc “arg” không phải là một từ tiếng Anh, nhưng nó có thể được sử dụng làm gốc cho “tranh luận”, “tranh luận”, “tranh luận”, “tranh cãi”, “Argus” và các từ khác.
Việc tạo gốc cải thiện kết quả, vì người dùng có thể nhập một từ không khớp chính xác nhưng “gốc” của nó thì có. Mặc dù trình gốc PHP hoặc trình gốc Python của Snowball có thể là một tùy chọn (nếu bạn có quyền truy cập SSH gốc vào máy chủ của mình), chúng tôi sẽ sử dụng lớp PorterStemmer.php.
Lớp này thực hiện thuật toán do Martin Porter đề xuất để lấy các từ trong tiếng Anh. Như tác giả đã nêu trong trang web của mình, nó được sử dụng miễn phí cho bất kỳ mục đích nào. Chỉ cần thả tệp vào bên trong thư mục Nhà cung cấp của bạn trong CakePHP, đưa thư viện vào mô hình của bạn và gọi phương thức tĩnh để tạo ra một từ:
// bao gồm thư viện (nên được gọi là PorterStemmer.php) trong thư mục CakePHP’s VendorsApp ::import ('Vendor', 'PorterStemmer'); // bắt nguồn từ một từ (các từ phải được tạo gốc từng từ một) echo PorterStemmer ::Stem (‘stemming’); // đầu ra sẽ là 'stem' Mục tiêu của chúng tôi là giúp tìm kiếm nhanh chóng và hiệu quả, đồng thời có thể sắp xếp kết quả theo mức độ liên quan của toàn văn bản. Để làm được điều này, chúng ta sẽ cần sử dụng cách tạo gốc từ theo hai cách:
- Các từ do người dùng nhập
- Dữ liệu liên quan đến bài hát (chúng tôi sẽ lưu trữ trong các cột và sắp xếp cho kết quả dựa trên mức độ liên quan)
Kiểu tạo gốc từ đầu tiên có thể được thực hiện như sau:
App ::import ('Vendor', 'PorterStemmer'); $ search =trim (preg_replace ('/ [^ A-Za-z0-9_ \ s] /', '', $ search)); / / xóa các ký tự không mong muốn $ words =boom ("", trim ($ search)); $ stemmedSearch =""; $ unstemmedSearch =""; foreach ($ words as $ word) {$ stemmedSearch. =PorterStemmer ::Stem ($ từ) . "*"; // chúng ta thêm ký tự đại diện sau mỗi từ $ unstemmedSearch =$ word. "*"; // để tìm kiếm cột nghệ sĩ không có gốc} $ stemmedSearch =trim ($ stemmedSearch); $ unstemmedSearch =trim ($ unstemmedSearch); if ($ stemmedSearch =="*" || $ unstemmedSearch ==" * ") {// nếu không mySql sẽ phàn nàn vì bạn không thể sử dụng ký tự đại diện một mình $ stemmedSearch =" "; $ unstemmedSearch ="";} Chúng tôi đã tạo hai chuỗi:một chuỗi để tìm kiếm tên nghệ sĩ (không có gốc) và một để tìm kiếm trong các cột có gốc khác. Điều này sẽ giúp chúng tôi sau này xây dựng tính năng ‘chống lại’ một phần của truy vấn toàn văn. Bây giờ, hãy xem cách chúng ta có thể tạo và sắp xếp dữ liệu của bài hát.
Chuẩn hóa dữ liệu bài hát
Tiêu chí phân loại của chúng tôi sẽ dựa trên việc so khớp với nghệ sĩ của bài hát (không xuất hiện gốc) trước. Tiếp theo sẽ đến tên bài hát, album và các danh mục liên quan. Việc lấy mẫu sẽ được sử dụng trên tất cả các tiêu chí tìm kiếm phụ.
Để minh họa điều này, giả sử tôi tìm kiếm từ ‘nirvana’ và có một bài hát tên là ‘Nirvana Games’ của ‘XYZ’ và một bài hát khác có tên ‘Polly’ của nghệ sĩ ‘Nirvana’. Kết quả nên liệt kê ‘Polly’ trước tiên, vì sự trùng khớp về tên nghệ sĩ quan trọng hơn sự trùng khớp về tên bài hát (dựa trên tiêu chí của tôi).
Để thực hiện việc này, tôi đã thêm 4 trường trong songs , một bảng cho mỗi tiêu chí tìm kiếm / sắp xếp mà chúng tôi muốn:
ALTER TABLE `bài hát` THÊM` Derm_artist` VARCHAR (255) KHÔNG ĐẦY ĐỦ SAU `tên nhạc phim`, THÊM` tên nhạc phim` Derm_trackname`, ADD `derm_categories` VARCHAR (500) KHÔNG ĐẦY ĐỦ SAU`denorm_album`, THÊM FULLTEXT (` derm_artist`), THÊM FULLTEXT (`tên_trường_trường`), THÊM FULLTEXT (` biểu_tượng_album`), THÊM FULLTate (`` dealbum ');
Mô hình cơ sở dữ liệu hoàn chỉnh của chúng tôi sẽ giống như sau:
Bất cứ khi nào bạn lưu một bài hát bằng cách sử dụng thêm / chỉnh sửa trong CakePHP, bạn chỉ cần lưu tên nghệ sĩ trong cột denorm_artist mà không cần đến gốc của nó. Tiếp theo, thêm tên bản nhạc gốc trong denorm_trackname (tương tự như những gì chúng tôi đã làm trong văn bản được tìm kiếm) và lưu tên của album gốc trong denorm_album cột. Cuối cùng, lưu trữ danh mục gốc được đặt cho bài hát trong denorm_categories , nối các từ và thêm một khoảng trắng giữa mỗi tên danh mục gốc.
Tìm kiếm toàn văn bản và sắp xếp mức độ liên quan trong CakePHP
Tiếp tục với ví dụ về tìm kiếm "Nirvana", hãy xem một truy vấn tương tự như thế này có thể đạt được những gì:
CHỌN tên bản nhạc, TRẬN ĐẤU (Derm_artist) CHỐNG LẠI ('Nirvana *' TRONG CHẾ ĐỘ BOOLEAN) dưới dạng rank1, MATCH (tên biểu tượng giá trị) LẠI ('Nirvana *' TRONG CHẾ ĐỘ BOOLEAN) là rank2, MATCH (derm_album) LẠI ('Nirvana *' Ở CHẾ ĐỘ BOOLEAN) ở vị trí thứ hạng 3, TRẬN ĐẤU (MATCH_categories) CHỐNG LẠI ('Nirvana *' TRONG CHẾ ĐỘ BOOLEAN) ở vị trí thứ hạng4 TỪ các bài hát Ở ĐÂU TRẬN ĐẤU (phái_biểu tượng) CHỐNG LẠI ('Nirvana *' TRONG CHẾ ĐỘ BOOLEAN) HOẶC TRẬN ĐẤU (tên tuổi nhạc nền) CHỐNG LẠI ('Nirvana * 'TRONG CHẾ ĐỘ BOOLEAN) HOẶC TRẬN ĐẤU (derm_album) LẠI (' Nirvana * 'TRONG CHẾ ĐỘ BOOLEAN) HOẶC TRẬN ĐẤU (danh mục_các loại) LẠI (' Nirvana * 'TRONG CHẾ ĐỘ BOOLEAN) ĐẶT HÀNG THEO rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC Chúng tôi sẽ nhận được kết quả sau:
| trackname | rank1 | rank2 | xếp hạng3 | rank4 |
| Polly | 0,0906190574169159 | 0 | 0 | 0 |
| trò chơi niết bàn | 0 | 0,0906190574169159 | 0 | 0 |
Để thực hiện việc này trong CakePHP, hãy chọn find phương thức phải được gọi bằng cách sử dụng kết hợp các tham số ‘trường’, ‘điều kiện’ và ‘thứ tự’. Tiếp tục với mã ví dụ PHP cũ:
// trong tệp mô hình Song.php $ fields =array ("Song.trackname", "MATCH (Song.denorm_artist) LẠI ({$ unstemmedSearch} TRONG CHẾ ĐỘ BOOLEAN) dưới dạng` rank1` "," MATCH (Bài hát. derm_trackname) CHỐNG LẠI ({$ stemmedSearch} TRONG CHẾ ĐỘ BOOLEAN) dưới dạng `rank2`", "TRẬN ĐẤU (Song.denorm_album) CHỐNG LẠI ({$ stemmedSearch} TRONG CHẾ ĐỘ BOOLEAN) với tư cách là` rank3` "," TRẬN ĐẤU (Song.denorm_categories) LẠI ( {$ stemmedSearch} IN BOOLEAN MODE) as `rank4`"); $ order ="` rank1` DESC, `rank2` DESC,` rank3` DESC, `rank4` DESC, Song.trackname ASC"; $ condition =array ( "HOẶC" => mảng ("TRẬN ĐẤU (Song.denorm_artist) CHỐNG LẠI ({$ unstemmedSearch} TRONG CHẾ ĐỘ BOOLEAN)", "TRẬN ĐẤU (Song.denorm_trackname) CHỐNG LẠI ({$ stemmedSearch} TRONG CHẾ ĐỘ BOOLEAN)", "MATCH (Bài hát. Derm_album) CHỐNG LẠI ({$ stemmedSearch} TRONG CHẾ ĐỘ BOOLEAN) "," TRẬN ĐẤU (Song.denorm_categories) CHỐNG lại ({$ stemmedSearch} Ở CHẾ ĐỘ BOOLEAN) ")); $ results =$ this-> tìm (‘Tất cả’, mảng (‘điều kiện’ => $ điều kiện, ’trường’ => $ fields, ’order’ => $ order); $ results sẽ là mảng các bài hát được sắp xếp với các tiêu chí mà chúng tôi đã xác định trước đó.
Giải pháp này có thể được sử dụng để tạo các tìm kiếm có ý nghĩa đối với người dùng - mà không yêu cầu quá nhiều thời gian từ các nhà phát triển hoặc thêm độ phức tạp lớn vào mã.
Làm bánhPHP Tìm kiếm tốt hơn nữa
Điều đáng nói là "ghép" các cột không chuẩn hóa với nhiều dữ liệu hơn có thể dẫn đến kết quả tốt hơn.
Bằng cách "spicing", ý tôi là bạn có thể đưa vào các cột không chuẩn hóa nhiều dữ liệu hơn từ các cột bổ sung mà bạn cho là hữu ích với mục tiêu làm cho kết quả phù hợp hơn, ví dụ:nếu bạn biết rằng quốc gia của một nghệ sĩ có thể tìm thấy trong các cụm từ tìm kiếm, bạn có thể thêm quốc gia cùng với tên nghệ sĩ trong denorm_artist cột. Điều này sẽ cải thiện chất lượng của kết quả tìm kiếm.
Theo kinh nghiệm của tôi (tùy thuộc vào dữ liệu thực tế mà bạn sử dụng và các cột bạn không chuẩn hóa), kết quả trên cùng có xu hướng thực sự chính xác. Điều này rất tốt cho các ứng dụng dành cho thiết bị di động, vì việc cuộn xuống một danh sách dài có thể gây khó chịu cho người dùng.
Cuối cùng, nếu bạn cần lấy thêm dữ liệu từ các bảng có liên quan đến bài hát, bạn luôn có thể tham gia và nhận nghệ sĩ, danh mục, album, nhận xét bài hát, v.v. Nếu bạn đang sử dụng bộ lọc hành vi có thể chứa của CakePHP, tôi sẽ đề xuất thêm plugin EagerLoader để thực hiện các phép nối một cách hiệu quả.
Nếu bạn có cách tiếp cận của riêng mình để triển khai tìm kiếm toàn văn, vui lòng chia sẻ nó trong phần bình luận bên dưới. Tất cả chúng ta có thể học hỏi kinh nghiệm của nhau.