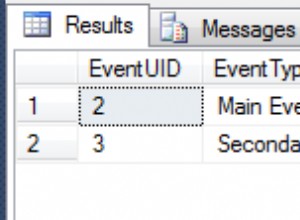
Bắt đầu từ một số bản ghi nhất định, IN vị từ trên SELECT trở nên nhanh hơn so với danh sách các hằng số.
Xem bài viết này trong blog của tôi để so sánh hiệu suất:
Nếu cột được sử dụng trong truy vấn trong IN mệnh đề được lập chỉ mục, như thế này:
SELECT *
FROM table1
WHERE unindexed_column IN
(
SELECT indexed_column
FROM table2
)
, thì truy vấn này chỉ được tối ưu hóa thành EXISTS (sử dụng trừ một mục nhập cho mỗi bản ghi từ table1 )
Thật không may, MySQL không có khả năng thực hiện HASH SEMI JOIN hoặc MERGE SEMI JOIN hiệu quả hơn (đặc biệt nếu cả hai cột đều được lập chỉ mục).