Trong Phần 5 của loạt bài về biểu thức bảng, tôi đã cung cấp giải pháp sau để tạo một chuỗi số bằng CTE, một hàm tạo giá trị bảng và các phép nối chéo:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Có nhiều trường hợp sử dụng thực tế cho một công cụ như vậy, bao gồm tạo một chuỗi giá trị ngày và giờ, tạo dữ liệu mẫu, v.v. Nhận thức được nhu cầu chung, một số nền tảng cung cấp công cụ tích hợp sẵn, chẳng hạn như hàm create_series của PostgreSQL. Tại thời điểm viết bài, T-SQL không cung cấp một công cụ tích hợp sẵn như vậy, nhưng người ta luôn có thể hy vọng và bỏ phiếu cho một công cụ như vậy sẽ được thêm vào trong tương lai.
Trong một nhận xét cho bài viết của tôi, Marcos Kirchner đã đề cập rằng anh ấy đã thử nghiệm giải pháp của tôi với các cấp số của hàm tạo giá trị bảng khác nhau và có thời gian thực thi khác nhau cho các cấp số khác nhau.
 Tôi luôn sử dụng giải pháp của mình với hàm tạo giá trị bảng cơ sở có cardinality là 2, nhưng nhận xét của Marcos khiến tôi phải suy nghĩ. Công cụ này rất hữu ích nên chúng ta với tư cách là một cộng đồng nên hợp lực để thử và tạo ra phiên bản nhanh nhất có thể. Thử nghiệm các bản số của bảng cơ sở khác nhau chỉ là một chiều để thử. Có thể có nhiều người khác. Tôi sẽ trình bày các bài kiểm tra hiệu suất mà tôi đã thực hiện với giải pháp của mình. Tôi chủ yếu thử nghiệm với các thẻ số của phương thức tạo giá trị bảng khác nhau, với xử lý nối tiếp so với song song và với chế độ hàng so với xử lý chế độ hàng loạt. Tuy nhiên, có thể là một giải pháp hoàn toàn khác thậm chí còn nhanh hơn phiên bản tốt nhất của tôi. Vì vậy, thách thức là trên! Tôi đang gọi tất cả jedi, padawan, wizard và người học việc như nhau. Giải pháp hoạt động tốt nhất mà bạn có thể đề xuất là gì? Bạn có nó bên trong mình để đánh bại giải pháp nhanh nhất được đăng cho đến nay không? Nếu vậy, hãy chia sẻ của bạn dưới dạng nhận xét cho bài viết này và vui lòng cải thiện bất kỳ giải pháp nào được đăng bởi những người khác.
Tôi luôn sử dụng giải pháp của mình với hàm tạo giá trị bảng cơ sở có cardinality là 2, nhưng nhận xét của Marcos khiến tôi phải suy nghĩ. Công cụ này rất hữu ích nên chúng ta với tư cách là một cộng đồng nên hợp lực để thử và tạo ra phiên bản nhanh nhất có thể. Thử nghiệm các bản số của bảng cơ sở khác nhau chỉ là một chiều để thử. Có thể có nhiều người khác. Tôi sẽ trình bày các bài kiểm tra hiệu suất mà tôi đã thực hiện với giải pháp của mình. Tôi chủ yếu thử nghiệm với các thẻ số của phương thức tạo giá trị bảng khác nhau, với xử lý nối tiếp so với song song và với chế độ hàng so với xử lý chế độ hàng loạt. Tuy nhiên, có thể là một giải pháp hoàn toàn khác thậm chí còn nhanh hơn phiên bản tốt nhất của tôi. Vì vậy, thách thức là trên! Tôi đang gọi tất cả jedi, padawan, wizard và người học việc như nhau. Giải pháp hoạt động tốt nhất mà bạn có thể đề xuất là gì? Bạn có nó bên trong mình để đánh bại giải pháp nhanh nhất được đăng cho đến nay không? Nếu vậy, hãy chia sẻ của bạn dưới dạng nhận xét cho bài viết này và vui lòng cải thiện bất kỳ giải pháp nào được đăng bởi những người khác.
Yêu cầu:
- Triển khai giải pháp của bạn dưới dạng một hàm giá trị bảng nội tuyến (iTVF) có tên là dbo.GetNumsYourName với các tham số @low AS BIGINT và @high AS BIGINT. Để làm ví dụ, hãy xem những thứ tôi gửi ở cuối bài viết này.
- Bạn có thể tạo các bảng hỗ trợ trong cơ sở dữ liệu người dùng nếu cần.
- Bạn có thể thêm các gợi ý nếu cần.
- Như đã đề cập, giải pháp sẽ hỗ trợ các dấu phân cách thuộc loại BIGINT, nhưng bạn có thể giả định số lượng chuỗi tối đa là 4,294,967,296.
- Để đánh giá hiệu suất của giải pháp của bạn và so sánh nó với những giải pháp khác, tôi sẽ kiểm tra nó với phạm vi từ 1 đến 100.000.000, với kết quả Loại bỏ sau khi thực thi được bật trong SSMS.
Chúc may mắn cho tất cả chúng ta! Cầu mong cộng đồng tốt nhất chiến thắng.;)
Các cấp số khác nhau cho hàm tạo giá trị bảng cơ sở
Tôi đã thử nghiệm với các cấp số khác nhau của CTE cơ sở, bắt đầu bằng 2 và tăng dần theo thang logarit, bình phương các cấp số trước đó trong mỗi bước:2, 4, 16 và 256.
Trước khi bạn bắt đầu thử nghiệm với các cấp số cơ sở khác nhau, có thể hữu ích nếu có một công thức cung cấp cấp số lượng cơ sở và cấp số lượng phạm vi tối đa sẽ cho bạn biết bạn cần bao nhiêu cấp độ CTE. Ở bước sơ bộ, trước tiên, sẽ dễ dàng hơn khi đưa ra công thức cung cấp cấp độ cơ bản và số lượng cấp CTE, tính toán cấp số lượng phạm vi kết quả tối đa là bao nhiêu. Đây là một công thức được biểu thị trong T-SQL:
DECLARE @basecardinality AS INT = 2, @levels AS INT = 5; SELECT POWER(1.*@basecardinality, POWER(2., @levels));
Với các giá trị đầu vào mẫu ở trên, biểu thức này mang lại một dãy số tối đa là 4,294,967,296.
Sau đó, công thức nghịch đảo để tính số mức CTE cần thiết liên quan đến việc lồng hai hàm nhật ký, như sau:
DECLARE @basecardinality AS INT = 2, @seriescardinality AS BIGINT = 4294967296; SELECT CEILING(LOG(LOG(@seriescardinality, @basecardinality), 2));
Với các giá trị đầu vào mẫu ở trên, biểu thức này cho kết quả là 5. Lưu ý rằng số này ngoài CTE cơ sở còn có hàm tạo giá trị bảng mà tôi đã đặt tên là L0 (cho cấp 0) trong giải pháp của mình.
Đừng hỏi tôi làm thế nào tôi có được những công thức này. Câu chuyện mà tôi gắn bó là Gandalf đã nói chúng với tôi ở Elvish trong giấc mơ của tôi.
Hãy tiến hành kiểm tra hiệu suất. Đảm bảo rằng bạn bật Loại bỏ kết quả sau khi thực thi trong hộp thoại Tùy chọn truy vấn SSMS trong Lưới, Kết quả. Sử dụng mã sau để chạy thử nghiệm với số lượng CTE cơ bản là 2 (yêu cầu thêm 5 cấp CTE):
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Tôi nhận được kế hoạch được hiển thị trong Hình 1 cho việc thực thi này.
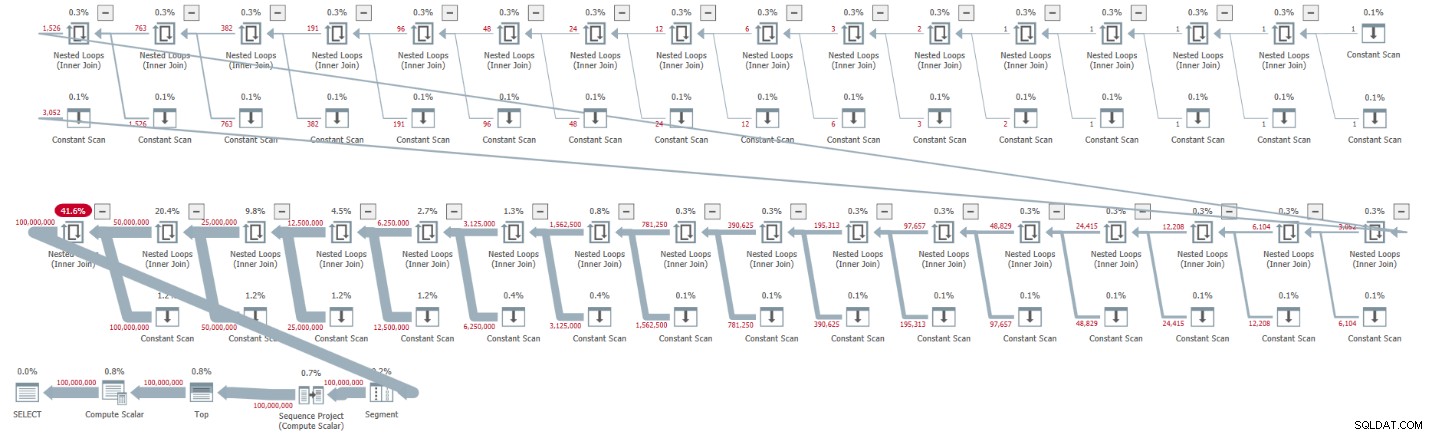 Hình 1:Kế hoạch cho số lượng CTE cơ sở của 2
Hình 1:Kế hoạch cho số lượng CTE cơ sở của 2
Kế hoạch là nối tiếp và tất cả các toán tử trong kế hoạch sử dụng xử lý chế độ hàng theo mặc định. Nếu bạn đang nhận được một kế hoạch song song theo mặc định, ví dụ:khi gói giải pháp trong iTVF và sử dụng một phạm vi lớn, thì bây giờ hãy bắt buộc một kế hoạch nối tiếp với gợi ý MAXDOP 1.
Quan sát cách giải nén các CTE dẫn đến 32 trường hợp của toán tử Quét liên tục, mỗi trường hợp đại diện cho một bảng có hai hàng.
Tôi nhận được thống kê hiệu suất sau cho lần thực thi này:
CPU time = 30188 ms, elapsed time = 32844 ms.
Sử dụng mã sau để kiểm tra giải pháp với số lượng CTE cơ bản là 4, theo công thức của chúng tôi yêu cầu bốn cấp độ CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L4 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Tôi nhận được kế hoạch được hiển thị trong Hình 2 cho việc thực thi này.
 Hình 2:Kế hoạch cho số lượng CTE cơ sở của 4
Hình 2:Kế hoạch cho số lượng CTE cơ sở của 4
Việc giải nén CTE dẫn đến 16 toán tử Quét liên tục, mỗi toán tử đại diện cho một bảng gồm 4 hàng.
Tôi nhận được thống kê hiệu suất sau cho lần thực thi này:
CPU time = 23781 ms, elapsed time = 25435 ms.
Đây là một sự cải thiện đáng kể 22,5% so với giải pháp trước đó.
Kiểm tra số liệu thống kê chờ được báo cáo cho truy vấn, loại chờ chủ đạo là SOS_SCHEDULER_YIELD. Thật vậy, số lượt chờ đã giảm 22,8% so với giải pháp đầu tiên một cách kỳ lạ (số lượt chờ là 15.280 so với 19.800).
Sử dụng mã sau để kiểm tra giải pháp với số lượng CTE cơ bản là 16, theo công thức của chúng tôi yêu cầu ba mức CTE:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Tôi nhận được kế hoạch được hiển thị trong Hình 3 cho việc thực thi này.
 Hình 3:Kế hoạch cho số lượng CTE cơ sở của 16
Hình 3:Kế hoạch cho số lượng CTE cơ sở của 16
Lần này, việc giải nén CTE dẫn đến 8 toán tử Quét liên tục, mỗi toán tử đại diện cho một bảng có 16 hàng.
Tôi nhận được thống kê hiệu suất sau cho lần thực thi này:
CPU time = 22968 ms, elapsed time = 24409 ms.
Giải pháp này tiếp tục giảm thời gian trôi qua, mặc dù chỉ thêm một vài phần trăm, giảm 25,7 phần trăm so với giải pháp đầu tiên. Một lần nữa, số lần chờ của loại chờ SOS_SCHEDULER_YIELD tiếp tục giảm (12,938).
Nâng cao trong thang đo logarit của chúng tôi, bài kiểm tra tiếp theo liên quan đến tổng số CTE cơ sở là 256. Nó dài và xấu, nhưng hãy thử:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L2 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Tôi nhận được kế hoạch được hiển thị trong Hình 4 cho việc thực thi này.
 Hình 4:Kế hoạch cho số lượng CTE cơ sở là 256
Hình 4:Kế hoạch cho số lượng CTE cơ sở là 256
Lần này, việc giải nén CTE chỉ dẫn đến bốn toán tử Quét liên tục, mỗi toán tử có 256 hàng.
Tôi nhận được các số hiệu suất sau cho việc thực thi này:
CPU time = 23516 ms, elapsed time = 25529 ms.
Lần này, có vẻ như hiệu suất đã giảm một chút so với giải pháp trước với số lượng CTE cơ bản là 16. Thật vậy, số lần chờ của kiểu chờ SOS_SCHEDULER_YIELD đã tăng lên một chút lên 13,176. Vì vậy, có vẻ như chúng tôi đã tìm thấy con số vàng của mình — 16!
Kế hoạch song song và nối tiếp
Tôi đã thử nghiệm với việc bắt buộc một kế hoạch song song bằng cách sử dụng gợi ý ENABLE_PARALLEL_PLAN_PREFERENCE, nhưng cuối cùng nó đã làm giảm hiệu suất. Trên thực tế, khi triển khai giải pháp dưới dạng iTVF, tôi nhận được một kế hoạch song song trên máy của mình theo mặc định cho các phạm vi lớn và phải bắt buộc một kế hoạch nối tiếp với gợi ý MAXDOP 1 để có được hiệu suất tối ưu.
Xử lý hàng loạt
Tài nguyên chính được sử dụng trong các kế hoạch cho các giải pháp của tôi là CPU. Cho rằng xử lý hàng loạt là để cải thiện hiệu quả của CPU, đặc biệt là khi xử lý với số lượng lớn hàng, bạn nên thử tùy chọn này. Hoạt động chính ở đây có thể được hưởng lợi từ xử lý hàng loạt là tính toán số hàng. Tôi đã thử nghiệm các giải pháp của mình trong phiên bản SQL Server 2019 Enterprise. SQL Server đã chọn xử lý chế độ hàng cho tất cả các giải pháp được hiển thị trước đó theo mặc định. Rõ ràng, giải pháp này đã không vượt qua các kinh nghiệm cần thiết để bật chế độ hàng loạt trên cửa hàng hàng. Có một số cách để SQL Server sử dụng xử lý hàng loạt ở đây.
Tùy chọn 1 là liên quan đến một bảng có chỉ mục cột trong giải pháp. Bạn có thể đạt được điều này bằng cách tạo một bảng giả với chỉ mục cột cửa hàng và giới thiệu một liên kết giả bên trái trong truy vấn ngoài cùng giữa Nums CTE của chúng tôi và bảng đó. Đây là định nghĩa bảng giả:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Sau đó, sửa lại truy vấn bên ngoài so với Nums để sử dụng FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Dưới đây là ví dụ về số lượng CTE cơ bản là 16:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Tôi nhận được kế hoạch được hiển thị trong Hình 5 cho việc thực thi này.
 Hình 5:Lập kế hoạch xử lý hàng loạt
Hình 5:Lập kế hoạch xử lý hàng loạt
Quan sát việc sử dụng toán tử Window Aggregate ở chế độ hàng loạt để tính toán các số hàng. Cũng lưu ý rằng kế hoạch không liên quan đến bảng giả. Trình tối ưu hóa đã tối ưu hóa nó.
Ưu điểm của tùy chọn 1 là nó hoạt động trong tất cả các phiên bản SQL Server và có liên quan trong SQL Server 2016 trở lên, kể từ khi toán tử Window Aggregate ở chế độ hàng loạt được giới thiệu trong SQL Server 2016. Nhược điểm là cần phải tạo bảng giả và bao gồm nó trong giải pháp.
Tùy chọn 2 để xử lý hàng loạt cho giải pháp của chúng tôi, với điều kiện bạn đang sử dụng phiên bản SQL Server 2019 Enterprise, là sử dụng gợi ý tự giải thích không có tài liệu OVERRIDE_BATCH_MODE_HEURISTICS (chi tiết trong bài viết của Dmitry Pilugin), như sau:
DECLARE @low AS BIGINT = 1, @high AS BIGINT = 100000000;
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum
OPTION(USE HINT('OVERRIDE_BATCH_MODE_HEURISTICS')); Ưu điểm của tùy chọn 2 là bạn không cần tạo bảng giả và đưa nó vào giải pháp của bạn. Nhược điểm là bạn cần sử dụng phiên bản Enterprise, sử dụng SQL Server 2019 tối thiểu khi chế độ hàng loạt trên cửa hàng đã được giới thiệu và giải pháp liên quan đến việc sử dụng gợi ý không có tài liệu. Vì những lý do này, tôi thích lựa chọn 1.
Dưới đây là các con số hiệu suất mà tôi nhận được cho các bản chất CTE cơ bản khác nhau:
Cardinality 2: CPU time = 21594 ms, elapsed time = 22743 ms (down from 32844). Cardinality 4: CPU time = 18375 ms, elapsed time = 19394 ms (down from 25435). Cardinality 16: CPU time = 17640 ms, elapsed time = 18568 ms (down from 24409). Cardinality 256: CPU time = 17109 ms, elapsed time = 18507 ms (down from 25529).
Hình 6 so sánh hiệu suất giữa các giải pháp khác nhau:
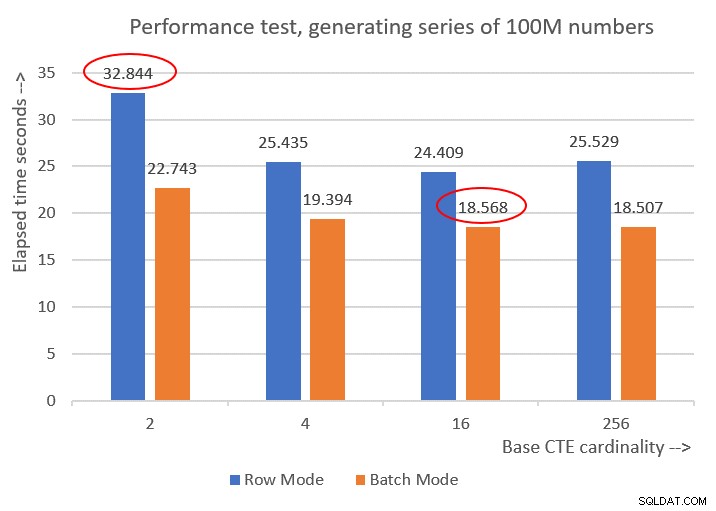 Hình 6:So sánh hiệu suất
Hình 6:So sánh hiệu suất
Bạn có thể quan sát thấy sự cải thiện hiệu suất đáng kể từ 20-30 phần trăm so với các đối tác ở chế độ hàng.
Thật kỳ lạ, với chế độ xử lý hàng loạt, giải pháp với số lượng cơ sở CTE là 256 đã hoạt động tốt nhất. Tuy nhiên, nó chỉ nhanh hơn một chút so với giải pháp có số lượng CTE cơ bản là 16. Sự khác biệt là rất nhỏ và giải pháp thứ hai có lợi thế rõ ràng về độ ngắn gọn của mã, mà tôi muốn tuân theo 16.
Vì vậy, nỗ lực điều chỉnh của tôi cuối cùng đã mang lại mức cải thiện 43,5% so với giải pháp ban đầu với số lượng cơ sở là 2 bằng cách sử dụng xử lý chế độ hàng.
Thử thách đang diễn ra!
Tôi gửi hai giải pháp như là sự đóng góp của cộng đồng cho thử thách này. Nếu bạn đang chạy trên SQL Server 2016 trở lên và có thể tạo bảng trong cơ sở dữ liệu người dùng, hãy tạo bảng giả sau:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Và sử dụng định nghĩa iTVF sau:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Sử dụng mã sau để kiểm tra nó (đảm bảo có kết quả Loại bỏ sau khi kiểm tra thực thi):
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Mã này hoàn thành sau 18 giây trên máy của tôi.
Nếu vì lý do nào đó mà bạn không thể đáp ứng các yêu cầu của giải pháp xử lý hàng loạt, tôi gửi định nghĩa chức năng sau làm giải pháp thứ hai của mình:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Sử dụng mã sau để kiểm tra nó:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Mã này hoàn thành sau 24 giây trên máy của tôi.
Đến lượt bạn!