Giả sử bạn muốn tìm tất cả những bệnh nhân chưa từng tiêm phòng cúm. Hoặc, trong AdventureWorks2012 , một câu hỏi tương tự có thể là, "cho tôi thấy tất cả những khách hàng chưa bao giờ đặt hàng". Được thể hiện bằng NOT IN , một mẫu mà tôi thấy quá thường xuyên, trông giống như thế này (Tôi đang sử dụng tiêu đề được phóng to và các bảng chi tiết từ tập lệnh này của Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Khi tôi nhìn thấy mô hình này, tôi co rúm người lại. Nhưng không phải vì lý do hiệu suất - sau tất cả, nó tạo ra một kế hoạch đủ tốt trong trường hợp này:
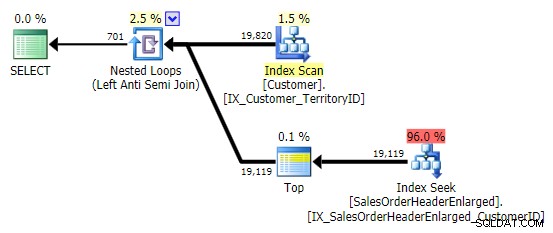
Vấn đề chính là kết quả có thể gây ngạc nhiên nếu cột mục tiêu là NULLable (SQL Server xử lý điều này như một phép nối chống bán bên trái, nhưng không thể cho bạn biết một cách đáng tin cậy nếu NULL ở phía bên phải bằng - hoặc không bằng - tài liệu tham khảo ở phía bên trái). Ngoài ra, việc tối ưu hóa có thể hoạt động khác nếu cột là NULLable, ngay cả khi nó không thực sự chứa bất kỳ giá trị NULL nào (Gail Shaw đã nói về điều này vào năm 2010).
Trong trường hợp này, cột đích không thể bị vô hiệu hóa, nhưng tôi muốn đề cập đến những vấn đề tiềm ẩn đó với NOT IN - Tôi có thể điều tra những vấn đề này kỹ lưỡng hơn trong một bài đăng trong tương lai.
TL; Phiên bản DR
Thay vì NOT IN , sử dụng NOT EXISTS tương quan cho mẫu truy vấn này. Luôn luôn. Các phương pháp khác có thể sánh ngang với nó về mặt hiệu suất, khi tất cả các biến khác đều giống nhau, nhưng tất cả các phương pháp khác đều gây ra các vấn đề về hiệu suất hoặc các thách thức khác.
Lựa chọn thay thế
Vậy chúng ta có thể viết truy vấn này theo những cách nào khác?
ÁP DỤNG NGOÀI TRỜI
Một cách chúng ta có thể thể hiện kết quả này là sử dụng OUTER APPLY có tương quan .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Về mặt logic, đây cũng là một phép nối bán chống bên trái, nhưng kế hoạch kết quả thiếu toán tử phép nối bán bên trái và có vẻ đắt hơn một chút so với NOT IN tương đương. Điều này là do nó không còn là một tham gia chống bán bên trái nữa; nó thực sự được xử lý theo một cách khác:một phép nối bên ngoài mang lại tất cả các hàng phù hợp và không khớp và * sau đó * một bộ lọc được áp dụng để loại bỏ các hàng phù hợp:
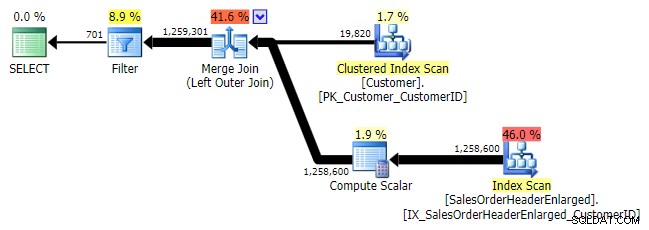
THAM GIA BÊN NGOÀI TRÁI
Một giải pháp thay thế điển hình hơn là LEFT OUTER JOIN trong đó phía bên phải là NULL . Trong trường hợp này, truy vấn sẽ là:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Điều này trả về kết quả tương tự; tuy nhiên, giống như ÁP DỤNG NGOÀI TRỜI, nó sử dụng cùng một kỹ thuật nối tất cả các hàng và chỉ sau đó loại bỏ các kết quả phù hợp:
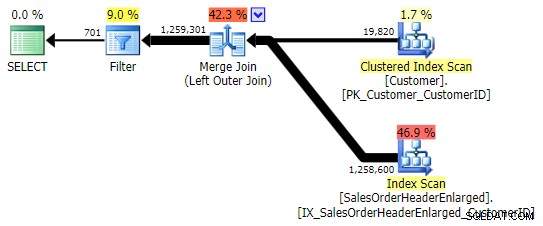
Tuy nhiên, bạn cần phải cẩn thận về cột mà bạn kiểm tra cho NULL . Trong trường hợp này CustomerID là sự lựa chọn hợp lý vì nó là cột tham gia; nó cũng tình cờ được lập chỉ mục. Tôi có thể đã chọn SalesOrderID , là khóa phân cụm, vì vậy nó cũng nằm trong chỉ mục trên CustomerID . Nhưng tôi có thể đã chọn một cột khác không có trong (hoặc cột đó sau này bị xóa khỏi) chỉ mục được sử dụng cho phép nối, dẫn đến một kế hoạch khác. Hoặc thậm chí một cột NULLable, dẫn đến kết quả không chính xác (hoặc ít nhất là không mong muốn), vì không có cách nào để phân biệt giữa hàng không tồn tại và hàng tồn tại nhưng cột đó ở đâu NULL . Và người đọc / nhà phát triển / trình khắc phục sự cố có thể không rõ ràng là trường hợp này. Vì vậy, tôi cũng sẽ kiểm tra ba WHERE này mệnh đề:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
Biến thể đầu tiên tạo ra cùng một kế hoạch như trên. Hai phần còn lại chọn một phép nối băm thay vì một phép nối hợp nhất và một chỉ mục hẹp hơn trong Customer bảng, ngay cả khi truy vấn cuối cùng kết thúc việc đọc cùng một số lượng trang và lượng dữ liệu. Tuy nhiên, trong khi h.SubTotal biến thể tạo ra kết quả chính xác:
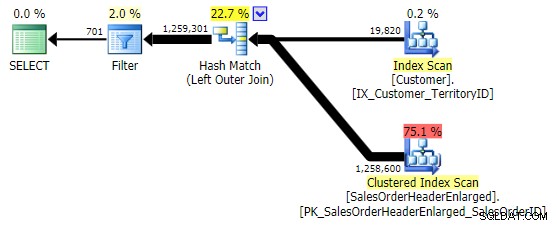
h.Comment thì không, vì nó bao gồm tất cả các hàng mà h.Comment IS NULL , cũng như tất cả các hàng không tồn tại cho bất kỳ khách hàng nào. Tôi đã đánh dấu sự khác biệt nhỏ về số hàng trong đầu ra sau khi bộ lọc được áp dụng:
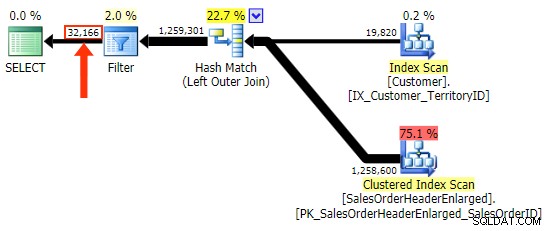
Ngoài việc cần phải cẩn thận về việc lựa chọn cột trong bộ lọc, vấn đề khác mà tôi gặp phải với LEFT OUTER JOIN hình thức là nó không tự lập tài liệu, giống như cách mà một liên kết bên trong ở dạng "kiểu cũ" của FROM dbo.table_a, dbo.table_b WHERE ... không phải là tài liệu tự. Điều đó có nghĩa là tôi rất dễ quên tiêu chí tham gia khi nó được đẩy đến WHERE hoặc để nó bị trộn lẫn với các tiêu chí lọc khác. Tôi nhận ra điều này là khá chủ quan, nhưng nó là có.
NGOẠI TRỪ
Nếu tất cả những gì chúng ta quan tâm là cột tham gia (theo định nghĩa nằm trong cả hai bảng), chúng ta có thể sử dụng EXCEPT - một giải pháp thay thế dường như không xuất hiện nhiều trong các cuộc hội thoại này (có thể vì - thông thường - bạn cần mở rộng truy vấn để bao gồm các cột mà bạn không so sánh):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Điều này đưa ra cùng một kế hoạch với NOT IN biến thể ở trên:
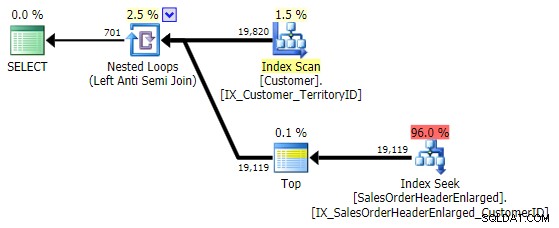
Một điều cần ghi nhớ là EXCEPT bao gồm một DISTINCT ngầm hiểu - vì vậy nếu bạn gặp trường hợp bạn muốn nhiều hàng có cùng giá trị trong bảng "bên trái", biểu mẫu này sẽ loại bỏ các hàng trùng lặp đó. Không phải là vấn đề trong trường hợp cụ thể này, chỉ là điều cần lưu ý - giống như UNION so với UNION ALL .
KHÔNG TỒN TẠI
Sở thích của tôi cho mẫu này chắc chắn là NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(Và có, tôi sử dụng SELECT 1 thay vì SELECT * … Không phải vì lý do hiệu suất, vì SQL Server không quan tâm (các) cột bạn sử dụng bên trong EXISTS và tối ưu hóa chúng đi, nhưng chỉ để làm rõ ý định:điều này nhắc tôi rằng "truy vấn con" này thực sự không trả về bất kỳ dữ liệu nào.)
Hiệu suất của nó tương tự như NOT IN và EXCEPT và nó tạo ra một kế hoạch giống hệt nhau, nhưng không dễ xảy ra các vấn đề tiềm ẩn do NULL hoặc các bản sao:
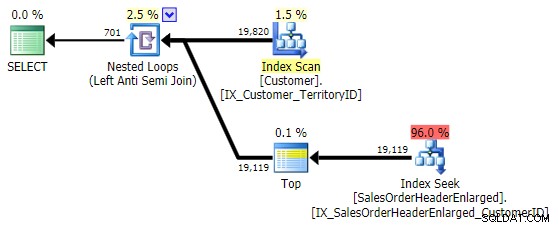
Kiểm tra hiệu suất
Tôi đã chạy vô số thử nghiệm, với cả bộ đệm lạnh và ấm, để xác nhận rằng nhận thức lâu đời của tôi về NOT EXISTS là sự lựa chọn đúng vẫn đúng. Đầu ra điển hình trông như thế này:
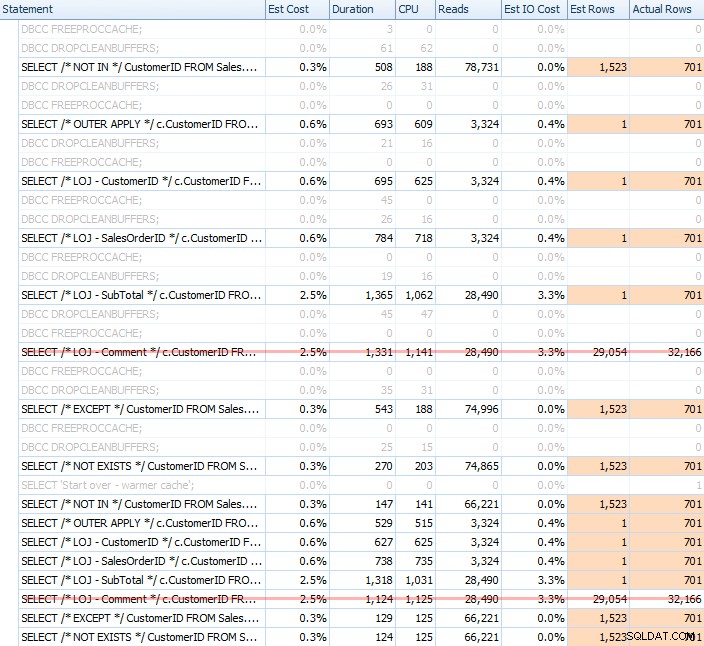
Tôi sẽ loại bỏ kết quả không chính xác khi hiển thị hiệu suất trung bình của 20 lần chạy trên biểu đồ (tôi chỉ đưa nó vào để chứng minh kết quả sai như thế nào) và tôi đã thực hiện các truy vấn theo thứ tự khác nhau trong các bài kiểm tra để đảm bảo rằng một truy vấn không thường xuyên được hưởng lợi từ công việc của một truy vấn trước đó. Tập trung vào thời lượng, đây là kết quả:
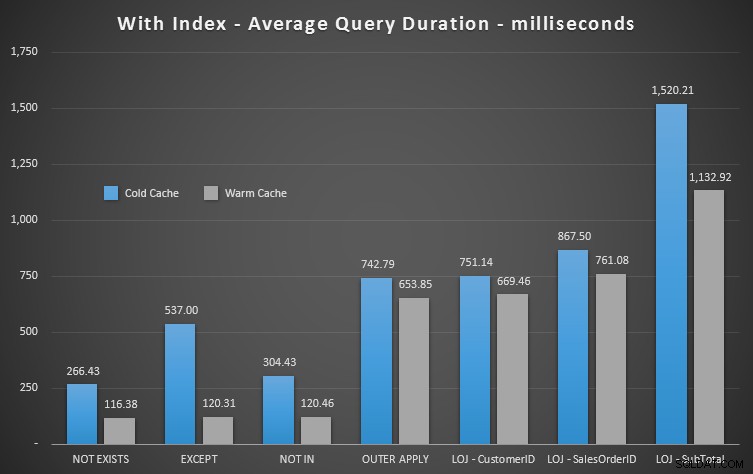
Nếu chúng tôi xem xét thời lượng và bỏ qua các lần đọc, KHÔNG TỒN TẠI là người chiến thắng của bạn, nhưng không nhiều. EXCEPT và NOT IN không kém xa, nhưng một lần nữa, bạn cần xem xét nhiều hơn hiệu suất để xác định xem các tùy chọn này có hợp lệ hay không và kiểm tra trong trường hợp của bạn.
Điều gì sẽ xảy ra nếu không có chỉ mục hỗ trợ?
Tất nhiên, các truy vấn trên được hưởng lợi từ chỉ mục trên Sales.SalesOrderHeaderEnlarged.CustomerID . Những kết quả này thay đổi như thế nào nếu chúng ta giảm chỉ số này? Tôi đã chạy lại cùng một tập hợp các bài kiểm tra, sau khi giảm chỉ mục:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Lần này có ít sai lệch hơn về mặt hiệu suất giữa các phương pháp khác nhau. Đầu tiên, tôi sẽ hiển thị các kế hoạch cho từng phương pháp (hầu hết trong số đó, không ngạc nhiên, chỉ ra mức độ hữu ích của chỉ mục bị thiếu mà chúng tôi vừa bỏ qua). Sau đó, tôi sẽ hiển thị một biểu đồ mới mô tả cấu hình hiệu suất cả với bộ đệm lạnh và bộ nhớ cache ấm.
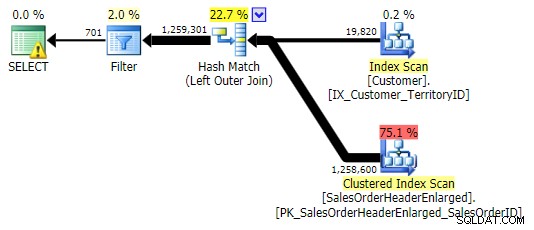
KHÔNG VÀO, NGOẠI LỆ, KHÔNG TỒN TẠI (cả ba đều giống hệt nhau)
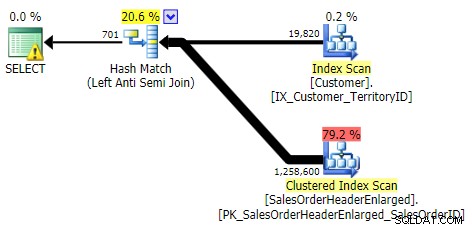
ÁP DỤNG NGOÀI TRỜI
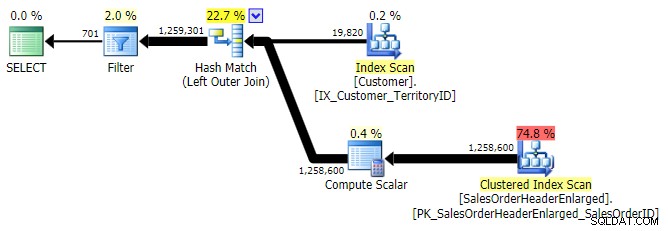
THAM GIA NGOÀI TRÁI (cả ba đều giống nhau ngoại trừ số hàng)
Kết quả hoạt động
Chúng ta có thể thấy ngay chỉ số hữu ích như thế nào khi chúng ta xem các kết quả mới này. Trong tất cả, ngoại trừ một trường hợp (liên kết ngoài bên trái vẫn nằm ngoài chỉ mục), kết quả rõ ràng là tồi tệ hơn khi chúng tôi đã bỏ chỉ mục:
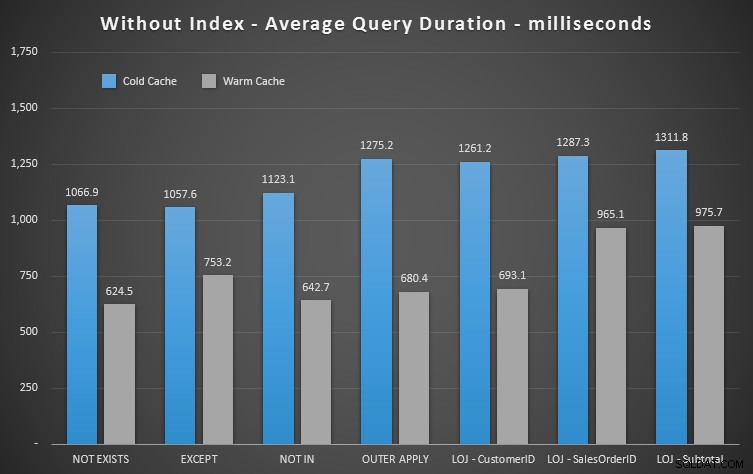
Vì vậy, chúng ta có thể thấy rằng, mặc dù có ít tác động đáng chú ý hơn, nhưng NOT EXISTS vẫn là người chiến thắng cận biên của bạn về thời lượng. Và trong những tình huống mà các phương pháp tiếp cận khác dễ bị ảnh hưởng bởi sự biến động của giản đồ, thì đó cũng là lựa chọn an toàn nhất của bạn.
Kết luận
Đây chỉ là một cách thực sự dài dòng để nói với bạn rằng, đối với mô hình tìm kiếm tất cả các hàng trong bảng A nơi một số điều kiện không tồn tại trong bảng B, NOT EXISTS thường sẽ là sự lựa chọn tốt nhất của bạn. Tuy nhiên, như mọi khi, bạn cần phải kiểm tra các mẫu này trong môi trường của riêng bạn, sử dụng lược đồ, dữ liệu và phần cứng của bạn và trộn lẫn với khối lượng công việc của riêng bạn.