Nhu cầu ngày càng tăng đối với các hệ thống có tính khả dụng cao và SLA chặt chẽ thúc đẩy chúng tôi thay thế các quy trình thủ công bằng các giải pháp tự động. Nhưng bạn có đủ thời gian và nguồn lực cần thiết để tự mình giải quyết sự phức tạp của các hoạt động chuyển đổi dự phòng không? Bạn sẽ hy sinh thời gian ngừng hoạt động của cơ sở dữ liệu sản xuất để tìm hiểu nó một cách khó khăn chứ?
ClusterControl cung cấp hỗ trợ nâng cao để phát hiện và xử lý lỗi. Nó được nhiều tổ chức doanh nghiệp sử dụng, giữ cho các hệ thống sản xuất quan trọng nhất luôn hoạt động ở chế độ 24/7.
Giải pháp quản lý cơ sở dữ liệu này cũng hỗ trợ bạn triển khai các proxy tải khác nhau. Các proxy này đóng vai trò quan trọng trong ngăn xếp HA nên không cần điều chỉnh chuỗi kết nối ứng dụng hoặc mục nhập DNS để chuyển hướng các kết nối ứng dụng đến nút chính mới.
Khi phát hiện lỗi, ClusterControl thực hiện tất cả các công việc nền để chọn một máy chủ mới, triển khai các máy chủ phụ bị lỗi và định cấu hình bộ cân bằng tải. Trong blog này, bạn sẽ tìm hiểu cách đạt được tự động chuyển đổi dự phòng TimescaleDB trong hệ thống sản xuất của mình.
Triển khai toàn bộ cấu trúc sao chép
Bắt đầu từ ClusterControl 1.7.2, bạn có thể triển khai toàn bộ thiết lập sao chép TimescaleDB giống như cách bạn triển khai PostgreSQL:bạn có thể sử dụng menu “Deploy Cluster” để triển khai một máy chủ dự phòng chính và một hoặc nhiều TimescaleDB. Hãy xem nó trông như thế nào.
Đầu tiên, bạn cần xác định chi tiết truy cập khi triển khai các cụm mới bằng ClusterControl. Nó yêu cầu quyền truy cập mật khẩu root hoặc sudo vào tất cả các nút mà cụm mới của bạn sẽ được triển khai.
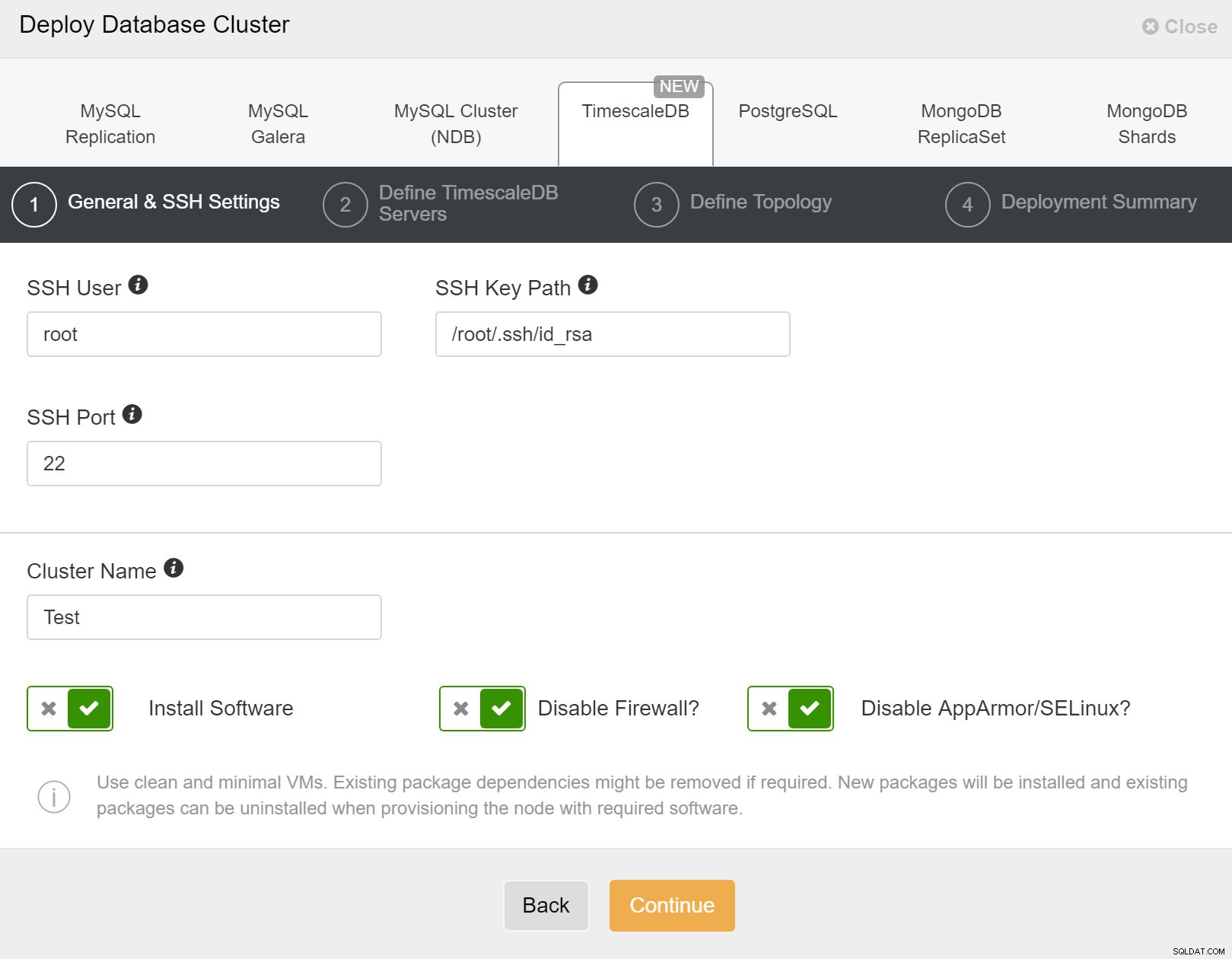 ClusterControl:Triển khai cụm mới
ClusterControl:Triển khai cụm mới Tiếp theo, chúng ta cần xác định người dùng và mật khẩu cho người dùng TimescaleDB.
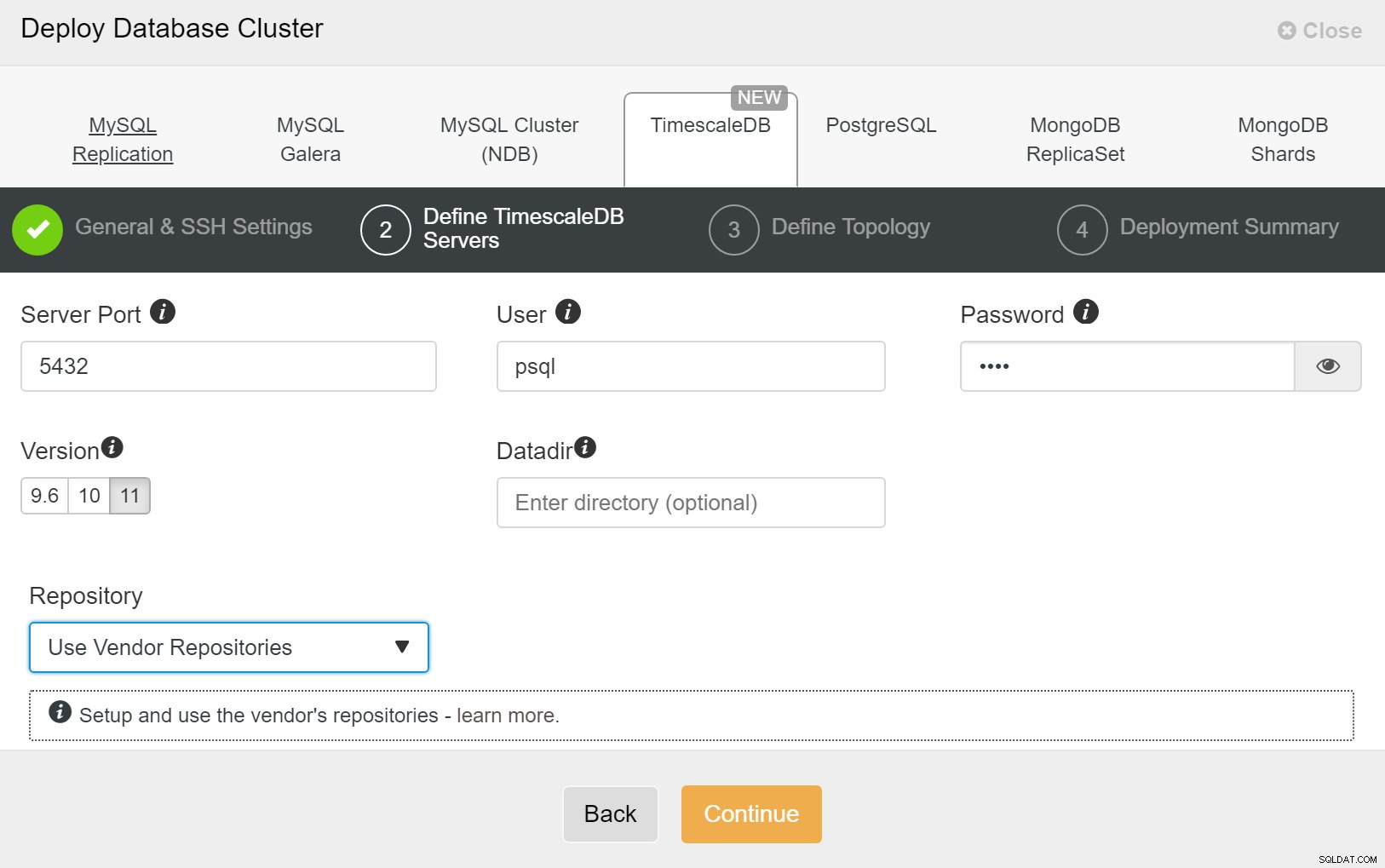 ClusterControl:Triển khai cụm cơ sở dữ liệu
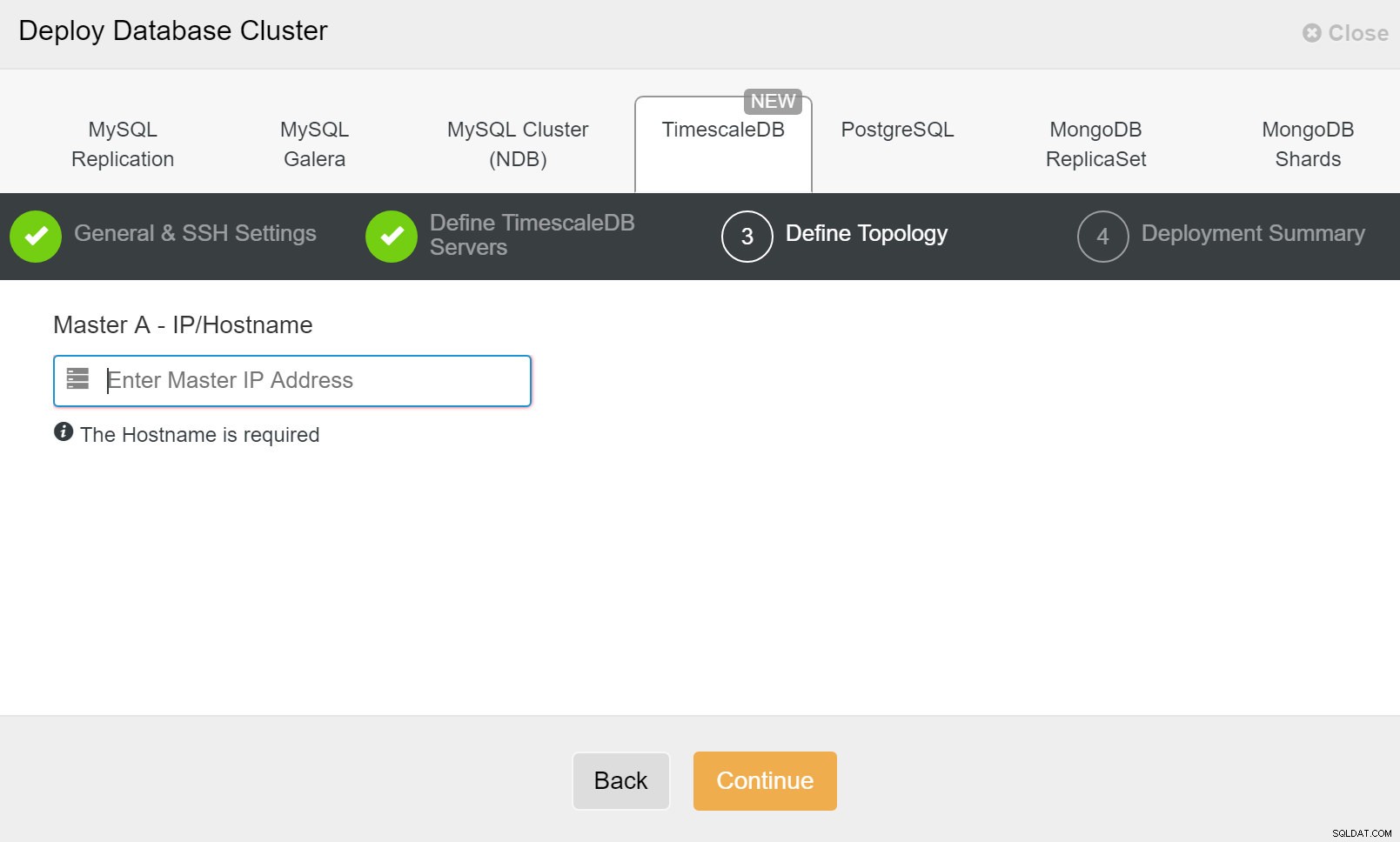
ClusterControl:Triển khai cụm cơ sở dữ liệu Cuối cùng, bạn muốn xác định cấu trúc liên kết - máy chủ nào phải là máy chính và máy chủ nào nên được định cấu hình ở chế độ chờ. Trong khi bạn xác định các máy chủ trong cấu trúc liên kết, ClusterControl sẽ kiểm tra xem quyền truy cập ssh có hoạt động như mong đợi hay không - điều này cho phép bạn sớm phát hiện được bất kỳ sự cố kết nối nào. Trên màn hình cuối cùng, bạn sẽ được hỏi về loại sao chép đồng bộ hoặc không đồng bộ.
 Triển khai ClusterControl
Triển khai ClusterControl Vậy là xong, sau đó là vấn đề bắt đầu triển khai. Một công việc được tạo trong ClusterControl và bạn sẽ có thể theo dõi tiến trình.
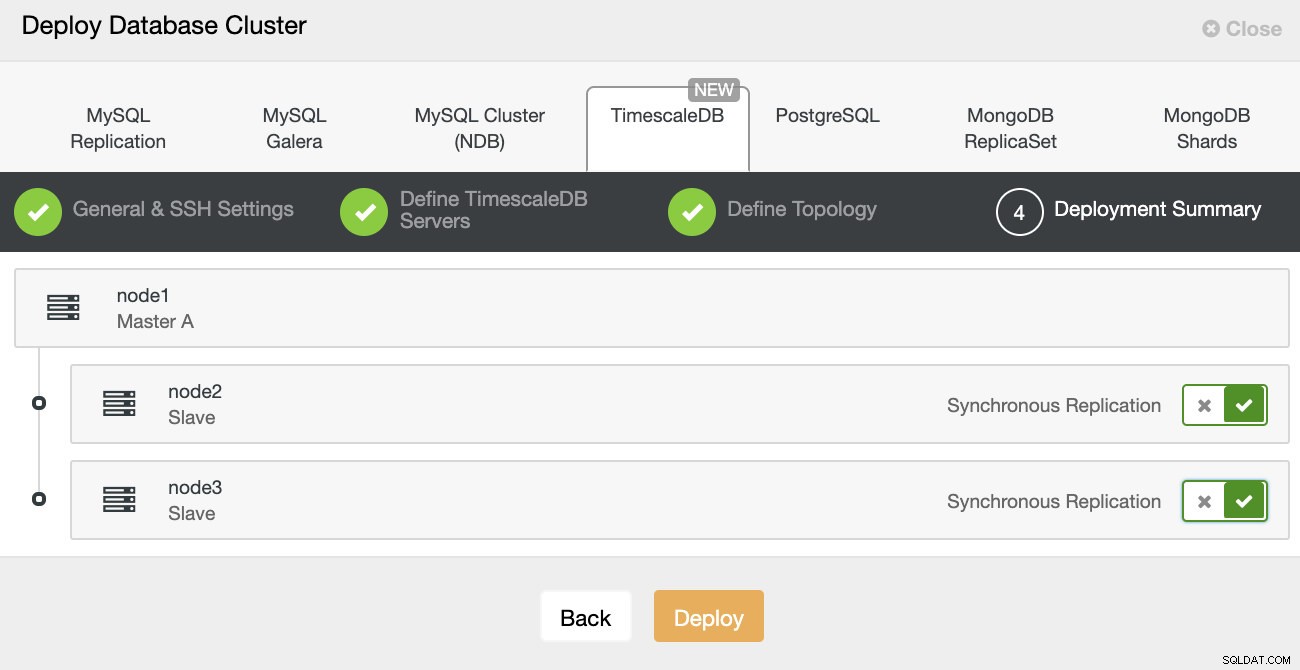
 ClusterControl:Xác định cấu trúc liên kết cho cụm TimescleDb
ClusterControl:Xác định cấu trúc liên kết cho cụm TimescleDb Sau khi hoàn thành, bạn sẽ thấy thiết lập cấu trúc liên kết với các vai trò trong cụm. Lưu ý rằng chúng tôi cũng đã thêm bộ cân bằng tải (HAProxy) trước các phiên bản cơ sở dữ liệu để chuyển đổi dự phòng tự động sẽ không yêu cầu thay đổi cài đặt kết nối cơ sở dữ liệu.
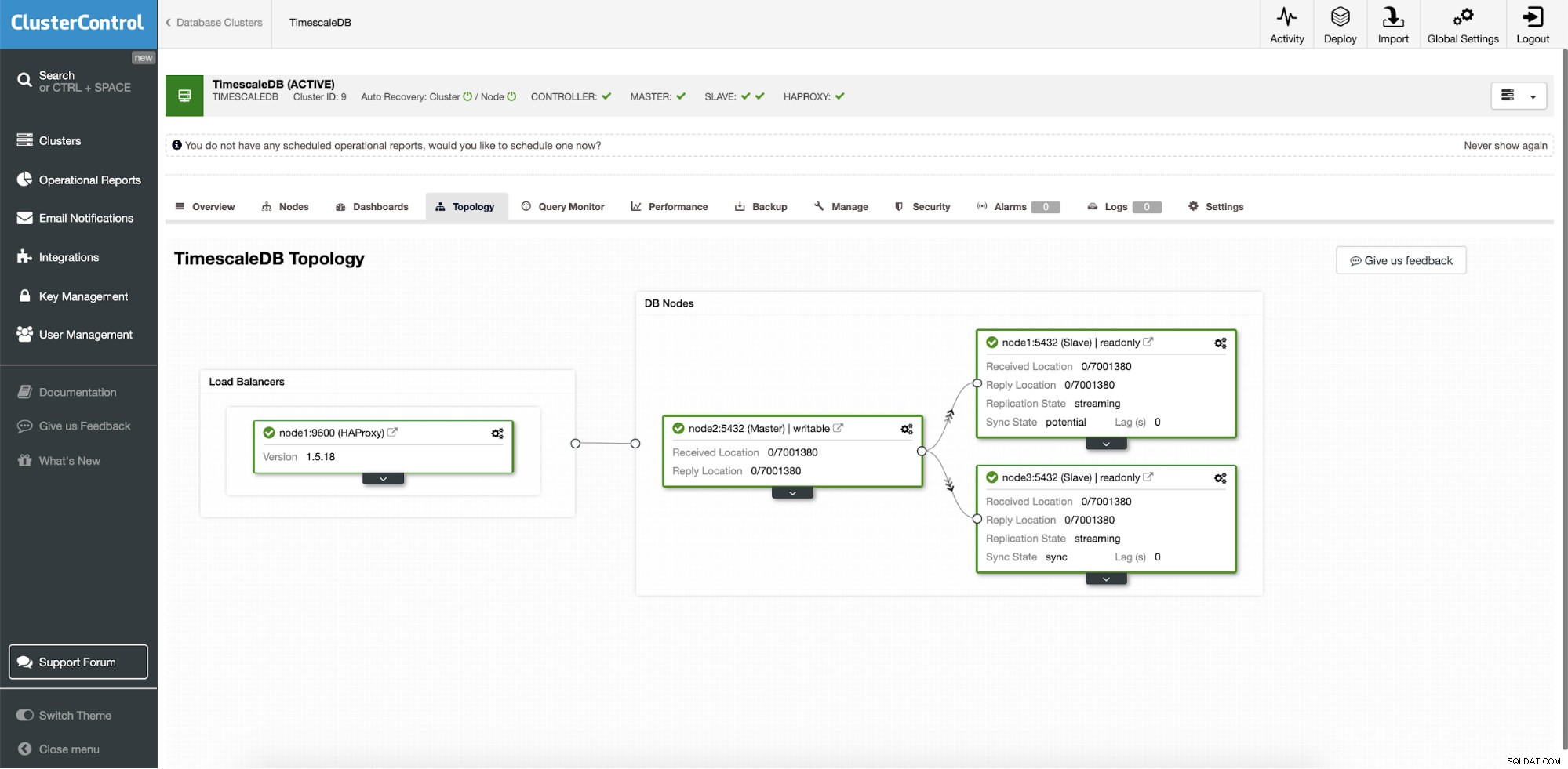 ClusterControl:Topology
ClusterControl:Topology Khi Timescale được triển khai bởi ClusterControl, phục hồi tự động được bật theo mặc định. Trạng thái có thể được kiểm tra trong thanh cụm.
 ClusterControl:Trạng thái nút và cụm khôi phục tự động
ClusterControl:Trạng thái nút và cụm khôi phục tự động Cấu hình chuyển đổi dự phòng
Sau khi thiết lập nhân rộng được triển khai, ClusterControl có thể giám sát thiết lập và tự động khôi phục bất kỳ máy chủ nào bị lỗi. Nó cũng có thể sắp xếp các thay đổi trong cấu trúc liên kết.
Chuyển đổi dự phòng tự động ClusterControl được thiết kế với các nguyên tắc sau:
- Đảm bảo rằng thiết bị chính đã thực sự chết trước khi bạn chuyển đổi dự phòng
- Chuyển đổi dự phòng chỉ một lần
- Không chuyển đổi dự phòng sang một nô lệ không nhất quán
- Chỉ viết thư cho chính chủ
- Không tự động khôi phục trang cái bị lỗi
Với các thuật toán tích hợp, chuyển đổi dự phòng thường có thể được thực hiện khá nhanh chóng, do đó bạn có thể đảm bảo SLA cao nhất cho môi trường cơ sở dữ liệu của mình.
Quá trình này có thể định cấu hình. Nó đi kèm với nhiều tham số mà bạn có thể sử dụng để áp dụng khôi phục cho các chi tiết cụ thể của môi trường của bạn.
| max_replication_lag | Độ trễ sao chép tối đa được phép tính bằng giây trước |
| replication_stop_on_error | Các thủ tục chuyển đổi / chuyển đổi dự phòng sẽ không thành công nếu gặp phải lỗi có thể gây mất dữ liệu. Được bật theo mặc định. 0 có nghĩa là vô hiệu hóa, |
| replication_auto_rebuild_slave | Nếu SQL THREAD bị dừng và mã lỗi khác 0 thì nô lệ sẽ được tự động xây dựng lại. 1 nghĩa là bật, 0 nghĩa là tắt (mặc định). |
| replication_failover_blacklist | Danh sách các cặp tên máy:cổng được phân tách bằng dấu phẩy. Các máy chủ nằm trong danh sách đen sẽ không được coi là một ứng cử viên trong quá trình chuyển đổi dự phòng. replication_failover_blacklist bị bỏ qua nếu replication_failover_whitelist được đặt. |
| replication_failover_whitelist | Danh sách các cặp tên máy:cổng được phân tách bằng dấu phẩy. Chỉ những máy chủ có trong danh sách cho phép mới được coi là một ứng cử viên trong quá trình chuyển đổi dự phòng. Nếu không có máy chủ nào trong danh sách trắng khả dụng (lên / kết nối) thì chuyển đổi dự phòng sẽ không thành công. replication_failover_blacklist bị bỏ qua nếu replication_failover_whitelist được đặt. |
Xử lý chuyển đổi dự phòng
Khi phát hiện lỗi tổng thể, một danh sách các ứng cử viên chính được tạo và một trong số họ được chọn làm chủ mới. Có thể có danh sách trắng các máy chủ để thăng cấp lên chính, cũng như danh sách đen các máy chủ không thể thăng cấp lên chính. Các nô lệ còn lại hiện đã bị xóa khỏi phần chính mới và phần chính cũ không được khởi động lại.
Dưới đây, chúng ta có thể thấy mô phỏng lỗi của nút.
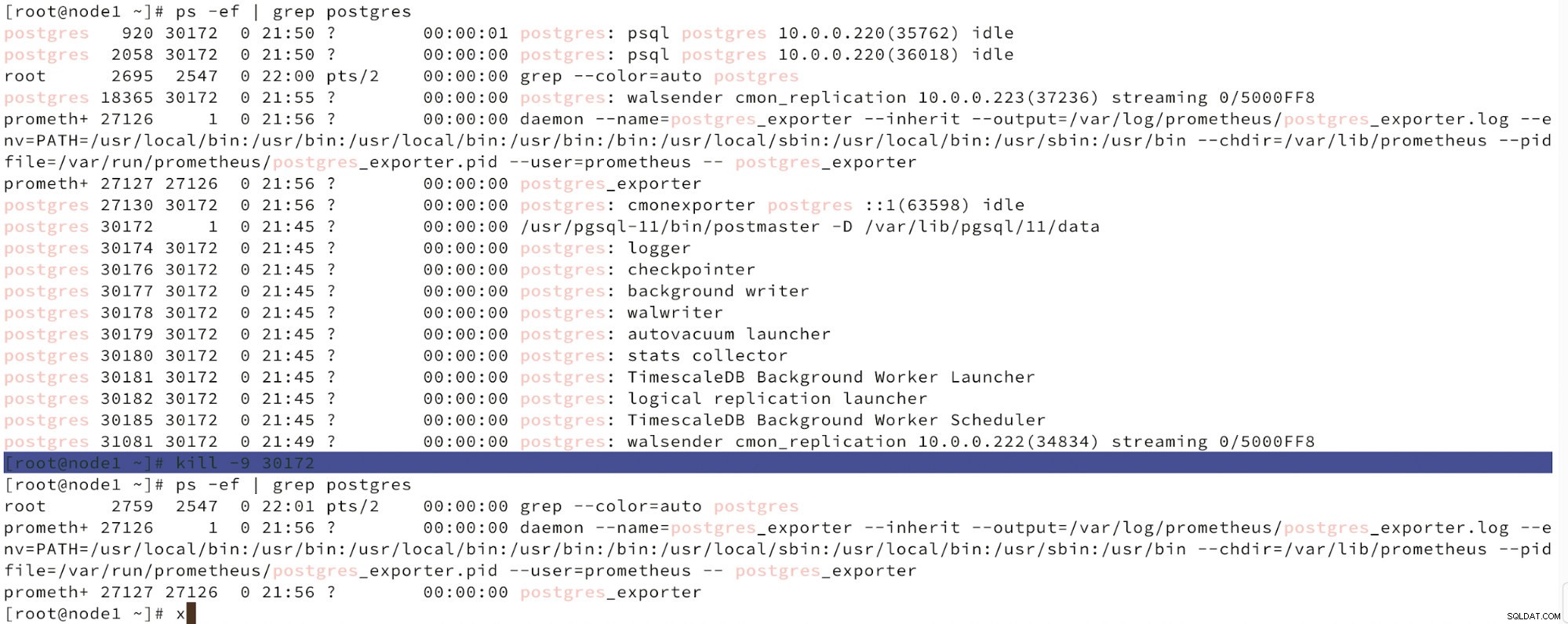 Mô phỏng lỗi nút chính bằng cách giết
Mô phỏng lỗi nút chính bằng cách giết Khi các nút bị trục trặc được phát hiện và tự động khôi phục được phát hiện, ClusterControl sẽ kích hoạt công việc để thực hiện chuyển đổi dự phòng. Dưới đây, chúng tôi có thể thấy các hành động được thực hiện để khôi phục cụm.
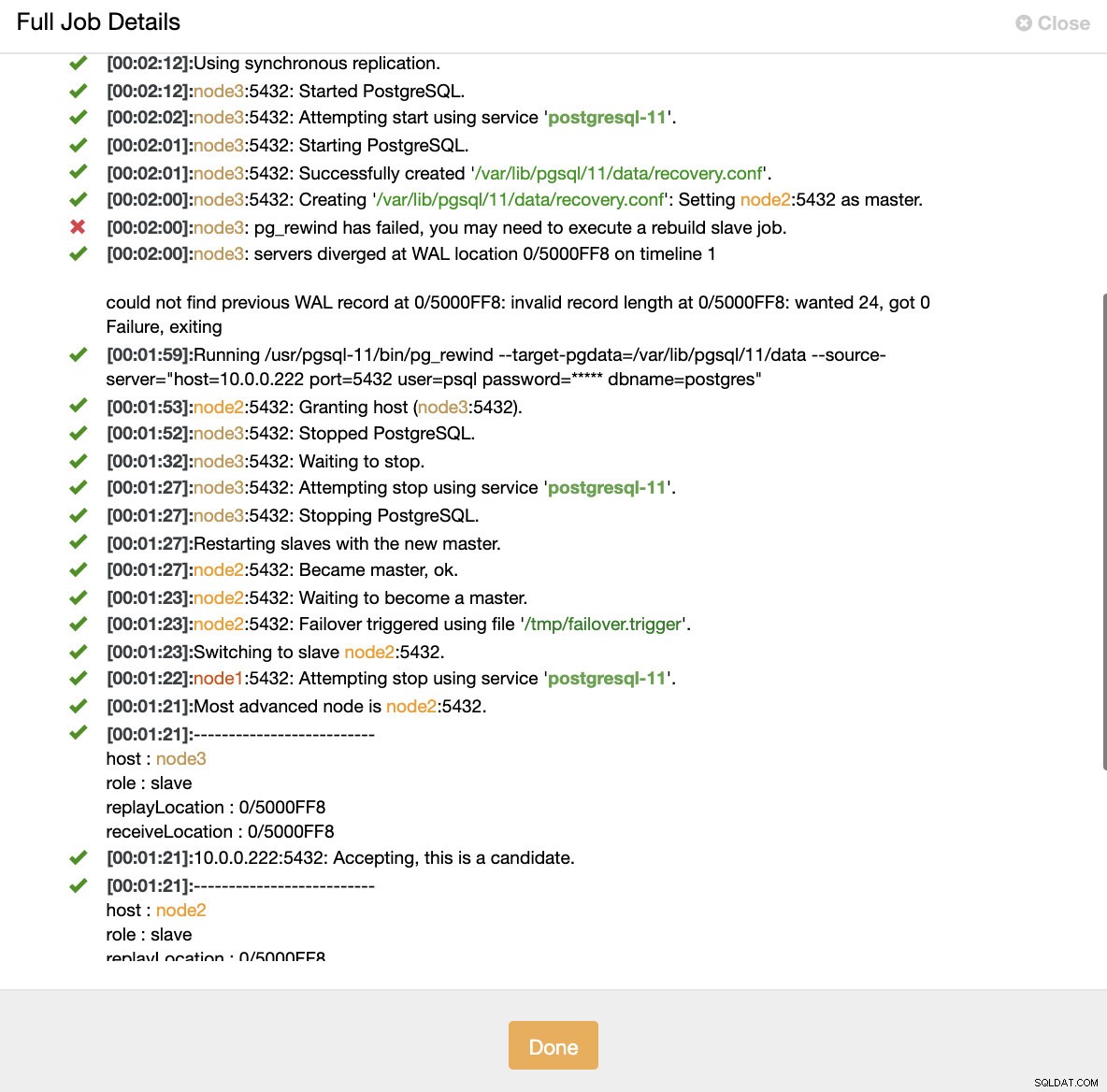 ClusterControl:Công việc được kích hoạt để xây dựng lại cụm
ClusterControl:Công việc được kích hoạt để xây dựng lại cụm ClusterControl cố ý giữ ngoại tuyến chính cũ vì có thể xảy ra trường hợp một số dữ liệu chưa được chuyển đến máy chủ dự phòng. Trong trường hợp như vậy, máy chủ chính là máy chủ duy nhất chứa dữ liệu này và bạn có thể muốn khôi phục dữ liệu bị thiếu theo cách thủ công. Đối với những người muốn tự động xây dựng lại chính bị lỗi, có một tùy chọn trong tệp cấu hình cmon:replication_auto_rebuild_slave. Theo mặc định, tính năng này bị vô hiệu hóa nhưng khi người dùng bật tính năng này, thiết bị chính bị lỗi sẽ được xây dựng lại dưới dạng nô lệ của thiết bị chính mới. Tất nhiên, nếu thiếu bất kỳ dữ liệu nào chỉ tồn tại trên trang chính bị lỗi, dữ liệu đó sẽ bị mất.
Xây dựng lại máy chủ dự phòng
Tính năng khác là công việc “Rebuild Replication Slave” có sẵn cho tất cả các nô lệ (hoặc máy chủ dự phòng) trong thiết lập nhân bản. Điều này sẽ được sử dụng chẳng hạn khi bạn muốn xóa dữ liệu ở chế độ chờ và xây dựng lại nó bằng một bản sao mới của dữ liệu chính. Nó có thể có lợi nếu một máy chủ dự phòng không thể kết nối và sao chép từ máy chủ chính vì một số lý do.
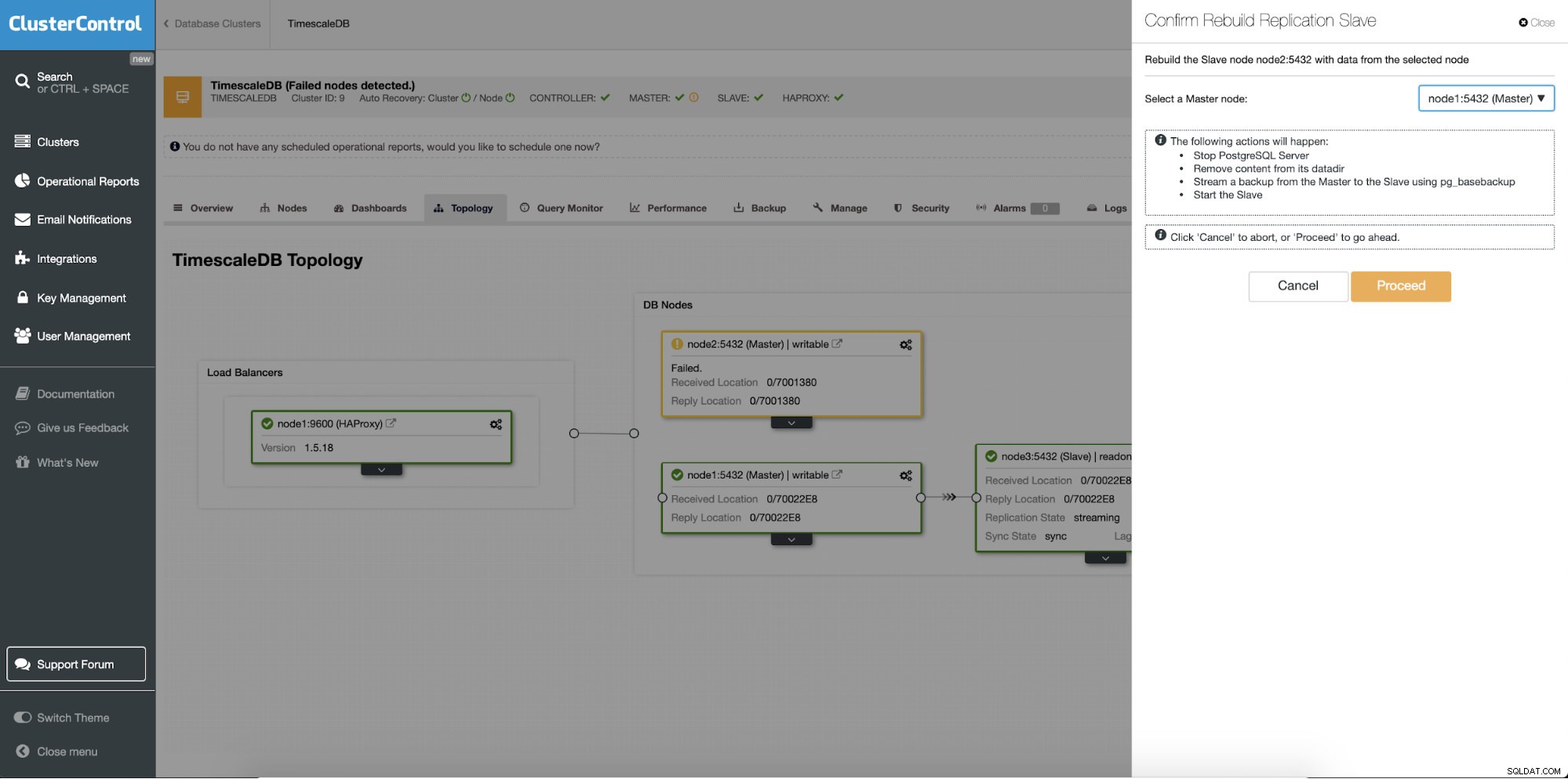 ClusterControl:Xây dựng lại nô lệ sao chép
ClusterControl:Xây dựng lại nô lệ sao chép  ClusterControl:Xây dựng lại nô lệ
ClusterControl:Xây dựng lại nô lệ