Trong thời đại toàn cầu hóa hiện nay, các công ty - bao gồm cả các nhà phát triển phần mềm - luôn quan tâm đến việc mở rộng sang các thị trường mới. Điều này thường có nghĩa là bản địa hóa các sản phẩm của họ cho các khu vực khác nhau. Trong bài viết này, chúng tôi sẽ giải thích một số cách tiếp cận để thiết kế mô hình dữ liệu của bạn để bản địa hóa - cụ thể là để quản lý nội dung bằng nhiều ngôn ngữ.
Bản địa hóa là gì?
Nội địa hóa là quá trình thích ứng một sản phẩm với các thị trường khác nhau. Đó là một yếu tố nổi bật trong việc đạt được thị phần tối đa về doanh số bán sản phẩm. Khi bản địa hóa được thực hiện chính xác, người dùng sẽ cảm thấy rằng sản phẩm được sản xuất cho ngôn ngữ, văn hóa và nhu cầu của họ.
Ở những nơi mà tiếng Anh không phải là ngôn ngữ đầu tiên phổ biến, các cuộc khảo sát đã chứng minh rằng ngôn ngữ địa phương được ưu tiên hơn nhiều cho một sản phẩm phần mềm. Bài báo này của MediaPost chứa một số số liệu thú vị về nhu cầu sử dụng các ngôn ngữ khác ngoài tiếng Anh khi nói đến bán hàng quốc tế.
Bạn có thể mất gì khi không bản địa hóa?
Hãy xem xét một ví dụ đáng tiếc về việc không bản địa hóa. Để thuận tiện cho khách hàng, cổng thương mại điện tử cho phép khách hàng gộp các giao dịch mua riêng lẻ thành một nhóm bốn người. Thật không may, cách phát âm của từ "bốn" trong tiếng Nhật giống như từ của họ để chỉ "cái chết". Người Nhật thường tránh tất cả những thứ liên quan đến con số này vì nó được coi là không may mắn. Không cần phải nói, doanh số bán những sản phẩm đó không tốt ở thị trường Nhật Bản.
Vì vậy, để trả lời cho câu hỏi trên, bạn có thể mất rất nhiều nếu không lập kế hoạch cẩn thận cho thị trường mục tiêu của mình.
Dịch nội dung dưới dạng bản địa hóa
Khi chúng ta nghĩ đến bản địa hóa, dịch nội dung thường là suy nghĩ đầu tiên xuất hiện trong đầu chúng ta. Suy nghĩ thứ hai là “Chúng ta cần một mô hình cơ sở dữ liệu mạnh mẽ và hiệu quả để lưu trữ nội dung đã dịch sang nhiều ngôn ngữ”.
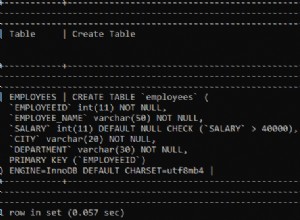
Giả sử chúng ta được yêu cầu thiết kế một mô hình dữ liệu cho một ứng dụng thương mại điện tử đa ngôn ngữ. Chúng tôi cần lưu trữ các trường văn bản như product_name và mô tả sản phẩm bằng nhiều ngôn ngữ khác nhau. Chúng tôi cũng cần lưu trữ các trường văn bản trong các bảng khác, chẳng hạn như customer bảng, bằng tất cả các ngôn ngữ này.
Để hiểu cách thiết kế mô hình dữ liệu của chúng tôi có lưu ý đến việc dịch nội dung, chúng tôi sẽ xem xét các phương pháp tiếp cận khác nhau bằng cách sử dụng hai bảng này. Mỗi cách tiếp cận này đều có ưu và nhược điểm. Các phương pháp tiếp cận được trình bày dưới đây có thể được mở rộng cho các bảng khác trong mô hình dữ liệu của bạn. Tất nhiên, cách tiếp cận chính xác bạn chọn sẽ dựa trên yêu cầu của riêng bạn.
Phương pháp 1 - Thêm các Cột Ngôn ngữ Riêng biệt cho Mỗi Trường Dự định
Đây là cách tiếp cận đơn giản nhất về mặt phát triển. Nó có thể được triển khai bằng cách thêm một cột ngôn ngữ cho mỗi trường.
Ưu điểm
- Nó rất dễ thực hiện.
-
Không có sự phức tạp trong việc viết SQL để tìm nạp dữ liệu cơ bản bằng bất kỳ ngôn ngữ nào. Giả sử tôi muốn viết một truy vấn để lấy thông tin chi tiết về sản phẩm và khách hàng cho một đơn đặt hàng cụ thể bằng tiếng Pháp. Mã sẽ giống như sau:
Select p.product_name_FR, p.description_FR, p.price, c.name_FR, c.address_FR, c.contact_name from order_line o, product p, customer c Where o.product_id = p.id and o.customer_id = c.id And id =;
Nhược điểm
- Không có khả năng mở rộng:mỗi khi một ngôn ngữ mới được thêm vào, hàng chục cột bổ sung cần được thêm vào trên các bảng.
- Việc này có thể tốn nhiều thời gian, đặc biệt nếu nhiều trường cần có nhiều ngôn ngữ.
-
Các nhà phát triển kết thúc việc viết truy vấn được hiển thị bên dưới để quản lý tất cả các ngôn ngữ hiện có. Vì vậy, tất cả SQL trong ứng dụng của bạn phải thay đổi khi một ngôn ngữ mới được giới thiệu. ( Lưu ý:
@in_languagebiểu thị ngôn ngữ hiện tại của ứng dụng; tham số này đến từ giao diện người dùng của ứng dụng, trong khi giao diện người dùng đang truy xuất bản ghi.)SELECT CASE @in_language WHEN ‘FR’ THEN p.product_name_FR WHEN ‘DE’ THEN p.product_name_DE DEFAULT THEN p.product_name_EN, p.price, CASE @in_language WHEN ‘FR’ THEN c.name_FR WHEN ‘DE’ THEN c.name_DE DEFAULT THEN c.name_EN, c.contact_name FROM order_line o, product p, customer c WHERE o.product_id = p.id AND o.customer_id = c.id AND id =;
Phương pháp tiếp cận 2 - Tạo một bảng riêng biệt cho văn bản đã dịch
Trong cách tiếp cận này, một bảng riêng biệt được sử dụng để lưu trữ văn bản đã dịch; trong ví dụ bên dưới, chúng tôi đã gọi bảng này là translation . Nó chứa một cột cho mỗi ngôn ngữ. Các giá trị đã được dịch từ các giá trị trường sang tất cả các ngôn ngữ áp dụng được lưu trữ dưới dạng bản ghi. Thay vì lưu trữ văn bản đã dịch thực tế trong các bảng bên dưới, chúng tôi lưu trữ tham chiếu của nó tới translation bàn. Việc triển khai này cho phép chúng tôi tạo một kho lưu trữ văn bản đã dịch chung mà không cần thực hiện quá nhiều thay đổi đối với mô hình dữ liệu hiện có.
Ưu điểm
- Đó là một cách tiếp cận tốt nếu quá trình bản địa hóa được triển khai trên một mô hình dữ liệu hiện có.
- Một cột bổ sung duy nhất trong
translationbảng là sự thay đổi duy nhất cần thiết khi một ngôn ngữ mới được giới thiệu. - Khi văn bản gốc giống nhau giữa các bảng, không có văn bản được dịch thừa. Ví dụ:giả sử tên khách hàng và tên sản phẩm giống hệt nhau. Trong trường hợp này, chỉ một bản ghi sẽ được chèn vào bảng dịch và cùng một bản ghi được tham chiếu trong cả
customervàproductbảng.
Nhược điểm
- Nó vẫn yêu cầu thay đổi mô hình dữ liệu.
- Có thể có NULL không cần thiết trong bảng. Nếu chỉ cần 1.000 trường cho một ngôn ngữ được hỗ trợ, bạn sẽ tạo ra 1.000 bản ghi - và rất nhiều NULL.
-
Sự phức tạp của việc viết SQL tăng lên khi số lượng các phép nối tăng lên. Và khi có nhiều bản ghi trong
translationbảng, thời gian truy xuất chậm hơn.Hãy viết lại câu lệnh SQL cho vấn đề quản lý ngôn ngữ:
SELECT CASE @in_language WHEN ‘FR’ THEN tp.text_FR WHEN ‘DE’ THEN tp.text_DE DEFAULT THEN p.product_name_EN, p.price, CASE @in_language WHEN ‘FR’ THEN tc.text_FR WHEN ‘DE’ THEN tc.text_DE DEFAULT THEN c.name_EN, c.contact_name FROM order_line o, product p, customer c, translation tp, translation tc WHERE o.product_id = p.id AND o.customer_id = c.id AND p.name_translation_id = tp.id AND c.name_translation_id = tc.id AND id =;
Một biến thể trong phương pháp tiếp cận bảng dịch
Để có được hiệu suất tốt hơn khi văn bản đã dịch đang được truy xuất, chúng tôi có thể tách translation bảng thành nhiều bảng. Chúng tôi có thể nhóm các bản ghi dựa trên miền, tức là một bảng cho customer , một cái khác cho product , v.v.
Cách tiếp cận 3 - Bảng dịch với các hàng cho mỗi ngôn ngữ
Cách triển khai này khá giống với cách tiếp cận thứ hai, nhưng nó lưu trữ các giá trị cho văn bản đã dịch theo hàng chứ không phải cột. Đây, translation id bảng vẫn giữ nguyên đối với một giá trị trường trong bất kỳ ngôn ngữ đã dịch nào. Khóa chính tổng hợp {id , language_id } được lưu trữ trong bảng dịch và nó lưu trữ cùng một translation_id cho mỗi trường so với nhiều language_id .
Ưu điểm
- Việc triển khai này cho phép các nhà phát triển viết các SQL truy xuất dữ liệu khá dễ dàng.
- Viết OEM cho mô hình này cũng dễ dàng.
- Không cần thay đổi mô hình dữ liệu khi bạn thêm ngôn ngữ mới; chỉ cần chèn các bản ghi cho ngôn ngữ mới.
- Không tiêu tốn bộ nhớ không cần thiết khi một nhóm trường không áp dụng cho một ngôn ngữ.
-
Giảm độ phức tạp của SQL truy xuất dữ liệu. Hãy xem ví dụ dưới đây:
SELECT tp.text, p.price, tc.text, c.contact_name FROM order_line o, product p, customer c, translation tp, translation tc, language l WHERE o.product_id = p.id AND o.customer_id = c.id AND p.name_translation_id = tp.id AND c.name_translation_id = tc.id AND tp.language_id = l.id AND tc.language_id = l.id AND l.name = @in_language AND id =;
Nhược điểm
- Cần có số lượng liên kết tương đối cao để truy xuất dữ liệu đã dịch.
- Theo thời gian, một số lượng lớn bản ghi có thể được lưu trữ trong
translationbàn. Vì chỉ có một bảng dịch nên tất cả văn bản đã dịch sẽ được đưa vào đó. Khi bạn có hàng triệu trường cần dịch và ứng dụng của bạn hỗ trợ một số lượng lớn ngôn ngữ, thì việc truy vấn một bảng để dịch sẽ là một hoạt động tốn nhiều thời gian. Tuy nhiên, bạn có thể chia bảng dịch dựa trên ngôn ngữ hoặc lĩnh vực chủ đề, như chúng tôi đã chỉ ra ở phần cuối của phương pháp thứ hai.
Điều gì xảy ra nếu chúng ta kết hợp các phương pháp tiếp cận 2 và 3?
Cụ thể, chúng tôi sẽ kết hợp biến thể của Phương pháp tiếp cận 2 - tách translation bảng - với ý tưởng sử dụng các hàng trong một bảng. Chúng tôi có thể dễ dàng khắc phục nhược điểm của việc có nhiều bản ghi trong translation bằng cách tạo nhiều bảng dựa trên một miền, giống như chúng tôi đã làm trong biến thể Phương pháp tiếp cận 2. Nếu có một số lượng đáng kể các bản ghi trong bảng dịch dựa trên miền, chúng tôi có thể tách các bảng đó ra dựa trên các trường riêng lẻ.
Phương pháp tiếp cận # 4 - Tạo Lớp thực thể cho Trường được dịch và Trường không được dịch
Trong giải pháp này, các bảng thực thể có chứa một hoặc nhiều trường đã dịch được chia thành hai lớp:một cho các trường đã dịch và một cho các trường chưa dịch. Bằng cách này, chúng tôi tạo các lớp riêng biệt cho mỗi lớp.
Ưu điểm
- Không cần tham gia các bảng dịch nếu chỉ liên quan đến các trường không được dịch. Do đó, các trường không được dịch sẽ có hiệu suất tốt hơn.
- Cần có số lượng liên kết tương đối ít hơn để truy xuất văn bản đã dịch.
- Viết OEM thật dễ dàng.
- SQL để truy xuất văn bản đã dịch rất đơn giản.
- Đây là một phương pháp đã được chứng minh để kết hợp nhiều ngôn ngữ giữa các thực thể.
Để chứng minh quan điểm, đây là một truy vấn mẫu sẽ truy xuất văn bản đã dịch:
SELECT pt.product_name, pt.description, p.price
FROM order_line o, product p, product_translation pt, language l
WHERE o.product_id = p.id AND
AND p.id = pt.product_non_trans_id
AND pt.language_id = l.id
AND l.name = @in_language
AND id = ;
Bản địa hóa - Vượt xa Bản dịch Nội dung
Bản địa hóa không chỉ là dịch nội dung ứng dụng của bạn sang một ngôn ngữ khác. Có những thông số văn hóa và chức năng cũng cần được quan tâm. Ví dụ:giá trị ngày được định dạng là ‘MM / DD / YYYY’ ở Bắc Mỹ, nhưng ở hầu hết châu Á, giá trị này được viết là ‘DD / MM / YYYY’.
Một ví dụ khác liên quan đến việc hiển thị tên trên tiêu đề ứng dụng. Ở Mỹ, việc gọi ai đó bằng tên của họ được chấp nhận hoặc thậm chí được ưu tiên hơn; Trong nền văn hóa này, tên của khách hàng được hiển thị trên tiêu đề ngay sau khi khách hàng đăng nhập. Tuy nhiên, ở Nhật Bản, mọi thứ lại ngược lại:gọi ai đó bằng tên của họ là bất lịch sự hoặc thậm chí là xúc phạm. Bản địa hóa sẽ tính đến điều này và tránh việc sử dụng tên riêng cho đối tượng người Nhật của ứng dụng.
Các thông số bản địa hóa có thể cần được lưu trữ ở phần cuối của ứng dụng. Đây là trường hợp rất phổ biến khi bạn phải thiết kế một số logic chương trình xung quanh bản địa hóa. Chúng ta có thể phân loại tất cả các tham số như vậy thành các danh mục văn hóa và chức năng, đồng thời xây dựng mô hình dữ liệu xung quanh chúng.
Thêm một suy nghĩ về bản địa hóa
Nội địa hóa là cần thiết khi một thương hiệu toàn cầu thâm nhập vào thị trường địa phương. Để bản địa hóa một ứng dụng, hãy nhìn vào bức tranh lớn. Nội địa hóa không chỉ là hiệu suất hoàn hảo về mặt kỹ thuật. Nó cũng có nghĩa là phải thông thạo văn hóa địa phương, hành vi, và thậm chí cả cách suy nghĩ và cách sống.
Có thể làm gì khác để làm cho một ứng dụng có thể thích ứng cục bộ? Cho chúng tôi biết suy nghĩ của bạn trong các ý kiến.