Câu hỏi của bạn là thực sự không chính xác. Vui lòng làm theo các đề xuất của @RiggsFolly và đọc các tài liệu tham khảo về cách đặt một câu hỏi hay.
Ngoài ra, theo đề xuất của @DuduMarkovitz, bạn nên bắt đầu bằng cách đơn giản hóa vấn đề và làm sạch dữ liệu của mình. Một số tài nguyên giúp bạn bắt đầu:
- Hướng dẫn Xử lý Văn bản Cơ bản bởi Matt Deny
- Xử lý và Xử lý chuỗi trong R bởi Gaston Sanchez
Khi bạn hài lòng với kết quả, bạn có thể tiến hành xác định một nhóm cho mỗi Var1 mục nhập (điều này sẽ giúp bạn thực hiện phân tích / thao tác sâu hơn trên các mục tương tự) Điều này có thể được thực hiện theo nhiều cách khác nhau nhưng như @GordonLinoff đã đề cập, một trong những khả năng có thể là Khoảng cách Levenshtein.
Lưu ý :đối với 50 nghìn mục nhập, kết quả sẽ không chính xác 100% vì nó sẽ không luôn luôn phân loại các thuật ngữ trong nhóm thích hợp nhưng điều này sẽ làm giảm đáng kể các nỗ lực thủ công.
Trong R, bạn có thể thực hiện việc này bằng cách sử dụng adist()
Sử dụng dữ liệu mẫu của bạn:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
Đối với mẫu nhỏ này, bạn có thể thấy 3 nhóm riêng biệt (các cụm có giá trị Khoảng cách Levensthein thấp) và có thể dễ dàng gán chúng theo cách thủ công, nhưng đối với các nhóm lớn hơn, bạn có thể sẽ cần một thuật toán phân cụm.
Tôi đã chỉ bạn trong các nhận xét đến một trong những câu trả lời trước đó
chỉ dẫn cách thực hiện việc này bằng cách sử dụng hclust() và phương pháp phương sai tối thiểu của Ward nhưng tôi nghĩ ở đây bạn nên sử dụng các kỹ thuật khác tốt hơn (một trong những tài nguyên yêu thích của tôi về chủ đề này để có cái nhìn tổng quan nhanh về một số phương pháp được sử dụng rộng rãi nhất trong R là đây câu trả lời chi tiết
)
Dưới đây là một ví dụ sử dụng phân nhóm lan truyền mối quan hệ:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
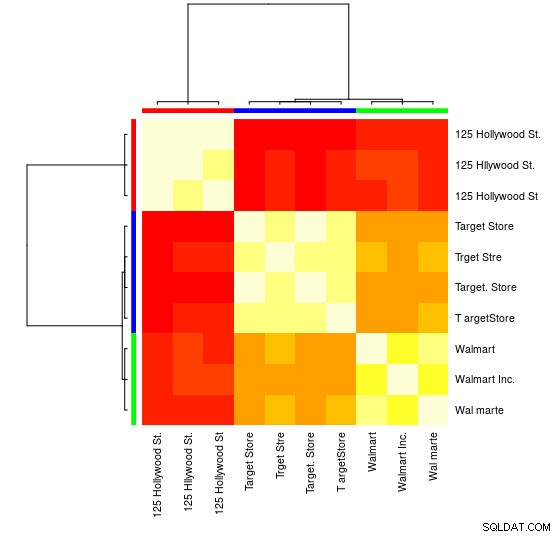
Bạn sẽ tìm thấy trong đối tượng APResult d_ap các phần tử được liên kết với mỗi cụm và số lượng cụm tối ưu, trong trường hợp này:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Bạn cũng có thể thấy hình ảnh đại diện:
> heatmap(d_ap, margins = c(10, 10))
Sau đó, bạn có thể thực hiện các thao tác tiếp theo cho mỗi nhóm. Ví dụ, ở đây tôi sử dụng hunspell để tra cứu từng từ riêng biệt từ Var1 trong từ điển en_US để tìm lỗi chính tả và cố gắng tìm trong mỗi nhóm group , id nào không có lỗi chính tả (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Điều này mang lại:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Lưu ý :Ở đây vì chúng tôi chưa thực hiện bất kỳ quá trình xử lý văn bản nào, nên kết quả không được kết luận cho lắm, nhưng bạn có thể hiểu được.
Dữ liệu
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)