Nhu cầu phổ biến nhất để tách thời gian khỏi giá trị ngày giờ là lấy tất cả các hàng đại diện cho đơn đặt hàng (hoặc lượt truy cập hoặc tai nạn) đã xảy ra vào một ngày nhất định. Tuy nhiên, không phải tất cả các kỹ thuật được sử dụng để làm như vậy đều hiệu quả hoặc thậm chí an toàn.
TL; Phiên bản DR
Nếu bạn muốn truy vấn phạm vi an toàn hoạt động tốt, hãy sử dụng phạm vi kết thúc mở hoặc đối với các truy vấn một ngày trên SQL Server 2008 trở lên, hãy sử dụng CONVERT(DATE) :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Một số lưu ý:
- Hãy cẩn thận với
DATEDIFFcách tiếp cận, vì có một số bất thường về ước tính bản số có thể xảy ra (xem bài đăng trên blog này và câu hỏi về Stack Overflow đã thúc đẩy nó để biết thêm thông tin). - Mặc dù biểu thức cuối cùng vẫn có khả năng sử dụng tìm kiếm chỉ mục (không giống như mọi biểu thức không thể phân loại khác mà tôi từng gặp), bạn cần phải cẩn thận về việc chuyển đổi cột thành ngày trước khi so sánh. Cách tiếp cận này cũng có thể mang lại các ước tính về bản số sai về cơ bản. Hãy xem câu trả lời này của Martin Smith để biết thêm chi tiết.
Trong mọi trường hợp, hãy đọc để hiểu tại sao đây là hai cách tiếp cận duy nhất mà tôi từng đề xuất.
Không phải tất cả các phương pháp đều an toàn
Là một ví dụ không an toàn, tôi thấy cái này được sử dụng rất nhiều:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Có một vài vấn đề với cách tiếp cận này, nhưng vấn đề đáng chú ý nhất là việc tính toán "kết thúc" của ngày hôm nay - nếu kiểu dữ liệu cơ bản là SMALLDATETIME , phạm vi kết thúc đó sẽ làm tròn lên; nếu đó là DATETIME2 , về mặt lý thuyết, bạn có thể bỏ lỡ dữ liệu vào cuối ngày. Nếu bạn chọn phút hoặc nano giây hoặc bất kỳ khoảng cách nào khác để phù hợp với loại dữ liệu hiện tại, truy vấn của bạn sẽ bắt đầu có hành vi kỳ lạ nếu loại dữ liệu thay đổi sau đó (và hãy trung thực, nếu ai đó thay đổi loại của cột đó để trở nên chi tiết hơn, họ không chạy xung quanh việc kiểm tra mọi truy vấn duy nhất truy cập nó). Việc phải viết mã theo cách này tùy thuộc vào loại dữ liệu ngày / giờ trong cột bên dưới bị phân mảnh và dễ xảy ra lỗi. Sẽ tốt hơn nhiều nếu sử dụng phạm vi ngày kết thúc cho việc này:
Tôi nói về điều này nhiều hơn trong một vài bài đăng trên blog cũ:
- GIỮA và ma quỷ có điểm gì chung?
- Thói quen xấu cần bắt đầu:xử lý sai các truy vấn ngày / phạm vi
Nhưng tôi muốn so sánh hiệu suất của một số cách tiếp cận phổ biến hơn mà tôi thấy ở đó. Tôi luôn sử dụng phạm vi kết thúc mở và kể từ SQL Server 2008, chúng tôi đã có thể sử dụng CONVERT(DATE) và vẫn sử dụng một chỉ mục trên cột đó, khá mạnh mẽ.
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Kiểm tra hiệu suất đơn giản
Để thực hiện một bài kiểm tra hiệu suất ban đầu rất đơn giản, tôi đã thực hiện như sau cho mỗi câu lệnh trên, đặt một biến cho đầu ra của phép tính 100.000 lần:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
Tôi đã làm điều này ba lần cho mỗi phương pháp và tất cả đều chạy trong khoảng 34-38 giây. Vì vậy, nói một cách chính xác, có sự khác biệt không đáng kể trong các phương pháp này khi thực hiện các hoạt động trong bộ nhớ:
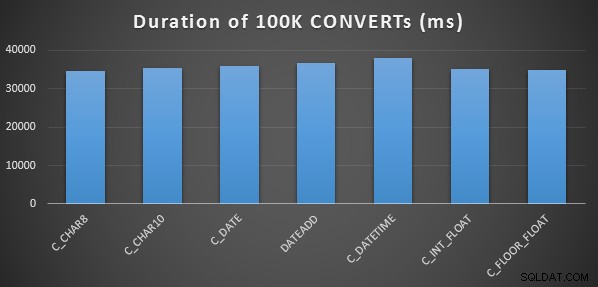
Kiểm tra Hiệu suất Công phu hơn
Tôi cũng muốn so sánh các phương pháp này với các kiểu dữ liệu khác nhau (DATETIME , SMALLDATETIME và DATETIME2 ), chống lại cả một chỉ mục được phân nhóm và một đống, và có và không có nén dữ liệu. Vì vậy, đầu tiên tôi tạo một cơ sở dữ liệu đơn giản. Thông qua thử nghiệm, tôi xác định rằng kích thước tối ưu để xử lý 120 triệu hàng và tất cả hoạt động nhật ký có thể phát sinh (và để ngăn các sự kiện tự động phát triển can thiệp vào quá trình thử nghiệm) là tệp dữ liệu 20 GB và nhật ký 3 GB:
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
Tiếp theo, tôi tạo 12 bảng:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Sau đó lặp lại lần nữa trong DATETIME và DATETIME2.]
Tiếp theo, tôi chèn 10.000.000 hàng vào mỗi bảng. Tôi đã làm điều này bằng cách tạo một chế độ xem sẽ tạo ra 10.000.000 ngày giống nhau mỗi lần:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
Điều này cho phép tôi điền các bảng theo cách này:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Sau đó lặp lại một lần nữa cho các đống và chỉ mục nhóm không nén. Tôi đặt CHECKPOINT giữa mỗi lần chèn để đảm bảo sử dụng lại nhật ký (mô hình khôi phục rất đơn giản).]
CHÈN Thời gian &Dung lượng Đã sử dụng
Dưới đây là thời gian cho mỗi lần chèn (như được chụp bằng Plan Explorer):
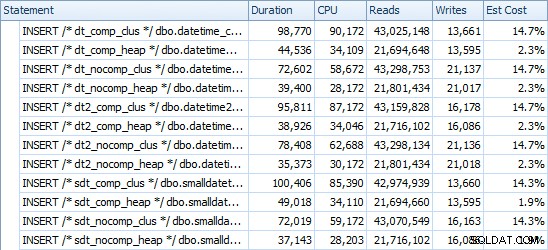
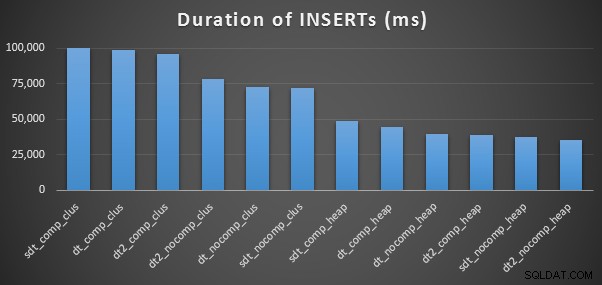
Và đây là dung lượng bị chiếm dụng bởi mỗi bảng:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
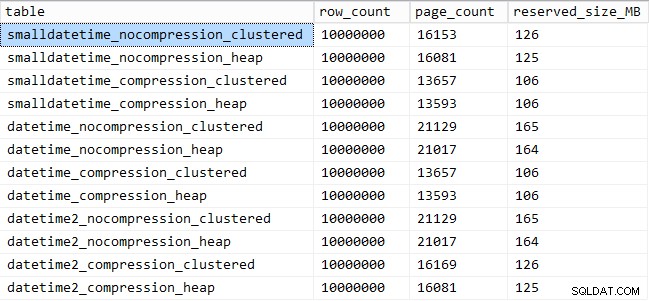
Hiệu suất mẫu truy vấn
Tiếp theo, tôi bắt đầu kiểm tra hai mẫu truy vấn khác nhau về hiệu suất:
- Đếm số hàng cho một ngày cụ thể, sử dụng bảy phương pháp ở trên, cũng như phạm vi ngày kết thúc mở
- Chuyển đổi tất cả 10.000.000 hàng bằng cách sử dụng bảy phương pháp trên, cũng như chỉ trả lại dữ liệu thô (vì định dạng ở phía máy khách có thể tốt hơn)
[Ngoại trừ FLOAT và DATETIME2 vì chuyển đổi này không hợp pháp.]
Đối với câu hỏi đầu tiên, các truy vấn trông như thế này (lặp lại cho từng loại bảng):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; Kết quả đối với một chỉ mục được phân nhóm trông như thế này (bấm vào để phóng to):
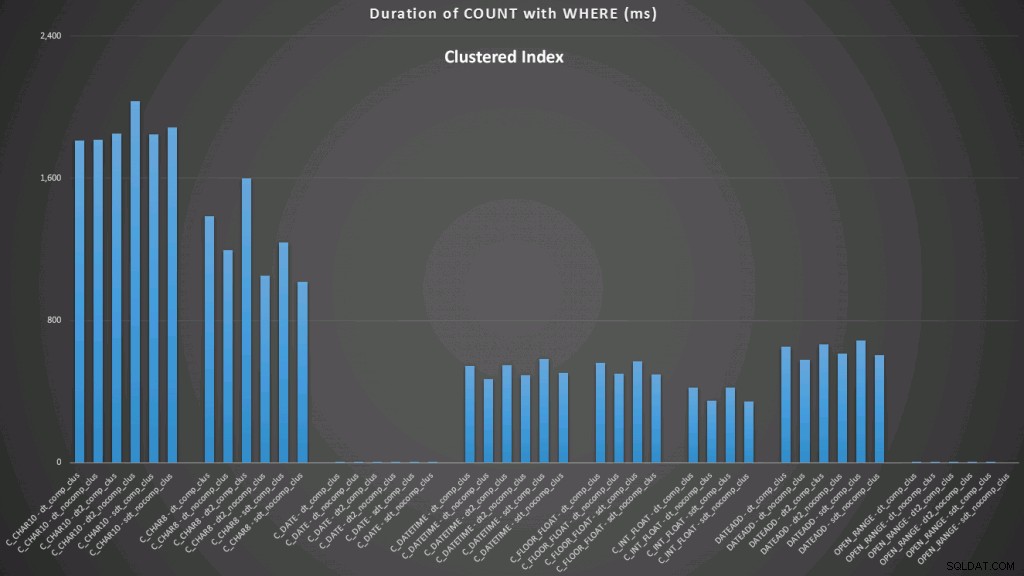
Ở đây, chúng tôi thấy rằng chuyển đổi theo ngày và phạm vi kết thúc mở sử dụng chỉ mục là hoạt động tốt nhất. Tuy nhiên, đối với một đống, việc chuyển đổi sang ngày thực sự mất một khoảng thời gian, làm cho phạm vi kết thúc mở trở thành lựa chọn tối ưu (nhấp để phóng to):
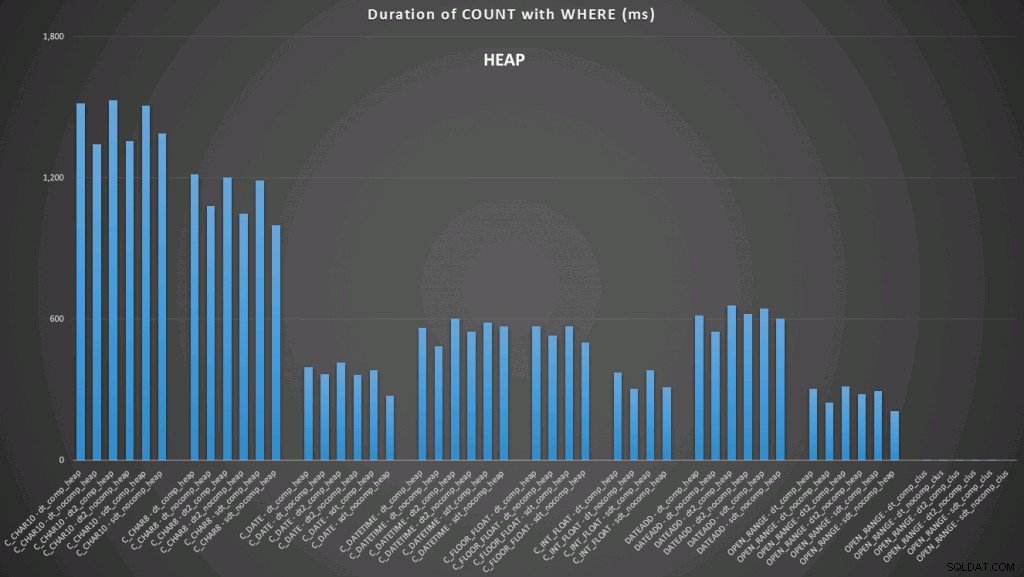
Và đây là nhóm truy vấn thứ hai (lặp lại cho từng loại bảng):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; Tập trung vào kết quả cho các bảng có chỉ mục được phân cụm, rõ ràng là chuyển đổi sang ngày là một công cụ thực hiện rất gần với việc chỉ chọn dữ liệu thô (nhấp để phóng to):
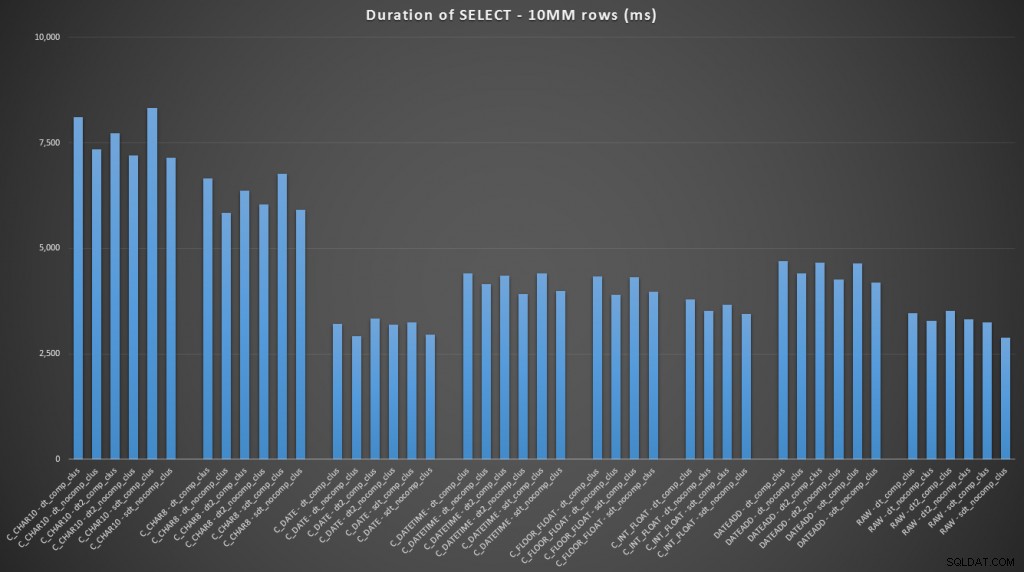
(Đối với tập hợp các truy vấn này, đống cho kết quả rất giống nhau - thực tế không thể phân biệt được.)
Kết luận
Trong trường hợp bạn muốn bỏ qua đến điểm mấu chốt, những kết quả này cho thấy rằng chuyển đổi trong bộ nhớ không quan trọng, nhưng nếu bạn đang chuyển đổi dữ liệu trên đường ra khỏi bảng (hoặc là một phần của vị từ tìm kiếm), thì phương pháp bạn chọn có thể có một tác động đáng kể đến hiệu suất. Chuyển đổi sang DATE (trong một ngày) hoặc sử dụng phạm vi ngày kết thúc trong mọi trường hợp sẽ mang lại hiệu suất tốt nhất, trong khi phương pháp phổ biến nhất hiện có - chuyển đổi thành chuỗi - hoàn toàn không tốt.
Chúng tôi cũng thấy rằng nén có thể có ảnh hưởng tốt đến không gian lưu trữ, với tác động rất nhỏ đến hiệu suất truy vấn. Ảnh hưởng đến hiệu suất chèn dường như phụ thuộc vào việc bảng có chỉ mục được phân cụm hay không hơn là việc có bật tính năng nén hay không. Tuy nhiên, với một chỉ mục theo nhóm được đưa ra, có một sự thay đổi đáng chú ý trong khoảng thời gian cần để chèn 10 triệu hàng. Một số điều cần ghi nhớ và cân bằng với việc tiết kiệm dung lượng ổ đĩa.
Rõ ràng là có thể có nhiều thử nghiệm hơn liên quan, với khối lượng công việc đa dạng và đáng kể hơn, mà tôi có thể khám phá thêm trong một bài đăng trong tương lai.