
Vào Thứ Ba T-SQL của tháng này, Steve Jones (@ way0utwest) đã yêu cầu chúng tôi nói về trải nghiệm kích hoạt tốt nhất hoặc tồi tệ nhất của chúng tôi. Mặc dù đúng là các trình kích hoạt thường khiến người dùng khó chịu và thậm chí sợ hãi, nhưng chúng có một số trường hợp sử dụng hợp lệ, bao gồm:
- Kiểm tra (trước SP1 2016, khi tính năng này được cung cấp miễn phí trong tất cả các phiên bản)
- Thực thi các quy tắc nghiệp vụ và tính toàn vẹn của dữ liệu, khi chúng không thể dễ dàng được triển khai trong các ràng buộc và bạn không muốn chúng phụ thuộc vào mã ứng dụng hoặc chính các truy vấn DML
- Duy trì các phiên bản lịch sử của dữ liệu (trước khi Thu thập dữ liệu thay đổi, Theo dõi thay đổi và Bảng tạm thời)
- Cảnh báo xếp hàng hoặc xử lý không đồng bộ để đáp ứng với một thay đổi cụ thể
- Cho phép sửa đổi các chế độ xem (thông qua INSTEAD OF trình kích hoạt)
Đó không phải là một danh sách đầy đủ, chỉ là một bản tóm tắt nhanh về một vài tình huống mà tôi đã trải qua trong đó kích hoạt là câu trả lời phù hợp vào thời điểm đó.
Khi các kích hoạt là cần thiết, tôi luôn thích khám phá việc sử dụng các kích hoạt INSTEAD OF hơn là các kích hoạt SAU. Đúng, chúng là công việc nâng cao hơn một chút *, nhưng chúng có một số lợi ích khá quan trọng. Về lý thuyết, ít nhất, viễn cảnh ngăn chặn một hành động (và hậu quả ghi lại của nó) xảy ra có vẻ hiệu quả hơn rất nhiều so với việc để tất cả xảy ra rồi hoàn tác.
*Tôi nói điều này bởi vì bạn phải viết mã lệnh DML một lần nữa trong trình kích hoạt; đây là lý do tại sao chúng không được gọi là kích hoạt TRƯỚC. Sự phân biệt là quan trọng ở đây, vì một số hệ thống triển khai các trình kích hoạt TRƯỚC KHI thực sự, mà chỉ đơn giản là chạy trước. Trong SQL Server, trình kích hoạt INSTEAD OF có hiệu quả hủy bỏ câu lệnh khiến nó kích hoạt.
Giả sử chúng ta có một bảng đơn giản để lưu trữ tên tài khoản. Trong ví dụ này, chúng tôi sẽ tạo hai bảng, vì vậy chúng tôi có thể so sánh hai trình kích hoạt khác nhau và tác động của chúng đến thời lượng truy vấn và việc sử dụng nhật ký. Khái niệm là chúng tôi có một quy tắc kinh doanh:tên tài khoản không xuất hiện trong một bảng khác, đại diện cho các tên "xấu" và trình kích hoạt được sử dụng để thực thi quy tắc này. Đây là cơ sở dữ liệu:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO Và các bảng:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
Và cuối cùng, các yếu tố kích hoạt. Để đơn giản, chúng tôi chỉ xử lý các phần chèn và trong cả trường hợp sau và thay thế, chúng tôi sẽ hủy bỏ toàn bộ đợt nếu có bất kỳ tên nào vi phạm quy tắc của chúng tôi:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Bây giờ, để kiểm tra hiệu suất, chúng tôi sẽ cố gắng chèn 100.000 tên vào mỗi bảng, với tỷ lệ thất bại có thể dự đoán được là 10%. Nói cách khác, 90.000 là tên phù hợp, 10.000 tên còn lại không đạt yêu cầu kiểm tra và khiến trình kích hoạt khôi phục hoặc không chèn tùy thuộc vào lô.
Trước tiên, chúng ta cần thực hiện một số thao tác dọn dẹp trước mỗi đợt:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Trước khi bắt đầu chia thịt mỗi lô, chúng tôi sẽ đếm các hàng trong nhật ký giao dịch, đồng thời đo kích thước và dung lượng trống. Sau đó, chúng ta sẽ đi qua một con trỏ để xử lý 100.000 hàng theo thứ tự ngẫu nhiên, cố gắng chèn từng tên vào bảng thích hợp. Khi hoàn tất, chúng tôi sẽ đo lại số lượng hàng và kích thước của nhật ký, đồng thời kiểm tra thời lượng.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Kết quả (tính trung bình trên 5 lần chạy mỗi đợt):
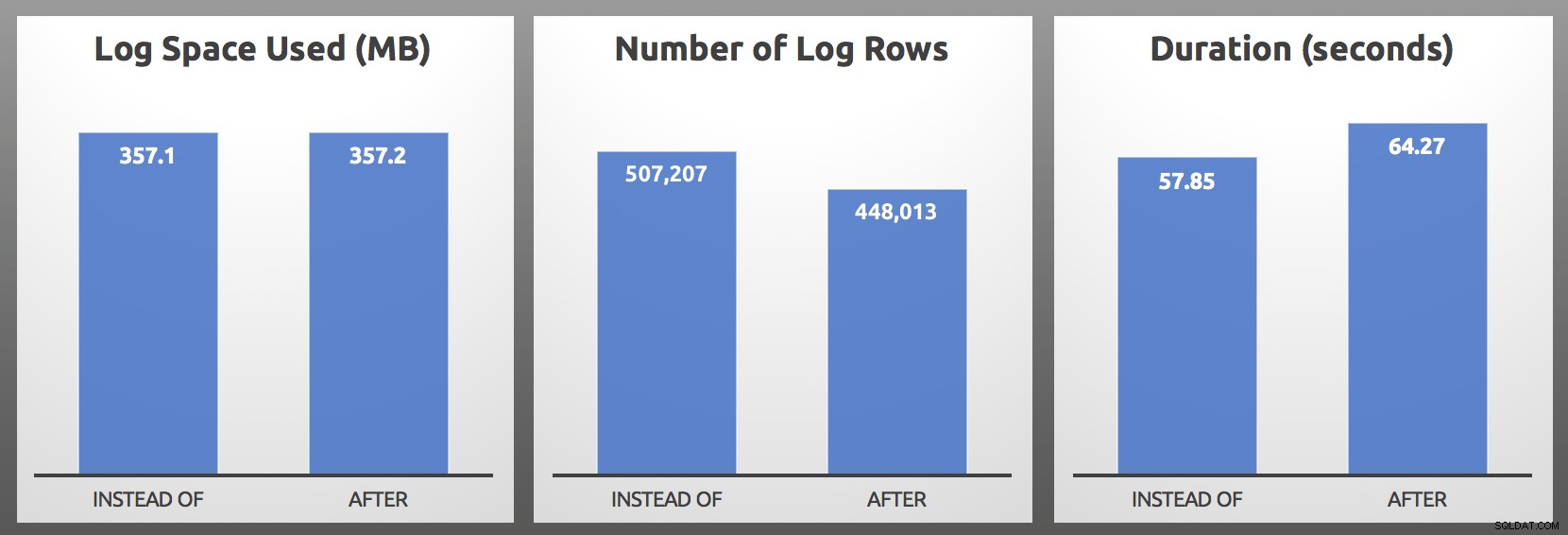 SAU so với INSTEAD OF:Kết quả
SAU so với INSTEAD OF:Kết quả
Trong các thử nghiệm của tôi, việc sử dụng nhật ký có kích thước gần như giống hệt nhau, với hơn 10% số hàng nhật ký được tạo bởi trình kích hoạt INSTEAD OF. Tôi đã thực hiện một số thao tác đào vào cuối mỗi đợt:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
Và đây là một kết quả điển hình (tôi đã đánh dấu các châu thổ chính):
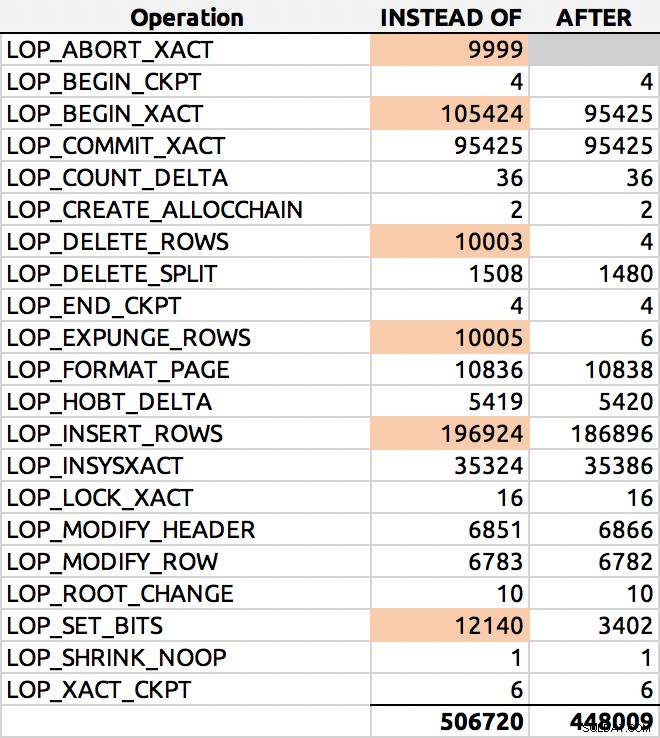 Phân phối hàng nhật ký
Phân phối hàng nhật ký
Tôi sẽ tìm hiểu sâu hơn về vấn đề đó vào lần khác.
Nhưng khi bạn bắt tay ngay vào nó…
… Số liệu quan trọng nhất hầu như luôn luôn là thời lượng và trong trường hợp của tôi, trình kích hoạt INSTEAD OF hoạt động nhanh hơn ít nhất 5 giây trong mỗi bài kiểm tra đối đầu. Trong trường hợp tất cả điều này nghe có vẻ quen thuộc, vâng, tôi đã nói về nó trước đây, nhưng hồi đó tôi không quan sát thấy các triệu chứng tương tự này với các hàng nhật ký.
Lưu ý rằng đây có thể không phải là lược đồ hoặc khối lượng công việc chính xác của bạn, bạn có thể có phần cứng rất khác, đồng thời của bạn có thể cao hơn và tỷ lệ thất bại của bạn có thể cao hơn (hoặc thấp hơn). Các bài kiểm tra của tôi được thực hiện trên một máy riêng biệt có nhiều bộ nhớ và SSD PCIe rất nhanh. Nếu nhật ký của bạn chạy chậm hơn, thì sự khác biệt trong việc sử dụng nhật ký có thể lớn hơn các chỉ số khác và thay đổi thời lượng đáng kể. Tất cả các yếu tố này (và hơn thế nữa!) Có thể ảnh hưởng đến kết quả của bạn, vì vậy bạn nên thử nghiệm trong môi trường của mình.
Tuy nhiên, vấn đề là INSTEAD OF kích hoạt có thể phù hợp hơn. Bây giờ giá như chúng ta có thể INSTEAD OF DDL kích hoạt…



