Giới thiệu
Các nhà phát triển thường được yêu cầu sử dụng các thủ tục được lưu trữ để tránh cái gọi là truy vấn đặc biệt điều này có thể dẫn đến sự phình to không cần thiết của bộ nhớ cache kế hoạch. Bạn thấy đấy, khi mã SQL lặp lại được viết không nhất quán hoặc khi có mã tạo SQL động nhanh chóng, SQL Server có xu hướng tạo một kế hoạch thực thi cho từng lần thực thi riêng lẻ. Điều này có thể làm giảm hiệu suất tổng thể do:
-
Yêu cầu giai đoạn biên dịch cho mỗi lần thực thi mã.
-
Làm đầy Bộ nhớ cache kế hoạch với quá nhiều trình xử lý kế hoạch có thể không được sử dụng lại.
Tối ưu hóa cho Khối lượng công việc của Ad Hoc
Một cách mà vấn đề này đã được xử lý trước đây là Tối ưu hóa phiên bản cho Khối lượng công việc Ad Hoc. Việc làm này chỉ có thể hữu ích nếu hầu hết các cơ sở dữ liệu hoặc cơ sở dữ liệu quan trọng nhất trên phiên bản này chủ yếu thực thi Ad Hoc SQL.
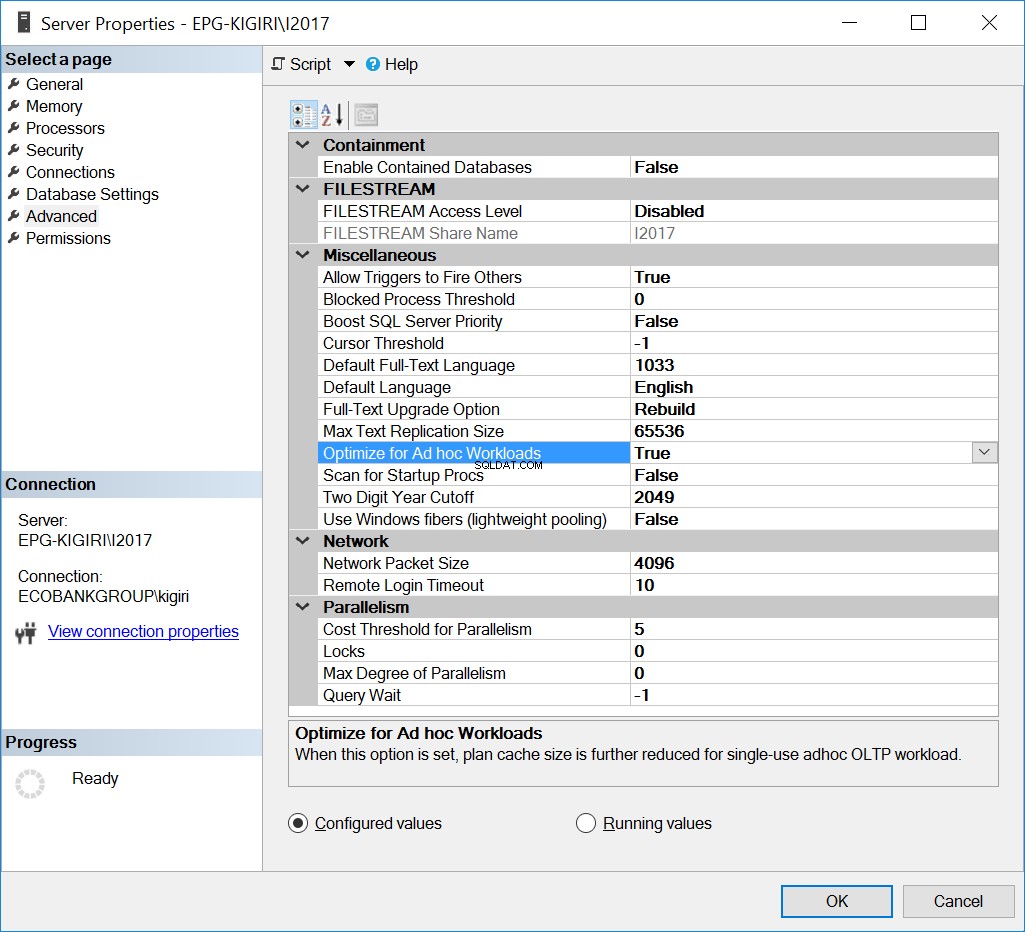
Hình. 1 Tối ưu hóa cho khối lượng công việc của Ad Hoc
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
Về cơ bản, tùy chọn này yêu cầu SQL Server lưu phiên bản một phần của kế hoạch được gọi là sơ khai kế hoạch đã biên dịch. Phần sơ khai chiếm ít không gian hơn nhiều so với toàn bộ kế hoạch.
Để thay thế cho phương pháp này, một số người tiếp cận vấn đề khá thô bạo và thỉnh thoảng xóa bộ nhớ cache của kế hoạch. Hoặc, một cách cẩn thận hơn, xóa các “gói sử dụng một lần” bằng cách sử dụng DBCC FREESYSTEMCACHE. Xóa toàn bộ bộ nhớ cache của gói có những mặt trái của nó, như bạn có thể đã biết.
Sử dụng các thủ tục và thông số đã lưu trữ
Bằng cách sử dụng các thủ tục được lưu trữ, người ta hầu như có thể loại bỏ sự cố do Ad Hoc SQL gây ra. Một thủ tục được lưu trữ chỉ được biên dịch một lần và cùng một kế hoạch được sử dụng lại cho các lần thực thi tiếp theo của các truy vấn SQL giống nhau hoặc tương tự. Khi các thủ tục được lưu trữ được sử dụng để triển khai logic nghiệp vụ, sự khác biệt chính trong các truy vấn SQL sẽ được SQL Server thực thi cuối cùng nằm ở các tham số được truyền vào thời điểm thực thi. Vì kế hoạch đã có sẵn và sẵn sàng để sử dụng, SQL Server sẽ sử dụng cùng một kế hoạch bất kể tham số nào được truyền đi.
Dữ liệu bị sai lệch
Trong một số trường hợp nhất định, dữ liệu chúng tôi đang xử lý không được phân phối đồng đều. Chúng tôi có thể chứng minh điều này - trước tiên, chúng tôi sẽ cần tạo một bảng:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Bảng của chúng tôi chứa dữ liệu về các thành viên câu lạc bộ từ các quốc gia khác nhau. Một số lượng lớn thành viên câu lạc bộ đến từ Ghana, trong khi hai quốc gia khác lần lượt có 10 và 2 thành viên. Để tiếp tục tập trung vào chương trình và vì lợi ích đơn giản, tôi chỉ sử dụng ba quốc gia và tên giống nhau cho các thành viên đến từ cùng một quốc gia. Ngoài ra, tôi đã thêm chỉ mục theo nhóm trong cột ID và chỉ mục không theo nhóm trong cột Mã quốc gia để chứng minh tác dụng của các kế hoạch thực thi khác nhau đối với các giá trị khác nhau.
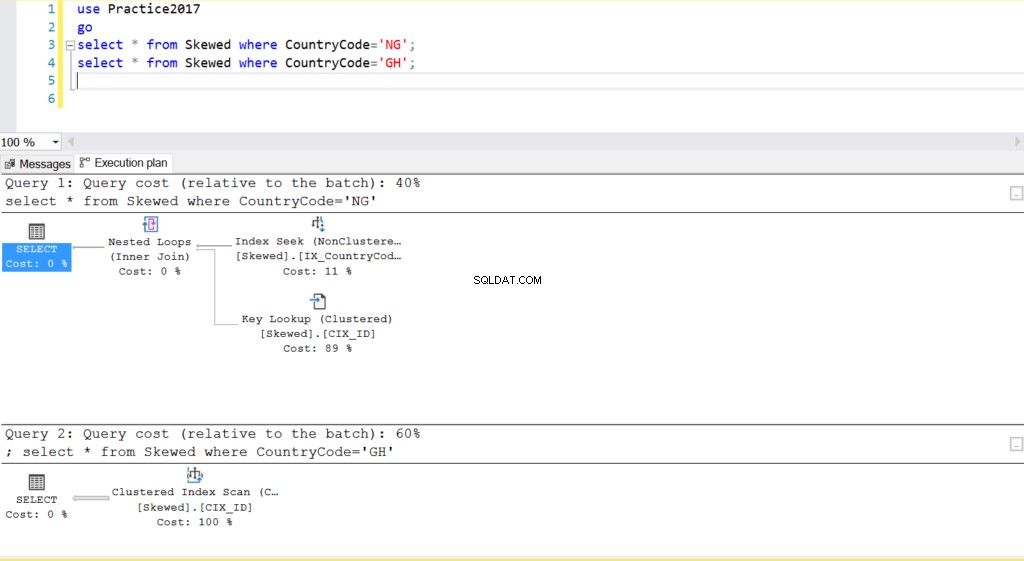
Hình. 2 Kế hoạch thực thi cho hai truy vấn
Khi chúng tôi truy vấn bảng cho các bản ghi có Mã quốc gia là NG và GH, chúng tôi thấy rằng SQL Server sử dụng hai kế hoạch thực thi khác nhau trong những trường hợp này. Điều này xảy ra vì số hàng dự kiến cho CountryCode =’NG’ là 10, trong khi cho CountryCode =’GH’ là 10000. SQL Server xác định kế hoạch thực thi thích hợp dựa trên thống kê bảng. Nếu số lượng hàng dự kiến cao so với tổng số hàng trong bảng, thì SQL Server quyết định rằng tốt hơn hết bạn nên thực hiện quét toàn bộ bảng hơn là tham chiếu đến một chỉ mục. Với số lượng hàng ước tính nhỏ hơn nhiều, chỉ mục trở nên hữu ích.
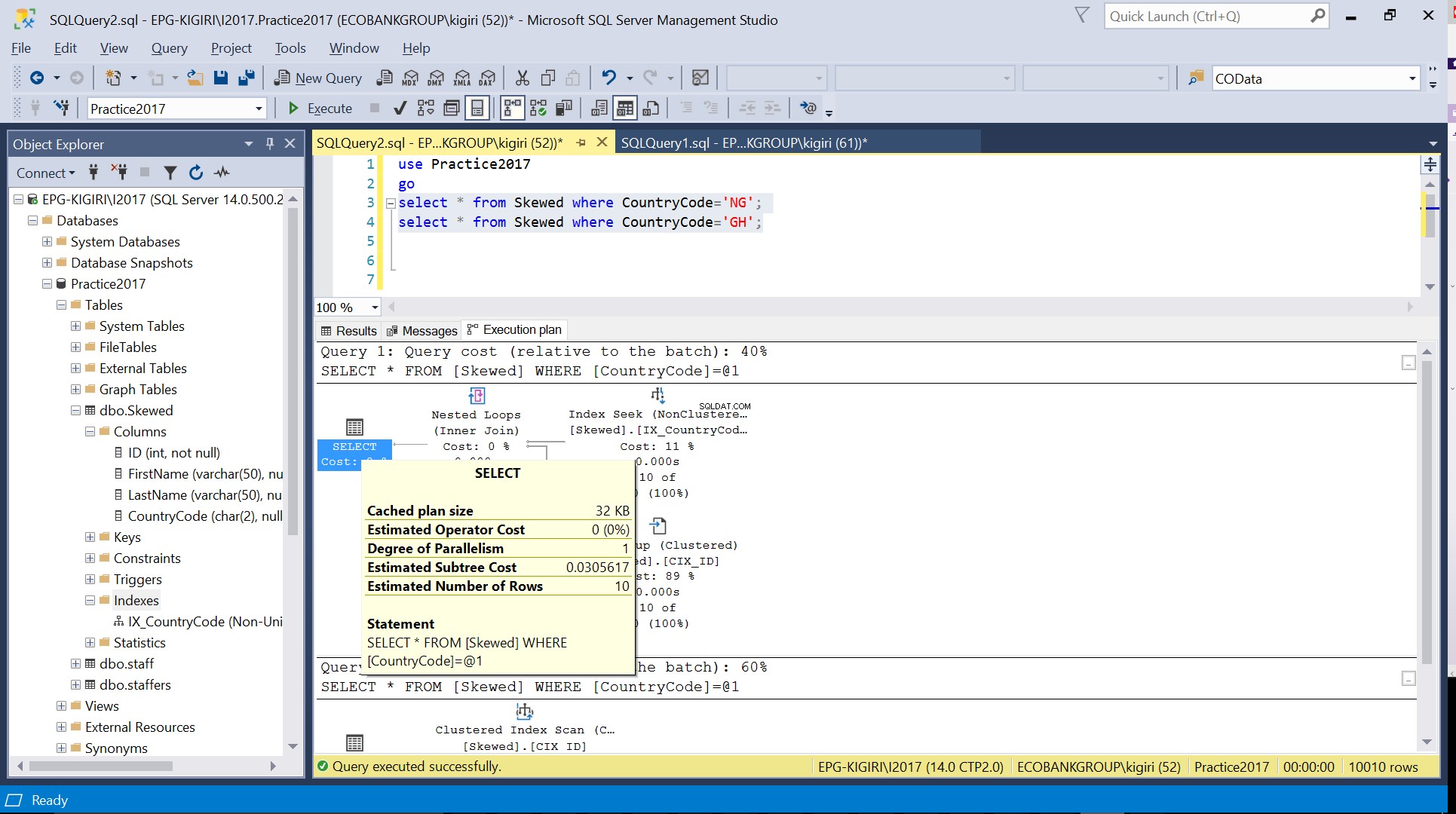
Hình. 3 Số hàng ước tính cho CountryCode =’NG’
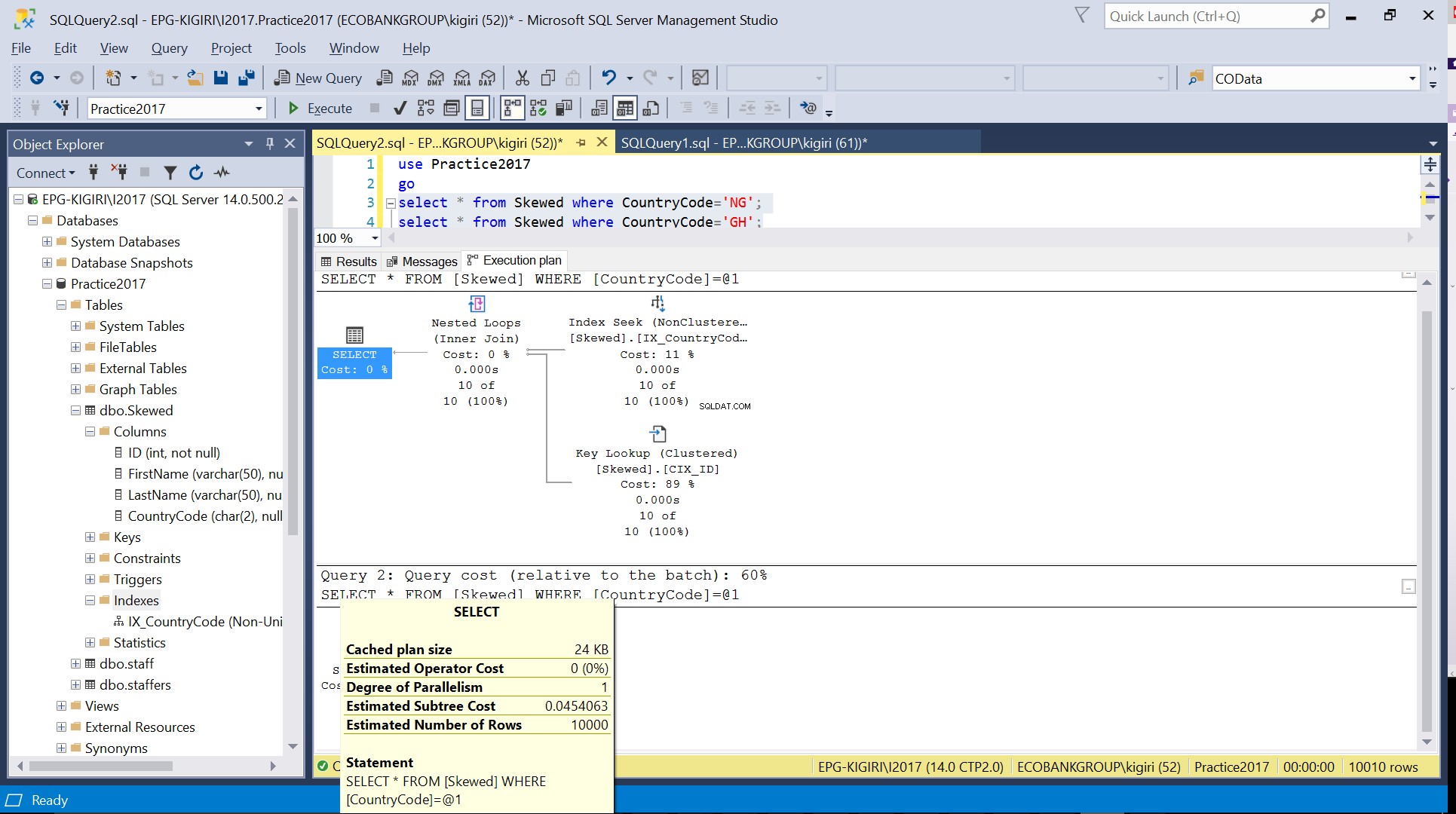
Hình. 4 Số lượng hàng ước tính cho Mã quốc gia =’GH’
Nhập Quy trình đã Lưu trữ
Chúng ta có thể tạo một thủ tục được lưu trữ để tìm nạp các bản ghi mà chúng ta muốn bằng cách sử dụng cùng một truy vấn. Sự khác biệt duy nhất lần này là chúng tôi truyền Mã quốc gia làm tham số (xem Liệt kê 3). Khi làm điều này, chúng tôi phát hiện ra rằng kế hoạch thực thi là giống nhau cho dù chúng tôi truyền tham số nào. Kế hoạch thực thi sẽ được sử dụng được xác định bởi kế hoạch thực thi được trả về ở lần đầu tiên thủ tục được lưu trữ được gọi. Ví dụ:Nếu chúng tôi chạy quy trình với CountryCode =’GH’ trước, nó sẽ sử dụng tính năng quét toàn bộ bảng kể từ thời điểm đó. Nếu sau đó chúng tôi xóa bộ nhớ cache của thủ tục và chạy quy trình với CountryCode =’NG’ trước, nó sẽ sử dụng tính năng quét dựa trên chỉ mục trong tương lai.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
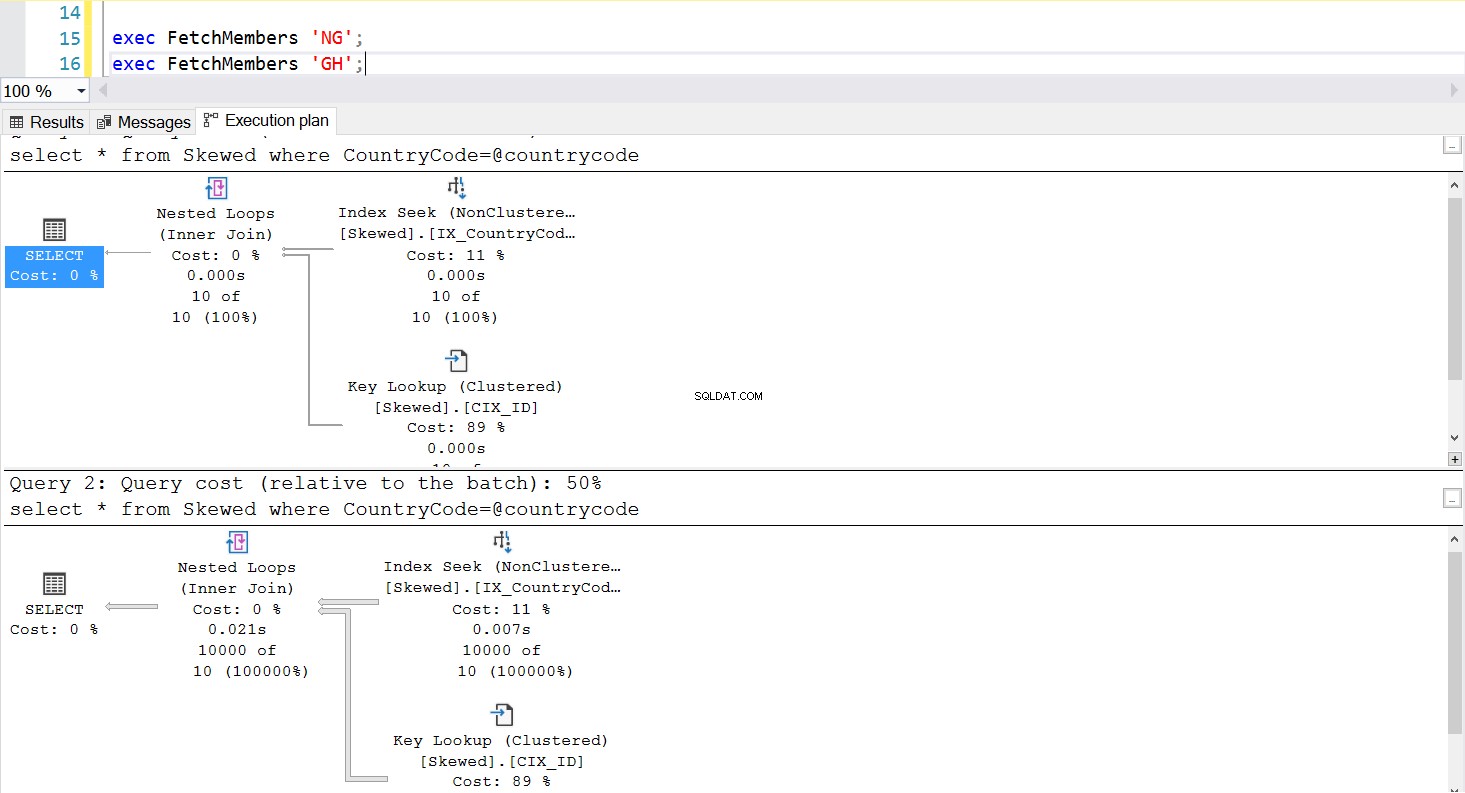
Hình. 5 Kế hoạch thực thi tìm kiếm chỉ mục khi ‘NG’ được sử dụng đầu tiên
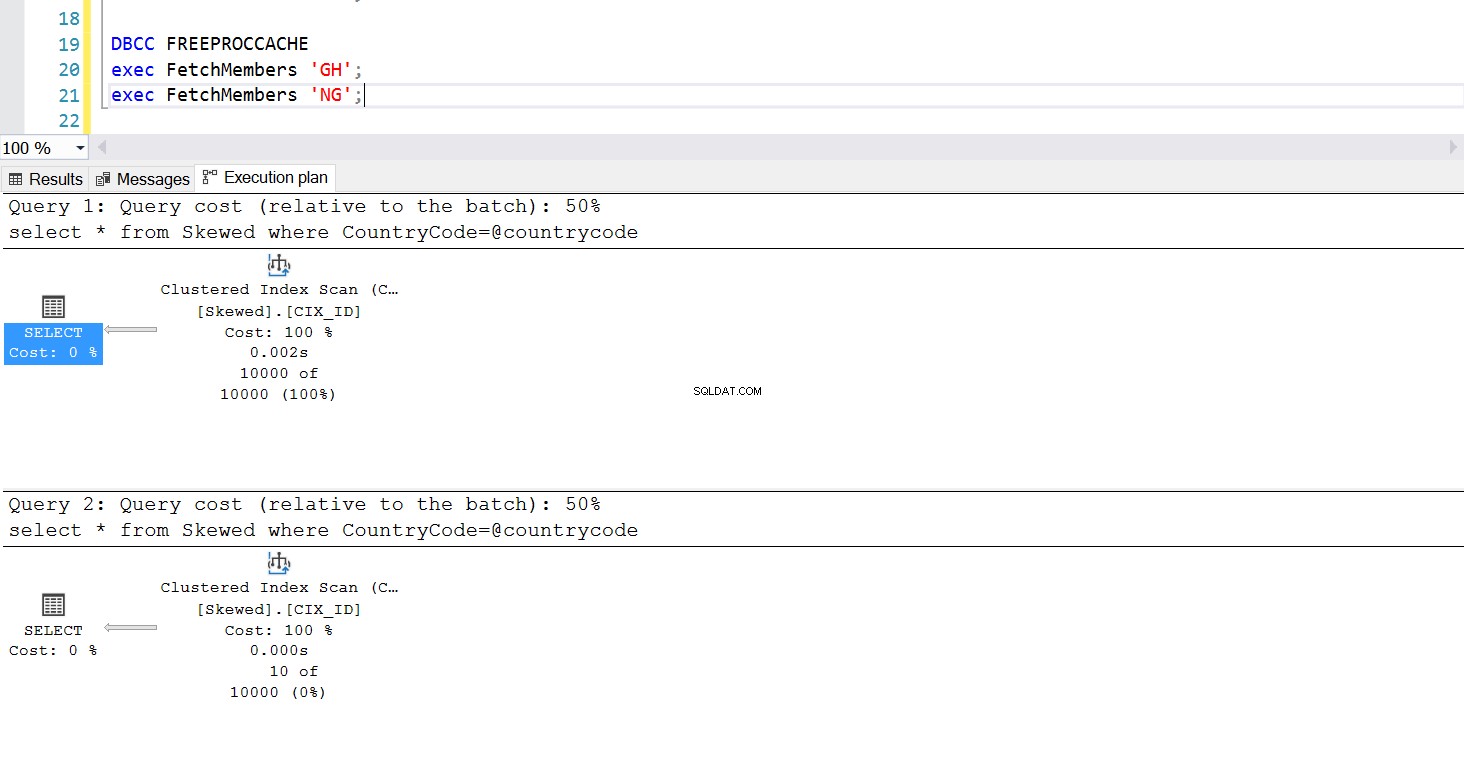
Hình. 6 Kế hoạch thực thi quét chỉ mục theo cụm khi ‘GH’ được sử dụng đầu tiên
Việc thực thi thủ tục được lưu trữ đang hoạt động như được thiết kế - kế hoạch thực thi bắt buộc được sử dụng nhất quán. Tuy nhiên, đây có thể là một vấn đề vì một kế hoạch thực thi không phù hợp cho tất cả các truy vấn nếu dữ liệu bị lệch. Sử dụng một chỉ mục để truy xuất một tập hợp các hàng gần như lớn bằng toàn bộ bảng là không hiệu quả - cũng không sử dụng quét toàn bộ để chỉ lấy một số lượng nhỏ các hàng. Đây là vấn đề Đánh hơi tham số.
Giải pháp Khả thi
Một cách phổ biến để quản lý vấn đề Đánh hơi tham số là cố tình gọi biên dịch lại bất cứ khi nào thủ tục được lưu trữ được thực thi. Điều này tốt hơn nhiều so với việc xóa Bộ đệm kế hoạch - ngoại trừ việc bạn muốn xóa bộ nhớ cache của truy vấn SQL cụ thể này, điều này hoàn toàn có thể thực hiện được. Hãy xem phiên bản cập nhật của quy trình được lưu trữ. Lần này, nó sử dụng TÙY CHỌN (RECOMPILE) để quản lý vấn đề. Hình 6 cho chúng ta thấy rằng, bất cứ khi nào thủ tục được lưu trữ mới được thực thi, nó sẽ sử dụng một kế hoạch phù hợp với tham số mà chúng ta đang truyền.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
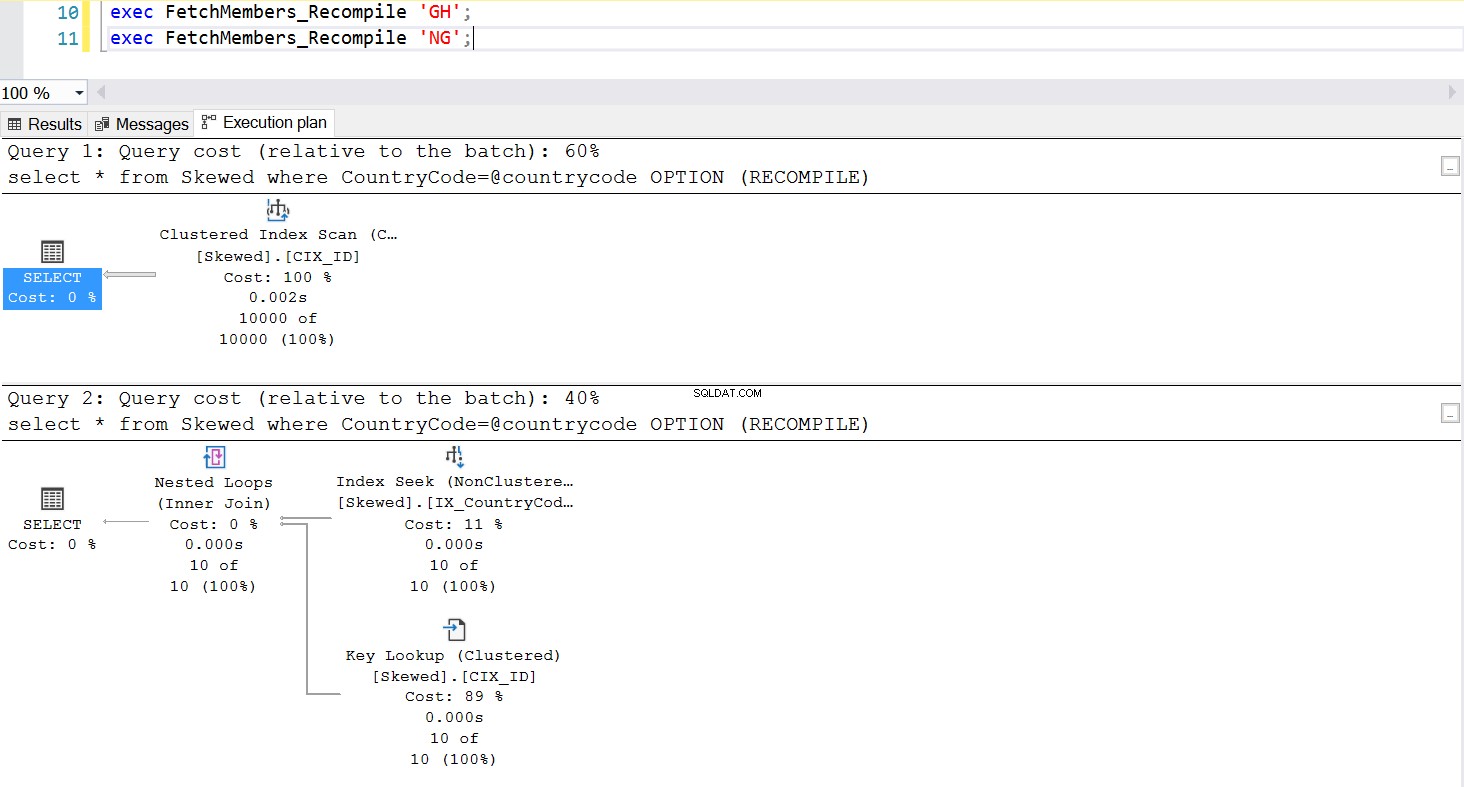
Hình. 7 Hành vi của thủ tục được lưu trữ với TÙY CHỌN (RECOMPILE)
Kết luận
Trong bài viết này, chúng ta đã xem xét các kế hoạch thực thi nhất quán cho các thủ tục được lưu trữ có thể trở thành vấn đề như thế nào khi dữ liệu chúng ta đang xử lý bị lệch. Chúng tôi cũng đã chứng minh điều này trong thực tế và tìm hiểu về một giải pháp chung cho vấn đề. Tôi dám khẳng định kiến thức này là vô giá đối với các nhà phát triển sử dụng SQL Server. Có một số giải pháp khác cho vấn đề này - Brent Ozar đã đi sâu hơn vào chủ đề và nêu bật một số chi tiết và giải pháp sâu sắc hơn tại SQLDay Ba Lan 2017. Tôi đã liệt kê liên kết tương ứng trong phần tham khảo.
Tài liệu tham khảo
Lập kế hoạch Cache và Tối ưu hóa cho Khối lượng Công việc Adhoc
Xác định và Khắc phục Sự cố Đánh hơi Tham số