Giới thiệu
- Có một số quy tắc cụ thể cần được tuân theo khi tạo các đối tượng cơ sở dữ liệu. Để cải thiện hiệu suất của cơ sở dữ liệu, một khóa chính, các chỉ mục được phân cụm và không được phân cụm và các ràng buộc nên được gán cho một bảng. Mặc dù chúng tôi tuân theo tất cả các quy tắc này, các hàng trùng lặp vẫn có thể xảy ra trong bảng.
- Việc sử dụng các khóa cơ sở dữ liệu luôn là một phương pháp hay. Sử dụng các khóa cơ sở dữ liệu sẽ giảm khả năng nhận được các bản ghi trùng lặp trong một bảng. Nhưng nếu các bản ghi trùng lặp đã có trong một bảng, thì có những cách cụ thể được sử dụng để xóa các bản ghi trùng lặp này.
Các cách xóa các hàng trùng lặp
- Sử dụng DELETE JOIN tuyên bố để loại bỏ các hàng trùng lặp
Câu lệnh DELETE JOIN được cung cấp trong MySQL để giúp loại bỏ các hàng trùng lặp khỏi bảng.
Hãy xem xét một cơ sở dữ liệu có tên "studentdb". Chúng tôi sẽ tạo một sinh viên bảng vào đó.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
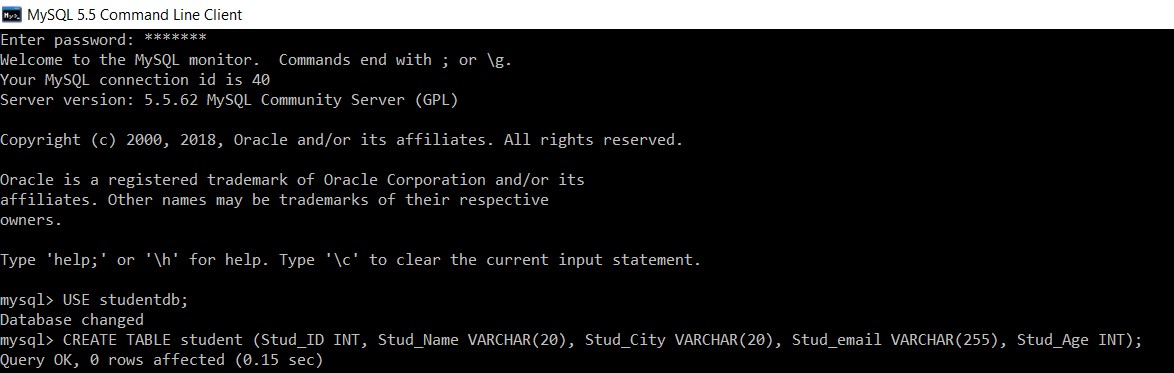
Chúng tôi đã tạo thành công bảng 'sinh viên' trong cơ sở dữ liệu 'studentdb'.
Bây giờ, chúng ta sẽ viết các truy vấn sau để chèn dữ liệu vào bảng sinh viên.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
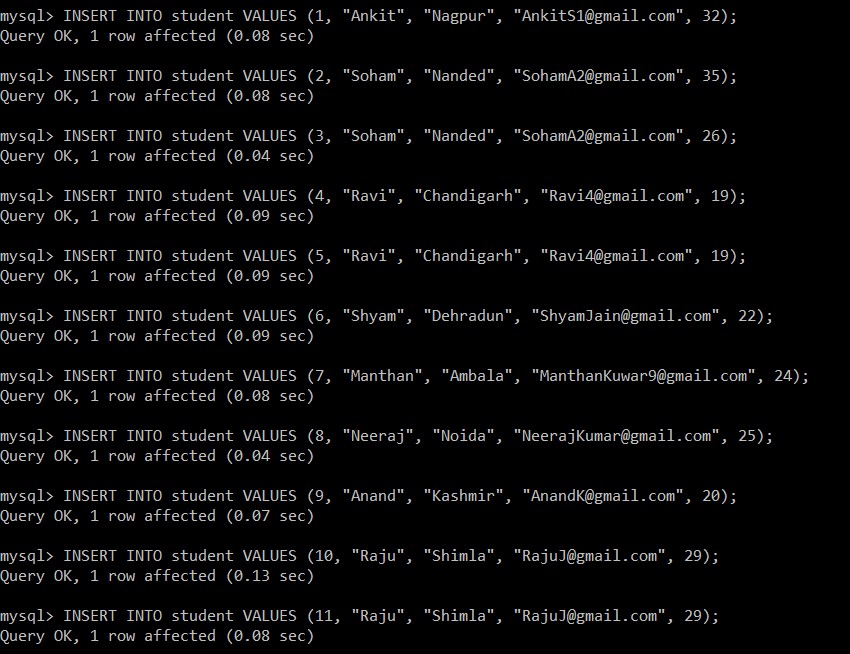
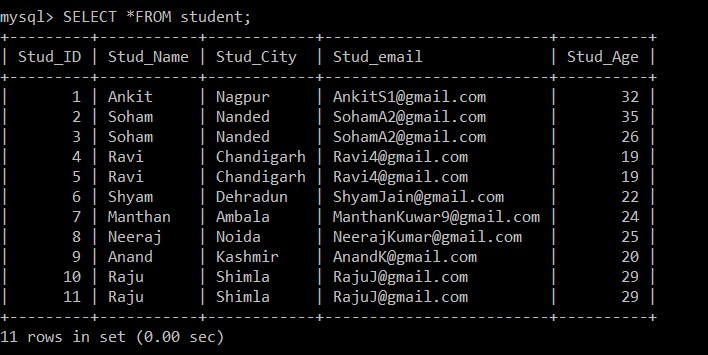
Bây giờ, chúng ta sẽ lấy tất cả các bản ghi từ bảng sinh viên. Chúng tôi sẽ xem xét bảng này và cơ sở dữ liệu cho tất cả các ví dụ sau.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Ví dụ 1:
Viết truy vấn để xóa các hàng trùng lặp khỏi bảng sinh viên bằng cách sử dụng XÓA THAM GIA tuyên bố.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Chúng tôi đã sử dụng truy vấn DELETE với INNER JOIN. Để triển khai INNER JOIN trên một bảng, chúng ta đã tạo hai phiên bản s1 và s2. Sau đó, với sự trợ giúp của mệnh đề WHERE, chúng tôi đã kiểm tra hai điều kiện để tìm ra các hàng trùng lặp trong bảng sinh viên. Nếu id email trong hai bản ghi khác nhau giống nhau và id sinh viên khác nhau, nó sẽ được coi là một bản ghi trùng lặp theo điều kiện mệnh đề WHERE.
Đầu ra:
Query OK, 3 rows affected (0.20 sec)Kết quả của truy vấn trên cho thấy có ba bản ghi trùng lặp trong bảng sinh viên.

Chúng tôi sẽ sử dụng truy vấn SELECT để tìm các bản ghi trùng lặp đã bị xóa.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
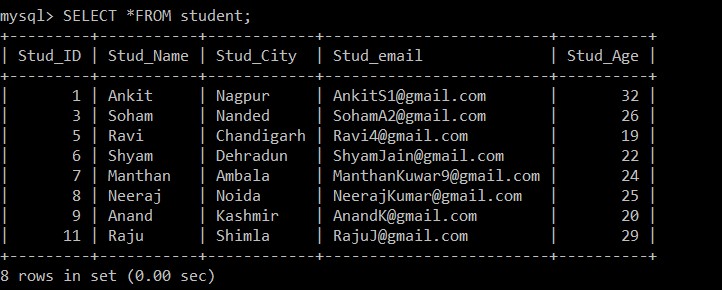
Bây giờ, chỉ có 8 bản ghi hiện diện trong bảng sinh viên vì ba bản ghi trùng lặp bị xóa khỏi bảng hiện được chọn. Theo điều kiện sau:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Nếu id email của bất kỳ hai bản ghi nào giống nhau, thì vì dấu nhỏ hơn được sử dụng giữa id sinh viên, chỉ bản ghi có ID nhân viên lớn hơn mới được lưu giữ và bản ghi trùng lặp khác sẽ bị xóa giữa hai bản ghi.
Ví dụ 2:
Viết truy vấn để xóa các hàng trùng lặp khỏi bảng sinh viên bằng cách sử dụng câu lệnh kết hợp xóa trong khi vẫn giữ bản ghi trùng lặp với id nhân viên thấp hơn và xóa cái kia.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Chúng tôi đã sử dụng truy vấn DELETE với INNER JOIN. Để triển khai INNER JOIN trên một bảng, chúng ta đã tạo hai phiên bản s1 và s2. Sau đó, với sự trợ giúp của mệnh đề WHERE, chúng ta đã kiểm tra hai điều kiện để tìm ra các hàng trùng lặp trong bảng sinh viên. Nếu id email có trong hai bản ghi khác nhau giống nhau và id sinh viên khác nhau, nó sẽ được coi là một bản ghi trùng lặp theo điều kiện mệnh đề WHERE.
Đầu ra:
Query OK, 3 rows affected (0.09 sec)Kết quả của truy vấn trên cho thấy có ba bản ghi trùng lặp trong bảng sinh viên.

Chúng tôi sẽ sử dụng truy vấn SELECT để tìm các bản ghi trùng lặp đã bị xóa.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
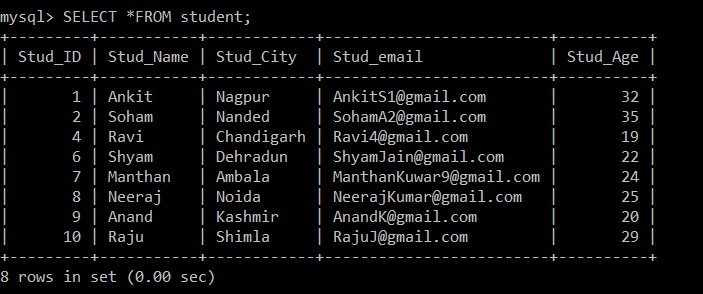
Bây giờ, chỉ có 8 bản ghi hiện diện trong bảng sinh viên vì ba bản ghi trùng lặp bị xóa khỏi bảng hiện được chọn. Theo điều kiện sau:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Nếu id email của hai bản ghi bất kỳ giống nhau vì dấu lớn hơn được sử dụng giữa id sinh viên, thì chỉ bản ghi có id nhân viên thấp hơn sẽ được giữ lại và bản ghi trùng lặp khác sẽ bị xóa giữa hai bản ghi.
- Sử dụng bảng trung gian để xóa các hàng trùng lặp
Các bước sau phải được thực hiện trong khi xóa các hàng trùng lặp với sự trợ giúp của bảng trung gian.
- Một bảng mới sẽ được tạo, bảng này sẽ giống như bảng thực tế.
- Thêm các hàng riêng biệt từ bảng thực tế vào bảng mới tạo.
- Bỏ bảng thực tế và đổi tên bảng mới bằng tên giống như bảng thực tế.
Ví dụ:
Viết truy vấn để xóa các bản ghi trùng lặp khỏi bảng sinh viên bằng cách sử dụng bảng trung gian.
Bước 1:
Đầu tiên, chúng ta sẽ tạo một bảng trung gian giống như bảng nhân viên.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Ở đây, ‘worker’ là bảng gốc và ‘temp_student’ là bảng trung gian.
Bước 2:
Bây giờ, chúng tôi sẽ chỉ tìm nạp các bản ghi duy nhất từ bảng sinh viên và chèn tất cả các bản ghi đã tìm nạp vào bảng temp_student.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Tại đây, trước khi chèn các bản ghi riêng biệt từ bảng sinh viên vào temp_student, tất cả các bản ghi trùng lặp được lọc bởi Stud_email. Sau đó, chỉ những bản ghi có id email duy nhất mới được chèn vào temp_student.
Bước 3:
Sau đó, chúng tôi sẽ xóa bảng sinh viên và đổi tên bảng temp_student thành bảng sinh viên.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
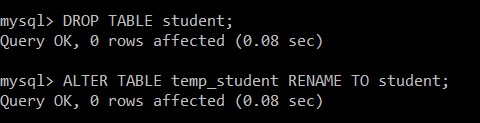
Đã xóa thành công bảng sinh viên và temp_student được đổi tên thành bảng sinh viên, chỉ chứa các bản ghi duy nhất.
Sau đó, chúng ta cần xác minh rằng bảng sinh viên bây giờ chỉ chứa các bản ghi duy nhất. Để xác minh điều này, chúng tôi đã sử dụng truy vấn SELECT để xem dữ liệu có trong bảng sinh viên.
mysql> SELECT *FROM student;Đầu ra:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
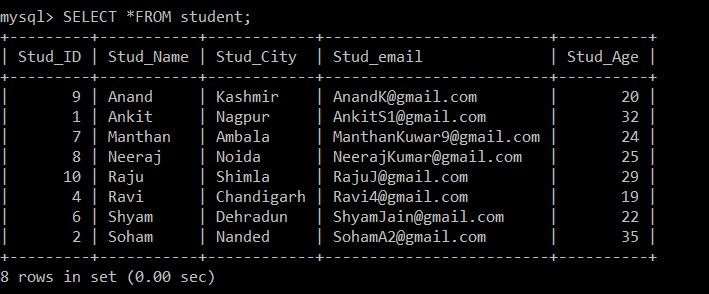
Bây giờ, chỉ có 8 bản ghi hiện diện trong bảng sinh viên vì ba bản ghi trùng lặp bị xóa khỏi bảng hiện được chọn. Ở bước 2, trong khi tìm nạp các bản ghi khác biệt từ bảng gốc và chèn chúng vào một bảng trung gian, mệnh đề GROUP BY đã được sử dụng trên Stud_email, vì vậy tất cả các bản ghi được chèn dựa trên id email của sinh viên. Ở đây, chỉ bản ghi có id nhân viên thấp hơn được giữ trong số các bản ghi trùng lặp theo mặc định và bản ghi còn lại sẽ bị xóa.