Tất cả dữ liệu dư luận đó được lưu trữ như thế nào? Chúng tôi kiểm tra mô hình dữ liệu thăm dò ý kiến.
Mọi người đều muốn biết công chúng nghĩ gì, từ các chính trị gia, công ty đến các cá nhân muốn biết người khác nghĩ gì về một chủ đề nhất định. Loại công việc này thường được thực hiện bởi các cơ quan chuyên về loại nghiên cứu đó.
Hôm nay, chúng ta sẽ xem xét mô hình dữ liệu mà một đại lý có thể sử dụng để lưu trữ tất cả dữ liệu thăm dò có liên quan, từ các câu hỏi và câu trả lời xác định trước cho đến phản hồi thực tế. Dữ liệu này sau đó sẽ được sử dụng để tạo các báo cáo khác nhau. Vì vậy, hãy bắt đầu.
Ý tưởng
Các cuộc thăm dò có thể được tạo ở bất cứ đâu. Chúng có thể được lập kế hoạch tốt và bao gồm một mẫu đại diện của công chúng (dựa trên nhân khẩu học). Hoặc bạn có thể làm chúng ngay tại chỗ, ví dụ:nếu bạn muốn dự đoán kết quả bầu cử dựa trên một mẫu (chẳng hạn như một cuộc thăm dò ý kiến), bạn có thể hỏi mọi người tại điểm bỏ phiếu xem họ đã bỏ phiếu như thế nào.
Mặt khác, nếu bạn muốn tạo cùng một cuộc thăm dò trước cuộc bầu cử, bạn có thể chọn một mẫu và liên hệ với các cá nhân qua điện thoại hoặc gặp trực tiếp. Thông thường, chỉ có một số câu hỏi cho loại cuộc thăm dò ý kiến này - một số câu hỏi bao gồm nhân khẩu học và một số câu hỏi khác bao gồm những gì chúng tôi thực sự quan tâm.
Các cuộc thăm dò cũng có thể phức tạp hơn nhiều, ví dụ:nếu bạn muốn biết ý kiến của công chúng về một sản phẩm nhất định, bao gồm tất cả mọi thứ từ hiệu suất đến bao bì của nó.
Trong bài viết này, tôi sẽ không thảo luận về cách chọn một nhóm người mẫu; thay vào đó, tôi sẽ tập trung vào bản thân cuộc thăm dò ý kiến, các câu hỏi của cuộc thăm dò ý kiến và các câu trả lời.
Mô hình dữ liệu
Mô hình dữ liệu của cơ quan thăm dò dư luận
Mô hình bao gồm ba lĩnh vực chủ đề:
-
Polls -
Questions & Answers -
Result
Chúng tôi sẽ mô tả từng lĩnh vực chủ đề theo thứ tự được liệt kê.
Cuộc thăm dò
Trước khi bắt đầu đặt câu hỏi, chúng tôi cần xác định những gì chúng tôi quan tâm. Chúng tôi sẽ xác định các cuộc thăm dò và bảng câu hỏi trong phần này, sau đó thêm câu hỏi và câu trả lời trong phần tiếp theo.
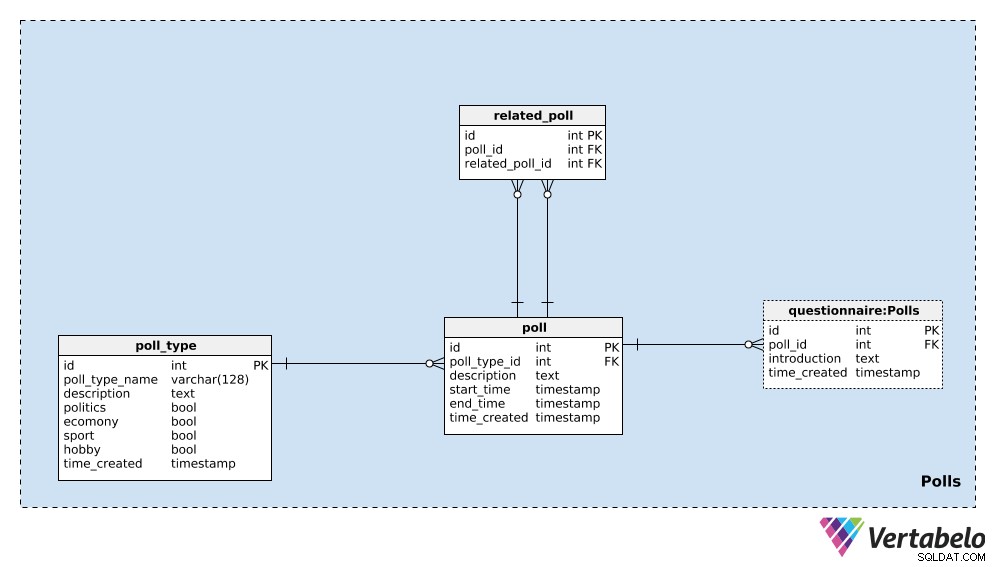
Chúng tôi sẽ bắt đầu với poll_type từ điển. Chúng tôi có thể mong đợi rằng chúng tôi sẽ chủ yếu lặp lại các cuộc thăm dò cùng loại. Loại phổ biến nhất có lẽ là thăm dò bầu cử, nhưng chúng tôi muốn có thể thêm các loại thăm dò mới trong quá trình thực hiện. Đối với mỗi loại thăm dò ý kiến, chúng tôi sẽ lưu trữ một poll_type_name và sử dụng description để cung cấp thêm thông tin chi tiết.
Bốn lá cờ - politics , economy , sport và hobby - được sử dụng để biểu thị loại cuộc thăm dò. Một cuộc thăm dò có thể bao gồm một hoặc nhiều chủ đề đó; nếu cần, chúng tôi có thể chia các danh mục này thành một từ điển riêng biệt và có mối quan hệ nhiều-nhiều giữa từ điển đó và poll_type bảng.
Thuộc tính cuối cùng trong bảng này là time_created . Nó biểu thị thời điểm khi một hàng được chèn vào bảng này.
Điều tiếp theo chúng ta cần làm là xác định một poll . Đây là một trường hợp duy nhất, ví dụ: “Cuộc bầu cử tổng thống Hoa Kỳ năm 2020 - Cuộc thăm dò ý kiến vào tháng 4 năm 2020” . Đối với mỗi cuộc thăm dò ý kiến, chúng tôi sẽ lưu trữ các thông tin chi tiết sau:
-
poll_type_id- Tham chiếu đếnpoll_type. -
description- Tất cả thông tin chi tiết liên quan đến cuộc thăm dò này, ở định dạng văn bản. -
start_timevàend_time- Thời gian bắt đầu và kết thúc được xác định, trong đó cuộc thăm dò ý kiến này được thực hiện. -
time_created- Thời điểm thực tế khi cuộc thăm dò ý kiến này được tạo.
Các cuộc thăm dò có thể liên quan đến nhau. Trong ví dụ về “Cuộc bầu cử tổng thống Hoa Kỳ năm 2020 - cuộc thăm dò ý kiến vào tháng 4 năm 2020” , chúng tôi có thể thực hiện cuộc thăm dò tương tự vào tháng tới để xem những ý kiến mới nhất. Chúng tôi gọi đây là “Cuộc bầu cử tổng thống Hoa Kỳ năm 2020 - Cuộc thăm dò ý kiến vào tháng 5 năm 2020” . Hai cuộc thăm dò này có liên quan với nhau vì kết quả của chúng cho thấy xu hướng. Để thiết lập mối quan hệ đó, chúng tôi sẽ sử dụng related_poll bảng trong mô hình của chúng tôi. Nó chỉ chứa cặp poll_id DUY NHẤT - related_poll_id , biểu thị cuộc thăm dò và tiền thân của nó.
Lưu ý rằng chúng ta có thể sử dụng bảng này để lưu trữ tất cả các cuộc thăm dò có liên quan theo bất kỳ cách nào, không chỉ người tiền nhiệm / người kế nhiệm. Nếu chúng tôi muốn xác định các mối quan hệ khác nhau, chúng tôi cần thêm một từ điển khác - nhưng chúng tôi sẽ không làm theo cách đó trong bài viết này.
Bảng cuối cùng trong chủ đề này là questionnaire bàn. Trong hầu hết các trường hợp, mỗi cuộc thăm dò sẽ có chính xác một bảng câu hỏi, nhưng tôi muốn để lại tùy chọn mà chúng tôi có thể có nhiều hơn một bảng nếu cần. Do đó, tôi đã sử dụng một bảng riêng. Trong bảng này, chúng tôi sẽ chỉ lưu trữ ID của cuộc thăm dò có liên quan (poll_id ), một introduction mô tả bảng câu hỏi đó và dấu thời gian khi bản ghi được chèn vào (time_created ).
Câu hỏi và câu trả lời
Bây giờ chúng tôi đã sẵn sàng tạo tất cả các chi tiết của bảng câu hỏi. Chúng tôi cũng có thể liệt kê tất cả các câu hỏi chúng tôi muốn hỏi cũng như tất cả các câu trả lời được xác định trước.
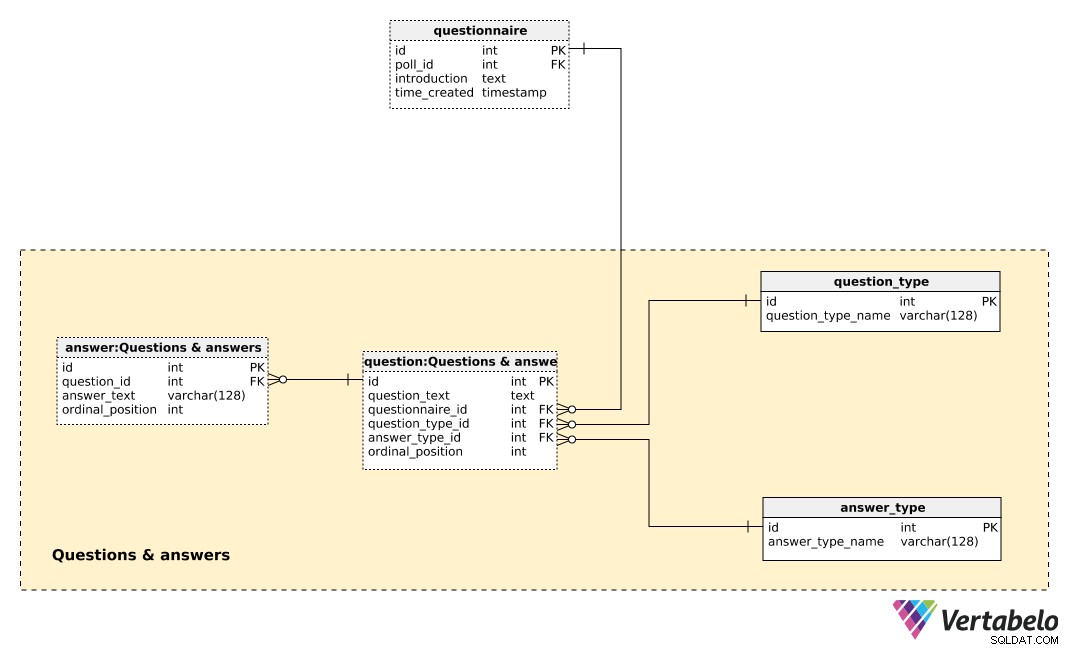
Bảng trung tâm trong chủ đề này là question bàn. Mỗi câu hỏi được xác định bởi các chi tiết sau:
-
question_text- Một văn bản sẽ được hiển thị cho từng cá nhân được thăm dò ý kiến. -
questionnaire_id- Tham chiếu biểu thị bảng câu hỏi của câu hỏi này. -
question_type_id- Tham chiếu biểu thịquestion_type, được biểu thị bằngquestion_type_name. Về cơ bản đây là các danh mục, ví dụ:"Nhân khẩu học", "ý kiến", "kiểm soát", v.v. Những điều này sẽ cho phép chúng tôi tách các câu hỏi về nhân khẩu học và quan điểm và tìm ra mối tương quan giữa chúng. -
answer_type_id- Tham chiếu đến loại câu trả lời sẽ được sử dụng cho câu hỏi này. Mỗianswer_typelà UNIQUELY được định nghĩa bởianswer_type_namevà biểu thị cách hiển thị câu trả lời. Một số loại được mong đợi là "mở", "danh sách", "hộp kiểm" và "nhiều". -
ordinal_position- Giá trị này biểu thị vị trí của câu hỏi này trong bảng câu hỏi. Cùng vớiquestionnaire_id, nó tạo thành khóa thay thế của bảng này.
Danh sách tất cả các câu trả lời được xác định trước được lưu trữ trong answer bàn. Nếu loại câu hỏi không mở (nghĩa là cá nhân sẽ không nhập văn bản), chúng tôi sẽ có một tập hợp các câu trả lời được xác định trước. Đối với mỗi câu trả lời, chúng tôi sẽ xác định câu hỏi mà nó thuộc về (question_id ), answer_text và ordinal_position của câu trả lời bên trong câu hỏi đó. Một lần nữa, một cặp DUY NHẤT - lần này là question_id - ordinal_position - tạo thành khóa thay thế của bảng này.
Kết quả
Trong hai lĩnh vực chủ đề trước, chúng tôi đã xác định mọi thứ chúng tôi cần để tạo cuộc thăm dò ý kiến và bắt đầu đặt câu hỏi. Bây giờ chúng ta cần xác định một cấu trúc dữ liệu để lưu trữ các câu trả lời thực tế.
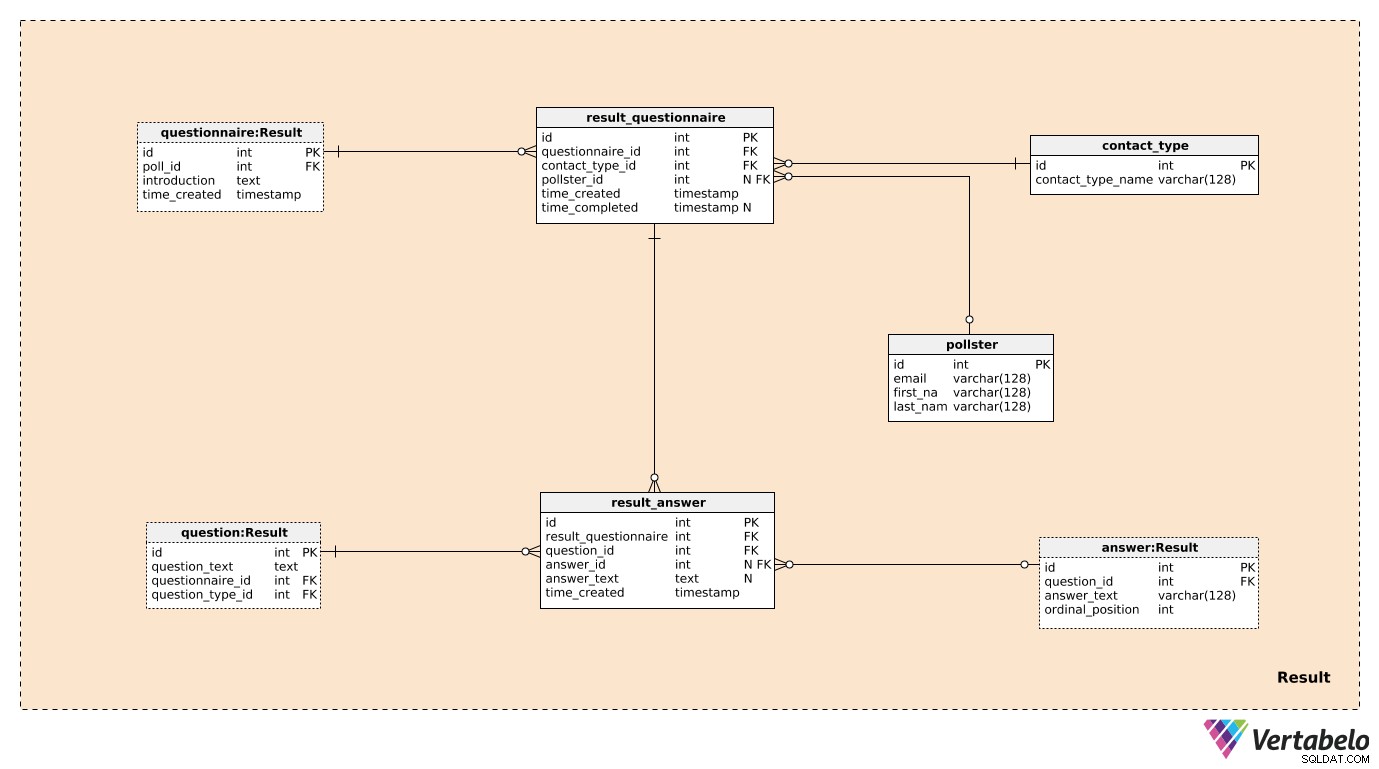
Ba trong số bảy bảng trong Result lĩnh vực chủ đề đã được đề cập và mô tả trước đó. Đây là questionnaire , question và answer . Bốn bảng còn lại được sử dụng để lưu trữ những gì chúng tôi thực sự quan tâm.
Chúng tôi sẽ tạo một bản ghi trong result_questionnaire bảng cho từng cá nhân tham gia cuộc bình chọn. questionnaire_id cung cấp esus với tất cả các thông tin về cuộc thăm dò có liên quan. contact_type_id là tham chiếu đến contact_type từ điển. Các giá trị trong bảng này mô tả cách chúng tôi đã tương tác với người này. Các giá trị này KHÔNG ĐƯỢC xác định bởi contact_type_name giá trị và có thể là một cái gì đó như “điện thoại”, “trực tiếp”, “email”, “biểu mẫu web”, v.v.
pollster_id thuộc tính là một tham chiếu đến poll bảng, cung cấp thông tin về người đã tiến hành cuộc thăm dò thực tế đó. Đối với mỗi pollster , chúng tôi sẽ chỉ lưu trữ email DUY NHẤT và first_name của họ và last_name . time_created thuộc tính biểu thị thời gian thực khi bản ghi này được tạo, trong khi time_completed sẽ được thiết lập tại thời điểm cuộc khảo sát này hoàn thành. (Cho đến thời điểm đó, nó sẽ là NULL).
Bảng cuối cùng trong mô hình là result_answer bàn. Đúng như tên gọi, đây là nơi chúng tôi sẽ lưu trữ các phản hồi thực tế mà chúng tôi nhận được từ những người tham gia khảo sát. Đối với mỗi bản ghi trong bảng này, chúng ta sẽ có:
-
result_questionnaire_id- Tham chiếu đến bảng câu hỏi liên quan. -
question_id- Tham chiếu biểu thị câu hỏi được trả lời bởi câu trả lời này. -
answer_id- Tham chiếu đến câu trả lời được sử dụng để trả lời câu hỏi này. Thuộc tính này sẽ chứa giá trị NULL khi câu hỏi thuộc loại "mở" (vì không có câu trả lời xác định trước để lựa chọn). -
answer_text- Văn bản đã được chèn để trả lời câu hỏi này. Thuộc tính này sẽ chứa một giá trị khi câu hỏi là "mở"; trong tất cả các trường hợp khác, nó sẽ là NULL. -
time_created- Thời gian thực tế khi câu trả lời này được đưa vào hệ thống của chúng tôi.
Các cải tiến có thể có
Cho đến nay, chúng tôi đã đề cập đến cách chúng tôi có thể lưu trữ dữ liệu cuộc thăm dò. Chúng tôi chưa thảo luận về những gì chúng tôi sẽ làm với dữ liệu sau khi cuộc thăm dò ý kiến kết thúc. Chúng tôi có thể hy vọng rằng chúng tôi sẽ không cần dữ liệu cũ trong tương lai, ít nhất là không cần trong cơ sở dữ liệu hoạt động của chúng tôi. Do đó, chúng tôi có thể làm hai điều:
- Lưu trữ tóm tắt cuộc thăm dò trong một bảng riêng biệt trong cơ sở dữ liệu hoạt động. Điều này sẽ giúp chúng tôi sử dụng những thông tin đó nếu chúng tôi muốn xem điều gì đã xảy ra với một cuộc thăm dò tương tự.
- Lưu trữ tất cả dữ liệu thăm dò ý kiến trong cơ sở dữ liệu dự phòng có cấu trúc giống với cơ sở dữ liệu hoạt động. Điều này sẽ cho phép chúng tôi truy cập thông tin chi tiết khi chúng tôi cần.
Chúng tôi cũng có thể tạo kho dữ liệu để lưu trữ kết quả thăm dò ý kiến, nhưng điều đó sẽ không cần thiết nếu chúng tôi đã thực hiện các nhiệm vụ được mô tả trong hai gạch đầu dòng.
Bạn nghĩ gì về Mô hình dữ liệu thăm dò ý kiến của chúng tôi?
Chúng tôi muốn nghe ý kiến của bạn về những gì chúng tôi có thể thay đổi để cải thiện mô hình dữ liệu thăm dò ý kiến. Bạn có kinh nghiệm trong ngành không? Bạn có nghĩ rằng chúng tôi đã bỏ lỡ một cái gì đó? Bạn sẽ thêm hoặc bớt một cái gì đó? Mong nhận được ý kiến của bạn.