Các nhiệm vụ Khoảng cách và Quần đảo là những thử thách truy vấn cổ điển mà bạn cần xác định các phạm vi giá trị bị thiếu và phạm vi giá trị hiện có trong một trình tự. Trình tự thường dựa trên một số giá trị ngày tháng hoặc ngày tháng và thời gian, thường sẽ xuất hiện trong các khoảng thời gian đều đặn, nhưng một số mục nhập bị thiếu. Nhiệm vụ khoảng trống tìm kiếm các khoảng thời gian bị thiếu và nhiệm vụ đảo tìm kiếm các khoảng thời gian hiện có. Tôi đã đề cập đến nhiều giải pháp cho các nhiệm vụ thiếu hụt và đảo trong các sách và bài báo của mình trong quá khứ. Gần đây, tôi đã được bạn tôi, Adam Machanic, đưa ra một thử thách đảo đặc biệt mới và việc giải quyết nó đòi hỏi một chút sáng tạo. Trong bài viết này, tôi trình bày thách thức và giải pháp mà tôi đưa ra.
Thử thách
Trong cơ sở dữ liệu của mình, bạn theo dõi các dịch vụ mà công ty của bạn hỗ trợ trong một bảng có tên là CompanyServices và mỗi dịch vụ thường báo cáo khoảng một phút một lần rằng dịch vụ đó trực tuyến trong một bảng có tên EventLog. Đoạn mã sau tạo các bảng này và điền chúng với các tập dữ liệu mẫu nhỏ:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
Bảng EventLog hiện được điền với dữ liệu sau:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
Nhiệm vụ đặc biệt của các đảo là xác định các khoảng thời gian khả dụng (phục vụ, thời gian bắt đầu, thời gian kết thúc). Một điều cần lưu ý là không có gì đảm bảo rằng một dịch vụ sẽ báo cáo rằng dịch vụ đó trực tuyến chính xác từng phút; bạn phải chịu được khoảng thời gian lên đến 66 giây kể từ lần nhập nhật ký trước đó và vẫn coi đó là một phần của cùng khoảng thời gian khả dụng (đảo). Sau 66 giây, mục nhập nhật ký mới bắt đầu một khoảng thời gian khả dụng mới. Vì vậy, đối với dữ liệu mẫu đầu vào ở trên, giải pháp của bạn phải trả về tập kết quả sau (không nhất thiết phải theo thứ tự này):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Lưu ý, ví dụ:cách mục nhập nhật ký 5 bắt đầu đảo mới vì khoảng thời gian từ mục nhật ký trước đó là 120 giây (> 66), trong khi mục nhật ký 6 không bắt đầu đảo mới vì khoảng thời gian từ mục nhập trước đó là 62 giây ( <=66). Một điểm khác là Adam muốn giải pháp tương thích với môi trường trước SQL Server 2012, điều này khiến nó trở thành một thách thức khó hơn nhiều, vì bạn không thể sử dụng các hàm tổng hợp cửa sổ với một khung để tính toán tổng đang chạy và các hàm cửa sổ bù trừ như LAG và LEAD. Như thường lệ, tôi khuyên bạn nên tự mình giải quyết thử thách trước khi xem xét các giải pháp của tôi. Sử dụng các bộ dữ liệu mẫu nhỏ để kiểm tra tính hợp lệ của các giải pháp của bạn. Sử dụng mã sau để điền vào các bảng của bạn một tập hợp lớn dữ liệu mẫu (500 dịch vụ, ~ 10 triệu mục nhập nhật ký để kiểm tra hiệu suất của các giải pháp của bạn):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Kết quả đầu ra mà tôi sẽ cung cấp cho các bước của giải pháp của mình sẽ giả sử các tập dữ liệu mẫu nhỏ và số hiệu suất mà tôi cung cấp sẽ giả định các tập hợp lớn.
Tất cả các giải pháp mà tôi trình bày sẽ được hưởng lợi từ chỉ số sau:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Chúc bạn thành công!
Giải pháp 1 cho SQL Server 2012+
Trước khi tôi trình bày một giải pháp tương thích với môi trường trước SQL Server 2012, tôi sẽ trình bày một giải pháp yêu cầu tối thiểu SQL Server 2012. Tôi sẽ gọi nó là Giải pháp 1.
Bước đầu tiên trong giải pháp là tính một cờ có tên isstart là 0 nếu sự kiện không bắt đầu một đảo mới và 1 nếu ngược lại. Điều này có thể đạt được bằng cách sử dụng hàm LAG để lấy thời gian ghi của sự kiện trước đó và kiểm tra xem chênh lệch thời gian tính bằng giây giữa sự kiện trước đó và hiện tại có nhỏ hơn hoặc bằng khoảng cách cho phép hay không. Đây là mã triển khai bước này:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Mã này tạo ra kết quả sau:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Tiếp theo, một tổng số cờ isstart đang chạy đơn giản tạo ra một số nhận dạng đảo (tôi sẽ gọi nó là grp). Đây là mã triển khai bước này:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Mã này tạo ra kết quả sau:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Cuối cùng, bạn nhóm các hàng theo ID dịch vụ và số nhận dạng đảo và trả về thời gian ghi nhật ký tối thiểu và tối đa là thời gian bắt đầu và thời gian kết thúc của mỗi đảo. Đây là giải pháp hoàn chỉnh:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Giải pháp này mất 41 giây để hoàn thành trên hệ thống của tôi và tạo ra kế hoạch được hiển thị trong Hình 1.
 Hình 1:Kế hoạch cho Giải pháp 1
Hình 1:Kế hoạch cho Giải pháp 1
Như bạn có thể thấy, cả hai hàm cửa sổ đều được tính toán dựa trên thứ tự chỉ mục mà không cần phân loại rõ ràng.
Nếu bạn đang sử dụng SQL Server 2016 trở lên, bạn có thể sử dụng thủ thuật mà tôi trình bày ở đây để bật toán tử Window Aggregate ở chế độ hàng loạt bằng cách tạo một chỉ mục columnstore được lọc trống, như sau:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Giải pháp tương tự hiện chỉ mất 5 giây để hoàn thành trên hệ thống của tôi, tạo ra kế hoạch được hiển thị trong Hình 2.
 Hình 2:Kế hoạch cho Giải pháp 1 sử dụng toán tử Tổng hợp cửa sổ chế độ hàng loạt
Hình 2:Kế hoạch cho Giải pháp 1 sử dụng toán tử Tổng hợp cửa sổ chế độ hàng loạt
Điều này thật tuyệt, nhưng như đã đề cập, Adam đang tìm kiếm một giải pháp có thể chạy trên các môi trường trước năm 2012.
Trước khi bạn tiếp tục, hãy đảm bảo rằng bạn thả chỉ mục columnstore để dọn dẹp:
DROP INDEX idx_cs ON dbo.EventLog;
Giải pháp 2 cho môi trường trước SQL Server 2012
Rất tiếc, trước SQL Server 2012, chúng tôi không có hỗ trợ cho các hàm cửa sổ bù đắp như LAG, cũng như không hỗ trợ tính toán tổng số đang chạy với các hàm tổng hợp cửa sổ có khung. Điều này có nghĩa là bạn sẽ cần phải làm việc chăm chỉ hơn nhiều để đưa ra giải pháp hợp lý.
Mẹo tôi đã sử dụng là biến mỗi mục nhập nhật ký thành một khoảng thời gian giả tạo có thời gian bắt đầu là thời gian ghi nhật ký của mục nhập và có thời gian kết thúc là thời gian ghi nhật ký của mục nhập cộng với khoảng cách cho phép. Sau đó, bạn có thể coi nhiệm vụ này như một nhiệm vụ đóng gói khoảng thời gian cổ điển.
Bước đầu tiên trong giải pháp tính toán các dấu phân cách khoảng giả tạo và số hàng đánh dấu vị trí của từng loại sự kiện (số đếm). Đây là mã triển khai bước này:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Mã này tạo ra kết quả sau:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Bước tiếp theo là bỏ chia các khoảng thời gian thành một chuỗi sự kiện bắt đầu và kết thúc theo trình tự thời gian, được xác định là các loại sự kiện 's' và 'e', tương ứng. Lưu ý rằng việc lựa chọn các chữ cái s và e là rất quan trọng ('s' > 'e' ). Bước này tính toán các số hàng đánh dấu thứ tự thời gian chính xác của cả hai loại sự kiện, hiện được xen kẽ (số đếm). Trong trường hợp một khoảng kết thúc chính xác ở nơi khác bắt đầu, bằng cách định vị sự kiện bắt đầu trước sự kiện kết thúc, bạn sẽ gói chúng lại với nhau. Đây là mã triển khai bước này:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Mã này tạo ra kết quả sau:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Như đã đề cập, đếm đánh dấu vị trí của sự kiện chỉ trong số các sự kiện cùng loại và đếm ngược đánh dấu vị trí của sự kiện trong số các sự kiện kết hợp, xen kẽ, của cả hai loại.
Sau đó, phép thuật được xử lý ở bước tiếp theo - tính toán số khoảng thời gian hoạt động sau mỗi sự kiện dựa trên đếm và đếm. Số khoảng thời gian hoạt động là số sự kiện bắt đầu đã xảy ra cho đến nay trừ đi số lượng sự kiện kết thúc đã xảy ra cho đến nay. Đối với các sự kiện bắt đầu, bộ đếm cho bạn biết có bao nhiêu sự kiện bắt đầu đã xảy ra cho đến nay và bạn có thể tìm ra bao nhiêu sự kiện đã kết thúc cho đến nay bằng cách lấy số đếm trừ đi. Vì vậy, biểu thức hoàn chỉnh cho bạn biết có bao nhiêu khoảng thời gian đang hoạt động sau đó:
counteach - (countboth - counteach)
Đối với các sự kiện kết thúc, bộ đếm cho bạn biết có bao nhiêu sự kiện kết thúc đã xảy ra cho đến nay và bạn có thể tìm ra bao nhiêu sự kiện bắt đầu cho đến nay bằng cách trừ số lượng cho số đếm. Vì vậy, biểu thức hoàn chỉnh cho bạn biết có bao nhiêu khoảng thời gian đang hoạt động sau đó:
(countboth - counteach) - counteach
Sử dụng biểu thức CASE sau, bạn tính toán cột đếm dựa trên loại sự kiện:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END Trong cùng một bước, bạn chỉ lọc các sự kiện đại diện cho các sự kiện bắt đầu và kết thúc của các khoảng thời gian được đóng gói. Số bắt đầu của các khoảng được đóng gói có loại 's' và số đếm 1. Kết thúc của các khoảng được đóng gói có loại 'e' và số đếm có hiệu lực 0.
Sau khi lọc, bạn sẽ còn lại các cặp sự kiện bắt đầu của các khoảng thời gian được đóng gói, nhưng mỗi cặp được chia thành hai hàng — một cho sự kiện bắt đầu và một cho sự kiện kết thúc. Do đó, bước tương tự sẽ tính toán số nhận dạng cặp bằng cách sử dụng số hàng, với công thức (rownum - 1) / 2 + 1.
Đây là mã triển khai bước này:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Mã này tạo ra kết quả sau:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
Bước cuối cùng xoay các cặp sự kiện thành một hàng trên mỗi khoảng thời gian và trừ khoảng cách cho phép từ thời gian kết thúc để tạo lại thời gian sự kiện chính xác. Đây là mã hoàn chỉnh của giải pháp:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Giải pháp này mất 43 giây để hoàn thành trên hệ thống của tôi và tạo ra kế hoạch được hiển thị trong Hình 3.
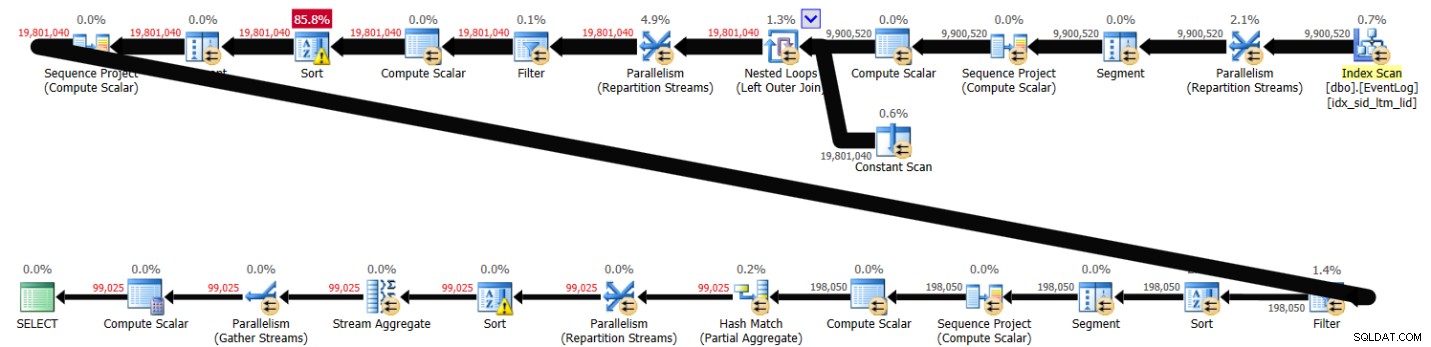 Hình 3:Kế hoạch cho Giải pháp 2
Hình 3:Kế hoạch cho Giải pháp 2
Như bạn có thể thấy, phép tính số hàng đầu tiên được tính dựa trên thứ tự chỉ mục, nhưng hai phép tính tiếp theo liên quan đến sắp xếp rõ ràng. Tuy nhiên, hiệu suất không tệ đến mức có khoảng 10.000.000 hàng tham gia.
Mặc dù điểm mấu chốt về giải pháp này là sử dụng môi trường trước SQL Server 2012, nhưng để cho vui, tôi đã kiểm tra hiệu suất của nó sau khi tạo chỉ mục columnstore được lọc để xem nó hoạt động như thế nào khi bật xử lý hàng loạt:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Khi kích hoạt xử lý hàng loạt, giải pháp này mất 29 giây để hoàn thành trên hệ thống của tôi, tạo ra kế hoạch được hiển thị trong Hình 4.
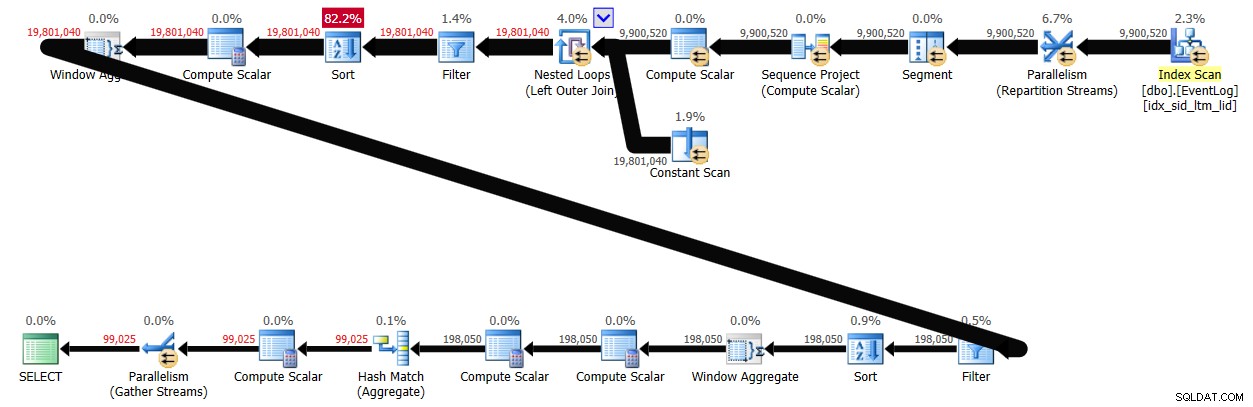
Kết luận
Điều tự nhiên là môi trường của bạn càng hạn chế thì việc giải quyết các nhiệm vụ truy vấn càng trở nên khó khăn hơn. Thử thách quần đảo đặc biệt của Adam dễ giải quyết hơn nhiều trên các phiên bản SQL Server mới hơn so với các phiên bản cũ hơn. Nhưng sau đó bạn buộc mình phải sử dụng nhiều kỹ thuật sáng tạo hơn. Vì vậy, như một bài tập, để cải thiện kỹ năng truy vấn của mình, bạn có thể giải quyết những thách thức mà bạn đã quen thuộc, nhưng cố ý áp đặt một số hạn chế nhất định. Bạn không bao giờ biết mình có thể vấp phải những loại ý tưởng thú vị nào!