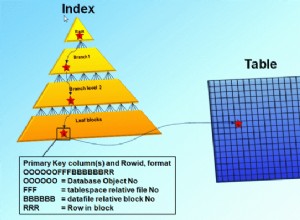
Trong bài đăng cuối cùng của tôi ("Anh bạn, ai sở hữu bảng #temp đó?"), Tôi đã đề xuất rằng trong SQL Server 2012 trở lên, bạn có thể sử dụng Sự kiện mở rộng để theo dõi việc tạo bảng #temp. Điều này sẽ cho phép bạn so sánh các đối tượng cụ thể chiếm nhiều dung lượng trong tempdb với phiên đã tạo ra chúng (ví dụ:để xác định xem phiên có thể bị hủy hay không để cố gắng giải phóng dung lượng). Điều tôi không thảo luận là chi phí của việc theo dõi này - chúng tôi hy vọng Sự kiện mở rộng sẽ nhẹ hơn so với theo dõi, nhưng không có giám sát nào là hoàn toàn miễn phí.
Vì hầu hết mọi người để lại dấu vết mặc định được kích hoạt, chúng tôi sẽ giữ nguyên vị trí đó. Chúng tôi sẽ kiểm tra cả hai heap bằng cách sử dụng SELECT INTO (mà theo dõi mặc định sẽ không thu thập) và các chỉ mục nhóm (mà nó sẽ thu thập), và chúng tôi sẽ tính thời gian của lô đó làm đường cơ sở, sau đó chạy lại lô với phiên Sự kiện mở rộng đang chạy. Chúng tôi cũng sẽ kiểm tra cả SQL Server 2012 và SQL Server 2014. Bản thân lô này khá đơn giản:
ĐẶT SỐ TÀI KHOẢN BẬT; SELECT SYSDATETIME (); GO - chỉ chạy phần này cho lô heap:CHỌN ĐẦU (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #foo; - chỉ chạy phần này cho lô CIX:CREATE TABLE #bar (id INT PRIMARY KEY); INSERT #bar (id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #bar; ĐI 100000 CHỌN SYSDATETIME ();
Cả hai phiên bản đều có tempdb được định cấu hình với bốn tệp dữ liệu và với TF 1117 và TF 1118 được kích hoạt, trong một máy ảo có bốn CPU, 16GB bộ nhớ và chỉ có SSD. Tôi đã cố ý tạo các bảng #temp nhỏ để khuếch đại bất kỳ tác động nào quan sát được đối với chính lô đó (điều này sẽ bị át đi nếu việc tạo bảng #temp mất nhiều thời gian hoặc gây ra quá nhiều sự kiện tự động phát triển).
Tôi đã chạy các lô này trong từng tình huống và đây là kết quả, được đo bằng thời lượng lô tính bằng giây:
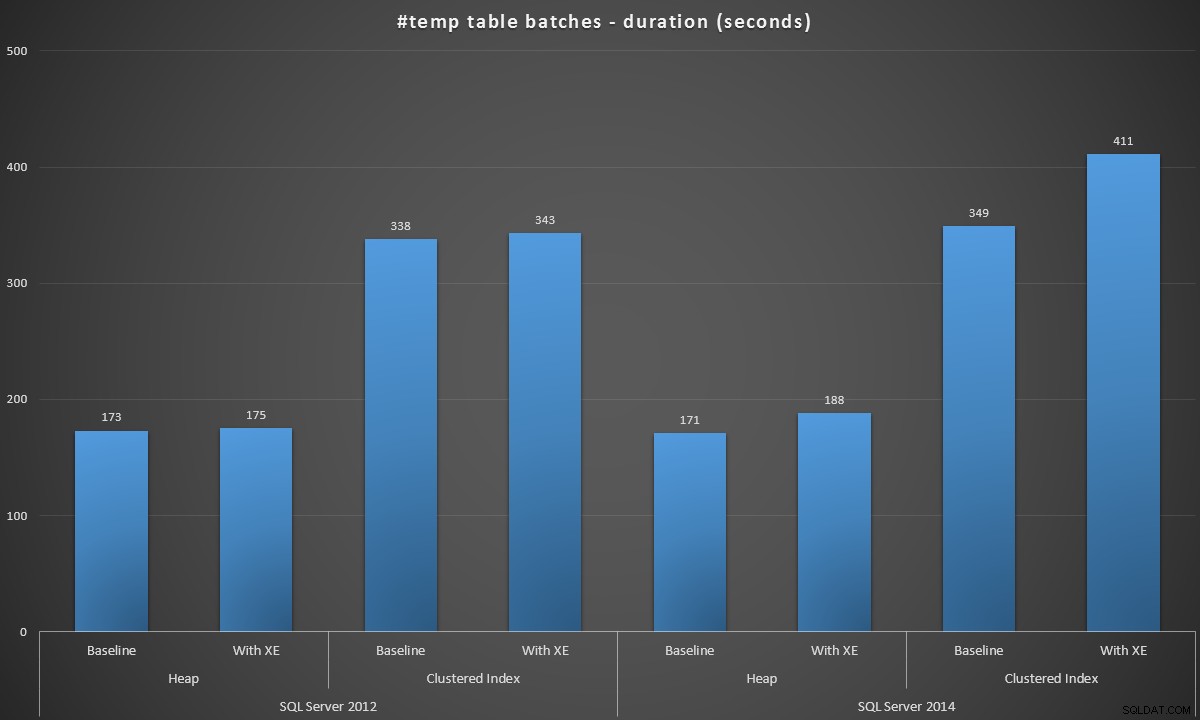
Thời lượng hàng loạt, tính bằng giây, tạo 100.000 bảng #temp
Biểu thị dữ liệu hơi khác một chút, nếu chúng ta chia 100.000 cho thời lượng, chúng ta có thể hiển thị số bảng #temp mà chúng ta có thể tạo mỗi giây trong mỗi kịch bản (đọc:thông lượng). Đây là những kết quả:
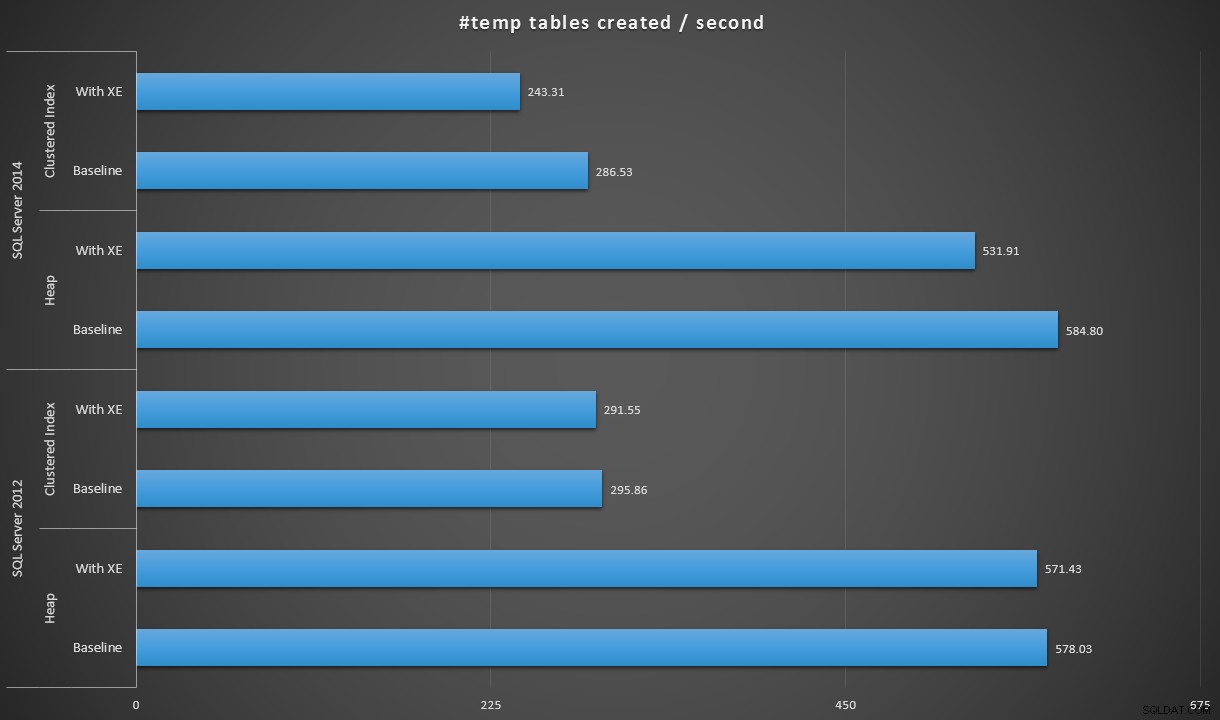
#temp bảng được tạo mỗi giây theo từng tình huống
Kết quả khiến tôi hơi ngạc nhiên - tôi mong đợi rằng, với những cải tiến của SQL Server 2014 trong logic ghi háo hức, ít nhất thì dân số heap sẽ chạy nhanh hơn rất nhiều. Tổng số trong năm 2014 nhanh hơn hai giây so với năm 2012 ở cấu hình cơ sở, nhưng Sự kiện mở rộng đã làm tăng thời gian lên khá nhiều (tăng khoảng 10% so với đường cơ sở); trong khi thời gian lập chỉ mục theo nhóm có thể so sánh với năm 2012 ở đường cơ sở, nhưng đã tăng gần 18% khi bật Sự kiện mở rộng. Trong năm 2012, tỷ lệ đồng bằng cho chỉ mục đống và chỉ mục nhóm khiêm tốn hơn nhiều - lần lượt là 1,1% và 1,5%. (Và rõ ràng là không có sự kiện tự động duyệt nào xảy ra trong bất kỳ thử nghiệm nào.)
Vì vậy, tôi nghĩ, điều gì sẽ xảy ra nếu tôi tạo một phiên Sự kiện mở rộng gọn gàng hơn? Chắc chắn tôi có thể xóa một số cột hành động đó - có thể tôi chỉ cần tên đăng nhập và spid, đồng thời có thể bỏ qua tên ứng dụng, tên máy chủ và sql_text có khả năng đắt tiền. Có lẽ tôi có thể bỏ bộ lọc bổ sung so với cam kết (thu thập gấp đôi số sự kiện, nhưng CPU dành ít hơn cho bộ lọc) và cho phép mất nhiều sự kiện để giảm tác động tiềm ẩn đến khối lượng công việc. Phiên gọn gàng hơn này trông giống như sau:
TẠO PHIÊN BẢN SỰ KIỆN [TempTableCreation2014_LeanerMeaner] TRÊN MÁY CHỦ THÊM SỰ KIỆN sqlserver.object_create (ACTION (sqlserver.server_principal_name, sqlserver.session_id) WHERE (sqlserver.like_i_sql_với_nói_nữ_dịch_số_tập_tập_trong_nói_nói_mẫu_dịch_tập_gói (SET FILENAME ='c:\ temp \ TempTableCreation2014_LeanerMeaner.xel', MAX_FILE_SIZE =32768, MAX_ROLLOVER_FILES =10) VỚI (EVENT_RETENTION_MODE =ALLOW_MULTIPLE_EVENT_LOSS); MỤC TIÊU =BẮT ĐẦU SỰ KIỆN;Than ôi, không, kết quả tương tự. Chỉ hơn ba phút cho heap và chỉ dưới bảy phút cho chỉ mục nhóm. Để tìm hiểu sâu hơn về nơi đã dành thêm thời gian, tôi đã xem phiên bản 2014 với SQL Sentry và chỉ chạy lô chỉ mục được phân cụm mà không có bất kỳ phiên Sự kiện mở rộng nào được định cấu hình. Sau đó, tôi chạy lại lô, lần này với phiên XE nhẹ hơn được cấu hình. Thời gian của lô là 5:47 (347 giây) và 6:55 (415 giây) - rất phù hợp với lô trước (Tôi rất vui khi thấy rằng quá trình theo dõi của chúng tôi không đóng góp thêm gì vào thời lượng :-)) . Tôi đã xác thực rằng không có sự kiện nào bị bỏ qua và một lần nữa rằng không có sự kiện tự động duyệt nào xảy ra.
Tôi đã xem bảng điều khiển SQL Sentry ở chế độ lịch sử, cho phép tôi xem nhanh số liệu hiệu suất của cả hai lô cạnh nhau:
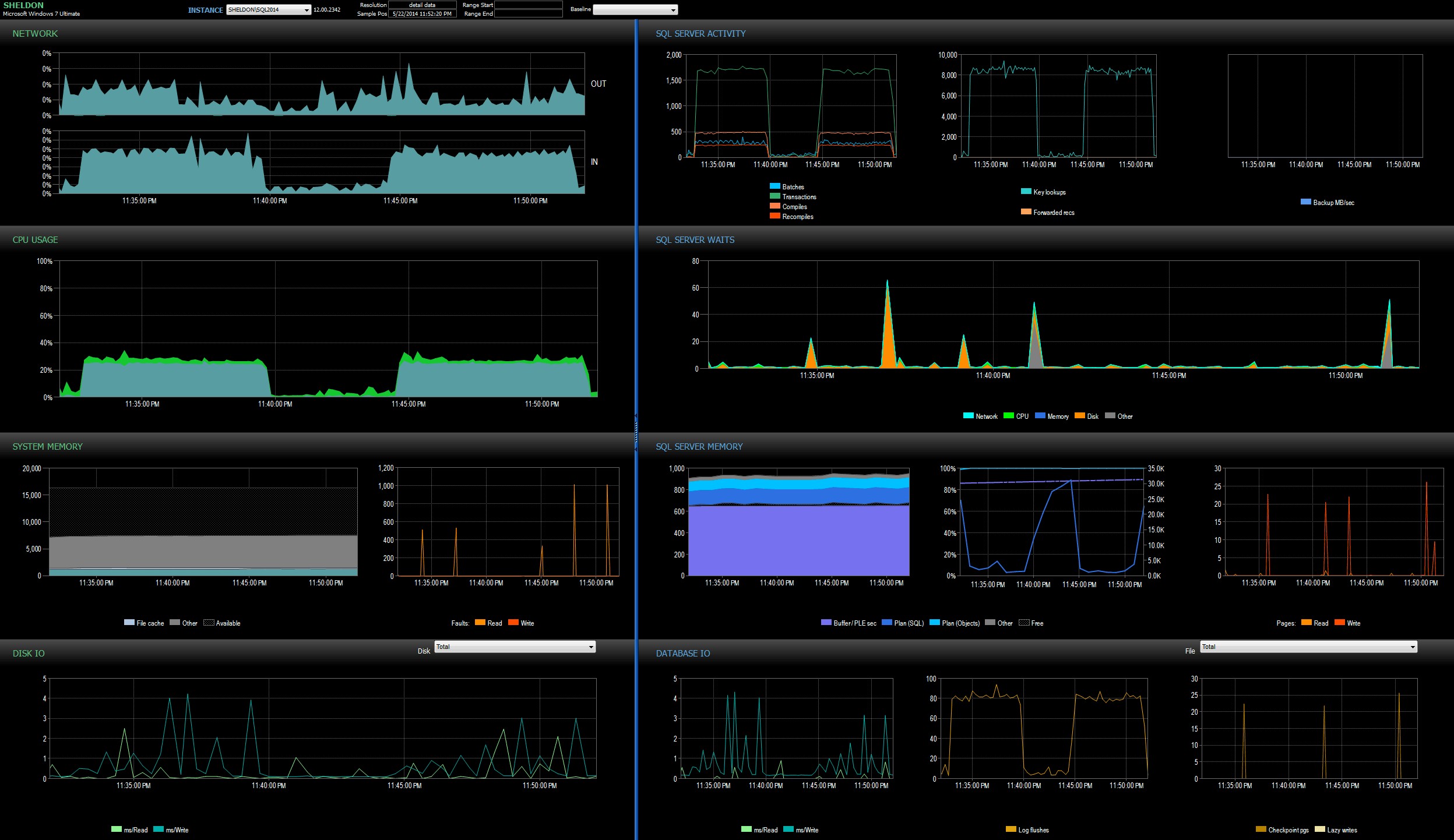
Bảng điều khiển SQL Sentry, ở chế độ lịch sử, hiển thị cả hai đợtCả hai lô hầu như giống hệt nhau về mạng, CPU, giao dịch, biên dịch, tra cứu khóa, v.v. Có một số khác biệt nhỏ trong Chờ đợi - mức tăng đột biến trong lô đầu tiên chỉ là WRITELOG, trong khi có một số lần chờ CXPACKET nhỏ được tìm thấy trong lô thứ hai. Lý thuyết hoạt động tốt của tôi sau nửa đêm là có lẽ một phần tốt của sự chậm trễ quan sát được là do chuyển đổi ngữ cảnh do quy trình Sự kiện mở rộng gây ra. Vì chúng tôi không có bất kỳ khả năng hiển thị chính xác những gì XE đang làm dưới vỏ bọc, cũng như không biết những gì cơ chế cơ bản đã thay đổi trong XE từ năm 2012 đến năm 2014, đó là câu chuyện tôi sẽ gắn bó cho đến bây giờ, cho đến khi tôi thoải mái hơn với xperf và / hoặc WinDbg.
Kết luận
Trong mọi trường hợp, rõ ràng là việc theo dõi tạo bảng #temp không miễn phí và chi phí có thể thay đổi tùy thuộc vào loại bảng #temp bạn đang tạo, lượng thông tin bạn đang thu thập trong các phiên XE của mình và thậm chí cả phiên bản của SQL Server bạn đang sử dụng. Vì vậy, bạn có thể chạy các bài kiểm tra tương tự như những gì tôi đã thực hiện ở đây và quyết định việc thu thập thông tin này có giá trị như thế nào trong môi trường của bạn.