Bạn có thể biết cách chèn các bản ghi vào một bảng bằng cách sử dụng một hoặc nhiều mệnh đề GIÁ TRỊ. Bạn cũng biết cách thực hiện chèn hàng loạt bằng cách sử dụng SQL INSERT INTO SELECT. Nhưng bạn vẫn nhấp vào bài viết. Có phải là về việc xử lý các bản sao không?
Nhiều bài viết đề cập đến SQL INSERT INTO SELECT. Google hoặc Bing nó và chọn dòng tiêu đề bạn thích nhất - nó sẽ làm được. Tôi cũng sẽ không đề cập đến các ví dụ cơ bản về cách nó được thực hiện. Thay vào đó, bạn sẽ thấy ví dụ về cách sử dụng nó VÀ xử lý các bản sao cùng một lúc . Vì vậy, bạn có thể tạo ra thông báo quen thuộc này nhờ nỗ lực CHÈN của mình:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Nhưng điều đầu tiên trước tiên.

[sendpulse-form id =”12989 ″]
Chuẩn bị dữ liệu thử nghiệm cho SQL CHÈN VÀO CHỌN Mẫu mã
Tôi đang nghĩ về mì ống lần này. Vì vậy, tôi sẽ sử dụng dữ liệu về các món mì ống. Tôi đã tìm thấy một danh sách tốt về các món mì ống trên Wikipedia mà chúng tôi có thể sử dụng và trích xuất trong Power BI bằng nguồn dữ liệu web. Tôi đã nhập URL Wikipedia. Sau đó, tôi chỉ định dữ liệu 2 bảng từ trang. Đã xóa nó một chút và sao chép dữ liệu sang Excel.
Bây giờ chúng tôi có dữ liệu - bạn có thể tải xuống từ đây. Nó là thô vì chúng tôi sẽ tạo ra 2 bảng quan hệ từ nó. Sử dụng CHÈN VÀO CHỌN sẽ giúp chúng tôi thực hiện công việc này,
Nhập dữ liệu trong SQL Server
Bạn có thể sử dụng SQL Server Management Studio hoặc dbForge Studio cho SQL Server để nhập 2 trang tính vào tệp Excel.
Tạo cơ sở dữ liệu trống trước khi nhập dữ liệu. Tôi đã đặt tên cho các bảng là dbo.ItalianPastaDished và dbo.NonItalianPastaDished .
Tạo thêm 2 bảng
Hãy xác định hai bảng đầu ra bằng lệnh SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Lưu ý:Có các chỉ mục duy nhất được tạo trên hai bảng. Nó sẽ ngăn chúng tôi chèn các bản ghi trùng lặp sau này. Những hạn chế sẽ khiến cuộc hành trình này khó khăn hơn một chút nhưng thú vị.
Bây giờ chúng ta đã sẵn sàng, hãy đi sâu vào.
5 cách dễ dàng để xử lý các bản sao bằng cách sử dụng SQL INSERT INTO SELECT
Cách dễ nhất để xử lý các bản sao là loại bỏ các ràng buộc duy nhất, phải không?
Sai!
Khi không còn các ràng buộc duy nhất, bạn rất dễ mắc lỗi và chèn dữ liệu hai lần trở lên. Chúng tôi không muốn điều đó. Và điều gì sẽ xảy ra nếu chúng ta có giao diện người dùng với danh sách thả xuống để chọn nguồn gốc của món mì ống? Các bản sao có làm cho người dùng của bạn hài lòng không?
Do đó, loại bỏ các ràng buộc duy nhất không phải là một trong năm cách để xử lý hoặc xóa các bản ghi trùng lặp trong SQL. Chúng tôi có những lựa chọn tốt hơn.
1. Sử dụng CHÈN VÀO CHỌN DISTINCT
Tùy chọn đầu tiên cho cách xác định bản ghi SQL trong SQL là sử dụng DISTINCT trong phần CHỌN của bạn. Để khám phá trường hợp này, chúng tôi sẽ điền Nguồn gốc bàn. Nhưng trước tiên, hãy sử dụng sai phương pháp:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
Điều này sẽ gây ra các lỗi trùng lặp sau:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Đã xảy ra sự cố khi bạn cố gắng chọn các hàng trùng lặp trong SQL. Để bắt đầu kiểm tra SQL cho các bản sao đã tồn tại trước đó, tôi đã chạy phần CHỌN của câu lệnh CHÈN VÀO CHỌN:
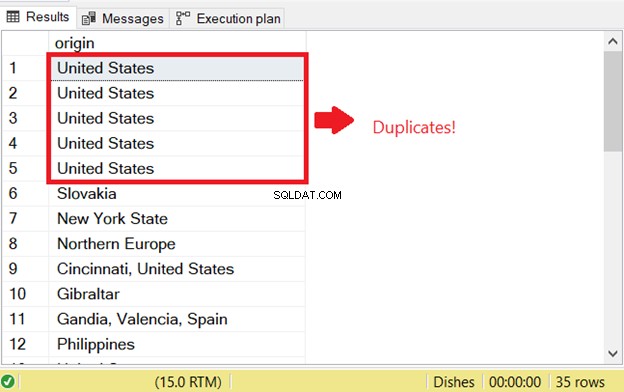
Đó là lý do gây ra lỗi trùng lặp SQL đầu tiên. Để ngăn chặn điều này, hãy thêm từ khóa DISTINCT để làm cho tập kết quả là duy nhất. Đây là mã chính xác:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Nó chèn các bản ghi thành công. Và chúng tôi đã hoàn tất với Nguồn gốc bảng.
Sử dụng DISTINCT sẽ tạo các bản ghi duy nhất từ câu lệnh SELECT. Tuy nhiên, nó không đảm bảo rằng các bản sao không tồn tại trong bảng mục tiêu. Sẽ tốt khi bạn chắc chắn rằng bảng mục tiêu không có các giá trị bạn muốn chèn.
Vì vậy, không chạy các câu lệnh này nhiều lần.
2. Sử dụng WHERE NOT IN
Tiếp theo, chúng tôi điền PastaDished bàn. Để làm được điều đó, trước tiên chúng tôi cần chèn các bản ghi từ ItalianPastaDished bàn. Đây là mã:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Kể từ ItalianPastaDished chứa dữ liệu thô, chúng tôi cần tham gia Nguồn gốc văn bản thay vì OriginID . Bây giờ, hãy thử chạy cùng một đoạn mã hai lần. Lần thứ hai nó chạy sẽ không có bản ghi được chèn vào. Nó xảy ra do mệnh đề WHERE với toán tử NOT IN. Nó lọc ra các bản ghi đã tồn tại trong bảng đích.
Tiếp theo, chúng ta cần điền PastaDished bảng từ NonItalianPastaDished bàn. Vì chúng tôi chỉ ở điểm thứ hai của bài đăng này, chúng tôi sẽ không chèn mọi thứ.
Chúng tôi đã chọn các món mì ống từ Hoa Kỳ và Philippines. Đây là:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Có 9 bản ghi được chèn từ câu lệnh này - xem Hình 2 bên dưới:
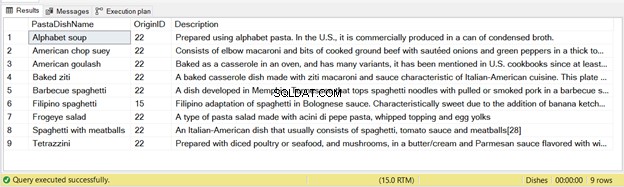
Một lần nữa, nếu bạn chạy mã trên hai lần, thì lần chạy thứ hai sẽ không chèn các bản ghi.
3. Sử dụng WHERE KHÔNG TỒN TẠI
Một cách khác để tìm các bản sao trong SQL là sử dụng NOT EXISTS trong mệnh đề WHERE. Hãy thử nó với các điều kiện tương tự từ phần trước:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
Đoạn mã trên sẽ chèn 9 bản ghi giống như bạn đã thấy trong Hình 2. Nó sẽ tránh việc chèn các bản ghi giống nhau nhiều lần.
4. Sử dụng NẾU KHÔNG TỒN TẠI
Đôi khi bạn có thể cần triển khai một bảng vào cơ sở dữ liệu và cần phải kiểm tra xem bảng có cùng tên đã tồn tại hay chưa để tránh trùng lặp. Trong trường hợp này, lệnh SQL DROP TABLE IF EXISTS có thể giúp ích rất nhiều. Một cách khác để đảm bảo bạn sẽ không chèn các bản sao là sử dụng NẾU KHÔNG TỒN TẠI. Một lần nữa, chúng tôi sẽ sử dụng các điều kiện tương tự từ phần trước:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Đoạn mã trên trước tiên sẽ kiểm tra sự tồn tại của 9 bản ghi. Nếu nó trả về true, INSERT sẽ tiếp tục.
5. Sử dụng COUNT (*) =0
Cuối cùng, việc sử dụng COUNT (*) trong mệnh đề WHERE cũng có thể đảm bảo bạn sẽ không chèn các bản sao. Đây là một ví dụ:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Để tránh trùng lặp, COUNT hoặc bản ghi được trả về bởi truy vấn con ở trên phải bằng không.
Lưu ý :Bạn có thể thiết kế bất kỳ truy vấn nào một cách trực quan trong một sơ đồ bằng cách sử dụng tính năng Trình tạo Truy vấn của dbForge Studio cho SQL Server.
So sánh các cách khác nhau để xử lý các bản sao bằng SQL INSERT INTO SELECT
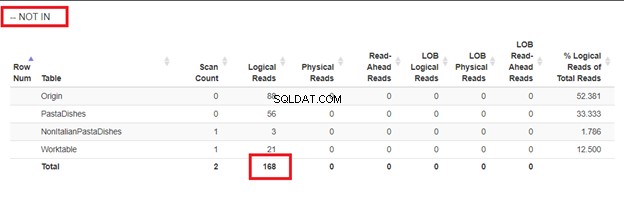
4 phần đã sử dụng cùng một đầu ra nhưng các cách tiếp cận khác nhau để chèn các bản ghi số lượng lớn với một câu lệnh SELECT. Bạn có thể tự hỏi nếu sự khác biệt chỉ là trên bề mặt. Chúng ta có thể kiểm tra các lần đọc logic của chúng từ STATISTICS IO để xem chúng khác nhau như thế nào.
Sử dụng WHERE NOT IN:
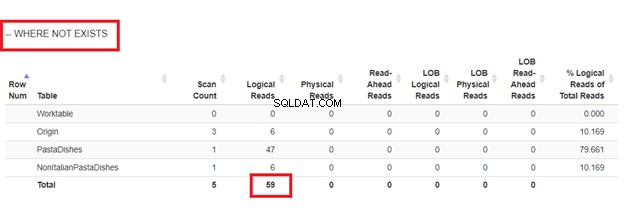
Sử dụng KHÔNG TỒN TẠI:
Sử dụng NẾU KHÔNG TỒN TẠI:
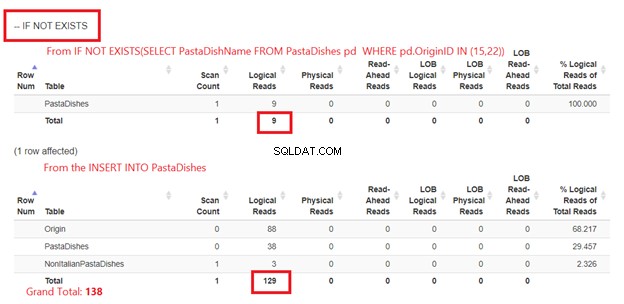
Hình 5 có một chút khác biệt. 2 lần đọc lôgic xuất hiện cho PastaDished bàn. Đầu tiên là từ NẾU KHÔNG TỒN TẠI (CHỌN PastaDishName từ PastaDished WHERE OriginID VÀO (15,22)). Câu thứ hai là từ câu lệnh INSERT.
Cuối cùng, sử dụng COUNT (*) =0
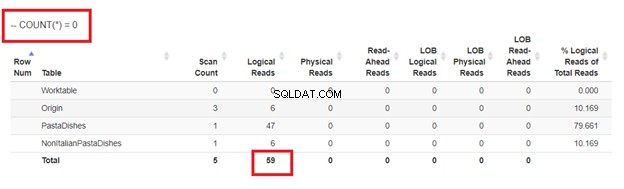
Từ các lần đọc logic của 4 cách tiếp cận mà chúng tôi đã có, lựa chọn tốt nhất là KHÔNG TỒN TẠI ĐÂU hoặc ĐẾM (*) =0. Khi chúng tôi kiểm tra các kế hoạch Thực thi của họ, chúng tôi thấy chúng có cùng một QueryHashPlan . Vì vậy, họ có kế hoạch tương tự. Trong khi đó, cách kém hiệu quả nhất đang sử dụng NOT IN.
Nó có nghĩa là WHERE KHÔNG TỒN TẠI luôn tốt hơn KHÔNG VÀO? Không hề.
Luôn kiểm tra các lần đọc logic và Kế hoạch Thực thi của các truy vấn của bạn!
Nhưng trước khi kết thúc, chúng ta cần hoàn thành nhiệm vụ trong tầm tay. Sau đó, chúng tôi sẽ chèn phần còn lại của hồ sơ và kiểm tra kết quả.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Lướt qua danh sách 179 món mì từ Á sang Âu khiến tôi thèm thuồng. Xem một phần danh sách từ Ý, Nga, v.v. từ bên dưới:

Kết luận
Rốt cuộc, việc tránh các bản sao trong SQL INSERT INTO SELECT không quá khó. Bạn có sẵn các toán tử và chức năng để đưa bạn đến cấp độ đó. Đây cũng là một thói quen tốt để kiểm tra Kế hoạch thực thi và các lần đọc logic để so sánh cái nào tốt hơn.
Nếu bạn nghĩ ai đó sẽ được lợi từ bài đăng này, hãy chia sẻ nó trên các nền tảng mạng xã hội yêu thích của bạn. Và nếu bạn có điều gì cần bổ sung mà chúng tôi quên, hãy cho chúng tôi biết trong phần Nhận xét bên dưới.