Từ lâu, tôi đã là người đề xuất việc chọn kiểu dữ liệu chính xác. Tôi đã nói về một số ví dụ trong bài đăng trên blog "Thói quen xấu" trước đây, nhưng cuối tuần này tại SQL Saturday # 162 (Cambridge, UK), chủ đề sử dụng DATETIME theo mặc định đã xuất hiện. Trong cuộc trò chuyện sau bài thuyết trình T-SQL:Thói quen xấu và Phương pháp hay nhất của tôi, một người dùng đã nói rằng họ chỉ sử dụng DATETIME ngay cả khi họ chỉ cần độ chi tiết đến từng phút hoặc từng ngày, theo cách này, các cột ngày / giờ trong toàn bộ doanh nghiệp của họ luôn có cùng một kiểu dữ liệu. Tôi đã gợi ý rằng điều này có thể lãng phí và tính nhất quán có thể không đáng giá, nhưng hôm nay tôi quyết định bắt đầu để chứng minh lý thuyết của mình.
TL; Phiên bản DR
Thử nghiệm của tôi bên dưới cho thấy rằng chắc chắn có những tình huống mà bạn có thể muốn xem xét sử dụng kiểu dữ liệu mỏng hơn thay vì gắn bó với DATETIME mọi nơi. Nhưng điều quan trọng là phải xem các thử nghiệm của tôi cho điều này chỉ theo cách khác và điều quan trọng là thử nghiệm các tình huống này dựa trên lược đồ của bạn, trong môi trường của bạn, với phần cứng và dữ liệu càng đúng với sản xuất càng tốt. Kết quả của bạn có thể, và gần như chắc chắn, sẽ khác nhau.
Các bảng đích
Hãy xem xét trường hợp mà mức độ chi tiết chỉ quan trọng trong ngày (chúng ta không quan tâm đến giờ, phút, giây). Đối với điều này, chúng tôi có thể chọn DATETIME (như người dùng đề xuất) hoặc SMALLDATETIME hoặc DATE trên SQL Server 2008+. Ngoài ra còn có hai loại dữ liệu khác nhau mà tôi muốn xem xét:
- Dữ liệu sẽ được chèn gần như tuần tự trong thời gian thực (ví dụ:các sự kiện đang diễn ra ngay bây giờ);
- Dữ liệu sẽ được chèn ngẫu nhiên (ví dụ:ngày sinh của các thành viên mới).
Tôi bắt đầu với 2 bảng như sau, sau đó tạo thêm 4 bảng nữa (2 cho SMALLDATETIME, 2 cho DATE):
TẠO BẢNG dbo.BirthDatesRandom_Datetime (ID INT IDENTITY (1,1) PRIMARY KEY, dt DATETIME NOT NULL); TẠO BẢNG dbo.EventsSequential_Datetime (ID INT IDENTITY (1,1) PRIMARY KEY, dt DATETIME NOT NULL); TẠO CHỈ SỐ d TRÊN dbo.BirthDatesRandom_Datetime (dt); TẠO CHỈ SỐ d TRÊN dbo.EventsSequential_Datetime (dt); - Sau đó lặp lại trong DATE và SMALLDATETIME.
Và mục tiêu của tôi là kiểm tra hiệu suất chèn hàng loạt theo hai cách khác nhau, cũng như tác động đến kích thước lưu trữ tổng thể và sự phân mảnh, và cuối cùng là hiệu suất của các truy vấn phạm vi.
Dữ liệu mẫu
Để tạo một số dữ liệu mẫu, tôi đã sử dụng một trong những kỹ thuật tiện dụng của mình để tạo ra thứ gì đó có ý nghĩa từ một thứ không phải:các chế độ xem danh mục. Trên hệ thống của tôi, điều này trả về 971 giá trị ngày / giờ riêng biệt (tổng cộng 1.000.000 hàng) trong khoảng 12 giây:
; WITH y AS (SELECT TOP (1000000) d =DATEADD (SECOND, x, DATEADD (DAY, DATEDIFF (DAY, x, 0), '20120101')) FROM (SELECT s1. [object_id]% 1000 FROM sys.all_objects AS s1 CROSS THAM GIA sys.all_objects AS s2) AS x (x) ORDER BY NEWID ()) SELECT DISTINCT d FROM y;
Tôi đặt hàng triệu hàng này vào một bảng để có thể mô phỏng các lần chèn tuần tự / ngẫu nhiên bằng các phương pháp truy cập khác nhau cho cùng một dữ liệu chính xác từ ba cửa sổ phiên khác nhau:
CREATE TABLE dbo.Staging (ID INT IDENTITY (1,1) PRIMARY KEY, source_date DATETIME NOT NULL);; WITH Staging_Data AS (SELECT TOP (1000000) dt =DATEADD (SECOND, x, DATEADD (DAY, DATEDIFF (DAY, x, 0), '20110101')) FROM (SELECT s1. [Object_id]% 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2) AS sd (x) ORDER BY NEWID ()) INSERT dbo.Staging (source_date) SELECT dt FROM y ORDER BY dt;
Quá trình này mất nhiều thời gian hơn một chút để hoàn thành (20 giây). Sau đó, tôi tạo một bảng thứ hai để lưu trữ cùng một dữ liệu nhưng được phân phối ngẫu nhiên (để tôi có thể lặp lại cùng một phân phối trên tất cả các lần chèn).
TẠO BẢNG dbo.Staging_Random (ID INT IDENTITY (1,1) PRIMARY KEY, source_date DATETIME NOT NULL); CHÈN dbo.Staging_Random (source_date) CHỌN source_date TỪ dbo.Staging ORDER BY NEWID ();
Truy vấn để điền bảng
Tiếp theo, tôi đã viết một tập hợp các truy vấn để điền dữ liệu này vào các bảng khác, sử dụng ba cửa sổ truy vấn để mô phỏng ít nhất một chút đồng thời:
WAITFOR TIME '13:53'; GO DECLARE @d DATETIME2 =SYSDATETIME (); CHÈN dbo. {Table_name} (dt) - tùy thuộc vào phương thức / kiểu dữ liệu CHỌN source_date FROM dbo.Staging [_Random] - tùy thuộc vào đích WHERE ID% 3 =<0,1,2> - tùy thuộc vào cửa sổ truy vấn LỆNH THEO ID; CHỌN DATEDIFF (MILLISECOND, @d, SYSDATETIME ()); Như trong bài viết trước của tôi, tôi đã mở rộng trước cơ sở dữ liệu để ngăn bất kỳ loại sự kiện tự động tăng trưởng tệp dữ liệu nào can thiệp vào kết quả. Tôi nhận ra rằng không hoàn toàn thực tế khi thực hiện chèn hàng triệu hàng trong một lần vượt qua, vì tôi không thể ngăn hoạt động nhật ký đối với một giao dịch lớn như vậy can thiệp, nhưng nó nên thực hiện nhất quán trên từng phương pháp. Do phần cứng tôi đang kiểm tra hoàn toàn khác với phần cứng bạn đang sử dụng, nên kết quả tuyệt đối không phải là vấn đề quan trọng, chỉ là so sánh tương đối.
(Trong một thử nghiệm trong tương lai, tôi cũng sẽ thử điều này với các lô thực đến từ các tệp nhật ký có dữ liệu tương đối hỗn hợp và sử dụng các phần của bảng nguồn trong các vòng lặp - Tôi nghĩ đó cũng sẽ là những thử nghiệm thú vị. Và tất nhiên là thêm nén vào hỗn hợp.)
Kết quả:
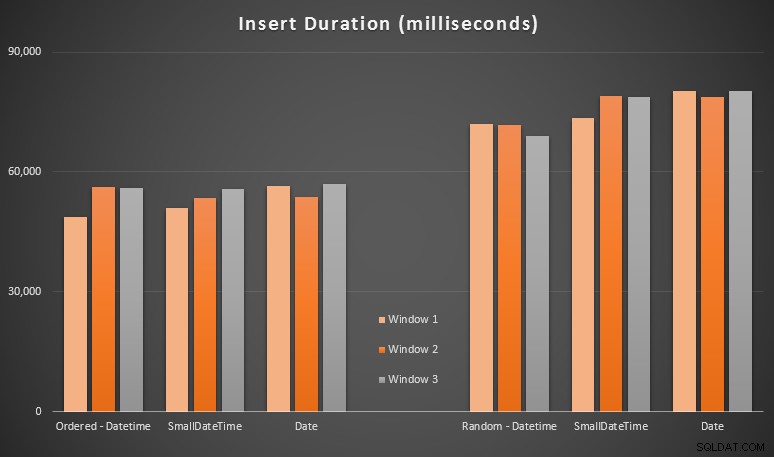
Những kết quả này không gây ngạc nhiên cho tôi - việc chèn theo thứ tự ngẫu nhiên dẫn đến thời gian chạy lâu hơn so với việc chèn tuần tự, điều mà tất cả chúng ta có thể lấy lại gốc rễ của mình là hiểu cách các chỉ mục trong SQL Server hoạt động và việc chia tách trang "xấu" hơn có thể xảy ra như thế nào trong kịch bản này (Tôi không theo dõi cụ thể việc tách trang trong bài tập này, nhưng đó là điều tôi sẽ xem xét trong các thử nghiệm trong tương lai).
Tôi nhận thấy rằng, về mặt ngẫu nhiên, các chuyển đổi ngầm định trên dữ liệu đến có thể có tác động đến thời gian, vì chúng có vẻ cao hơn một chút so với DATETIME -> DATETIME gốc phụ trang. Vì vậy, tôi quyết định tạo hai bảng mới chứa dữ liệu nguồn:một bảng sử dụng DATE và một bằng SMALLDATETIME . Điều này sẽ mô phỏng, ở một mức độ nào đó, chuyển đổi kiểu dữ liệu của bạn đúng cách trước khi chuyển nó sang câu lệnh insert, sao cho không cần chuyển đổi ngầm trong quá trình chèn. Dưới đây là các bảng mới và cách chúng được điền:
TẠO BẢNG dbo.Staging_Random_SmallDatetime (ID INT IDENTITY (1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date (ID INT IDENTITY (1,1) PRIMARY KEY, source_date DATE NOT NULL); CHÈN dbo.Staging_Random_SmallDatetime (source_date) CHỌN CHUYỂN ĐỔI (SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER THEO ID; CHÈN dbo.Staging_Random_Date (source_date) CHỌN CHUYỂN ĐỔI (DATE, source_date) FROM dbo.Staging_Random ORDER THEO ID;
Điều này không có tác dụng mà tôi mong đợi - thời gian là tương tự nhau trong mọi trường hợp. Vì vậy, đó là một cuộc rượt đuổi ngỗng hoang dã.
Không gian được sử dụng &phân mảnh
Tôi đã chạy truy vấn sau để xác định có bao nhiêu trang được dành riêng cho mỗi bảng:
SELECT name ='dbo.' + OBJECT_NAME ([object_id]), pages =SUM (Reser_page_count) TỪ sys.dm_db_partition_stats GROUP BY OBJECT_NAME ([object_id]) ORDER BY các trang;
Kết quả:
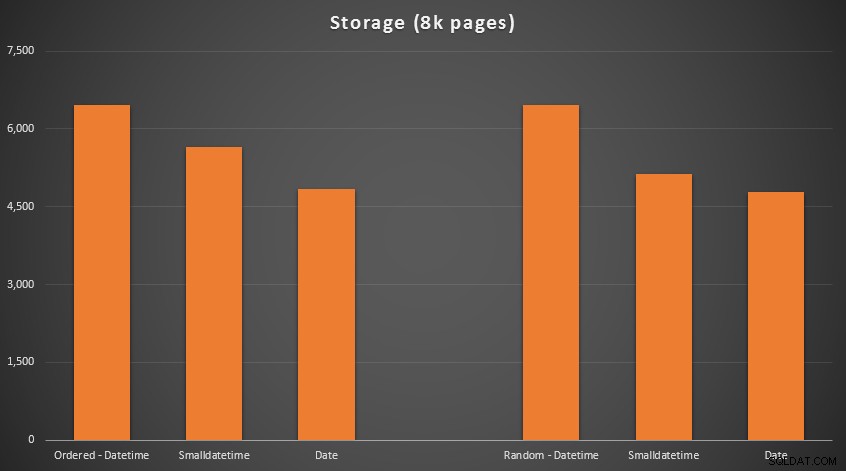
Không có khoa học tên lửa ở đây; sử dụng kiểu dữ liệu nhỏ hơn, bạn nên sử dụng ít trang hơn. Chuyển từ DATETIME đến DATE liên tục mang lại giảm 25% số lượng trang được sử dụng, trong khi SMALLDATETIME giảm yêu cầu từ 13-20%.
Bây giờ để phân mảnh và mật độ trang trên các chỉ mục không phân cụm (có rất ít sự khác biệt đối với các chỉ mục được phân cụm):
SELECT '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats (DB_ID (), OBJECT_ID ('{table_name}'), NULL, NULL, 'DETAILED' =2ERE;
Kết quả:
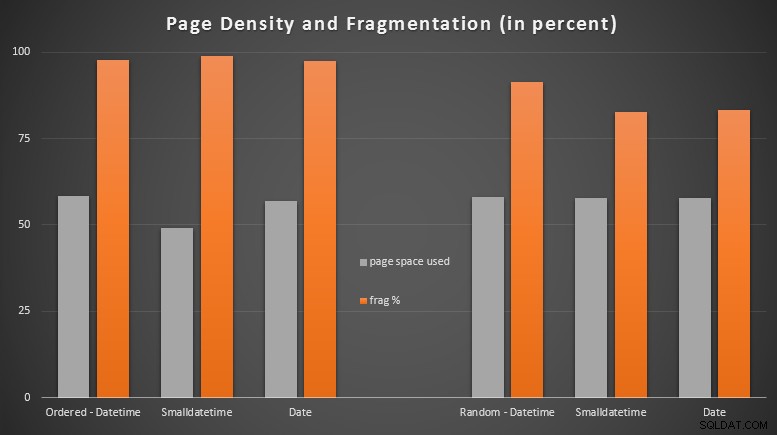
Tôi khá ngạc nhiên khi thấy dữ liệu được sắp xếp gần như bị phân mảnh hoàn toàn, trong khi dữ liệu được chèn ngẫu nhiên thực sự kết thúc với việc sử dụng trang tốt hơn một chút. Tôi đã lưu ý rằng điều này đảm bảo điều tra thêm bên ngoài phạm vi của các thử nghiệm cụ thể này, nhưng nó có thể là thứ bạn muốn kiểm tra nếu bạn có các chỉ mục không phân cụm đang dựa vào phần lớn các lần chèn tuần tự.
[Việc xây dựng lại trực tuyến các chỉ mục không phân cụm trên tất cả 6 bảng diễn ra trong 7 giây, đưa mật độ trang trở lại phạm vi 99,5% và giảm phân mảnh xuống dưới 1%. Nhưng tôi đã không chạy nó cho đến khi thực hiện các kiểm tra truy vấn bên dưới…]
Kiểm tra truy vấn phạm vi
Cuối cùng, tôi muốn xem tác động về thời gian chạy đối với các truy vấn phạm vi ngày đơn giản so với các chỉ mục khác nhau, cả với sự phân mảnh cố hữu do hoạt động ghi kiểu OLTP gây ra và đối với một chỉ mục sạch được xây dựng lại. Bản thân truy vấn khá đơn giản:
CHỌN HÀNG ĐẦU (200000) dt TỪ dbo. {table_name} WHERE dt> ='20110101' ĐẶT HÀNG THEO dt;
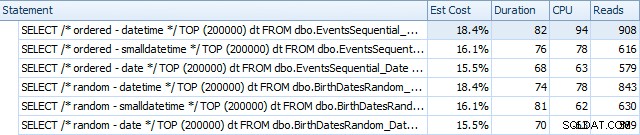
Đây là kết quả trước khi các chỉ mục được tạo lại, sử dụng SQL Sentry Plan Explorer:
Và chúng hơi khác sau khi xây dựng lại:
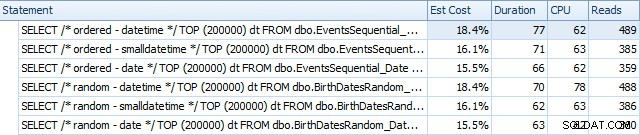
Về cơ bản, chúng tôi thấy thời lượng và đọc cao hơn một chút đối với các phiên bản DATETIME, nhưng rất ít khác biệt về CPU. Và sự khác biệt giữa SMALLDATETIME và DATE là không đáng kể khi so sánh. Tất cả các truy vấn đều có các kế hoạch truy vấn đơn giản như sau:

(Tất nhiên, tìm kiếm là một quá trình quét phạm vi có thứ tự.)
Kết luận
Mặc dù phải thừa nhận rằng các thử nghiệm này khá bịa đặt và có thể được hưởng lợi từ nhiều hoán vị hơn, nhưng chúng cho thấy gần đúng những gì tôi mong đợi:tác động lớn nhất đến lựa chọn cụ thể này là đối với không gian bị chiếm bởi chỉ mục không phân cụm (trong đó việc chọn loại dữ liệu mỏng hơn sẽ chắc chắn có lợi), và vào thời gian cần thiết để thực hiện chèn theo thứ tự tùy ý, thay vì tuần tự, (trong đó DATETIME chỉ có một cạnh biên).
Tôi rất muốn nghe ý kiến của bạn về cách đặt các lựa chọn kiểu dữ liệu như thế này thông qua các bài kiểm tra kỹ lưỡng và trừng phạt hơn. Tôi dự định sẽ đi vào chi tiết hơn trong các bài đăng trong tương lai.