Trong bài viết này, tôi tiếp tục đề cập đến các giải pháp cho sự kết hợp hấp dẫn giữa cung và cầu của Peter Larsson. Một lần nữa, xin cảm ơn Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie và Peter Larsson, vì đã gửi các giải pháp của bạn.
Tháng trước, tôi đã đề cập đến một giải pháp dựa trên các giao lộ ngắt quãng, sử dụng một thử nghiệm giao lộ ngắt quãng dựa trên vị từ cổ điển. Tôi sẽ gọi giải pháp đó là nút giao thông cổ điển . Phương pháp tiếp cận các giao điểm theo khoảng cổ điển dẫn đến một kế hoạch với tỷ lệ bậc hai (N ^ 2). Tôi đã chứng minh hiệu suất kém của nó so với các đầu vào mẫu khác nhau, từ 100K đến 400K hàng. Giải pháp đã mất 931 giây để hoàn thành so với đầu vào 400K hàng! Tháng này, tôi sẽ bắt đầu bằng cách nhắc bạn một cách ngắn gọn về giải pháp của tháng trước và lý do tại sao giải pháp đó lại thay đổi quy mô và hoạt động kém như vậy. Sau đó, tôi sẽ giới thiệu một cách tiếp cận dựa trên bản sửa đổi cho bài kiểm tra giao nhau giữa các quãng. Cách tiếp cận này đã được sử dụng bởi Luca, Kamil, và có thể cả Daniel, và nó cho phép một giải pháp có hiệu suất và khả năng mở rộng tốt hơn nhiều. Tôi sẽ gọi giải pháp đó là nút giao đã sửa đổi .
Vấn đề với Kiểm tra Giao lộ Cổ điển
Hãy bắt đầu với lời nhắc nhanh về giải pháp của tháng trước.
Tôi đã sử dụng các chỉ mục sau trên bảng dbo.Auctions đầu vào để hỗ trợ tính toán các tổng đang chạy tạo ra khoảng cung và cầu:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
Đoạn mã sau có giải pháp hoàn chỉnh triển khai phương pháp tiếp cận các nút giao cách quãng cổ điển:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
CREATE UNIQUE CLUSTERED INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S WITH (FORCESEEK)
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; Mã này bắt đầu bằng cách tính toán các khoảng cung và cầu và ghi chúng vào các bảng tạm thời được gọi là #Demand và #Supply. Sau đó, mã này sẽ tạo một chỉ mục theo nhóm trên #Supply với EndSupply là chìa khóa hàng đầu để hỗ trợ kiểm tra giao cắt tốt nhất có thể. Cuối cùng, mã kết hợp #Supply và #Demand, xác định các giao dịch là các phân đoạn chồng chéo của các khoảng giao nhau, sử dụng vị từ nối sau dựa trên thử nghiệm giao nhau giữa các khoảng cổ điển:
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
Kế hoạch cho giải pháp này được thể hiện trong Hình 1.
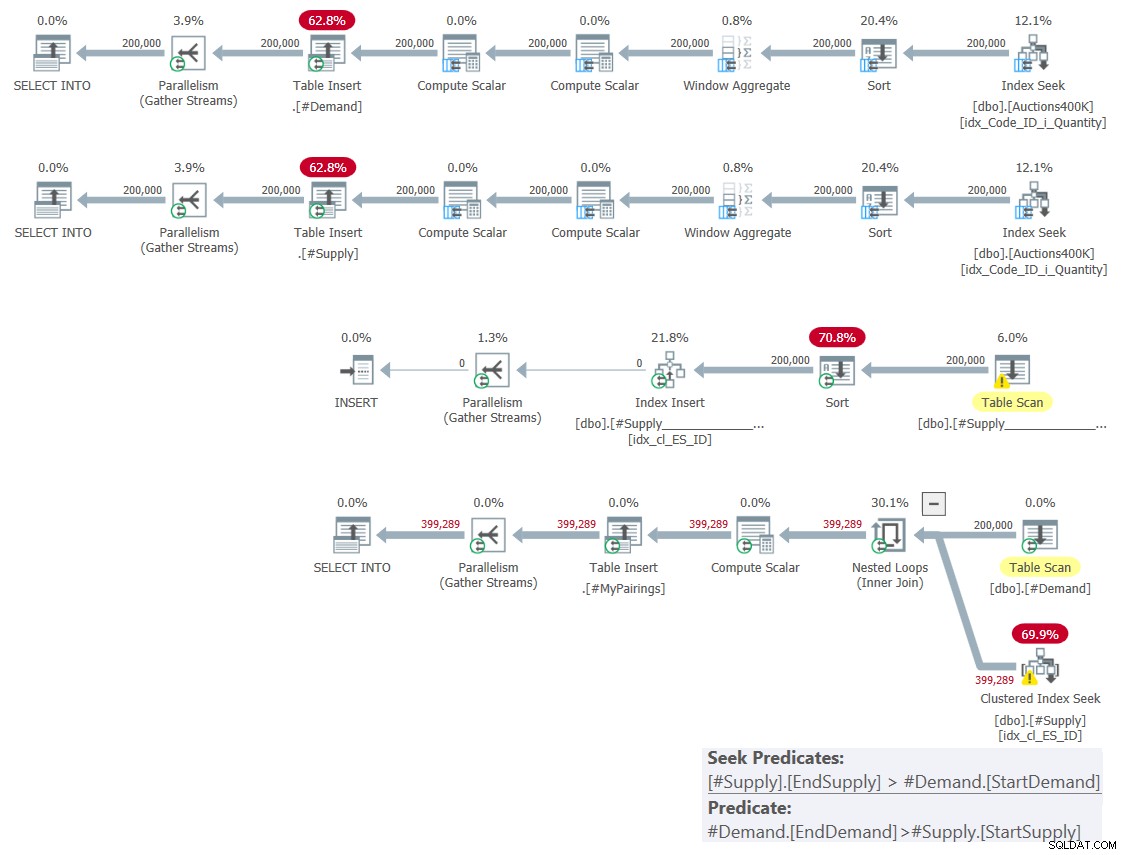 Hình 1:Kế hoạch truy vấn cho giải pháp dựa trên các nút giao thông cổ điển
Hình 1:Kế hoạch truy vấn cho giải pháp dựa trên các nút giao thông cổ điển
Như tôi đã giải thích vào tháng trước, trong số hai vị từ phạm vi có liên quan, chỉ một vị từ có thể được sử dụng làm vị từ tìm kiếm như một phần của hoạt động tìm kiếm chỉ mục, trong khi vị từ còn lại phải được áp dụng làm vị từ dư. Bạn có thể thấy rõ điều này trong sơ đồ cho truy vấn cuối cùng trong Hình 1. Đó là lý do tại sao tôi chỉ bận tâm tạo một chỉ mục trên một trong các bảng. Tôi cũng đã buộc sử dụng tìm kiếm trong chỉ mục mà tôi đã tạo bằng cách sử dụng gợi ý FORCESEEK. Nếu không, trình tối ưu hóa có thể bỏ qua chỉ mục đó và tạo một trong những chỉ mục của riêng nó bằng cách sử dụng toán tử Bộ chỉ mục.
Kế hoạch này có độ phức tạp bậc hai vì mỗi hàng ở một phía— # Cầu trong trường hợp của chúng tôi — tìm kiếm chỉ mục sẽ phải truy cập trung bình một nửa số hàng ở phía bên kia— # Cung trong trường hợp của chúng tôi — dựa trên vị từ tìm kiếm và xác định đối sánh cuối cùng bằng cách áp dụng vị từ còn lại.
Nếu bạn vẫn chưa rõ lý do tại sao kế hoạch này có độ phức tạp bậc hai, có lẽ một mô tả trực quan về công việc có thể hữu ích, như thể hiện trong Hình 2.
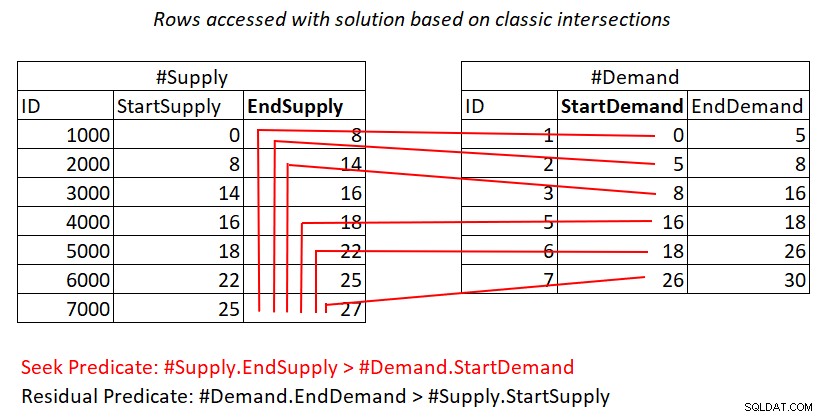 Hình 2:Minh họa công việc với giải pháp dựa trên các nút giao thông cổ điển
Hình 2:Minh họa công việc với giải pháp dựa trên các nút giao thông cổ điển
Hình minh họa này thể hiện công việc được thực hiện bởi tham gia Vòng lặp lồng nhau trong kế hoạch cho truy vấn cuối cùng. #Demand heap là đầu vào bên ngoài của phép nối và chỉ mục nhóm trên #Supply (với EndSupply là khóa hàng đầu) là đầu vào bên trong. Các đường màu đỏ đại diện cho các hoạt động tìm kiếm chỉ mục được thực hiện trên mỗi hàng trong #Demand trong chỉ mục trên #Supply và các hàng mà họ truy cập như một phần của phạm vi quét trong lá chỉ mục. Đối với các giá trị StartDemand cực thấp trong #Demand, quá trình quét phạm vi cần truy cập gần tất cả các hàng trong #Supply. Đối với các giá trị StartDemand cực cao trong #Demand, quá trình quét phạm vi cần truy cập gần bằng 0 hàng trong #Supply. Trung bình, quá trình quét phạm vi cần truy cập vào khoảng một nửa số hàng trong #Supply cho mỗi hàng có nhu cầu. Với D hàng cầu và S hàng cung, số hàng được truy cập là D + D * S / 2. Điều đó cộng với chi phí của những lần tìm kiếm đưa bạn đến các hàng phù hợp. Ví dụ:khi lấp đầy dbo.Auctions với 200.000 hàng cầu và 200.000 hàng cung, điều này có nghĩa là Vòng lặp lồng nhau tham gia truy cập 200.000 hàng cầu + 200.000 * 200.000 / 2 hàng cung cấp hoặc 200.000 + 200.000 ^ 2/2 =20.000.200.000 hàng được truy cập. Có rất nhiều quá trình quét lại các hàng cung ứng đang diễn ra ở đây!
Nếu bạn muốn theo đuổi ý tưởng giao cắt quãng nhưng đạt được hiệu suất tốt, bạn cần nghĩ ra một cách để giảm bớt khối lượng công việc được thực hiện.
Trong giải pháp của mình, Joe Obbish đã đấu giá các khoảng thời gian dựa trên độ dài khoảng thời gian tối đa. Bằng cách này, anh ấy có thể giảm số lượng hàng mà các phép nối cần xử lý và dựa vào quá trình xử lý hàng loạt. Ông đã sử dụng thử nghiệm giao nhau giữa các khoảng cổ điển như một bộ lọc cuối cùng. Giải pháp của Joe hoạt động tốt miễn là độ dài khoảng thời gian tối đa không quá cao, nhưng thời gian chạy của giải pháp tăng lên khi độ dài khoảng thời gian tối đa tăng lên.
Vậy, bạn có thể làm gì khác…?
Kiểm tra nút giao đã sửa đổi
Luca, Kamil và có thể là Daniel (có một phần không rõ ràng về giải pháp đã đăng của anh ấy do định dạng của trang web, vì vậy tôi phải đoán) đã sử dụng thử nghiệm giao nhau giữa các khoảng sửa đổi để cho phép sử dụng lập chỉ mục tốt hơn nhiều.
Kiểm tra giao điểm của chúng là sự tách biệt của hai vị từ (các vị từ được phân tách bằng toán tử OR):
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply >= D.StartDemand AND S.StartSupply < D.EndDemand)
Trong tiếng Anh, hoặc dấu phân cách bắt đầu nhu cầu giao với khoảng cung một cách toàn diện, độc quyền (bao gồm cả phần đầu và không bao gồm phần cuối); hoặc dấu phân cách bắt đầu cung giao với khoảng cầu, theo cách bao trùm, độc quyền. Để làm cho hai vị từ rời rạc (không có các trường hợp chồng chéo) nhưng vẫn hoàn chỉnh trong tất cả các trường hợp, bạn có thể giữ toán tử =chỉ trong một hoặc khác, ví dụ:
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand)
Bài kiểm tra giao cắt quãng được sửa đổi này khá sâu sắc. Mỗi vị từ có thể sử dụng một chỉ mục một cách hiệu quả. Xem xét vị từ 1:
D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Giả sử bạn tạo một chỉ mục bao trùm trên #Demand với StartDemand làm khóa hàng đầu, bạn có thể có được một phép tham gia Vòng lặp lồng nhau áp dụng công việc được minh họa trong Hình 3.
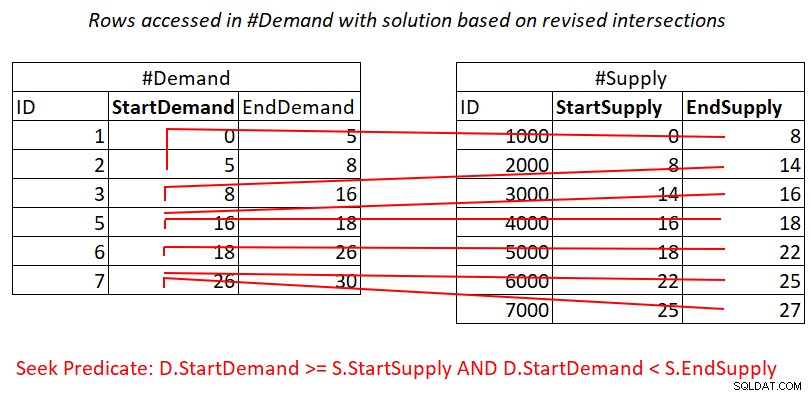
Hình 3:Minh họa các công việc lý thuyết cần thiết để xử lý vị từ 1
Có, bạn vẫn trả tiền cho một tìm kiếm trong chỉ mục #Demand cho mỗi hàng trong #Supply, nhưng phạm vi quét trong quyền truy cập lá chỉ mục gần như tách rời các tập con của các hàng. Không quét lại hàng!
Tình hình tương tự với vị ngữ 2:
S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Giả sử bạn tạo một chỉ mục bao trùm trên #Supply với StartSupply là khóa hàng đầu, bạn có thể có được một tham gia Vòng lặp lồng nhau áp dụng công việc được minh họa trong Hình 4.
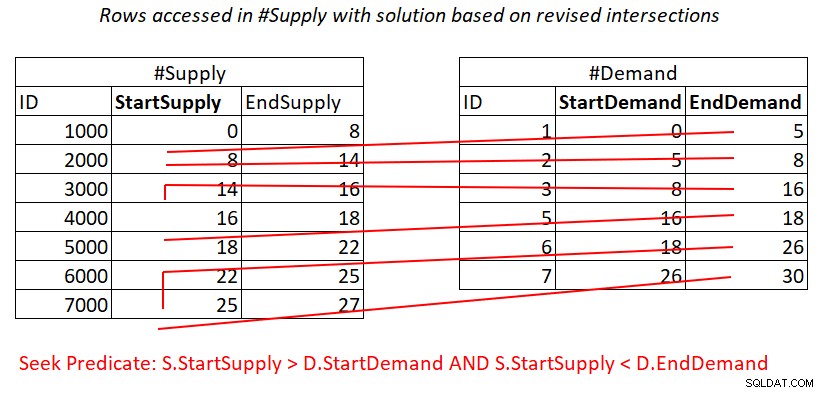
Hình 4:Hình minh họa các công việc lý thuyết cần thiết để xử lý vị từ 2
Ngoài ra, ở đây bạn trả tiền cho một tìm kiếm trong chỉ mục #Supply cho mỗi hàng trong #Demand, sau đó phạm vi quét trong quyền truy cập lá chỉ mục gần như tách rời các tập con của các hàng. Một lần nữa, không cần quét lại hàng!
Giả sử D hàng cầu và hàng cung S, công việc có thể được mô tả như sau:
Number of index seek operations: D + S Number of rows accessed: 2D + 2S
Vì vậy, rất có thể, phần lớn nhất của chi phí ở đây là chi phí I / O liên quan đến các cuộc tìm kiếm. Nhưng phần này của công việc có tỷ lệ tuyến tính so với tỷ lệ bậc hai của truy vấn các giao điểm cổ điển.
Tất nhiên, bạn cần phải xem xét chi phí sơ bộ của việc tạo chỉ mục trên các bảng tạm thời, bảng này có tỷ lệ n log n do liên quan đến việc sắp xếp, nhưng bạn phải trả phần này như một phần sơ bộ của cả hai giải pháp.
Hãy thử và áp dụng lý thuyết này vào thực tế. Hãy bắt đầu bằng cách điền vào bảng #Demand và #supply tạm thời với các khoảng cung và cầu (giống như với các giao điểm trong khoảng cổ điển) và tạo các chỉ mục hỗ trợ:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID); Các kế hoạch để điền các bảng tạm thời và tạo các chỉ mục được thể hiện trong Hình 5.
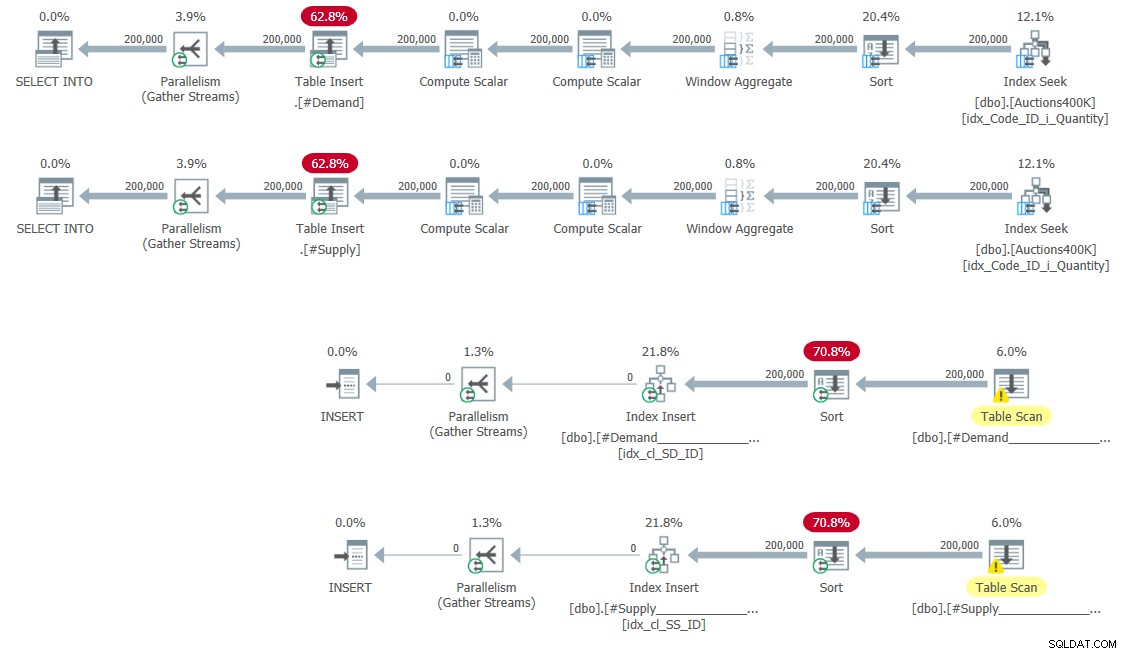
Hình 5:Các kế hoạch truy vấn để tạo và tạo bảng tạm thời chỉ mục
Không có gì ngạc nhiên ở đây.
Bây giờ đến truy vấn cuối cùng. Bạn có thể bị cám dỗ để sử dụng một truy vấn duy nhất với sự tách rời hai vị từ đã nói ở trên, như sau:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON (D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand); Kế hoạch cho truy vấn này được thể hiện trong Hình 6.
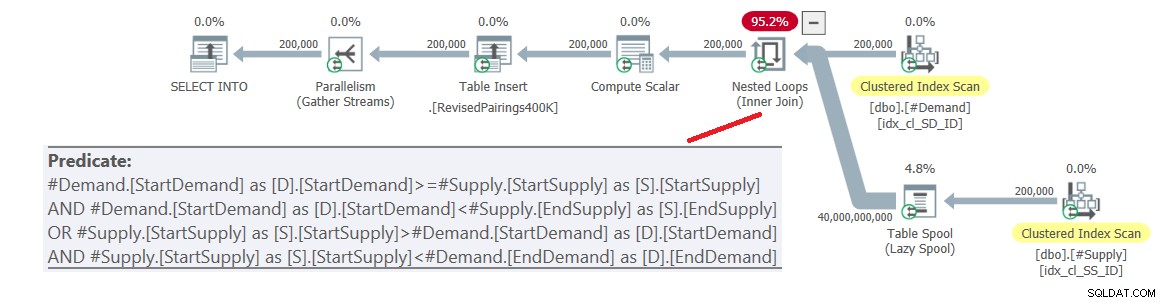
Hình 6:Kế hoạch truy vấn cho truy vấn cuối cùng sử dụng nút giao đã sửa đổi kiểm tra, thử 1
Vấn đề là trình tối ưu hóa không biết cách chia logic này thành hai hoạt động riêng biệt, mỗi hoạt động xử lý một vị từ khác nhau và sử dụng chỉ mục tương ứng một cách hiệu quả. Vì vậy, nó kết thúc với một tích cacte đầy đủ của hai bên, áp dụng tất cả các vị từ là các vị từ dư. Với 200.000 hàng cầu và 200.000 hàng cung cấp, phép liên kết xử lý 40.000.000.000 hàng.
Thủ thuật sâu sắc được sử dụng bởi Luca, Kamil và có thể là Daniel là chia logic thành hai truy vấn, thống nhất kết quả của chúng. Đó là nơi mà việc sử dụng hai vị từ riêng biệt trở nên quan trọng! Bạn có thể sử dụng toán tử UNION ALL thay vì UNION, tránh chi phí tìm kiếm trùng lặp không cần thiết. Đây là truy vấn triển khai phương pháp này:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Kế hoạch cho truy vấn này được thể hiện trong Hình 7.
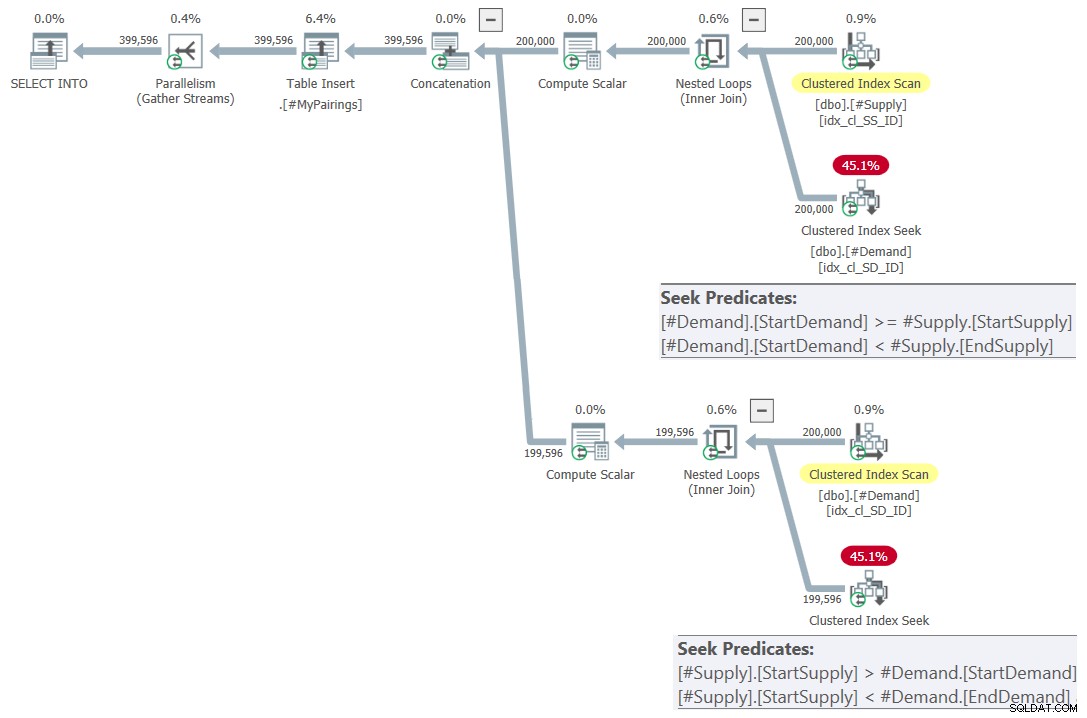
Hình 7:Kế hoạch truy vấn cho truy vấn cuối cùng sử dụng nút giao đã sửa đổi kiểm tra, thử 2
Điều này chỉ là đẹp! Phải không? Và bởi vì nó quá đẹp, đây là toàn bộ giải pháp từ đầu, bao gồm cả việc tạo bảng tạm thời, lập chỉ mục và truy vấn cuối cùng:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Như đã đề cập trước đó, tôi sẽ gọi giải pháp này là nút giao đã sửa đổi .
Giải pháp của Kamil
Giữa các giải pháp của Luca’s, Kamil’s và Daniel’s, Kamil’s là giải pháp nhanh nhất. Đây là giải pháp hoàn chỉnh của Kamil:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #supply, #demand;
GO
CREATE TABLE #demand
(
DemandID INT NOT NULL,
DemandQuantity DECIMAL(19, 6) NOT NULL,
QuantityFromDemand DECIMAL(19, 6) NOT NULL,
QuantityToDemand DECIMAL(19, 6) NOT NULL
);
CREATE TABLE #supply
(
SupplyID INT NOT NULL,
QuantityFromSupply DECIMAL(19, 6) NOT NULL,
QuantityToSupply DECIMAL(19,6) NOT NULL
);
WITH demand AS
(
SELECT
a.ID AS DemandID,
a.Quantity AS DemandQuantity,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromDemand,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToDemand
FROM dbo.Auctions AS a WHERE Code = 'D'
)
INSERT INTO #demand
(
DemandID,
DemandQuantity,
QuantityFromDemand,
QuantityToDemand
)
SELECT
d.DemandID,
d.DemandQuantity,
d.QuantityFromDemand,
d.QuantityToDemand
FROM demand AS d;
WITH supply AS
(
SELECT
a.ID AS SupplyID,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromSupply,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToSupply
FROM dbo.Auctions AS a WHERE Code = 'S'
)
INSERT INTO #supply
(
SupplyID,
QuantityFromSupply,
QuantityToSupply
)
SELECT
s.SupplyID,
s.QuantityFromSupply,
s.QuantityToSupply
FROM supply AS s;
CREATE UNIQUE INDEX ix_1 ON #demand(QuantityFromDemand)
INCLUDE(DemandID, DemandQuantity, QuantityToDemand);
CREATE UNIQUE INDEX ix_1 ON #supply(QuantityFromSupply)
INCLUDE(SupplyID, QuantityToSupply);
CREATE NONCLUSTERED COLUMNSTORE INDEX nci ON #demand(DemandID)
WHERE DemandID is null;
DROP TABLE IF EXISTS #myPairings;
CREATE TABLE #myPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
INSERT INTO #myPairings(DemandID, SupplyID, TradeQuantity)
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 end
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #demand AS d
INNER JOIN #supply AS s
ON (d.QuantityFromDemand < s.QuantityToSupply
AND s.QuantityFromSupply <= d.QuantityFromDemand)
UNION ALL
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 END
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #supply AS s
INNER JOIN #demand AS d
ON (s.QuantityFromSupply < d.QuantityToDemand
AND d.QuantityFromDemand < s.QuantityFromSupply); Như bạn có thể thấy, nó rất gần với giải pháp nút giao đã sửa đổi mà tôi đã đề cập.
Kế hoạch cho truy vấn cuối cùng trong giải pháp của Kamil được thể hiện trong Hình 8.
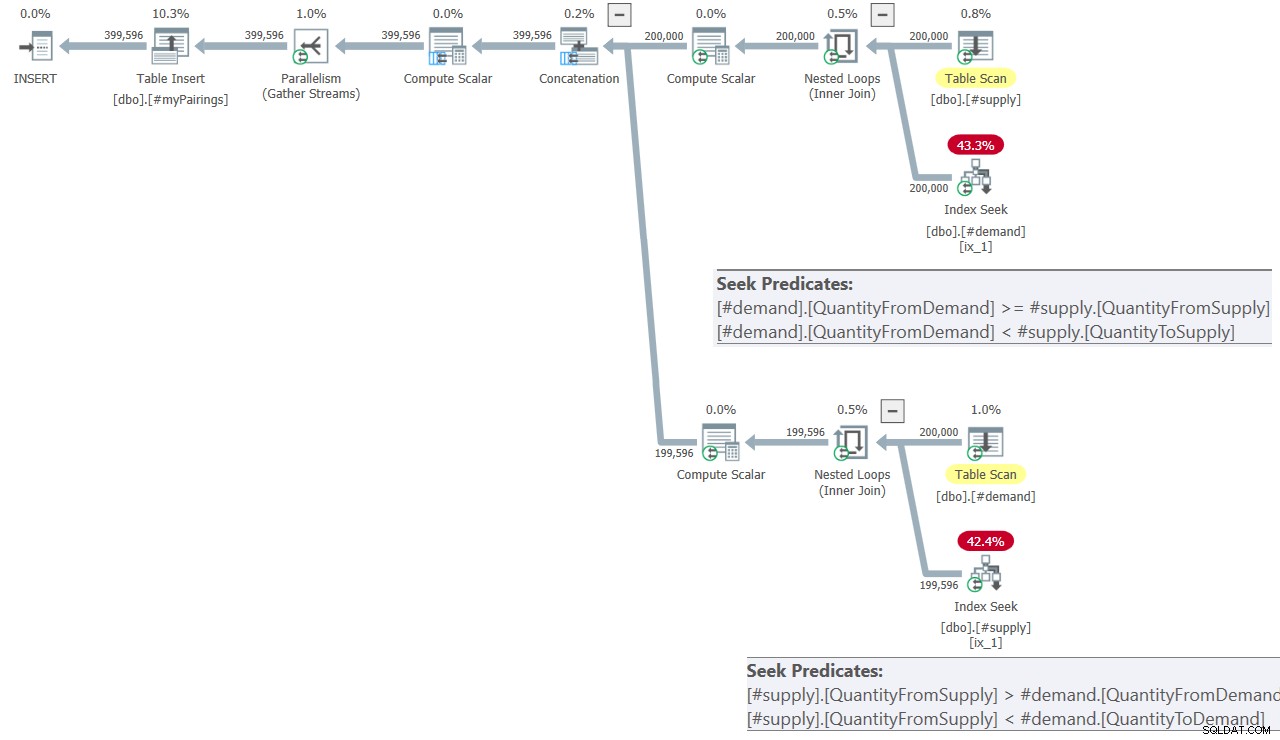
Hình 8:Kế hoạch truy vấn cho truy vấn cuối cùng trong giải pháp của Kamil
Kế hoạch trông khá giống với kế hoạch được hiển thị trước đó trong Hình 7.
Kiểm tra hiệu suất
Nhớ lại rằng giải pháp nút giao thông cổ điển mất 931 giây để hoàn thành so với đầu vào có 400K hàng. Đó là 15 phút! Nó tệ hơn rất nhiều so với giải pháp con trỏ, mất khoảng 12 giây để hoàn thành với cùng một đầu vào. Hình 9 có các số hiệu suất bao gồm các giải pháp mới được thảo luận trong bài viết này.
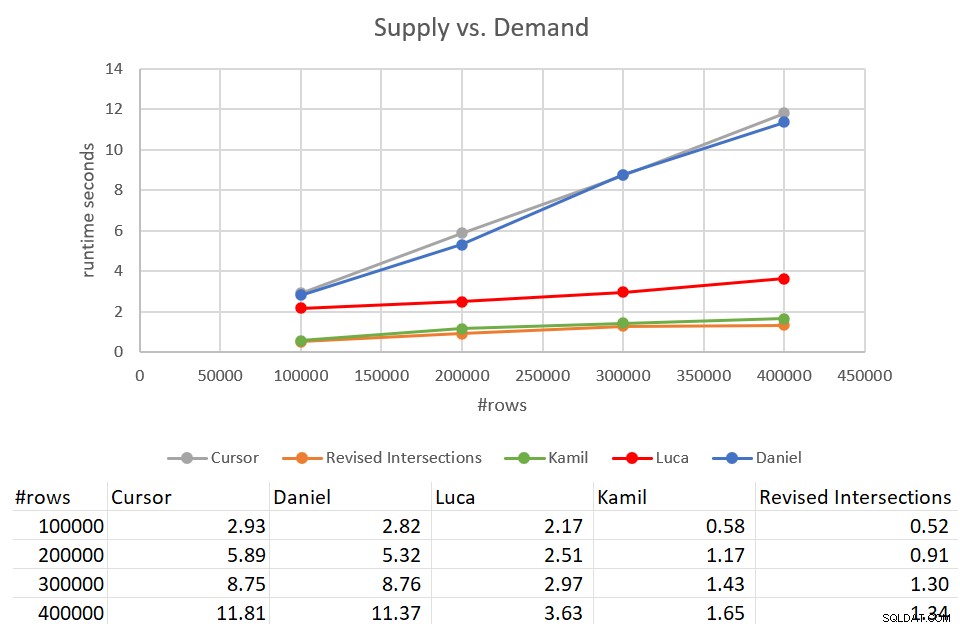
Hình 9:Kiểm tra hiệu suất
Như bạn có thể thấy, giải pháp của Kamil và giải pháp nút giao đã sửa đổi tương tự mất khoảng 1,5 giây để hoàn thành so với đầu vào 400K hàng. Đó là một cải tiến khá tốt so với giải pháp dựa trên con trỏ ban đầu. Hạn chế chính của các giải pháp này là chi phí I / O. Với một lần tìm kiếm trên mỗi hàng, đối với đầu vào 400K hàng, các giải pháp này thực hiện vượt quá 1,35M lần đọc. Nhưng nó cũng có thể được coi là một chi phí hoàn toàn có thể chấp nhận được với thời gian chạy tốt và quy mô mà bạn nhận được.
Tiếp theo là gì?
Nỗ lực đầu tiên của chúng tôi trong việc giải quyết thách thức cung và cầu so khớp dựa trên thử nghiệm giao cắt khoảng thời gian cổ điển và nhận được một kế hoạch hoạt động kém với tỷ lệ bậc hai. Tệ hơn nhiều so với giải pháp dựa trên con trỏ. Dựa trên thông tin chi tiết từ Luca, Kamil và Daniel, bằng cách sử dụng thử nghiệm giao nhau giữa các khoảng đã sửa đổi, nỗ lực thứ hai của chúng tôi là một cải tiến đáng kể sử dụng lập chỉ mục hiệu quả và hoạt động tốt hơn so với giải pháp dựa trên con trỏ. Tuy nhiên, giải pháp này liên quan đến chi phí I / O đáng kể. Tháng tới, tôi sẽ tiếp tục khám phá các giải pháp bổ sung.
[Bước tới:Thử thách ban đầu | Giải pháp:Phần 1 | Phần 2 | Phần 3]