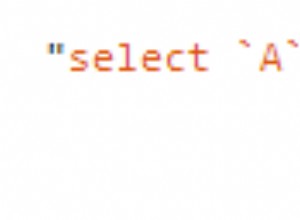
Cách tiếp cận này có một số vấn đề về khả năng mở rộng (nếu bạn chọn chuyển đến, chẳng hạn như dữ liệu địa lý cụ thể của thành phố), nhưng đối với kích thước dữ liệu nhất định, nó sẽ cung cấp tối ưu hóa đáng kể.
Vấn đề bạn đang gặp phải là MySQL không tối ưu hóa các truy vấn dựa trên phạm vi rất tốt. Lý tưởng nhất là bạn muốn tra cứu chính xác ("=") trên một chỉ mục thay vì "lớn hơn", vì vậy chúng tôi sẽ cần tạo một chỉ mục như vậy từ dữ liệu bạn có sẵn. Bằng cách này, MySQL sẽ có ít hàng hơn để đánh giá trong khi tìm kiếm đối sánh.
Để thực hiện việc này, tôi khuyên bạn nên tạo một bảng tra cứu lập chỉ mục bảng vị trí địa lý dựa trên octet đầu tiên (=1 từ 1.2.3.4) của địa chỉ IP. Ý tưởng là đối với mỗi lần tra cứu bạn phải thực hiện, bạn có thể bỏ qua tất cả các IP vị trí địa lý không bắt đầu bằng cùng một octet với IP bạn đang tìm kiếm.
CREATE TABLE `ip_geolocation_lookup` (
`first_octet` int(10) unsigned NOT NULL DEFAULT '0',
`ip_numeric_start` int(10) unsigned NOT NULL DEFAULT '0',
`ip_numeric_end` int(10) unsigned NOT NULL DEFAULT '0',
KEY `first_octet` (`first_octet`,`ip_numeric_start`,`ip_numeric_end`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Tiếp theo, chúng tôi cần lấy dữ liệu có sẵn trong bảng vị trí địa lý của bạn và tạo dữ liệu bao gồm tất cả (đầu tiên) bộ tám cho hàng vị trí địa lý:Nếu bạn có một mục nhập với ip_start = '5.3.0.0' và ip_end = '8.16.0.0' , bảng tra cứu sẽ cần các hàng cho các octet 5, 6, 7 và 8. Vì vậy ...
ip_geolocation
|ip_start |ip_end |ip_numeric_start|ip_numeric_end|
|72.255.119.248 |74.3.127.255 |1224701944 |1241743359 |
Nên chuyển đổi thành:
ip_geolocation_lookup
|first_octet|ip_numeric_start|ip_numeric_end|
|72 |1224701944 |1241743359 |
|73 |1224701944 |1241743359 |
|74 |1224701944 |1241743359 |
Vì ai đó ở đây đã yêu cầu giải pháp MySQL gốc, đây là quy trình được lưu trữ sẽ tạo dữ liệu đó cho bạn:
DROP PROCEDURE IF EXISTS recalculate_ip_geolocation_lookup;
CREATE PROCEDURE recalculate_ip_geolocation_lookup()
BEGIN
DECLARE i INT DEFAULT 0;
DELETE FROM ip_geolocation_lookup;
WHILE i < 256 DO
INSERT INTO ip_geolocation_lookup (first_octet, ip_numeric_start, ip_numeric_end)
SELECT i, ip_numeric_start, ip_numeric_end FROM ip_geolocation WHERE
( ip_numeric_start & 0xFF000000 ) >> 24 <= i AND
( ip_numeric_end & 0xFF000000 ) >> 24 >= i;
SET i = i + 1;
END WHILE;
END;
Và sau đó, bạn sẽ cần điền vào bảng bằng cách gọi thủ tục được lưu trữ đó:
CALL recalculate_ip_geolocation_lookup();
Tại thời điểm này, bạn có thể xóa thủ tục bạn vừa tạo - nó không còn cần thiết nữa, trừ khi bạn muốn tính toán lại bảng tra cứu.
Sau khi bảng tra cứu có sẵn, tất cả những gì bạn phải làm là tích hợp nó vào các truy vấn của mình và đảm bảo rằng bạn đang truy vấn theo octet đầu tiên. Truy vấn của bạn đối với bảng tra cứu sẽ đáp ứng hai điều kiện:
- Tìm tất cả các hàng khớp với octet đầu tiên trong địa chỉ IP của bạn
- Trong số tập hợp con đó :Tìm hàng có phạm vi khớp với địa chỉ IP của bạn
Bởi vì bước hai được thực hiện trên một tập hợp con dữ liệu, nó nhanh hơn đáng kể so với thực hiện các bài kiểm tra phạm vi trên toàn bộ dữ liệu. Đây là chìa khóa cho chiến lược tối ưu hóa này.
Có nhiều cách khác nhau để tìm ra octet đầu tiên của địa chỉ IP là gì; Tôi đã sử dụng ( r.ip_numeric & 0xFF000000 ) >> 24 vì các IP nguồn của tôi ở dạng số:
SELECT
r.*,
g.country_code
FROM
ip_geolocation g,
ip_geolocation_lookup l,
ip_random r
WHERE
l.first_octet = ( r.ip_numeric & 0xFF000000 ) >> 24 AND
l.ip_numeric_start <= r.ip_numeric AND
l.ip_numeric_end >= r.ip_numeric AND
g.ip_numeric_start = l.ip_numeric_start;
Bây giờ, phải thừa nhận rằng cuối cùng thì tôi cũng hơi lười biếng:Bạn có thể dễ dàng thoát khỏi ip_geolocation toàn bộ bảng nếu bạn đã tạo ip_geolocation_lookup bảng cũng chứa dữ liệu quốc gia. Tôi đoán rằng việc bỏ một bảng khỏi truy vấn này sẽ làm cho nó nhanh hơn một chút.
Và, cuối cùng, đây là hai bảng khác mà tôi đã sử dụng trong phản hồi này để tham khảo, vì chúng khác với các bảng của bạn. Tuy nhiên, tôi chắc chắn rằng chúng tương thích với nhau.
# This table contains the original geolocation data
CREATE TABLE `ip_geolocation` (
`ip_start` varchar(16) NOT NULL DEFAULT '',
`ip_end` varchar(16) NOT NULL DEFAULT '',
`ip_numeric_start` int(10) unsigned NOT NULL DEFAULT '0',
`ip_numeric_end` int(10) unsigned NOT NULL DEFAULT '0',
`country_code` varchar(3) NOT NULL DEFAULT '',
`country_name` varchar(64) NOT NULL DEFAULT '',
PRIMARY KEY (`ip_numeric_start`),
KEY `country_code` (`country_code`),
KEY `ip_start` (`ip_start`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
# This table simply holds random IP data that can be used for testing
CREATE TABLE `ip_random` (
`ip` varchar(16) NOT NULL DEFAULT '',
`ip_numeric` int(10) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`ip`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;