Khi làm việc với tên người và tra cứu chúng, điều làm việc hiệu quả với tôi là tạo ra một bảng từ thứ hai. Cũng tạo một bảng thứ ba là một bảng giao nhau cho mối quan hệ nhiều đến nhiều giữa bảng chứa văn bản và bảng từ. Khi một hàng được thêm vào bảng văn bản, bạn chia văn bản thành các từ và điền vào bảng giao nhau một cách thích hợp, thêm các từ mới vào bảng từ khi cần thiết. Khi cấu trúc này đã có, bạn có thể tra cứu nhanh hơn một chút, vì bạn chỉ cần thực hiện hàm damlev của mình trên bảng các từ duy nhất. Một phép nối đơn giản sẽ giúp bạn có văn bản chứa các từ phù hợp. 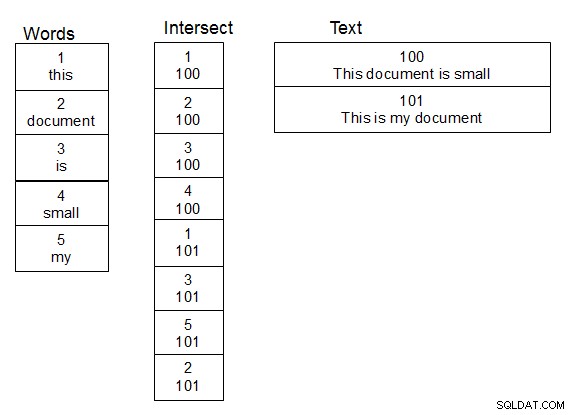
Truy vấn cho một kết hợp từ duy nhất sẽ trông giống như sau:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
và hai từ sẽ trông như thế này (tôi không hiểu, vì vậy có thể không chính xác):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Ưu điểm ở đây, với chi phí của một số không gian cơ sở dữ liệu, là bạn chỉ phải áp dụng hàm damlev tốn kém thời gian cho các từ duy nhất, có thể sẽ chỉ nằm trong số 10 của hàng nghìn bất kể kích thước của bảng văn bản của bạn. Điều này rất quan trọng vì UDF damlev sẽ không sử dụng các chỉ mục - nó sẽ quét toàn bộ bảng mà nó được áp dụng để tính giá trị cho mọi hàng. Chỉ quét các từ duy nhất sẽ nhanh hơn nhiều. Ưu điểm khác là damlev được áp dụng ở cấp độ từ, đây dường như là những gì bạn đang yêu cầu. Một ưu điểm khác là bạn có thể mở rộng truy vấn để hỗ trợ tìm kiếm trên nhiều từ và có thể xếp hạng kết quả bằng cách nhóm các hàng giao nhau phù hợp trên TextId và xếp hạng dựa trên số lượng kết quả phù hợp.