Có nhiều trường hợp sử dụng để tạo chuỗi giá trị trong SQL Server. Tôi không nói về IDENTITY vẫn tồn tại cột (hoặc SEQUENCE mới trong SQL Server 2012), mà là một tập hợp tạm thời chỉ được sử dụng cho thời gian tồn tại của một truy vấn. Hoặc ngay cả những trường hợp đơn giản nhất - chẳng hạn như chỉ thêm một số hàng vào mỗi hàng trong tập kết quả - có thể liên quan đến việc thêm ROW_NUMBER() chức năng cho truy vấn (hoặc tốt hơn là trong tầng trình bày, vẫn phải lặp lại từng hàng một trong các kết quả).
Tôi đang nói về những trường hợp phức tạp hơn một chút. Ví dụ:bạn có thể có một báo cáo hiển thị doanh số bán hàng theo ngày. Một truy vấn điển hình có thể là:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
Vấn đề với truy vấn này là, nếu không có đơn đặt hàng vào một ngày nhất định, thì sẽ không có hàng cho ngày đó. Điều này có thể dẫn đến nhầm lẫn, dữ liệu sai lệch hoặc thậm chí tính toán không chính xác (nghĩ là trung bình hàng ngày) cho những người tiêu dùng cuối cùng của dữ liệu.
Vì vậy, cần phải lấp đầy những khoảng trống đó bằng những ngày tháng không có trong dữ liệu. Và đôi khi mọi người sẽ nhét dữ liệu của họ vào bảng #temp và sử dụng WHILE vòng lặp hoặc con trỏ để điền lần lượt vào các ngày còn thiếu. Tôi sẽ không hiển thị mã đó ở đây vì tôi không muốn ủng hộ việc sử dụng nó, nhưng tôi đã thấy nó ở khắp nơi.
Tuy nhiên, trước khi chúng ta đi quá sâu vào ngày tháng, trước tiên hãy nói về các con số, vì bạn luôn có thể sử dụng một chuỗi số để tính ra một chuỗi ngày.
Bảng số
Từ lâu, tôi đã ủng hộ việc lưu trữ một "bảng số" phụ trợ trên đĩa (và, đối với vấn đề đó, cả một bảng lịch).
Đây là một cách để tạo một bảng số đơn giản với 1.000.000 giá trị:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
Tại sao lại MAXDOP 1? Xem bài đăng trên blog của Paul White và mục Kết nối của anh ấy liên quan đến mục tiêu hàng.
Tuy nhiên, nhiều người phản đối cách tiếp cận bảng bổ trợ. Lập luận của họ:tại sao lại lưu trữ tất cả dữ liệu đó trên đĩa (và trong bộ nhớ) khi họ có thể tạo dữ liệu một cách nhanh chóng? Mục tiêu của tôi là phải thực tế và suy nghĩ về những gì bạn đang tối ưu hóa; tính toán có thể tốn kém, và bạn có chắc rằng việc tính toán một loạt các con số đang diễn ra sẽ luôn rẻ hơn không? Về không gian, bảng Numbers chỉ chiếm khoảng 11 MB được nén và 17 MB không được nén. Và nếu bảng được tham chiếu đủ thường xuyên, thì bảng phải luôn ở trong bộ nhớ, giúp truy cập nhanh chóng.
Chúng ta hãy xem xét một vài ví dụ và một số cách tiếp cận phổ biến hơn được sử dụng để đáp ứng chúng. Tôi hy vọng tất cả chúng ta có thể đồng ý rằng, ngay cả ở 1.000 giá trị, chúng tôi không muốn giải quyết những vấn đề này bằng cách sử dụng vòng lặp hoặc con trỏ.
Tạo một chuỗi 1.000 số
Bắt đầu đơn giản, hãy tạo một tập hợp các số từ 1 đến 1.000.
Bảng số
Tất nhiên với một bảng số, nhiệm vụ này khá đơn giản:
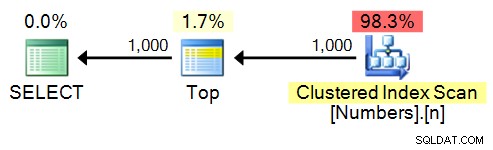
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Kế hoạch:
spt_values
Đây là một bảng được sử dụng bởi các thủ tục được lưu trữ bên trong cho các mục đích khác nhau. Việc sử dụng nó trực tuyến dường như khá phổ biến, ngay cả khi nó không có giấy tờ, không được hỗ trợ, nó có thể biến mất vào một ngày nào đó và bởi vì nó chỉ chứa một bộ giá trị hữu hạn, không duy nhất và không liền kề. Có 2.164 giá trị duy nhất và 2.508 tổng giá trị trong SQL Server 2008 R2; trong năm 2012 có 2.167 duy nhất và 2.515 tổng số. Điều này bao gồm các bản sao, giá trị âm và ngay cả khi sử dụng DISTINCT , rất nhiều khoảng trống khi bạn vượt qua con số 2.048. Vì vậy, giải pháp là sử dụng ROW_NUMBER() để tạo một chuỗi liền kề, bắt đầu từ 1, dựa trên các giá trị trong bảng.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Kế hoạch:

Điều đó nói rằng, chỉ với 1.000 giá trị, bạn có thể viết một truy vấn đơn giản hơn một chút để tạo ra cùng một chuỗi:
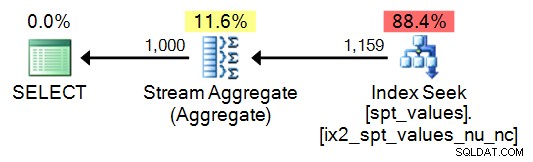
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Tất nhiên, điều này dẫn đến một kế hoạch đơn giản hơn, nhưng bị phá vỡ khá nhanh (khi trình tự của bạn phải nhiều hơn 2.048 hàng):
Trong mọi trường hợp, tôi không khuyến khích sử dụng bảng này; Tôi đưa nó vào với mục đích so sánh, chỉ vì tôi biết có bao nhiêu thứ trong số này ngoài kia và việc chỉ sử dụng lại mã mà bạn bắt gặp có thể hấp dẫn như thế nào.
sys.all_objects
Một cách tiếp cận khác mà tôi yêu thích trong những năm qua là sử dụng sys.all_objects . Giống như spt_values , không có cách nào đáng tin cậy để tạo một chuỗi liền kề trực tiếp và chúng ta gặp phải các vấn đề tương tự khi xử lý một tập hợp hữu hạn (chỉ dưới 2.000 hàng trong SQL Server 2008 R2 và chỉ hơn 2.000 hàng trong SQL Server 2012), nhưng đối với 1.000 hàng chúng ta có thể sử dụng cùng một ROW_NUMBER() bí quyết, Thuật, mẹo. Lý do tôi thích cách tiếp cận này là (a) ít lo ngại rằng chế độ xem này sẽ sớm biến mất, (b) bản thân chế độ xem được tài liệu hóa và hỗ trợ, và (c) nó sẽ chạy trên bất kỳ cơ sở dữ liệu nào trên bất kỳ phiên bản nào kể từ SQL Server 2005 mà không cần phải vượt qua ranh giới cơ sở dữ liệu (bao gồm cả cơ sở dữ liệu có sẵn).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Kế hoạch:

CTE xếp chồng
Tôi tin rằng Itzik Ben-Gan xứng đáng được ghi nhận xứng đáng cho cách tiếp cận này; về cơ bản, bạn tạo CTE với một tập hợp giá trị nhỏ, sau đó bạn tạo tích Đề-các đối với chính nó để tạo ra số hàng bạn cần. Và một lần nữa, thay vì cố gắng tạo một tập hợp liền kề như một phần của truy vấn cơ bản, chúng tôi chỉ có thể áp dụng ROW_NUMBER() đến kết quả cuối cùng.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
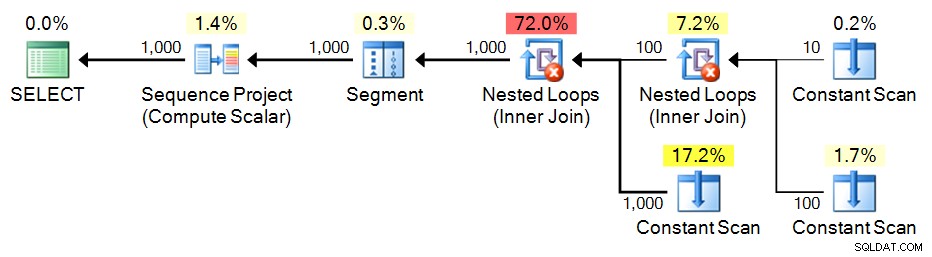
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Kế hoạch:
CTE đệ quy
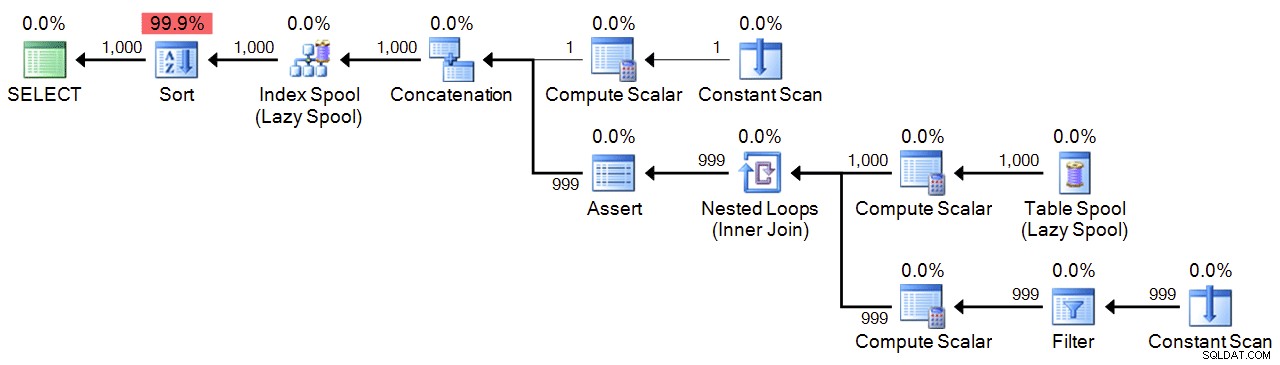
Cuối cùng, chúng ta có một CTE đệ quy, sử dụng 1 làm mỏ neo và thêm 1 cho đến khi chúng ta đạt mức tối đa. Để đảm bảo an toàn, tôi chỉ định giá trị tối đa trong cả WHERE mệnh đề của phần đệ quy và trong MAXRECURSION thiết lập. Tùy thuộc vào số lượng bạn cần, bạn có thể phải đặt MAXRECURSION thành 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Kế hoạch:
Hiệu suất
Tất nhiên với 1.000 giá trị, sự khác biệt về hiệu suất là không đáng kể, nhưng có thể hữu ích khi xem các tùy chọn khác nhau này hoạt động như thế nào:
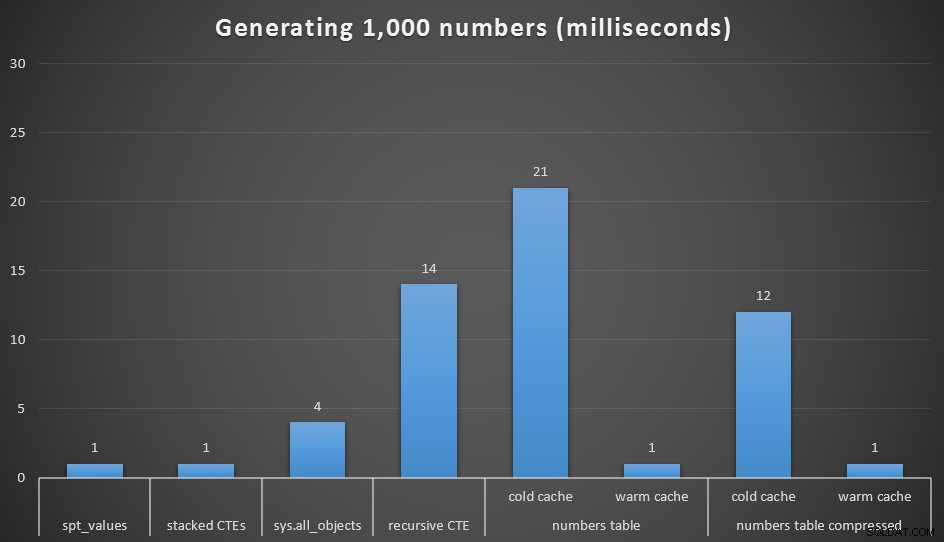
Thời gian chạy, tính bằng mili giây, để tạo 1.000 số liền kề
Tôi đã chạy mỗi truy vấn 20 lần và mất thời gian chạy trung bình. Tôi cũng đã kiểm tra dbo.Numbers bảng, ở cả hai định dạng nén và không nén, và có cả bộ đệm lạnh và bộ nhớ cache ấm. Với bộ nhớ đệm ấm áp, nó rất cạnh tranh với các tùy chọn nhanh nhất khác hiện có (spt_values , không được khuyến khích và CTE xếp chồng lên nhau), nhưng lần đánh đầu tiên tương đối đắt (mặc dù tôi gần như cười khi gọi nó như vậy).
Được tiếp tục…
Nếu đây là trường hợp sử dụng điển hình của bạn và bạn sẽ không mạo hiểm vượt quá 1.000 hàng, thì tôi hy vọng tôi đã chỉ ra những cách nhanh nhất để tạo ra những con số đó. Nếu trường hợp sử dụng của bạn là một số lớn hơn hoặc nếu bạn đang tìm kiếm các giải pháp để tạo chuỗi ngày, hãy chú ý theo dõi. Phần sau của loạt bài này, tôi sẽ khám phá việc tạo ra các chuỗi số 50.000 và 1.000.000 và phạm vi ngày từ một tuần đến một năm.
[Phần 1 | Phần 2 | Phần 3]