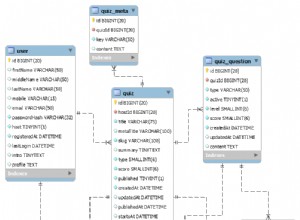
Đây là cách hai cách tiếp cận này sẽ được biểu diễn vật lý trong cơ sở dữ liệu:
Hãy để chúng tôi phân tích cả hai cách tiếp cận ...
Cách tiếp cận 1 (cả hai hướng được lưu trữ trong bảng):
- CHUYÊN NGHIỆP:Các truy vấn đơn giản hơn.
- CON:Dữ liệu có thể bị hỏng khi chèn / cập nhật / xóa chỉ một hướng.
- MINOR PRO:Không yêu cầu các ràng buộc bổ sung để đảm bảo tình bạn không thể nhân đôi.
- Cần phân tích thêm:
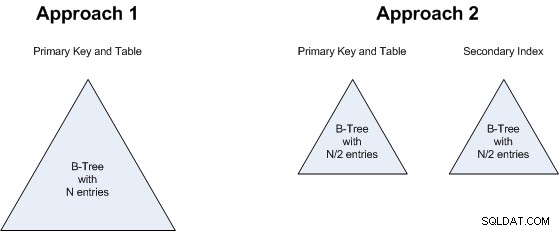
- TIE:Một chỉ mục cover cả hai hướng, vì vậy bạn không cần chỉ mục phụ.
- TIE:Yêu cầu lưu trữ.
- TIE:Hiệu suất.
Cách tiếp cận 2 (chỉ một hướng được lưu trữ trong bảng):
- CON:Các truy vấn phức tạp hơn.
- CHUYÊN NGHIỆP:Không thể làm hỏng dữ liệu do quên xử lý hướng ngược lại, vì không có hướng ngược lại .
- MINOR CON:Yêu cầu
CHECK(UID < FriendID), vì vậy, một tình bạn giống nhau không bao giờ có thể được thể hiện theo hai cách khác nhau và chìa khóa ở(UID, FriendID)có thể làm công việc của mình. - Cần phân tích thêm:
- TIE:Hai chỉ mục là cần thiết để che
cả hai hướng truy vấn (chỉ mục tổng hợp trên
{UID, FriendID}và chỉ mục tổng hợp trên{FriendID, UID}). - TIE:Yêu cầu lưu trữ.
- TIE:Hiệu suất.
- TIE:Hai chỉ mục là cần thiết để che
cả hai hướng truy vấn (chỉ mục tổng hợp trên
Điểm 1 được quan tâm đặc biệt. MySQL / InnoDB luôn luôn cụm dữ liệu và các chỉ mục phụ có thể tốn kém trong các bảng được phân nhóm (xem "Nhược điểm của phân nhóm" trong bài viết này ), vì vậy có thể có vẻ như chỉ số phụ trong cách tiếp cận 2 sẽ ăn mòn tất cả các lợi thế của ít hàng hơn. Tuy nhiên , chỉ mục phụ chứa các trường giống hệt như chỉ mục chính (chỉ theo thứ tự ngược lại) nên không có chi phí lưu trữ trong trường hợp cụ thể này. Cũng không có con trỏ tới bảng heap (vì không có bảng nào), vì vậy có lẽ chỉ số dựa trên heap thông thường thậm chí còn rẻ hơn khi lưu trữ. Và giả sử truy vấn được bao phủ bởi chỉ mục, sẽ không có tra cứu kép thường được kết hợp với chỉ mục phụ trong một bảng được phân nhóm. Vì vậy, về cơ bản đây là một hòa (cả cách tiếp cận 1 và cách tiếp cận 2 đều không có lợi thế đáng kể).
Điểm 2 có liên quan đến điểm 1:không quan trọng là chúng ta sẽ có Cây B gồm N giá trị hay hai Cây B, mỗi cây có N / 2 giá trị. Vì vậy, đây cũng là một điểm ràng buộc:cả hai cách tiếp cận sẽ sử dụng khoảng dung lượng lưu trữ tương đương nhau.
Lập luận tương tự cũng áp dụng cho điểm 3 :cho dù chúng ta tìm kiếm một B-Tree lớn hơn hay 2 cây nhỏ hơn, không tạo ra nhiều sự khác biệt, vì vậy đây cũng là một sự ràng buộc.
Vì vậy, để có được sự mạnh mẽ và mặc dù các truy vấn có phần xấu hơn và cần thêm CHECK , Tôi sẽ đi theo cách tiếp cận 2.