Đánh dấu lần nhấn là một tính năng mà nhiều người mong muốn Tìm kiếm toàn văn bản của SQL Server sẽ hỗ trợ nguyên bản. Đây là nơi bạn có thể trả lại toàn bộ tài liệu (hoặc một đoạn trích) và chỉ ra các từ hoặc cụm từ đã giúp khớp tài liệu đó với tìm kiếm. Làm như vậy một cách hiệu quả và chính xác không phải là nhiệm vụ dễ dàng, như tôi đã phát hiện ra lần đầu.
Ví dụ về đánh dấu nhấn:khi bạn thực hiện tìm kiếm trong Google hoặc Bing, bạn sẽ thấy các từ khóa được in đậm trong cả tiêu đề và đoạn trích (nhấp vào một trong hai hình ảnh để phóng to):

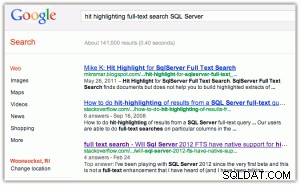
[Ngoài ra, tôi thấy có hai điều thú vị ở đây:(1) rằng Bing ủng hộ các tài sản của Microsoft hơn Google rất nhiều và (2) rằng Bing khó chịu khi trả về 2,2 triệu kết quả, nhiều trong số đó có thể không liên quan.]
Những đoạn trích này thường được gọi là "đoạn trích" hoặc "tóm tắt thiên về truy vấn". Chúng tôi đã yêu cầu chức năng này trong SQL Server được một thời gian, nhưng vẫn chưa nhận được tin vui nào từ Microsoft:
- Connect # 295100:Tóm tắt tìm kiếm toàn văn bản (đánh dấu lần truy cập)
- Connect # 722324:Sẽ rất tuyệt nếu SQL Full Text Search cung cấp hỗ trợ đoạn mã / tô sáng
Đôi khi, câu hỏi cũng xuất hiện trên Stack Overflow:
- Cách thực hiện đánh dấu các kết quả từ truy vấn toàn văn bản của Máy chủ SQL
- Sql Server 2012 FTS có hỗ trợ gốc cho việc đánh dấu lần truy cập không?
Có một số giải pháp từng phần. Ví dụ:tập lệnh này của Mike Kramar sẽ tạo ra một đoạn trích được đánh dấu nổi bật, nhưng không áp dụng cùng một logic (chẳng hạn như các dấu ngắt từ dành riêng cho ngôn ngữ) cho chính tài liệu. Nó cũng sử dụng số lượng ký tự tuyệt đối, vì vậy đoạn trích có thể bắt đầu và kết thúc bằng các từ từng phần (như tôi sẽ trình bày ngay sau đây). Cách thứ hai khá dễ sửa, nhưng một vấn đề khác là nó tải toàn bộ tài liệu vào bộ nhớ, thay vì thực hiện bất kỳ loại phát trực tuyến nào. Tôi nghi ngờ rằng trong các chỉ mục toàn văn bản với kích thước tài liệu lớn, đây sẽ là một thành công đáng chú ý về hiệu suất. Hiện tại, tôi sẽ tập trung vào kích thước tài liệu trung bình tương đối nhỏ (35 KB).
Một ví dụ đơn giản
Vì vậy, giả sử chúng ta có một bảng rất đơn giản, với một chỉ mục toàn văn được xác định:
TẠO DANH MỤC FULLTEXT [FTSDemo]; ĐI TẠO BẢNG [dbo]. [Document] ([ID] INT IDENTITY (1001,1) NOT NULL, [Url] NVARCHAR (200) NOT NULL, [Date] DATE NOT NULL , [Tiêu đề] NVARCHAR (200) KHÔNG ĐẦY ĐỦ, [Nội dung] NVARCHAR (TỐI ĐA) KHÔNG ĐẦY ĐỦ, CONSTRAINT PK_DOCUMENT PRIMARY KEY (ID)); ĐI TẠO CHỈ SỐ FULLTEXT TRÊN [dbo]. [Tài liệu] ([Nội dung] NGÔN NGỮ [Tiếng Anh] , [Title] LANGUAGE [Tiếng Anh]) CHỈ SỐ TỪ KHÓA [PK_Document] BẬT ([FTSDemo]);
Bảng này có một số tài liệu (cụ thể là 7), chẳng hạn như Tuyên ngôn Độc lập và bài phát biểu "Tôi chuẩn bị chết" của Nelson Mandela. Tìm kiếm toàn văn điển hình dựa trên bảng này có thể là:
SELECT d.Title, d. [Content] FROM dbo. [Document] AS d INNER JOIN CONTAINSTABLE (dbo. [Document], *, N'states ') AS t ON d.ID =t. [KEY] ĐẶT HÀNG BẰNG [RANK] DESC;
Kết quả trả về 4 hàng trong số 7:

Hiện đang sử dụng chức năng UDF như của Mike Kramar:
SELECT d.Title, Excerpt =dbo.HighLightSearch (d. [Content], N'states ',' font-weight:bold ', 80) TỪ dbo. [Document] AS dINNER JOIN CONTAINSTABLE (dbo. [Document ], *, N'states ') AS tON d.ID =t. [KEY] ORDER BY [RANK] DESC;
Kết quả cho thấy đoạn trích hoạt động như thế nào:a <SPAN> thẻ được chèn vào từ khóa đầu tiên và đoạn trích được tạo ra dựa trên phần bù từ vị trí đó (không tính đến việc sử dụng các từ hoàn chỉnh):

(Một lần nữa, đây là điều có thể sửa được, nhưng tôi muốn đảm bảo rằng tôi trình bày đúng những gì hiện có ở đó.)
ThinkHighlight
Eran Meyuchas của Tư duy Tương tác đã phát triển một thành phần giải quyết nhiều vấn đề này. ThinkHighlight được triển khai dưới dạng CLR Assembly với hai hàm có giá trị vô hướng CLR:
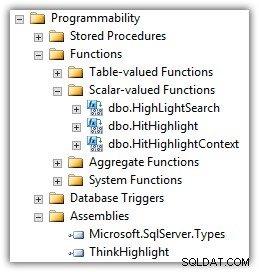
(Bạn cũng sẽ thấy UDF của Mike Kramar trong danh sách các chức năng.)
Bây giờ, không cần đi sâu vào tất cả các chi tiết về cài đặt và kích hoạt assembly trên hệ thống của bạn, đây là cách truy vấn trên sẽ được biểu diễn với ThinkHighlight:
SELECT d.Title, Excerpt =dbo.HitHighlight (dbo.HitHighlightContext ('Document', 'Content', N'states ', -1),' top -gment ', 100, d.ID) FROM dbo. [Tài liệu] AS DINNER JOIN CONTAINSTABLE (dbo. [Document], *, N'states ') AS tON d.ID =t. [KEY] ORDER BY t. [RANK] DESC; Kết quả cho biết cách các từ khóa có liên quan nhất được đánh dấu và một đoạn trích được lấy từ đó dựa trên các từ đầy đủ và phần bù từ thuật ngữ được đánh dấu:

Một số lợi thế bổ sung mà tôi chưa trình bày ở đây bao gồm khả năng chọn các chiến lược tóm tắt khác nhau, kiểm soát việc trình bày từng từ khóa (thay vì tất cả) bằng cách sử dụng CSS duy nhất, cũng như hỗ trợ nhiều ngôn ngữ và thậm chí cả tài liệu ở định dạng nhị phân (hầu hết IFilters được hỗ trợ).
Kết quả hoạt động
Ban đầu, tôi đã kiểm tra số liệu thời gian chạy cho ba truy vấn bằng cách sử dụng SQL Sentry Plan Explorer, dựa trên bảng 7 hàng. Kết quả là:

Tiếp theo, tôi muốn xem chúng sẽ so sánh như thế nào trên kích thước dữ liệu lớn hơn nhiều. Tôi đã chèn bảng vào chính nó cho đến khi tôi ở 4.000 hàng, sau đó chạy truy vấn sau:
ĐẶT THỜI GIAN THỐNG KÊ BẬT; ĐI CHỌN / * FTS * / d.Title, d. [Nội dung] TỪ dbo. [Tài liệu] AS d INNER JOIN CONTAINSTABLE (dbo. [Document], *, N'states ') AS tON d.ID =t. [KEY] ORDER BY [RANK] DESC; ĐI CHỌN / * UDF * / d.Title, Excerpt =dbo.HighLightSearch (d. [Content], N'states ',' font-weight:bold ', 100) FROM dbo. [Document] AS dINNER JOIN CONTAINSTABLE (dbo. [Document], *, N'states') AS tON d.ID =t. [KEY] ORDER BY [RANK] DESC; ĐI CHỌN / * ThinkHighlight * / d.Title, Excerpt =dbo.HitHighlight (dbo.HitHighlightContext ('Document', 'Content', N'states ', -1),' top -gment ', 100, d.ID) TỪ dbo. [Tài liệu] AS dINNER JOIN CONTAINSTABLE (dbo. [Document], *, N'states ') AS tON d.ID =t. [KEY] ORDER BY t. [RANK] DESC; GO ĐẶT THỐNG KÊ THỜI GIAN TẮT; ĐI
Tôi cũng đã theo dõi sys.dm_exec_memory_grants trong khi các truy vấn đang chạy, để nhận ra bất kỳ sự khác biệt nào trong việc cấp bộ nhớ. Kết quả trung bình trên 10 lần chạy:
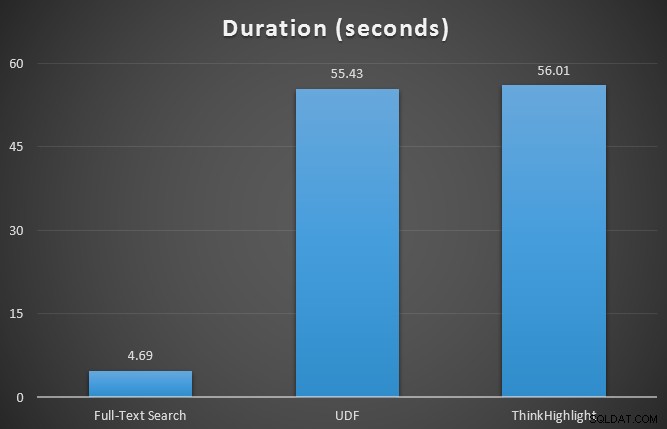
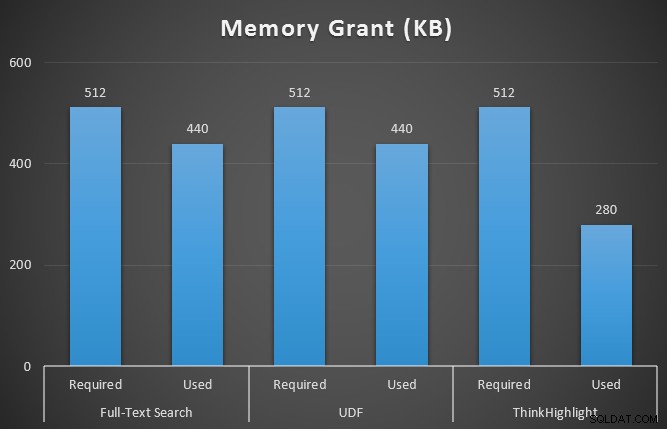
Trong khi cả hai tùy chọn đánh dấu lần lượt đều phải chịu một hình phạt đáng kể nếu không đánh dấu chút nào, giải pháp ThinkHighlight - với các tùy chọn linh hoạt hơn - thể hiện chi phí gia tăng rất nhỏ về thời lượng (~ 1%), trong khi sử dụng ít bộ nhớ hơn đáng kể (36%) so với biến thể UDF.
Kết luận
Không có gì ngạc nhiên khi đánh dấu nổi bật là một hoạt động tốn kém và dựa trên sự phức tạp của những gì phải được hỗ trợ (suy nghĩ nhiều ngôn ngữ), có rất ít giải pháp tồn tại ở đó. Tôi nghĩ Mike Kramar đã hoàn thành xuất sắc việc tạo ra một UDF cơ bản giúp bạn có cách giải quyết vấn đề hiệu quả, nhưng tôi rất ngạc nhiên khi tìm thấy một dịch vụ thương mại mạnh mẽ hơn - và nhận thấy nó rất ổn định, ngay cả ở dạng beta. Tôi có kế hoạch thực hiện các bài kiểm tra kỹ lưỡng hơn bằng cách sử dụng nhiều loại và kích thước tài liệu hơn. Trong thời gian chờ đợi, nếu đánh nổi bật là một phần của yêu cầu ứng dụng của bạn, bạn nên dùng thử UDF của Mike Kramar và cân nhắc sử dụng ThinkHighlight để lái thử.



