Giới thiệu
Tìm ra loại cơ sở hạ tầng cơ sở dữ liệu nào bạn cần để phù hợp với các yêu cầu về hiệu suất, độ tin cậy và khả năng mở rộng của ứng dụng có thể là một nhiệm vụ khó khăn. Các lựa chọn bạn thực hiện cho cấu trúc liên kết cơ sở dữ liệu của mình có thể ảnh hưởng đến cách toàn bộ ngăn xếp ứng dụng của bạn phản ứng với các kiểu sử dụng khác nhau và những trường hợp lỗi mà nó có thể giải thích. Do đó, điều quan trọng là phải hiểu các lựa chọn của bạn và đưa ra quyết định sáng suốt phù hợp với mục tiêu của bạn.
Có nhiều cách khác nhau để đi từ một cơ sở dữ liệu duy nhất xử lý tất cả các nhu cầu cơ sở hạ tầng của bạn đến các hệ thống phức tạp hơn. Cùng với điều này, có nhiều sự đánh đổi cần cân nhắc.
Trong hướng dẫn này, chúng tôi sẽ giới thiệu một số mẫu phổ biến nhất cho cơ sở hạ tầng cơ sở dữ liệu quan hệ và cách chúng phù hợp với các mẫu sử dụng khác nhau. Chúng tôi sẽ giới thiệu cho các bạn những ưu điểm mà mỗi cấu hình mang lại cũng như một số thiếu sót mà bạn cần tính đến. Chúng tôi cũng sẽ nói về tác động của các quyết định khác nhau đối với sự phức tạp trong hoạt động tổng thể của bạn. Sau khi hoàn thành, bạn sẽ có thể đưa ra quyết định tốt hơn về những thiết kế nào phù hợp nhất với nhu cầu hiện tại của bạn và những tùy chọn nào bạn có thể muốn thử nghiệm khi nhu cầu của bạn thay đổi.
Chia tỷ lệ theo chiều dọc
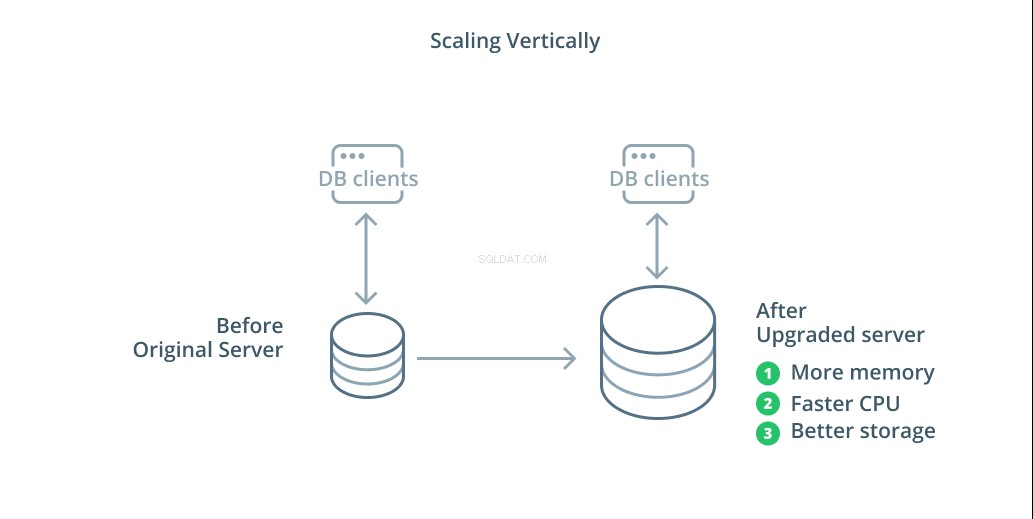
Cách đơn giản nhất để mở rộng hệ thống cơ sở dữ liệu là chia tỷ lệ theo chiều dọc. Chia tỷ lệ theo chiều dọc , còn được gọi là mở rộng quy mô , có nghĩa là thêm dung lượng cho máy chủ quản lý cơ sở dữ liệu của bạn. Bằng cách tăng sức mạnh xử lý, phân bổ bộ nhớ hoặc dung lượng lưu trữ, bạn có thể tăng hiệu suất và khối lượng mà hệ thống cơ sở dữ liệu có thể xử lý mà không làm tăng độ phức tạp của toàn bộ hệ thống.
Theo nguyên tắc chung, mở rộng cơ sở dữ liệu của bạn là một bước đầu tiên tốt vì nó tăng khả năng của cơ sở dữ liệu mà không ảnh hưởng đến cấu trúc liên kết cơ sở hạ tầng của bạn. Việc mở rộng quy mô thường cũng khá đơn giản, vì một máy có dung lượng lớn hơn có thể được định cấu hình như một máy theo dõi bản sao cho đến khi nó được đồng bộ hóa và sau đó chuyển đổi dự phòng có thể được kích hoạt để biến nó trở thành máy chủ chính mới.
Tuy nhiên, mở rộng quy mô có những hạn chế của nó vì số lượng tài nguyên có thể được phân bổ hợp lý cho một máy bị hạn chế. Nó cũng đại diện cho một điểm thất bại duy nhất nếu không có người theo dõi bản sao nào được cấu hình để tiếp quản khi sự cố xảy ra. Những mối quan tâm này được giải quyết bằng một số tùy chọn mở rộng quy mô khác.
Phân biệt trách nhiệm truy vấn lệnh (CQRS) và các bản sao Chỉ đọc
Cách chính khác để mở rộng cơ sở hạ tầng cơ sở dữ liệu của bạn là mở rộng quy mô. Mở rộng quy mô có nghĩa là thay vì tăng dung lượng của một máy chủ duy nhất, bạn tăng số lượng máy chủ chuyên dụng để phục vụ một nhu cầu cụ thể. Vì vậy, bạn tăng thêm dung lượng bằng cách thêm các máy bổ sung vào cơ sở hạ tầng của mình.
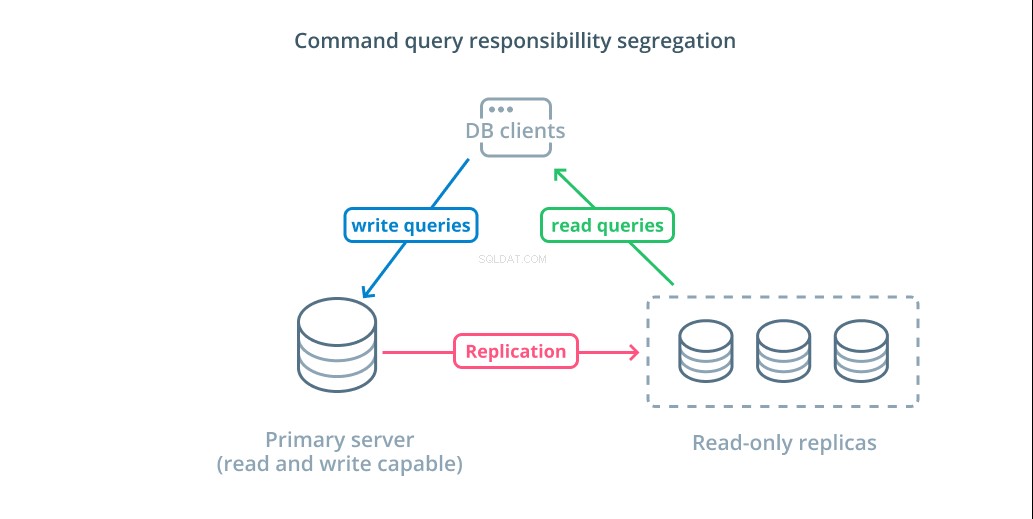
Phân biệt trách nhiệm truy vấn lệnh (CQRS) là một thuật ngữ được sử dụng để mô tả việc thêm logic để tách biệt các truy vấn làm thay đổi dữ liệu (truy vấn ghi) với những truy vấn không (truy vấn đọc). Điều này cho phép bạn định tuyến các danh mục yêu cầu khác nhau này đến các máy chủ khác nhau để giúp phân phối tải.
Cơ sở hạ tầng cơ bản nhất để tận dụng lợi thế của thiết kế này là một máy chủ chính có thể chấp nhận các truy vấn đọc và ghi kết hợp với một hoặc nhiều máy chủ bản sao theo sau máy chủ chính có thể chấp nhận các truy vấn đọc. Thiết kế này phù hợp với các kiểu sử dụng ứng dụng có tính năng đọc nhiều, vì bất kỳ máy chủ cơ sở dữ liệu nào cũng có thể xử lý các thao tác đọc.
Ngoài ra, hệ thống này cung cấp một số dự phòng cho kiến trúc của bạn vì hệ thống sẽ vẫn hoạt động nếu bất kỳ máy chủ nào gặp sự cố. Nếu một người theo dõi gặp sự cố, các yêu cầu đọc có thể được chuyển đến các máy chủ khác. Nếu máy chủ chính gặp sự cố, một trong những người theo dõi bản sao có thể được thăng cấp để chấp nhận các truy vấn viết.
Sao chép nhiều lần
Mặc dù việc sử dụng CQRS với các bản sao chỉ đọc giúp bạn giải quyết số lượng yêu cầu đọc cao hơn, nhưng nó không ảnh hưởng đáng kể đến hiệu suất ghi của cơ sở hạ tầng của bạn. Để tăng số lần ghi mà kiến trúc của bạn có thể xử lý, bạn cần xem xét liệu bạn có thể áp dụng thiết kế sao chép nhiều chính hay không.
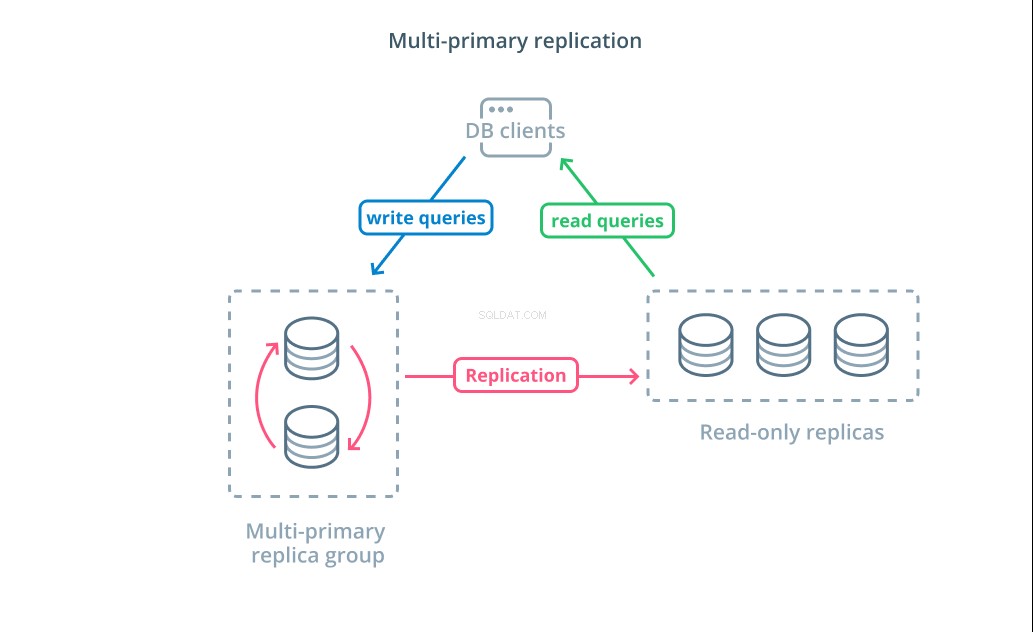
Sao chép nhiều lần chính là một dạng sao chép mà nhiều máy chủ có thể chấp nhận các yêu cầu ghi. Một số hệ thống được cấu hình để bất kỳ máy chủ nào cũng có thể xử lý yêu cầu ghi, trong khi những hệ thống khác được thiết kế để một nhóm máy chủ chính xử lý việc ghi với số lượng lớn hơn người theo dõi chỉ đọc. Bất kể việc triển khai như thế nào, sao chép nhiều chính sẽ làm tăng số lượng máy chủ chịu trách nhiệm ghi truy vấn.
Mặc dù thiết kế này có vẻ lý tưởng ngay từ đầu, nhưng có một số thách thức lớn khiến đây không thể là một mô hình được áp dụng rộng rãi. Trong khi nhiều máy chủ có thể xử lý các yêu cầu ghi, chúng vẫn phải phối hợp để sao chép các thay đổi giữa các máy chủ của mình và để giải quyết xung đột trong các thay đổi dữ liệu. Điều này có thể dẫn đến thời gian phản hồi lâu do các xung đột được thương lượng hoặc có khả năng dữ liệu không nhất quán.
Mỗi hệ thống chọn cách tiếp cận riêng của họ để xử lý những thách thức này. Đây là một minh chứng của Định lý CAP - một tuyên bố mô tả tác động qua lại giữa tính nhất quán, tính khả dụng và dung sai phân vùng trong các hệ thống phân tán - trong hoạt động. Một số hệ thống cung cấp đảm bảo tính nhất quán yếu hơn để duy trì tính khả dụng, trong khi các cơ sở dữ liệu khác từ chối chấp nhận các thay đổi nếu các đồng nghiệp của chúng không thể điều phối giao dịch tại thời điểm viết. Chọn cách tiếp cận phù hợp nhất với nhu cầu của bạn là một yếu tố quan trọng khi quyết định giữa các cách triển khai khác nhau.
Đọc bộ nhớ đệm truy vấn
Mặc dù sử dụng các bản sao chỉ đọc là một cách để tăng cơ sở dữ liệu có sẵn có thể đáp ứng các yêu cầu đọc, nhưng nó không cải thiện hiệu suất truy vấn cơ bản của các hoạt động đọc phức tạp. Một trong các máy chủ vẫn phải thực hiện thao tác đọc mỗi khi yêu cầu được thực hiện, ngay cả khi kết quả giống với lần tra cứu trước đó.
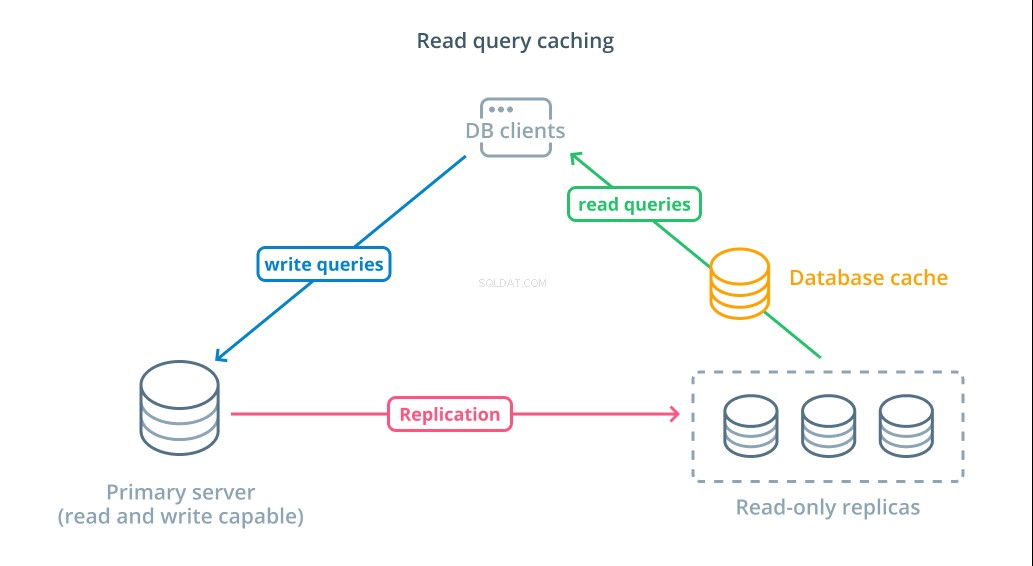
Để giảm thời gian phản hồi, hãy đọc bộ nhớ đệm truy vấn lớp có thể được giới thiệu. Việc thêm bộ đệm ẩn giữa các máy khách cơ sở dữ liệu của bạn và chính các cơ sở dữ liệu có thể giảm đáng kể thời gian truy vấn cho các yêu cầu chung. Ứng dụng có thể yêu cầu đọc kết quả từ bộ nhớ đệm và nhận chúng gần như ngay lập tức nếu có. Đối với những trường hợp không tìm thấy kết quả trong bộ đệm, chúng sẽ được tìm nạp từ chính cơ sở dữ liệu và được thêm vào bộ đệm cho lần sau.
Định cấu hình bộ nhớ đệm theo cách này cực kỳ hiệu quả đối với các trường hợp mà dữ liệu không có khả năng thay đổi mỗi khi yêu cầu được thực hiện. Nó đặc biệt hữu ích cho các truy vấn đọc đắt tiền tham khảo nhiều bảng và bao gồm các hoạt động nối phức tạp. Các kết quả này có thể được thực thi một lần và sau đó được lưu lại cho các truy vấn trong tương lai.
Trong trường hợp dữ liệu thay đổi nhanh hơn, bộ nhớ đệm đọc có thể không giúp được nhiều. Tùy thuộc vào hành vi được định cấu hình, bộ nhớ đệm có nguy cơ trả lại dữ liệu cũ trong những trường hợp này và các chiến lược hủy bỏ hiệu lực bộ nhớ cache chu đáo nên được thực hiện để loại bỏ dữ liệu cũ khỏi bộ nhớ cache khi được thay đổi.
Phân tích dữ liệu
Cho đến nay, các thiết kế mà chúng ta đã thảo luận đã phân đoạn các thành phần cơ sở dữ liệu dựa trên việc chúng có phản hồi để viết các yêu cầu hay không. Tuy nhiên, một cách khác để phân chia trách nhiệm là chia tập dữ liệu thực tế thành nhiều phần.
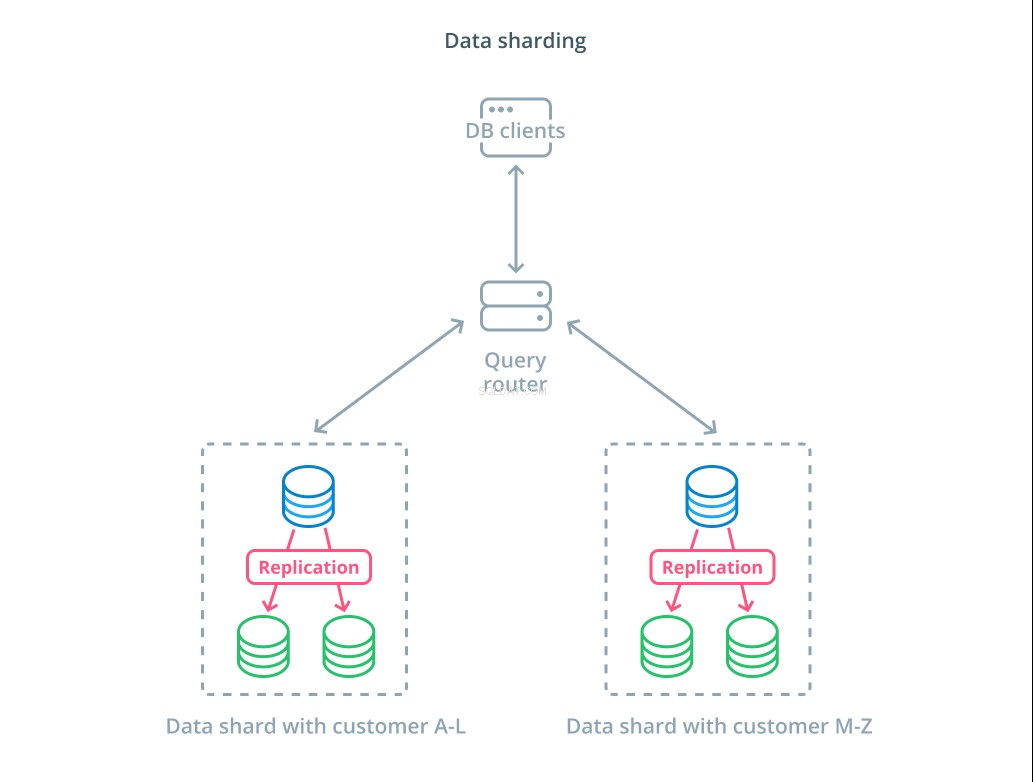
Mài sắc là quá trình chia nhỏ một tập dữ liệu logic thành các tập con nhỏ hơn để phân phối quyền quản lý của chúng cho các máy khác nhau. Mỗi máy chủ cơ sở dữ liệu chỉ xử lý một phần dữ liệu và một công cụ định tuyến được giới thiệu để hiểu máy nào chịu trách nhiệm cho những phần dữ liệu nào.
Thông thường, sharding được thực hiện trong các tình huống mà thao tác trên toàn bộ tập dữ liệu cùng một lúc là không cần thiết hoặc không phổ biến. Tập dữ liệu được phân đoạn dựa trên giá trị của mỗi bản ghi cho một khóa cụ thể, được gọi là khóa sharding . Ví dụ:bạn có thể phân đoạn dữ liệu theo cách thủ công dựa trên vị trí của khách hàng. Bạn cũng có thể phân đoạn tự động bằng cách sử dụng thuật toán băm để xác định nút nào sẽ xử lý khóa nào. Điều này có thể giúp hệ thống của bạn tránh phân phối không cân bằng trong trường hợp không gian phím phân đoạn được phân phối không đồng đều.
Sharding đưa vào hệ thống dữ liệu khá phức tạp và không phù hợp với mọi tình huống. Các hoạt động tương tác với nhiều phân đoạn sẽ bị phạt hiệu suất đáng kể khi chúng lấy kết quả từ mỗi thành viên. Điều này có thể xảy ra đối với các truy vấn tổng hợp hoặc nếu khóa phân đoạn cụ thể không được biết trước. Ngoài ra, việc phân bổ không đồng đều các phân đoạn cũng có thể gây ra sự kém hiệu quả và tắc nghẽn cần được khắc phục bằng cách cân bằng lại việc phân phối toàn bộ tập dữ liệu.
Quản lý dữ liệu chức năng phi tập trung
Thay vì chia nhỏ các giá trị của một tập dữ liệu thành nhiều phân đoạn, trong nhiều trường hợp, việc sử dụng các cơ sở dữ liệu khác nhau cho các mục đích chức năng khác nhau sẽ có ý nghĩa hơn. Ví dụ:nếu bạn có dịch vụ tài khoản và dịch vụ sản phẩm, việc có cơ sở dữ liệu chuyên dụng trùng với từng mối quan tâm có thể giúp bạn mở rộng các thành phần khác nhau một cách độc lập.
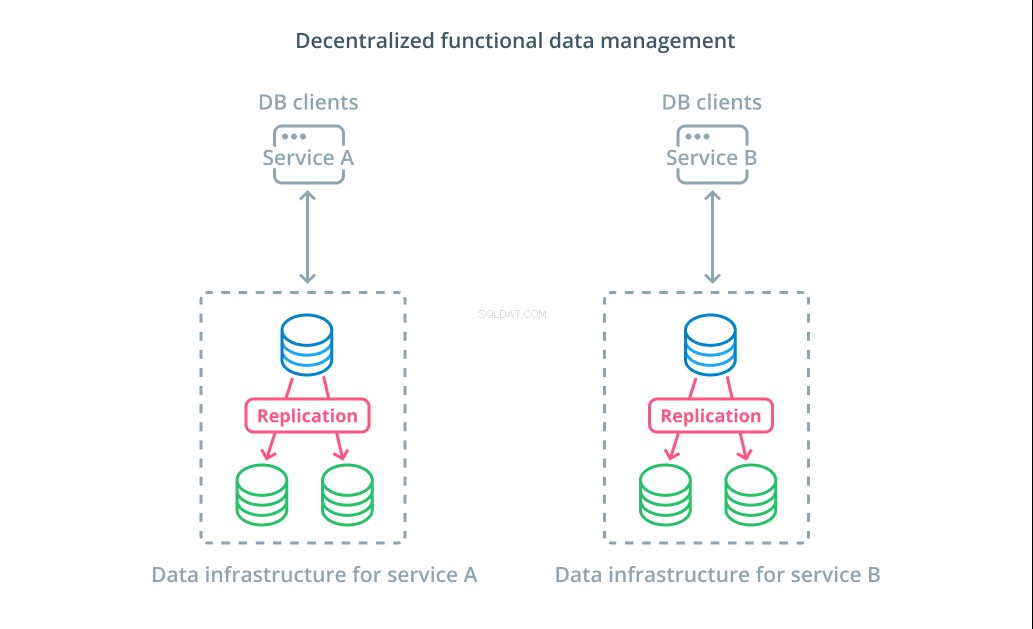
Quản lý dữ liệu chức năng cho phép bạn chia nhỏ cơ sở hạ tầng cơ sở dữ liệu của mình và quản lý từng phần theo nhu cầu của khách hàng. Mỗi bộ phận chức năng có thể được thay đổi tỷ lệ bằng cách sử dụng bất kỳ chiến lược nào phù hợp nhất. Nó cho phép bạn thiết kế lược đồ cơ sở dữ liệu và triển khai nó đến một vị trí phù hợp nhất với các mẫu của một trường hợp sử dụng cụ thể thay vì yêu cầu nó phải phục vụ toàn bộ tổ chức.
Đối với nhiều tổ chức, chiến lược này có những lợi thế quan trọng vượt ra ngoài các thuộc tính của hệ thống thực tế. Việc phân quyền quản lý dữ liệu có thể cho phép các nhóm nhỏ hơn sở hữu dữ liệu của riêng họ mà không cần phối hợp thay đổi với các bên khác. Nó phù hợp tốt với việc phân tách tập trung các mối quan tâm được thúc đẩy bởi các kiến trúc ứng dụng hướng dịch vụ vi mô.
Cơ sở dữ liệu không máy chủ
Những sự đánh đổi khác nhau mà bạn phải đánh giá và số lượng cơ sở hạ tầng bạn có thể phải quản lý để mở rộng quy mô phù hợp có thể khiến nhiều người choáng ngợp. Một tùy chọn để giảm bớt sự phức tạp này là tận dụng các dịch vụ cơ sở dữ liệu quản lý cơ sở hạ tầng và quy mô cho bạn.
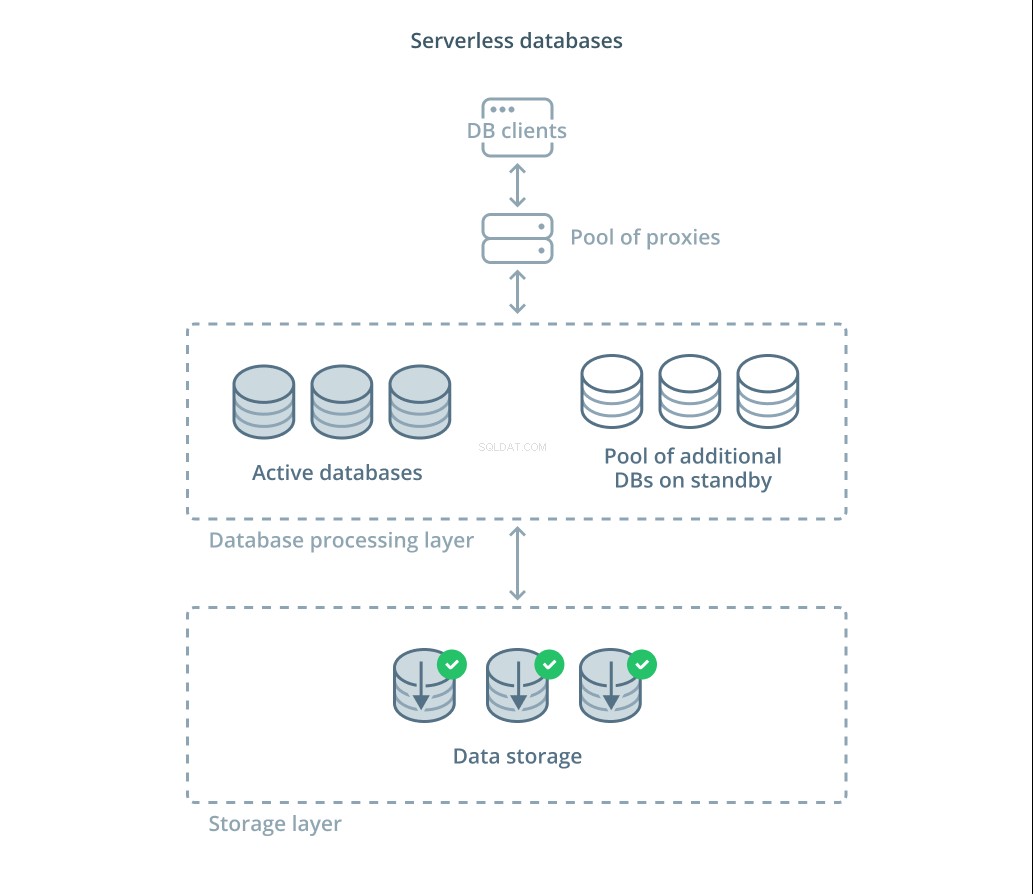
Cơ sở dữ liệu không máy chủ là một danh mục dịch vụ tách rời việc lưu trữ dữ liệu khỏi quá trình xử lý dữ liệu để dễ dàng mở rộng tài nguyên theo những thay đổi của nhu cầu.
Lớp lưu trữ dữ liệu có nhiệm vụ duy trì dữ liệu thực tế do hệ thống quản lý. Ở phía trước của lớp này, một cấp các đơn vị xử lý cơ sở dữ liệu có thể mở rộng được triển khai để xử lý quá trình xử lý truy vấn thực tế đối với các tập dữ liệu. Số lượng đơn vị hoạt động tại bất kỳ thời điểm nhất định nào được liên kết trực tiếp với mức sử dụng hiện tại, do đó, nhiều tài nguyên hơn được phân bổ khi nhu cầu đạt đến đỉnh điểm và các đơn vị xử lý được đưa về chế độ chờ nếu mọi thứ im lặng.
Các truy vấn được chuyển tiếp đến bộ xử lý cơ sở dữ liệu thông qua proxy định tuyến biết cách chuyển tiếp yêu cầu tới các nút đang hoạt động và khi nào cần yêu cầu tài nguyên bổ sung.
Cơ sở dữ liệu không máy chủ có nhiều thuộc tính giống như các dịch vụ cơ sở dữ liệu truyền thống thực hiện các tính năng tự động chia tỷ lệ. Cả hai đều có thể phân bổ công suất dựa trên nhu cầu. Tuy nhiên, cơ sở dữ liệu không máy chủ cho phép bạn tách chi phí lưu trữ khỏi chi phí xử lý và có thể giảm quy mô xử lý xuống 0 khi không cần thiết. Ngoài ra, các giải pháp không máy chủ có xu hướng có thể mở rộng quy mô nhanh hơn nhiều để đáp ứng nhu cầu so với tính năng tự động chia tỷ lệ do các dịch vụ truyền thống cung cấp.
Mặc dù cơ sở dữ liệu không máy chủ có thể phù hợp với một số người, nhưng chúng không phải là một viên đạn bạc. Trong trường hợp bộ xử lý cơ sở dữ liệu đã được thu nhỏ về 0, có thể có sự chậm trễ trong quá trình xử lý lại do khởi động nguội. Hơn nữa, sự xáo trộn giữa các kết nối giữa các thành phần khác nhau trong ngăn xếp cơ sở dữ liệu không máy chủ có thể dẫn đến độ trễ bổ sung.
Nền tảng cơ sở dữ liệu không máy chủ cũng có thể khó khăn từ quan điểm hoạt động. Việc triển khai và thay đổi cơ sở dữ liệu có thể khó khăn hơn để lập luận và giám sát. Môi trường phát triển cục bộ cũng có thể khác đáng kể so với môi trường sản xuất vì trạng thái động của hệ thống cơ sở dữ liệu. Và cuối cùng, như với bất kỳ dịch vụ đám mây nào khác, việc sử dụng cơ sở dữ liệu không máy chủ có thể khiến bạn gặp nguy cơ bị nhà cung cấp khóa. Điều quan trọng là phải nhớ những đánh đổi này khi thiết kế xung quanh nền tảng không máy chủ.
Kết luận
Có nhiều cách để thiết kế, triển khai và quản lý cơ sở hạ tầng cơ sở dữ liệu của bạn khi các yêu cầu ứng dụng của bạn trở nên nghiêm trọng hơn. Mỗi giải pháp đều có những điểm mạnh và hạn chế, điều quan trọng cần hiểu khi cố gắng tìm kiếm sự phù hợp với môi trường của bạn.
Tìm hiểu về cách cơ sở hạ tầng cơ sở dữ liệu ảnh hưởng đến tính khả dụng, hiệu suất và tính toàn vẹn của dữ liệu cho phép bạn tránh những sai lầm tốn kém và triển khai không mang lại sự đảm bảo mà bạn cần. Nếu một trong những thiết kế trên không đáp ứng được yêu cầu của bạn, bạn có thể kết hợp một số yếu tố của các phương pháp tiếp cận khác nhau để đạt được những lợi thế bổ sung.
Nếu bạn muốn tìm hiểu thêm về các mẫu chung được đề cập ở trên, đây là một số tài nguyên bổ sung mà bạn có thể muốn xem:
- Mở rộng quy mô so với mở rộng quy mô
- Phân biệt trách nhiệm truy vấn lệnh
- Sao chép nhiều lần sơ cấp
- Lưu vào bộ nhớ đệm các truy vấn đã đọc
- Phân bổ dữ liệu
- Quản lý dữ liệu phi tập trung
- Cơ sở dữ liệu không máy chủ