Cơ sở dữ liệu được thiết kế theo nhiều cách khác nhau. Hầu hết thời gian chúng ta có thể sử dụng "ví dụ trường học":bình thường hóa cơ sở dữ liệu và mọi thứ sẽ hoạt động tốt. Nhưng có những tình huống sẽ yêu cầu một cách tiếp cận khác. Chúng tôi có thể xóa các tham chiếu để có được sự linh hoạt hơn. Nhưng điều gì sẽ xảy ra nếu chúng ta phải cải thiện hiệu suất khi mọi thứ đã được thực hiện bởi cuốn sách? Trong trường hợp đó, không chuẩn hóa là một kỹ thuật mà chúng ta nên xem xét. Trong bài viết này, chúng ta sẽ thảo luận về những lợi ích và bất lợi của việc không chuẩn hóa và những tình huống nào có thể đảm bảo điều đó.
Chuẩn hóa là gì?
Chuẩn hóa là một chiến lược được sử dụng trên cơ sở dữ liệu đã được chuẩn hóa trước đó để tăng hiệu suất. Ý tưởng đằng sau nó là thêm dữ liệu thừa vào những nơi mà chúng tôi nghĩ rằng nó sẽ giúp ích cho chúng tôi nhiều nhất. Chúng ta có thể sử dụng các thuộc tính bổ sung trong bảng hiện có, thêm bảng mới hoặc thậm chí tạo các phiên bản của bảng hiện có. Mục tiêu thông thường là giảm thời gian chạy của các truy vấn được chọn bằng cách làm cho dữ liệu dễ truy cập hơn đối với các truy vấn hoặc bằng cách tạo báo cáo tóm tắt trong các bảng riêng biệt. Quá trình này có thể mang lại một số vấn đề mới và chúng ta sẽ thảo luận sau.
Cơ sở dữ liệu chuẩn hóa là điểm khởi đầu cho quá trình không chuẩn hóa. Điều quan trọng là phải phân biệt cơ sở dữ liệu chưa được chuẩn hóa và cơ sở dữ liệu đã được chuẩn hóa trước rồi sau đó không được chuẩn hóa sau. Cái thứ hai là được; đầu tiên thường là kết quả của thiết kế cơ sở dữ liệu tồi hoặc thiếu kiến thức.
Ví dụ:Mô hình chuẩn hóa cho CRM rất đơn giản
Mô hình dưới đây sẽ là ví dụ của chúng tôi:
Hãy xem nhanh các bảng:
-
user_accountbảng lưu trữ dữ liệu về những người dùng đăng nhập vào ứng dụng của chúng tôi (đơn giản hóa mô hình, vai trò và quyền người dùng bị loại trừ khỏi bảng). -
clientbảng chứa một số dữ liệu cơ bản về khách hàng của chúng tôi. -
productbảng liệt kê các sản phẩm được cung cấp cho khách hàng của chúng tôi. -
taskbảng chứa tất cả các tác vụ chúng tôi đã tạo. Bạn có thể coi mỗi nhiệm vụ như một tập hợp các hành động liên quan đến khách hàng. Mỗi nhiệm vụ đều có các cuộc gọi, cuộc họp liên quan và danh sách các sản phẩm được cung cấp và bán. -
callvàmeetingbảng lưu trữ dữ liệu về tất cả các cuộc gọi và cuộc họp, đồng thời liên hệ chúng với các nhiệm vụ và người dùng. - Từ điển
task_outcome,meeting_outcomevàcall_outcomechứa tất cả các tùy chọn có thể có cho trạng thái cuối cùng của nhiệm vụ, cuộc họp hoặc cuộc gọi. -
product_offeredlưu trữ danh sách tất cả các sản phẩm đã được cung cấp cho khách hàng trong một số tác vụ nhất định trong khiproduct_soldchứa danh sách tất cả các sản phẩm mà khách hàng đã thực sự mua. -
supply_orderbảng lưu trữ dữ liệu về tất cả các đơn hàng chúng tôi đã đặt vàproducts_on_orderbảng liệt kê các sản phẩm và số lượng của chúng cho các đơn đặt hàng cụ thể. -
writeoffbảng là danh sách các sản phẩm đã bị xóa do tai nạn hoặc tương tự (ví dụ:gương vỡ).
Cơ sở dữ liệu được đơn giản hóa nhưng nó được chuẩn hóa hoàn toàn. Bạn sẽ không tìm thấy bất kỳ sự dư thừa nào và nó sẽ thực hiện công việc. Chúng tôi sẽ không gặp bất kỳ sự cố hiệu suất nào trong bất kỳ trường hợp nào, miễn là chúng tôi làm việc với một lượng dữ liệu tương đối nhỏ.
Khi nào và Tại sao sử dụng Chuẩn hóa
Như với hầu hết mọi thứ, bạn phải chắc chắn lý do tại sao bạn muốn áp dụng bất chuẩn hóa. Bạn cũng cần chắc chắn rằng lợi nhuận từ việc sử dụng nó lớn hơn bất kỳ tác hại nào. Có một vài tình huống mà bạn chắc chắn nên nghĩ đến việc không chuẩn hóa:
- Duy trì lịch sử: Dữ liệu có thể thay đổi theo thời gian và chúng ta cần lưu trữ các giá trị hợp lệ khi tạo bản ghi. Chúng tôi muốn nói đến những loại thay đổi nào? Họ và tên của một người có thể thay đổi; khách hàng cũng có thể thay đổi tên doanh nghiệp của họ hoặc bất kỳ dữ liệu nào khác. Chi tiết nhiệm vụ phải chứa các giá trị thực tế tại thời điểm tác vụ được tạo. Chúng tôi sẽ không thể tạo lại dữ liệu trong quá khứ một cách chính xác nếu điều này không xảy ra. Chúng tôi có thể giải quyết vấn đề này bằng cách thêm một bảng chứa lịch sử của những thay đổi này. Trong trường hợp đó, một truy vấn chọn trả về nhiệm vụ và tên máy khách hợp lệ sẽ trở nên phức tạp hơn. Có lẽ một chiếc bàn phụ không phải là giải pháp tốt nhất.
- Cải thiện hiệu suất truy vấn: Một số truy vấn có thể sử dụng nhiều bảng để truy cập dữ liệu mà chúng tôi thường xuyên cần. Hãy nghĩ đến tình huống chúng ta cần ghép 10 bàn để trả lại tên của khách hàng và các sản phẩm đã bán cho họ. Một số bảng dọc theo đường dẫn cũng có thể chứa một lượng lớn dữ liệu. Trong trường hợp đó, có lẽ sẽ là khôn ngoan nếu thêm
client_idthuộc tính trực tiếp choproducts_soldbảng. - Tăng tốc độ báo cáo: Chúng tôi cần một số thống kê nhất định rất thường xuyên. Việc tạo chúng từ dữ liệu trực tiếp khá tốn thời gian và có thể ảnh hưởng đến hiệu suất tổng thể của hệ thống. Giả sử chúng tôi muốn theo dõi doanh số bán hàng của khách hàng trong những năm nhất định cho một số hoặc tất cả khách hàng. Việc tạo ra các báo cáo như vậy từ dữ liệu trực tiếp sẽ "đào" gần như trong toàn bộ cơ sở dữ liệu và làm chậm đi rất nhiều. Và điều gì sẽ xảy ra nếu chúng ta sử dụng thống kê đó thường xuyên?
- Tính toán trước các giá trị thường cần thiết: Chúng tôi muốn tính toán sẵn một số giá trị để không phải tạo chúng trong thời gian thực.
Điều quan trọng là chỉ ra rằng bạn không cần sử dụng chức năng không chuẩn hóa nếu không có vấn đề về hiệu suất trong ứng dụng. Nhưng nếu bạn nhận thấy hệ thống đang chậm lại - hoặc nếu bạn biết rằng điều này có thể xảy ra - thì bạn nên nghĩ đến việc áp dụng kỹ thuật này. Tuy nhiên, trước khi tiếp tục, hãy xem xét các tùy chọn khác, như tối ưu hóa truy vấn và lập chỉ mục thích hợp. Bạn cũng có thể sử dụng chức năng không chuẩn hóa nếu bạn đang trong quá trình sản xuất nhưng tốt hơn là giải quyết các vấn đề trong giai đoạn phát triển.
Nhược điểm của Chuẩn hóa là gì?
Rõ ràng, lợi thế lớn nhất của quá trình không chuẩn hóa là tăng hiệu suất. Nhưng chúng ta phải trả giá cho nó, và giá đó có thể bao gồm:
- Dung lượng đĩa: Điều này được mong đợi, vì chúng tôi sẽ có dữ liệu trùng lặp.
- Sự bất thường về dữ liệu: Chúng ta phải nhận thức được thực tế rằng dữ liệu hiện có thể được thay đổi ở nhiều nơi. Chúng tôi phải điều chỉnh từng phần dữ liệu trùng lặp cho phù hợp. Điều đó cũng áp dụng cho các giá trị và báo cáo được tính toán. Chúng ta có thể đạt được điều này bằng cách sử dụng trình kích hoạt, giao dịch và / hoặc thủ tục cho tất cả các hoạt động phải được hoàn thành cùng nhau.
- Tài liệu: Chúng tôi phải ghi lại đúng mọi quy tắc không chuẩn hóa mà chúng tôi đã áp dụng. Nếu chúng tôi sửa đổi thiết kế cơ sở dữ liệu sau đó, chúng tôi sẽ phải xem xét tất cả các ngoại lệ của mình và xem xét chúng một lần nữa. Có lẽ chúng tôi không cần chúng nữa vì chúng tôi đã giải quyết được vấn đề. Hoặc có thể chúng ta cần thêm vào các quy tắc không chuẩn hóa hiện có. (Ví dụ:Chúng tôi đã thêm một thuộc tính mới vào bảng khách hàng và chúng tôi muốn lưu trữ giá trị lịch sử của nó cùng với mọi thứ chúng tôi đã lưu trữ. Chúng tôi sẽ phải thay đổi các quy tắc tiêu chuẩn hóa hiện có để đạt được điều đó).
- Làm chậm các hoạt động khác: Chúng tôi có thể mong đợi rằng chúng tôi sẽ làm chậm các hoạt động chèn, sửa đổi và xóa dữ liệu. Nếu những hoạt động này xảy ra tương đối hiếm khi xảy ra, thì đây có thể là một lợi ích. Về cơ bản, chúng tôi sẽ chia một lựa chọn chậm thành một số lượng lớn hơn các truy vấn chèn / cập nhật / xóa chậm hơn. Mặc dù một truy vấn lựa chọn rất phức tạp về mặt kỹ thuật có thể làm chậm toàn bộ hệ thống một cách đáng kể, nhưng việc làm chậm nhiều hoạt động “nhỏ hơn” sẽ không làm hỏng khả năng sử dụng của ứng dụng của chúng tôi.
- Viết mã nhiều hơn: Quy tắc 2 và 3 sẽ yêu cầu mã hóa bổ sung, nhưng đồng thời chúng sẽ đơn giản hóa một số truy vấn chọn lọc rất nhiều. Nếu chúng tôi đang không chuẩn hóa cơ sở dữ liệu hiện có, chúng tôi sẽ phải sửa đổi các truy vấn chọn lọc này để có được những lợi ích cho công việc của chúng tôi. Chúng tôi cũng sẽ phải cập nhật các giá trị trong các thuộc tính mới được thêm vào cho các bản ghi hiện có. Điều này cũng sẽ yêu cầu viết mã nhiều hơn một chút.
Mô hình mẫu, được chuẩn hóa
Trong mô hình bên dưới, tôi đã áp dụng một số quy tắc không chuẩn hóa nói trên. Bảng màu hồng đã được sửa đổi, trong khi bảng màu xanh lam nhạt là bảng hoàn toàn mới.
Những thay đổi nào được áp dụng và tại sao?

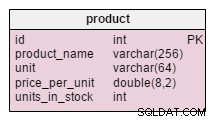
Thay đổi duy nhất trong product bảng là sự bổ sung của units_in_stock thuộc tính. Trong mô hình chuẩn hóa, chúng tôi có thể tính toán dữ liệu này dưới dạng đơn vị đã đặt hàng - đơn vị đã bán - (đơn vị được cung cấp) - đơn vị bị xóa sổ . Chúng tôi sẽ lặp lại phép tính mỗi khi khách hàng yêu cầu sản phẩm đó, điều này sẽ cực kỳ mất thời gian. Thay vào đó, chúng tôi sẽ tính toán trước giá trị; khi khách hàng hỏi chúng tôi, chúng tôi sẽ chuẩn bị sẵn sàng. Tất nhiên, điều này đơn giản hóa truy vấn chọn rất nhiều. Mặt khác, units_in_stock thuộc tính phải được điều chỉnh sau mỗi lần chèn, cập nhật hoặc xóa trong products_on_order , writeoff , product_offered và product_sold bảng.
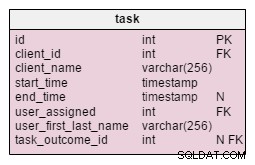
Trong task bảng, chúng tôi tìm thấy hai thuộc tính mới:client_name và user_first_last_name . Cả hai đều lưu trữ các giá trị khi tác vụ được tạo. Lý do là cả hai giá trị này có thể thay đổi theo thời gian. Chúng tôi cũng sẽ giữ một khóa ngoại liên quan đến chúng với ID người dùng và ứng dụng khách ban đầu. Có nhiều giá trị khác mà chúng tôi muốn lưu trữ, như địa chỉ khách hàng, ID VAT, v.v.




product_offered bảng có hai thuộc tính mới, price_per_unit và price . price_per_unit thuộc tính được lưu trữ vì chúng tôi cần lưu trữ giá thực tế khi sản phẩm được cung cấp . Mô hình chuẩn hóa sẽ chỉ hiển thị trạng thái hiện tại của nó, vì vậy khi giá sản phẩm thay đổi, giá 'lịch sử' của chúng tôi cũng sẽ thay đổi. Thay đổi của chúng tôi không chỉ làm cho cơ sở dữ liệu chạy nhanh hơn mà còn làm cho nó hoạt động tốt hơn. price thuộc tính là giá trị được tính toán units_sold * price_per_unit . Tôi đã thêm nó vào đây để tránh thực hiện phép tính đó mỗi khi chúng tôi muốn xem danh sách các sản phẩm được cung cấp. Đó là một chi phí nhỏ, nhưng nó cải thiện hiệu suất.
Các thay đổi được thực hiện trên product_sold bảng rất giống nhau. Cấu trúc bảng giống nhau, nhưng nó lưu trữ danh sách các mặt hàng đã bán.
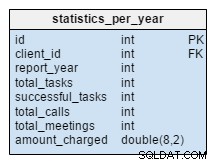
statistics_per_year bảng hoàn toàn mới đối với mô hình của chúng tôi. Chúng ta nên xem nó như một bảng không chuẩn hóa vì tất cả dữ liệu của nó có thể được tính toán từ các bảng khác. Ý tưởng đằng sau bảng này là lưu trữ số lượng nhiệm vụ, nhiệm vụ thành công, cuộc họp và cuộc gọi liên quan đến bất kỳ khách hàng nhất định nào. Nó cũng xử lý tổng số tiền được tính mỗi năm. Sau khi chèn, cập nhật hoặc xóa bất kỳ thứ gì trong task , meeting , call và product_sold , chúng tôi nên tính toán lại dữ liệu của bảng này cho khách hàng đó và năm tương ứng. Chúng tôi có thể mong đợi rằng hầu hết chúng tôi sẽ chỉ có những thay đổi cho năm hiện tại. Các báo cáo cho những năm trước không cần thay đổi.
Các giá trị trong bảng này được tính toán trước, vì vậy, chúng tôi sẽ dành ít thời gian và tài nguyên hơn vào lúc cần kết quả tính toán. Hãy nghĩ về những giá trị bạn sẽ cần thường xuyên. Có thể bạn sẽ không thường xuyên cần đến tất cả chúng và có thể mạo hiểm tính toán một số trong số chúng còn sống.
Chuẩn hóa là một khái niệm rất thú vị và mạnh mẽ. Mặc dù đây không phải là điều đầu tiên bạn cần lưu ý để cải thiện hiệu suất, nhưng trong một số trường hợp, đó có thể là giải pháp tốt nhất hoặc thậm chí là duy nhất.
Trước khi bạn chọn sử dụng chức năng không chuẩn hóa, hãy chắc chắn rằng bạn muốn nó. Thực hiện một số phân tích và theo dõi hiệu suất. Bạn có thể sẽ quyết định sử dụng chức năng không chuẩn hóa sau khi bạn đã phát trực tiếp. Đừng ngại sử dụng nó, nhưng hãy theo dõi các thay đổi và bạn sẽ không gặp bất kỳ sự cố nào (tức là các dị thường dữ liệu đáng sợ).