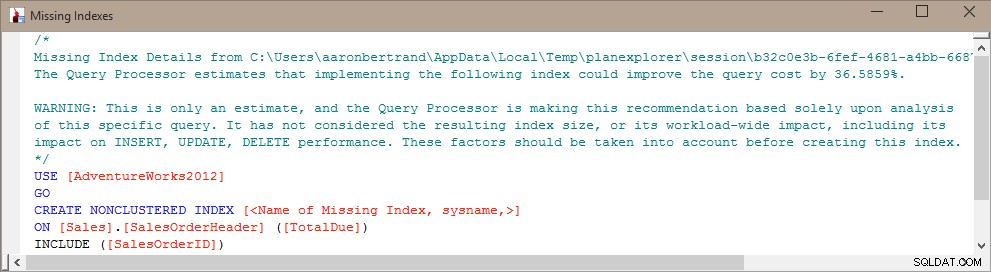
Kevin Kline (@kekline) và tôi gần đây đã tổ chức một hội thảo trên web về điều chỉnh truy vấn (thực ra là một trong một loạt bài), và một trong những điều xuất hiện là xu hướng của mọi người là tạo bất kỳ chỉ mục nào bị thiếu mà SQL Server cho họ biết. một điều tốt ™ . Họ có thể tìm hiểu về các chỉ mục bị thiếu này từ Cố vấn điều chỉnh công cụ cơ sở dữ liệu (DTA), các DMV chỉ mục bị thiếu hoặc kế hoạch thực thi được hiển thị trong Management Studio hoặc Plan Explorer (tất cả đều chỉ chuyển tiếp thông tin từ chính xác cùng một nơi):
Vấn đề với việc chỉ tạo chỉ mục này một cách mù quáng là SQL Server đã quyết định rằng nó hữu ích cho một truy vấn cụ thể (hoặc một số truy vấn), nhưng hoàn toàn và đơn phương bỏ qua phần còn lại của khối lượng công việc. Như chúng ta đã biết, các chỉ mục không phải là "miễn phí" - bạn phải trả tiền cho các chỉ mục cả trong lưu trữ thô cũng như yêu cầu bảo trì đối với các hoạt động DML. Việc thêm một chỉ mục giúp làm cho một truy vấn hiệu quả hơn một chút sẽ không có ý nghĩa gì, đặc biệt nếu truy vấn đó không được chạy thường xuyên. Trong những trường hợp này, điều rất quan trọng là phải hiểu khối lượng công việc tổng thể của bạn và đạt được sự cân bằng tốt giữa việc thực hiện các truy vấn của bạn hiệu quả và không phải trả quá nhiều cho việc đó về mặt duy trì chỉ mục.
Vì vậy, tôi có ý tưởng là "trộn" thông tin từ các DMV chỉ mục bị thiếu, DMV thống kê sử dụng chỉ mục và thông tin về các kế hoạch truy vấn, để xác định loại số dư hiện đang tồn tại và cách thêm chỉ mục có thể tính tổng thể.
Thiếu chỉ mục
Đầu tiên, chúng ta có thể xem xét các chỉ mục còn thiếu mà SQL Server hiện đang đề xuất:
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
Điều này cho thấy (các) bảng và (các) cột sẽ hữu ích trong một chỉ mục, số lượng biên dịch / tìm kiếm / quét sẽ được sử dụng và thời điểm sự kiện như vậy cuối cùng xảy ra cho mỗi chỉ mục tiềm năng. Bạn cũng có thể bao gồm các cột như s.avg_total_user_cost và s.avg_user_impact nếu bạn muốn sử dụng những số liệu đó để ưu tiên.
Lập kế hoạch hoạt động
Tiếp theo, hãy xem xét các thao tác được sử dụng trong tất cả các kế hoạch mà chúng tôi đã lưu vào bộ nhớ đệm dựa trên các đối tượng đã được xác định bởi các chỉ mục còn thiếu của chúng tôi.
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; Một người bạn trên dba.SE, Mikael Eriksson, đã đề xuất hai truy vấn sau đây, trên một hệ thống lớn hơn, sẽ hoạt động tốt hơn nhiều so với truy vấn XML / UNION mà tôi đã tập hợp ở trên, vì vậy bạn có thể thử nghiệm với những truy vấn đó trước. Nhận xét kết thúc của anh ấy là anh ấy "không ngạc nhiên khi phát hiện ra rằng ít XML hơn là một điều tốt cho hiệu suất. :)" Thật vậy.
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
Bây giờ trong #planops bảng bạn có nhiều giá trị cho plan_handle để bạn có thể đi và điều tra từng kế hoạch riêng lẻ để chống lại các đối tượng đã được xác định là thiếu một số chỉ mục hữu ích. Chúng tôi sẽ không sử dụng nó cho việc đó ngay bây giờ, nhưng bạn có thể dễ dàng tham khảo chéo điều này với:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
Bây giờ bạn có thể nhấp vào bất kỳ kế hoạch đầu ra nào để xem chúng hiện đang làm gì với các đối tượng của bạn. Lưu ý rằng một số kế hoạch sẽ được lặp lại, vì một kế hoạch có thể có nhiều toán tử tham chiếu đến các chỉ mục khác nhau trên cùng một bảng.
Thống kê sử dụng chỉ mục
Tiếp theo, hãy xem số liệu thống kê sử dụng chỉ mục, vì vậy chúng tôi có thể xem có bao nhiêu hoạt động thực tế hiện đang chạy so với các bảng ứng cử viên của chúng tôi (và đặc biệt là các bản cập nhật).
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
Đừng lo lắng nếu rất ít hoặc không có kế hoạch nào trong bộ đệm ẩn hiển thị các bản cập nhật cho một chỉ mục cụ thể, mặc dù số liệu thống kê sử dụng chỉ mục cho thấy rằng các chỉ mục đó đã được cập nhật. Điều này chỉ có nghĩa là các kế hoạch cập nhật hiện không có trong bộ nhớ cache, có thể vì nhiều lý do - ví dụ:đó có thể là một khối lượng công việc rất nặng và chúng đã bị cũ đi hoặc tất cả chúng đều đơn lẻ- sử dụng và optimize for ad hoc workloads được bật.
Kết hợp tất cả lại với nhau
Truy vấn sau đây sẽ cho bạn biết, đối với mỗi chỉ mục bị thiếu được đề xuất, số lần đọc mà một chỉ mục có thể đã hỗ trợ, số lần ghi và đọc hiện đã được ghi lại so với các chỉ mục hiện có, tỷ lệ của chúng, số lượng kế hoạch được liên kết với đối tượng đó và tổng số lần sử dụng được tính cho các kế hoạch đó:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
Nếu tỷ lệ ghi:đọc của bạn đối với các chỉ mục này đã> 1 (hoặc> 10!), Tôi nghĩ rằng điều đó sẽ cho bạn lý do để tạm dừng trước khi tạo ra một chỉ mục chỉ có thể tăng tỷ lệ này một cách mù quáng. Số lượng potential_read_ops hiển thị, tuy nhiên, có thể bù đắp điều đó khi con số trở nên lớn hơn. Nếu potential_read_ops số rất nhỏ, bạn có thể muốn bỏ qua hoàn toàn đề xuất trước khi bận tâm đến việc điều tra các số liệu khác - vì vậy bạn có thể thêm WHERE để lọc ra một số khuyến nghị đó.
Một số lưu ý:
- Đây là các hoạt động đọc và ghi, không phải là các lần đọc và ghi được đo riêng lẻ của 8K trang.
- Tỷ lệ và các so sánh chủ yếu mang tính giáo dục; rất có thể xảy ra trường hợp 10.000.000 thao tác ghi đều ảnh hưởng đến một hàng duy nhất, trong khi 10 thao tác đọc có thể có tác động nhiều hơn đáng kể. Điều này chỉ có nghĩa là một hướng dẫn sơ bộ và giả định rằng các hoạt động đọc và ghi có trọng số gần như nhau.
- Bạn cũng có thể sử dụng các biến thể nhỏ trên một số truy vấn này để tìm hiểu - ngoài các chỉ mục bị thiếu mà SQL Server đang đề xuất - có bao nhiêu chỉ mục hiện tại của bạn là lãng phí. Có rất nhiều ý tưởng về vấn đề này trên mạng, bao gồm cả bài đăng này của Paul Randal (@PaulRandal).
Tôi hy vọng điều đó sẽ cung cấp một số ý tưởng để bạn hiểu sâu hơn về hành vi của hệ thống trước khi bạn quyết định thêm chỉ mục mà một số công cụ yêu cầu bạn tạo. Tôi có thể đã tạo điều này dưới dạng một truy vấn lớn, nhưng tôi nghĩ rằng các phần riêng lẻ sẽ cung cấp cho bạn một số lỗ thỏ để điều tra, nếu bạn muốn.
Các ghi chú khác
Bạn cũng có thể muốn mở rộng điều này để nắm bắt các chỉ số kích thước hiện tại, chiều rộng của bảng và số lượng hàng hiện tại (cũng như bất kỳ dự đoán nào về tăng trưởng trong tương lai); điều này có thể cung cấp cho bạn một ý tưởng tốt về lượng không gian mà một chỉ mục mới sẽ chiếm, điều này có thể là một mối quan tâm tùy thuộc vào môi trường của bạn. Tôi có thể xử lý vấn đề này trong một bài đăng trong tương lai.
Tất nhiên, bạn phải lưu ý rằng những số liệu này chỉ hữu ích khi thời gian hoạt động của bạn ra lệnh. Các DMV sẽ bị xóa sau khi khởi động lại (và đôi khi trong các trường hợp khác, ít gây gián đoạn hơn), vì vậy nếu bạn cho rằng thông tin này sẽ hữu ích trong một khoảng thời gian dài hơn, thì việc chụp ảnh nhanh định kỳ có thể là điều bạn muốn xem xét.