Là SQL Server DBA, chúng tôi đã nghe nói rằng cấu trúc chỉ mục có thể cải thiện đáng kể hiệu suất của bất kỳ truy vấn nhất định nào (hoặc tập hợp các truy vấn). Tuy nhiên, có một số chi tiết nhất định mà nhiều DBA bỏ qua, như sau:
- Cấu trúc chỉ mục có thể trở nên phân mảnh, có khả năng dẫn đến các vấn đề về giảm hiệu suất.
- Sau khi cấu trúc chỉ mục đã được triển khai cho một bảng cơ sở dữ liệu, SQL Server sẽ cập nhật cấu trúc đó bất cứ khi nào các hoạt động ghi diễn ra cho bảng đó. Điều này xảy ra nếu các cột tuân theo chỉ mục bị ảnh hưởng.
- Có siêu dữ liệu bên trong SQL Server có thể được sử dụng để biết khi nào thống kê cho một cấu trúc chỉ mục cụ thể được cập nhật (nếu có) lần cuối cùng. Số liệu thống kê không đầy đủ hoặc lỗi thời có thể ảnh hưởng đến hiệu suất của một số truy vấn nhất định.
- Có siêu dữ liệu bên trong SQL Server có thể được sử dụng để biết cấu trúc chỉ mục đã được sử dụng bao nhiêu bởi các hoạt động đọc hoặc được cập nhật bởi các hoạt động ghi bởi chính SQL Server. Thông tin này có thể hữu ích để biết liệu có chỉ mục nào có lượng ghi vượt quá lượng đọc. Nó có thể là một cấu trúc chỉ mục không hữu ích để duy trì. *
* Điều rất quan trọng cần lưu ý là chế độ xem hệ thống chứa siêu dữ liệu cụ thể này sẽ bị xóa mỗi khi phiên bản SQL Server được khởi động lại, vì vậy, đó sẽ không phải là thông tin từ quan niệm của nó.
Do tầm quan trọng của những chi tiết này, tôi đã tạo Quy trình lưu trữ để theo dõi thông tin liên quan đến cấu trúc chỉ mục trong môi trường của anh ấy / cô ấy, để hành động một cách chủ động nhất có thể.
Cân nhắc ban đầu
- Đảm bảo rằng tài khoản thực hiện Quy trình đã lưu trữ này có đủ đặc quyền. Bạn có thể bắt đầu với những sysadmin và sau đó đi càng chi tiết càng tốt để đảm bảo rằng người dùng có tối thiểu các đặc quyền cần thiết để SP hoạt động bình thường.
- Các đối tượng cơ sở dữ liệu (bảng cơ sở dữ liệu và thủ tục được lưu trữ) sẽ được tạo bên trong cơ sở dữ liệu được chọn tại thời điểm tập lệnh được thực thi, vì vậy hãy chọn cẩn thận.
- Tập lệnh được tạo theo cách có thể được thực thi nhiều lần mà không gặp lỗi. Đối với Quy trình đã lưu trữ, tôi đã sử dụng câu lệnh CREATE OR ALTER PROCEDURE, có sẵn kể từ SQL Server 2016 SP1.
- Vui lòng thay đổi tên của các đối tượng cơ sở dữ liệu đã tạo nếu bạn muốn sử dụng quy ước đặt tên khác.
- Khi bạn chọn giữ nguyên dữ liệu do Thủ tục đã lưu trữ trả về, bảng đích sẽ bị cắt bớt đầu tiên để chỉ tập kết quả gần đây nhất mới được lưu trữ. Bạn có thể thực hiện những điều chỉnh cần thiết nếu muốn điều này diễn ra khác đi, vì bất kỳ lý do gì (có lẽ để lưu giữ thông tin lịch sử?).
Cách sử dụng quy trình đã lưu trữ?
- Sao chép và dán Mã T-SQL (có sẵn trong bài viết này).
- SP mong đợi 2 tham số:
- @ persData:‘Y’ nếu DBA muốn lưu kết quả đầu ra trong bảng đích và ‘N’ nếu DBA chỉ muốn xem trực tiếp kết quả đầu ra.
- @db:'all' để lấy thông tin cho tất cả cơ sở dữ liệu (hệ thống &người dùng), 'user' để nhắm mục tiêu cơ sở dữ liệu người dùng, 'system' để chỉ nhắm mục tiêu cơ sở dữ liệu hệ thống (không bao gồm tempdb) và cuối cùng là tên thực của một cơ sở dữ liệu cụ thể.
Các trường được trình bày và ý nghĩa của chúng
- dbName: tên của cơ sở dữ liệu nơi cư trú của đối tượng chỉ mục.
- schemaName: tên của lược đồ nơi cư trú của đối tượng chỉ mục.
- tableName: tên của bảng có đối tượng chỉ mục.
- indexName: tên của cấu trúc chỉ mục.
- loại: loại chỉ mục (ví dụ:Nhóm, Không nhóm).
- phân bổ_unit_type: chỉ định loại dữ liệu đề cập đến (ví dụ:dữ liệu trong hàng, dữ liệu lob).
- phân mảnh: lượng phân mảnh (tính bằng%) mà cấu trúc chỉ mục hiện có.
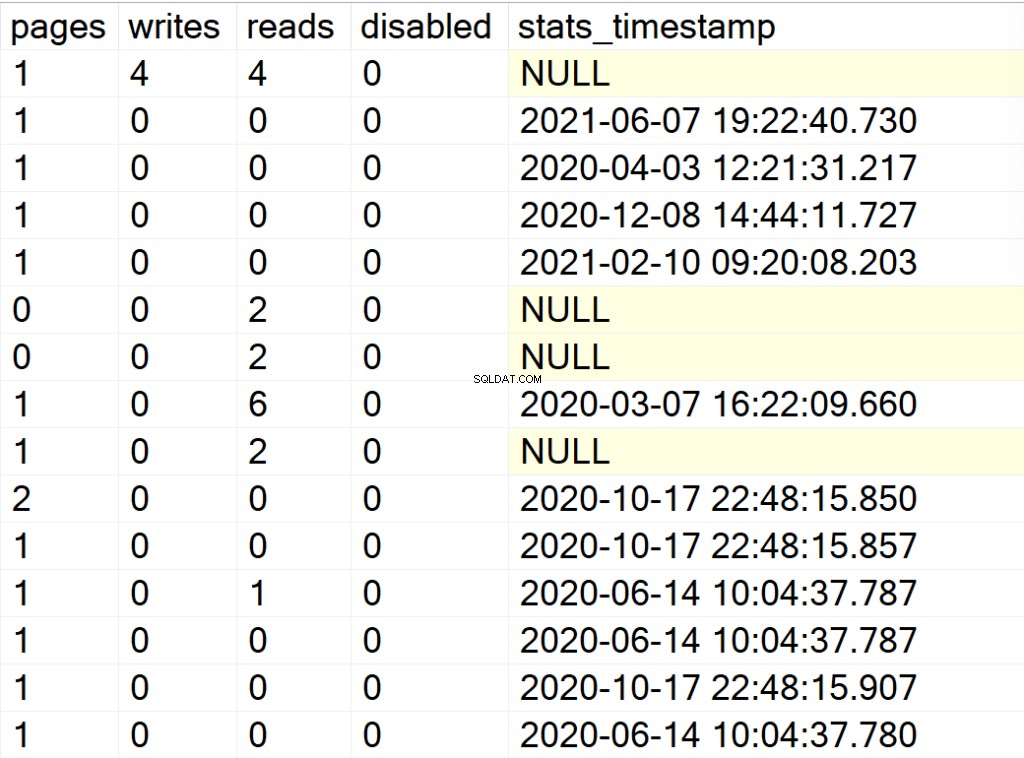
- trang: số lượng trang 8KB tạo thành cấu trúc chỉ mục.
- viết: số lần ghi mà cấu trúc chỉ mục đã trải qua kể từ khi phiên bản SQL Server được khởi động lại lần cuối.
- đọc: số lần đọc mà cấu trúc chỉ mục đã trải qua kể từ khi phiên bản SQL Server được khởi động lại lần cuối.
- bị vô hiệu hóa: 1 nếu cấu trúc chỉ mục hiện đang bị vô hiệu hóa hoặc 0 nếu cấu trúc được bật.
- stats_timestamp: giá trị dấu thời gian về thời điểm các thống kê cho cấu trúc chỉ mục cụ thể được cập nhật lần cuối (NULL nếu chưa bao giờ).
- data_collection_timestamp: chỉ hiển thị nếu ‘Y’ được truyền cho tham số @persistData và nó được sử dụng để biết khi nào SP được thực thi và thông tin đã được lưu thành công trong bảng DBA_Indexes.
Kiểm tra thực thi
Tôi sẽ trình bày một số cách thực thi của Thủ tục được lưu trữ để bạn có thể biết được những gì sẽ xảy ra từ nó:
* Bạn có thể tìm thấy mã T-SQL hoàn chỉnh của tập lệnh ở phần cuối của bài viết này, vì vậy hãy đảm bảo thực thi nó trước khi chuyển sang phần sau.
* Tập hợp kết quả sẽ quá rộng để vừa với 1 ảnh chụp màn hình, vì vậy tôi sẽ chia sẻ tất cả các ảnh chụp màn hình cần thiết để trình bày thông tin đầy đủ.
/ * Hiển thị tất cả thông tin chỉ mục cho tất cả hệ thống và cơ sở dữ liệu người dùng * /
EXEC GetIndexData @persistData = 'N',@db = 'all'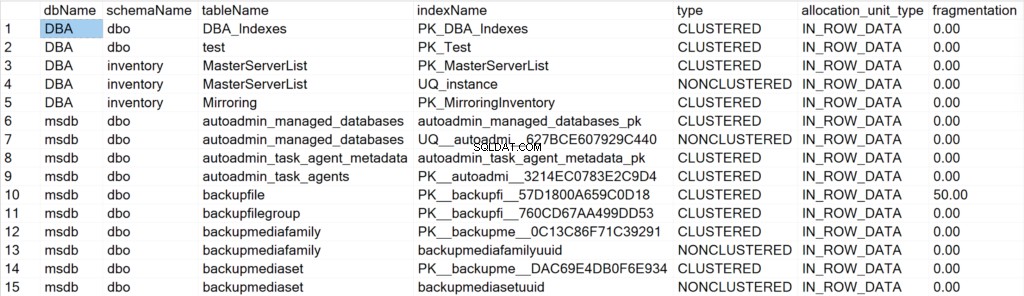
/ * Hiển thị tất cả thông tin chỉ mục cho tất cả cơ sở dữ liệu hệ thống * /
EXEC GetIndexData @persistData = 'N',@db = 'system'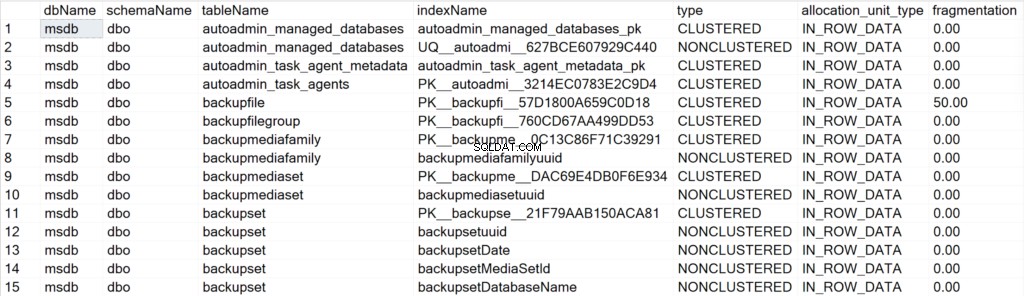
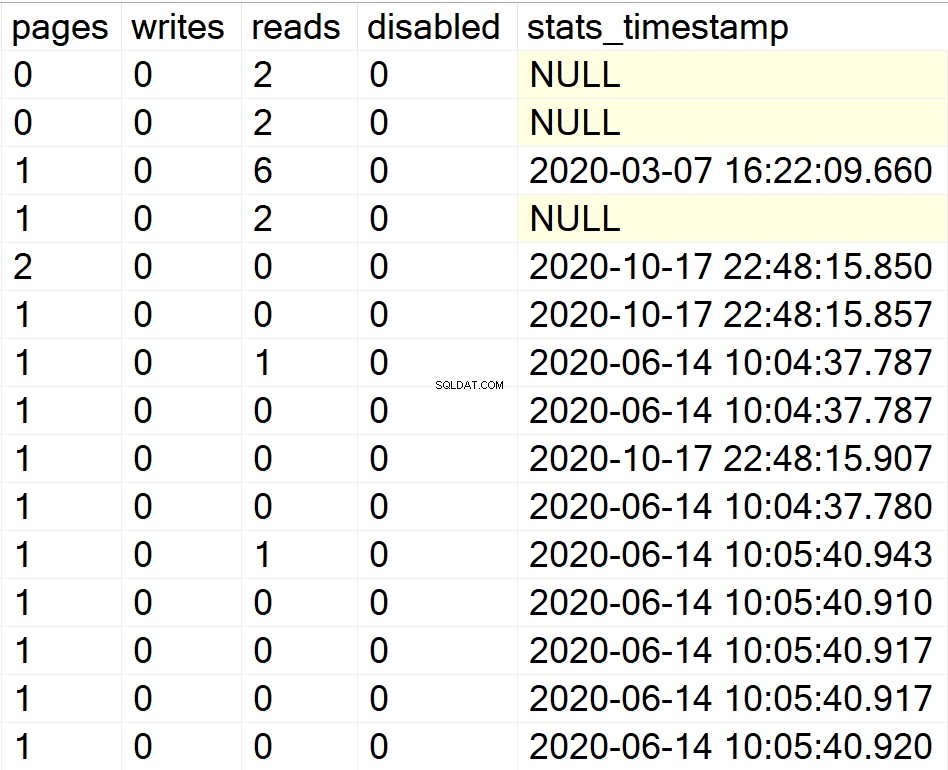
/ * Hiển thị tất cả thông tin chỉ mục cho tất cả cơ sở dữ liệu người dùng * /
EXEC GetIndexData @persistData = 'N',@db = 'user'
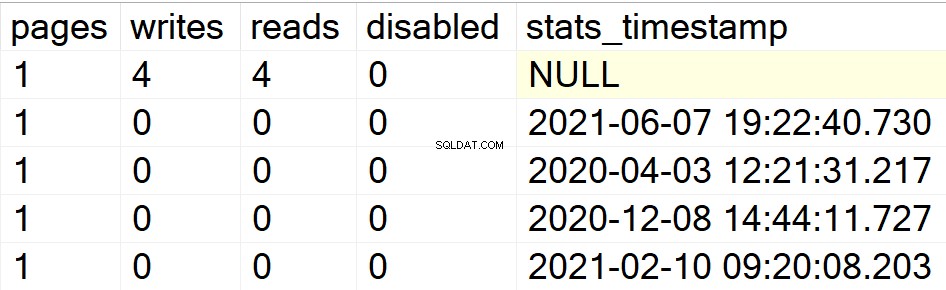
/ * Hiển thị tất cả thông tin chỉ mục cho cơ sở dữ liệu người dùng cụ thể * /
Trong các ví dụ trước của tôi, chỉ cơ sở dữ liệu DBA mới hiển thị là cơ sở dữ liệu người dùng duy nhất của tôi với các chỉ mục trong đó. Do đó, hãy để tôi tạo một cấu trúc chỉ mục trong một cơ sở dữ liệu khác mà tôi đã đặt xung quanh trong cùng một trường hợp để bạn có thể xem liệu SP có thực hiện đúng nhiệm vụ của nó hay không.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Tất cả các ví dụ được giới thiệu cho đến nay đều chứng minh kết quả đầu ra mà bạn nhận được khi không muốn duy trì dữ liệu, cho các kết hợp tùy chọn khác nhau cho thông số @db. Đầu ra trống khi bạn chỉ định một tùy chọn không hợp lệ hoặc cơ sở dữ liệu đích không tồn tại. Nhưng còn khi DBA muốn duy trì dữ liệu trong một bảng cơ sở dữ liệu thì sao? Hãy cùng tìm hiểu.
* Tôi sẽ chỉ chạy SP cho một trường hợp vì phần còn lại của các tùy chọn cho tham số @db đã được giới thiệu ở trên khá nhiều và kết quả là giống nhau nhưng vẫn tồn tại trong một bảng cơ sở dữ liệu.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
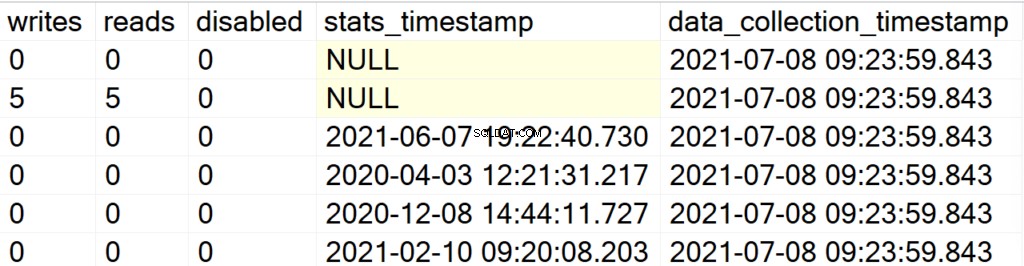
Bây giờ, sau khi bạn thực hiện Thủ tục đã lưu trữ, bạn sẽ không nhận được bất kỳ đầu ra nào. Để truy vấn tập kết quả, bạn phải đưa ra câu lệnh SELECT đối với bảng DBA_Indexes. Điểm hấp dẫn chính ở đây là bạn có thể truy vấn tập kết quả thu được, để xử lý hậu phân tích và việc bổ sung trường data_collection_timestamp sẽ cho bạn biết dữ liệu bạn đang xem gần đây / cũ như thế nào.
Truy vấn bên
Bây giờ, để mang lại nhiều giá trị hơn cho DBA, tôi đã chuẩn bị một số truy vấn có thể giúp bạn thu được thông tin hữu ích từ dữ liệu được lưu trong bảng.
* Truy vấn để tìm các chỉ mục rất phân mảnh về tổng thể.
* Chọn số% mà bạn cho là phù hợp.
* 1500 trang dựa trên một bài báo tôi đã đọc, dựa trên khuyến nghị của Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;* Truy vấn để tìm các chỉ mục bị vô hiệu hóa trong môi trường của bạn.
SELECT * FROM DBA_Indexes WHERE disabled = 1;* Truy vấn để tìm các chỉ mục (chủ yếu là không phân cụm) không được các truy vấn sử dụng nhiều, ít nhất là không phải kể từ lần cuối cùng phiên bản SQL Server được khởi động lại.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';* Truy vấn để tìm số liệu thống kê chưa bao giờ được cập nhật hoặc đã cũ.
* Bạn xác định những gì cũ trong môi trường của bạn, vì vậy hãy đảm bảo điều chỉnh số ngày cho phù hợp.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Đây là mã hoàn chỉnh của Quy trình đã lưu trữ:
* Ở phần đầu của tập lệnh, bạn sẽ thấy giá trị mặc định mà Thủ tục được lưu trữ giả định nếu không có giá trị nào được chuyển cho mỗi tham số.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOKết luận
- Bạn có thể triển khai SP này trong mọi phiên bản SQL Server dưới sự hỗ trợ của bạn và triển khai cơ chế cảnh báo trên toàn bộ ngăn xếp các phiên bản được hỗ trợ của bạn.
- Nếu bạn triển khai một công việc đại lý truy vấn thông tin này tương đối thường xuyên, bạn có thể luôn cập nhật trò chơi để quản lý các cấu trúc chỉ mục trong (các) môi trường được hỗ trợ của bạn.
- Đảm bảo kiểm tra cơ chế này đúng cách trong môi trường hộp cát và khi bạn đang lên kế hoạch triển khai sản xuất, hãy đảm bảo chọn khoảng thời gian hoạt động thấp.
Các vấn đề phân mảnh chỉ mục có thể phức tạp và căng thẳng. Để tìm và sửa chúng, bạn có thể sử dụng các công cụ khác nhau, chẳng hạn như Trình quản lý chỉ mục dbForge có thể tải xuống tại đây.