SQL Server theo truyền thống tránh cung cấp các giải pháp nguyên bản cho một số câu hỏi thống kê phổ biến hơn, chẳng hạn như tính toán giá trị trung bình. Theo WikiPedia, "trung vị được mô tả là giá trị số tách nửa cao hơn của mẫu, tập hợp hoặc phân phối xác suất, với nửa dưới. Trung vị của danh sách hữu hạn số có thể được tìm thấy bằng cách sắp xếp tất cả các quan sát từ giá trị thấp nhất đến giá trị cao nhất và chọn giá trị giữa. Nếu có số lượng quan sát chẵn thì không có giá trị giữa duy nhất; giá trị trung bình khi đó thường được xác định là giá trị trung bình của hai giá trị giữa. "
Về truy vấn SQL Server, điều quan trọng bạn sẽ rút ra được là bạn cần phải "sắp xếp" (sắp xếp) tất cả các giá trị. Sắp xếp trong SQL Server thường là một hoạt động khá tốn kém nếu không có chỉ mục hỗ trợ và việc thêm chỉ mục để hỗ trợ một hoạt động có thể không được yêu cầu thường có thể không đáng giá.
Hãy xem xét cách chúng tôi thường giải quyết vấn đề này trong các phiên bản SQL Server trước. Đầu tiên, hãy tạo một bảng rất đơn giản để chúng ta có thể phân tích rằng logic của chúng ta là chính xác và lấy ra một trung vị chính xác. Chúng ta có thể kiểm tra hai bảng sau, một bảng có số hàng chẵn và bảng còn lại có số hàng lẻ:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Chỉ từ quan sát thông thường, chúng ta có thể thấy rằng trung vị của bảng có các hàng lẻ phải là 6 và đối với bảng chẵn phải là 7,5 ((6 + 9) / 2). Vì vậy, bây giờ chúng ta hãy xem một số giải pháp đã được sử dụng trong những năm qua:
SQL Server 2000
Trong SQL Server 2000, chúng tôi bị giới hạn trong một phương ngữ T-SQL rất hạn chế. Tôi đang điều tra các tùy chọn này để so sánh bởi vì một số người ngoài kia vẫn đang chạy SQL Server 2000 và những người khác có thể đã nâng cấp, nhưng vì các phép tính trung bình của họ được viết "trước đây", mã vẫn có thể trông như thế này ngày nay.
2000_A - tối đa của một nửa, tối thiểu của nửa kia
Cách tiếp cận này lấy giá trị cao nhất từ 50 phần trăm đầu tiên, giá trị thấp nhất từ 50 phần trăm cuối cùng, sau đó chia chúng cho hai. Điều này hoạt động cho các hàng chẵn hoặc lẻ bởi vì, trong trường hợp chẵn, hai giá trị là hai hàng ở giữa và trong trường hợp lẻ, hai giá trị thực sự thuộc cùng một hàng.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B - #temp table
Ví dụ này trước tiên tạo một bảng #temp và sử dụng cùng một loại toán học như trên, xác định hai hàng "giữa" với sự hỗ trợ từ IDENTITY liền kề cột thứ tự của cột val. (Thứ tự gán IDENTITY chỉ có thể dựa vào giá trị vì MAXDOP cài đặt.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 đã giới thiệu một số hàm cửa sổ mới thú vị, chẳng hạn như ROW_NUMBER() , có thể giúp giải quyết các vấn đề thống kê như trung bình dễ dàng hơn một chút so với chúng ta có thể làm trong SQL Server 2000. Tất cả các phương pháp này đều hoạt động trong SQL Server 2005 trở lên:
2005_A - số hàng đấu
Ví dụ này sử dụng ROW_NUMBER() để đi lên và xuống các giá trị một lần theo mỗi hướng, sau đó tìm một hoặc hai hàng "ở giữa" dựa trên phép tính đó. Điều này khá giống với ví dụ đầu tiên ở trên, với cú pháp dễ dàng hơn:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B - số hàng + số lượng
Kết quả này tương tự như ở trên, sử dụng một phép tính duy nhất là ROW_NUMBER() và sau đó sử dụng tổng số COUNT() để tìm một hoặc hai hàng "ở giữa":
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C - biến thể về số hàng + số lượng
Đồng nghiệp MVP Itzik Ben-Gan đã chỉ cho tôi phương pháp này, phương pháp này đạt được câu trả lời giống như hai phương pháp trên, nhưng theo một cách rất khác một chút:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
Trong SQL Server 2012, chúng tôi có các khả năng tạo cửa sổ mới trong T-SQL cho phép các phép tính thống kê như giá trị trung bình được thể hiện trực tiếp hơn. Để tính giá trị trung bình cho một tập hợp giá trị, chúng ta có thể sử dụng PERCENTILE_CONT() . Chúng tôi cũng có thể sử dụng phần mở rộng "phân trang" mới cho ORDER BY mệnh đề (OFFSET / FETCH ).
2012_A - chức năng phân phối mới
Giải pháp này sử dụng một phép tính rất đơn giản bằng cách sử dụng phân phối (nếu bạn không muốn giá trị trung bình giữa hai giá trị giữa trong trường hợp một số hàng chẵn).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B - thủ thuật phân trang
Ví dụ này sử dụng OFFSET / FETCH một cách thông minh (và không chính xác là một hàng như dự định) - chúng ta chỉ cần di chuyển đến hàng có một trước một nửa số đếm, sau đó lấy một hoặc hai hàng tiếp theo tùy thuộc vào số lượng là lẻ hay chẵn. Cảm ơn Itzik Ben-Gan đã chỉ ra cách tiếp cận này.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
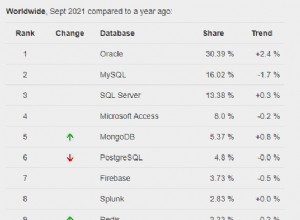
Nhưng cái nào hoạt động tốt hơn?
Chúng tôi đã xác minh rằng các phương pháp trên đều tạo ra kết quả mong đợi trên bảng nhỏ của chúng tôi và chúng tôi biết rằng phiên bản SQL Server 2012 có cú pháp hợp lý và rõ ràng nhất. Nhưng bạn nên sử dụng cái nào trong môi trường sản xuất bận rộn của mình? Chúng tôi có thể tạo một bảng lớn hơn nhiều từ siêu dữ liệu hệ thống, đảm bảo rằng chúng tôi có nhiều giá trị trùng lặp. Tập lệnh này sẽ tạo ra một bảng có 10.000.000 số nguyên không phải là duy nhất:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
Trên hệ thống của tôi, giá trị trung bình cho bảng này phải là 146.099.561. Tôi có thể tính toán điều này khá nhanh mà không cần kiểm tra vị trí thủ công 10.000.000 hàng bằng cách sử dụng truy vấn sau:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Kết quả:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Vì vậy, bây giờ chúng ta có thể tạo một quy trình được lưu trữ cho từng phương pháp, xác minh rằng mỗi phương pháp tạo ra kết quả chính xác, sau đó đo lường các chỉ số hiệu suất như thời lượng, CPU và số lần đọc. Chúng tôi sẽ thực hiện tất cả các bước này với bảng hiện có và cả với một bản sao của bảng không được hưởng lợi từ chỉ mục được phân nhóm (chúng tôi sẽ loại bỏ nó và tạo lại bảng dưới dạng một đống).
Tôi đã tạo bảy thủ tục triển khai các phương thức truy vấn ở trên. Để ngắn gọn, tôi sẽ không liệt kê chúng ở đây, nhưng mỗi cái được đặt tên là dbo.Median_<version> , ví dụ. dbo.Median_2000_A , dbo.Median_2000_B , v.v. tương ứng với các cách tiếp cận được mô tả ở trên. Nếu chúng tôi chạy bảy thủ tục này bằng SQL Sentry Plan Explorer miễn phí, thì đây là những gì chúng tôi quan sát được về thời lượng, CPU và số lần đọc (lưu ý rằng chúng tôi chạy DBCC FREEPROCCACHE và DBCC DROPCLEANBUFFERS giữa các lần thực thi):
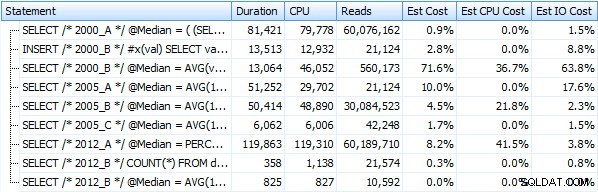
Và những chỉ số này không thay đổi nhiều nếu thay vào đó chúng ta hoạt động dựa trên một đống. Phần trăm thay đổi lớn nhất là phương pháp cuối cùng vẫn là nhanh nhất:thủ thuật phân trang sử dụng OFFSET / FETCH:
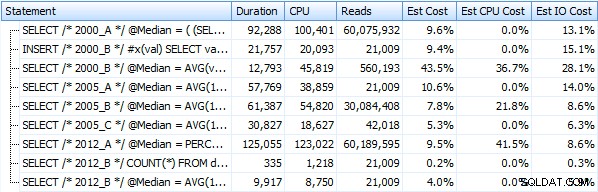
Đây là một biểu diễn đồ họa của các kết quả. Để làm rõ hơn, tôi đánh dấu người hoạt động chậm nhất bằng màu đỏ và cách tiếp cận nhanh nhất bằng màu xanh lục.
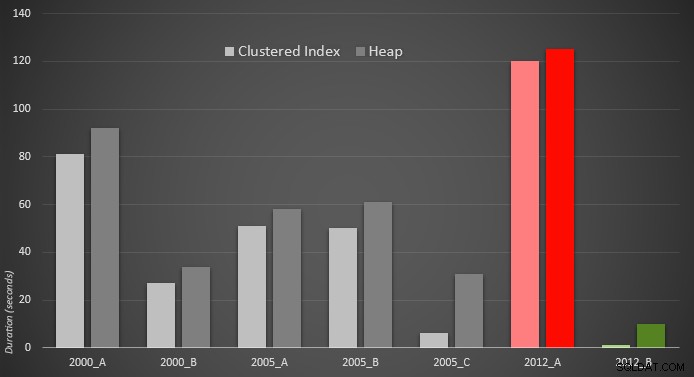
Tôi rất ngạc nhiên khi thấy rằng, trong cả hai trường hợp, PERCENTILE_CONT() - được thiết kế cho kiểu tính toán này - thực sự kém hơn tất cả các giải pháp khác trước đó. Tôi đoán nó chỉ cho thấy rằng mặc dù đôi khi cú pháp mới hơn có thể làm cho việc viết mã của chúng ta dễ dàng hơn, nhưng không phải lúc nào nó cũng đảm bảo rằng hiệu suất sẽ được cải thiện. Tôi cũng ngạc nhiên khi thấy OFFSET / FETCH tỏ ra rất hữu ích trong các tình huống thường không phù hợp với mục đích của nó - phân trang.
Trong mọi trường hợp, tôi hy vọng tôi đã chứng minh được bạn nên sử dụng cách tiếp cận nào, tùy thuộc vào phiên bản SQL Server của bạn (và lựa chọn phải giống nhau cho dù bạn có chỉ mục hỗ trợ cho phép tính hay không).