Mọi sản phẩm đều có lỗi và SQL Server cũng không ngoại lệ. Sử dụng các tính năng của sản phẩm theo cách hơi khác thường (hoặc kết hợp các tính năng tương đối mới với nhau) là một cách tuyệt vời để tìm ra chúng. Lỗi có thể thú vị và thậm chí mang tính giáo dục, nhưng có lẽ một số niềm vui bị mất đi khi kết quả là máy nhắn tin của bạn bị ngắt lúc 4 giờ sáng, có lẽ sau một đêm giao lưu đặc biệt với bạn bè…
Lỗi là chủ đề của bài đăng này có lẽ rất hiếm trong tự nhiên, nhưng nó không phải là một trường hợp kinh điển. Tôi biết ít nhất một nhà tư vấn đã gặp phải vấn đề này trong một hệ thống sản xuất. Về một chủ đề hoàn toàn không liên quan, tôi nên nhân cơ hội này để nói "xin chào" với Grumpy Old DBA (blog).
Tôi sẽ bắt đầu với một số thông tin cơ bản có liên quan về phép nối hợp nhất. Nếu bạn chắc chắn rằng bạn đã biết mọi thứ cần biết về tham gia hợp nhất hoặc chỉ muốn tiếp tục cuộc rượt đuổi, hãy cuộn xuống phần có tiêu đề, "The Bug".
Hợp nhất Tham gia
Hợp nhất tham gia không phải là một điều quá phức tạp và có thể rất hiệu quả trong những trường hợp thích hợp. Nó yêu cầu các đầu vào của nó được sắp xếp trên các khóa tham gia và hoạt động tốt nhất ở chế độ một-nhiều (trong đó ít nhất các đầu vào của nó là duy nhất trên các khóa tham gia). Đối với các phép nối một-nhiều có kích thước vừa phải, phép nối hợp nhất nối tiếp không phải là một lựa chọn tồi chút nào, miễn là có thể đáp ứng các yêu cầu sắp xếp đầu vào mà không cần thực hiện một cách sắp xếp rõ ràng.
Việc tránh sắp xếp thường đạt được bằng cách khai thác thứ tự được cung cấp bởi một chỉ mục. Kết hợp hợp nhất cũng có thể tận dụng thứ tự sắp xếp được bảo toàn từ một sắp xếp không thể tránh khỏi trước đó. Một điều thú vị về phép kết hợp là nó có thể ngừng xử lý các hàng đầu vào ngay khi một trong hai đầu vào hết hàng. Một điều cuối cùng:phép nối hợp nhất không quan tâm thứ tự sắp xếp đầu vào là tăng dần hay giảm dần (mặc dù cả hai đầu vào phải giống nhau). Ví dụ sau sử dụng bảng Numbers tiêu chuẩn để minh họa hầu hết các điểm ở trên:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Lưu ý rằng các chỉ mục thực thi khóa chính trên hai bảng đó được định nghĩa là giảm dần. Kế hoạch truy vấn cho INSERT có một số tính năng thú vị:
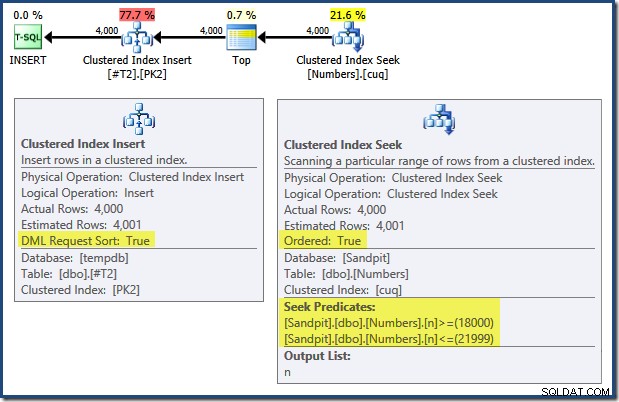
Đọc từ trái sang phải (chỉ có thể hiểu được!) Chèn chỉ mục theo cụm có bộ thuộc tính "Sắp xếp theo yêu cầu DML". Điều này có nghĩa là toán tử yêu cầu các hàng theo thứ tự khóa Chỉ mục cụm. Chỉ mục được phân nhóm (thực thi khóa chính trong trường hợp này) được định nghĩa là DESC , vì vậy các hàng có giá trị cao hơn bắt buộc phải đến trước. Chỉ mục được phân nhóm trên bảng Numbers của tôi là ASC , do đó, trình tối ưu hóa truy vấn tránh sắp xếp rõ ràng bằng cách tìm kiếm kết quả phù hợp cao nhất trong bảng Numbers (21.999) trước, sau đó quét về kết quả phù hợp thấp nhất (18.000) theo thứ tự chỉ mục ngược lại. Chế độ xem "Cây kế hoạch" trong SQL Sentry Plan Explorer hiển thị quá trình quét ngược (lùi) rõ ràng:
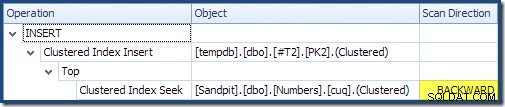
Quét ngược sẽ đảo ngược thứ tự tự nhiên của chỉ mục. Quét ngược ASC khóa chỉ mục trả về các hàng theo thứ tự khóa giảm dần; quét ngược một DESC khóa chỉ mục trả về các hàng theo thứ tự khóa tăng dần. "Hướng quét" không chỉ ra thứ tự khóa được trả về - bạn phải biết liệu chỉ mục có phải là ASC hay không hoặc DESC để thực hiện quyết tâm đó.
Sử dụng các bảng và dữ liệu thử nghiệm này (T1 có 10.000 hàng được đánh số từ 10.000 đến 19.999 bao gồm; T2 có 4.000 hàng được đánh số từ 18.000 đến 21.999) truy vấn sau đây nối hai bảng với nhau và trả về kết quả theo thứ tự giảm dần của cả hai khóa:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; Truy vấn trả về đúng 2.000 hàng phù hợp như bạn mong đợi. Kế hoạch sau khi thực hiện như sau:
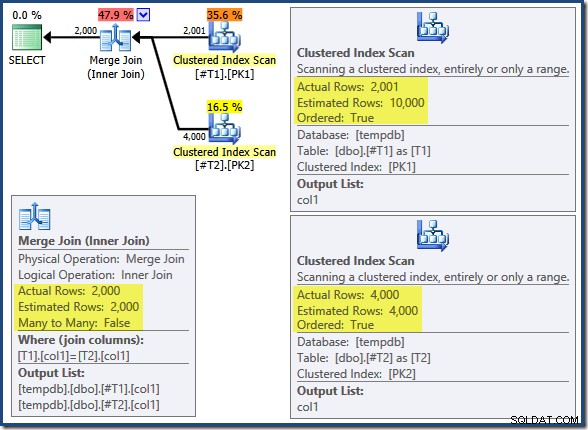
Kết hợp Hợp nhất không chạy ở chế độ nhiều thành nhiều (đầu vào trên cùng là duy nhất trên các phím kết hợp) và ước tính số lượng 2.000 hàng là chính xác. Quét chỉ mục theo cụm của bảng T2 được sắp xếp theo thứ tự (mặc dù chúng ta phải đợi một lúc để khám phá xem thứ tự đó là tiến hay lùi) và ước tính về số lượng của 4.000 hàng cũng chính xác. Quét chỉ mục theo cụm của bảng T1 cũng được đặt hàng, nhưng chỉ có 2.001 hàng được đọc trong khi ước tính có 10.000 hàng. Chế độ xem dạng cây kế hoạch cho thấy cả hai Bản quét chỉ mục theo cụm đều được sắp xếp theo thứ tự về phía trước:
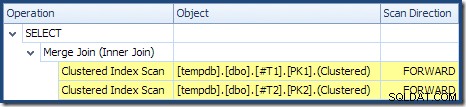
Nhớ lại rằng đọc một DESC chỉ mục FORWARD sẽ tạo ra các hàng theo thứ tự khóa ngược lại. Đây chính xác là những gì được yêu cầu bởi ORDER BY T1.col DESC, T2.col1 DESC mệnh đề, vì vậy không cần sắp xếp rõ ràng. Mã giả cho một-nhiều Hợp nhất Tham gia (sao chép từ blog Tham gia Hợp nhất của Craig Freedman) là:

Quét theo thứ tự giảm dần của T1 trả về các hàng bắt đầu từ 19.999 và giảm xuống 10.000. Quét theo thứ tự giảm dần của T2 trả về các hàng bắt đầu từ 21.999 và giảm xuống 18.000. Tất cả 4.000 hàng trong T2 cuối cùng được đọc, nhưng quá trình hợp nhất lặp lại dừng khi giá trị khóa 17,999 được đọc từ T1 , bởi vì T2 hết hàng. Do đó, quá trình hợp nhất hoàn thành mà không cần đọc đầy đủ T1 . Nó đọc các hàng từ 19.999 xuống bao gồm 17.999; tổng cộng 2.001 hàng như được hiển thị trong kế hoạch thực thi ở trên.
Vui lòng chạy lại kiểm tra với ASC thay vào đó, lập chỉ mục cũng thay đổi ORDER BY mệnh đề từ DESC thành ASC . Kế hoạch thực hiện được tạo ra sẽ rất giống nhau và không cần sắp xếp.
Để tóm tắt các điểm sẽ quan trọng trong giây lát, Merge Join yêu cầu các đầu vào được sắp xếp theo khóa nối, nhưng không quan trọng việc các khóa được sắp xếp tăng dần hay giảm dần.
Lỗi
Để tái tạo lỗi, ít nhất một trong các bảng của chúng ta cần được phân vùng. Để giữ cho kết quả có thể quản lý được, ví dụ này sẽ chỉ sử dụng một số lượng nhỏ các hàng, do đó, hàm phân vùng cũng cần các ranh giới nhỏ:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
Bảng đầu tiên chứa hai cột và được phân vùng trên KHÓA CHÍNH:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
); Bảng thứ hai không được phân vùng. Nó chứa một khóa chính và một cột sẽ tham gia vào bảng đầu tiên:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Dữ liệu mẫu
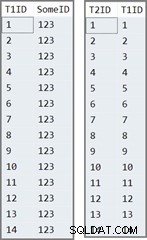
Bảng đầu tiên có 14 hàng, tất cả đều có cùng giá trị trong SomeID cột. Máy chủ SQL chỉ định IDENTITY giá trị cột, được đánh số từ 1 đến 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
Bảng thứ hai được điền đơn giản bằng IDENTITY giá trị từ bảng một:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Dữ liệu trong hai bảng trông giống như sau:
Truy vấn kiểm tra
Truy vấn đầu tiên chỉ cần kết hợp cả hai bảng, áp dụng một vị từ mệnh đề WHERE duy nhất (điều này xảy ra khớp với tất cả các hàng trong ví dụ được đơn giản hóa rất nhiều này):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Kết quả chứa tất cả 14 hàng, như mong đợi:

Do số lượng hàng nhỏ, trình tối ưu hóa chọn một kế hoạch tham gia các vòng lồng nhau cho truy vấn này:
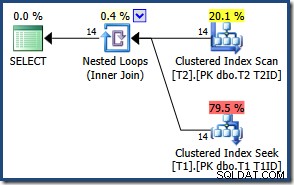
Kết quả giống nhau (và vẫn đúng) nếu chúng ta buộc một phép băm hoặc phép hợp nhất:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
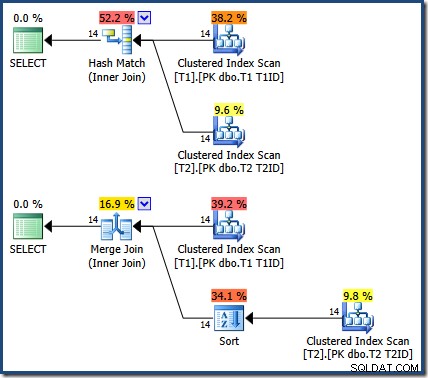
Kết hợp Hợp nhất ở đó là một - nhiều, với sự sắp xếp rõ ràng trên T1ID bắt buộc đối với bảng T2 .
Vấn đề chỉ mục giảm dần
Tất cả đều ổn cho đến một ngày (vì những lý do chính đáng mà chúng tôi không cần quan tâm đến chúng tôi ở đây) một quản trị viên khác thêm một chỉ mục giảm dần trên SomeID cột của bảng 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Truy vấn của chúng tôi tiếp tục tạo ra kết quả chính xác khi trình tối ưu hóa chọn Vòng lặp lồng nhau hoặc Tham gia băm, nhưng lại là một câu chuyện khác khi Kết hợp hợp nhất được sử dụng. Phần sau vẫn sử dụng gợi ý truy vấn để buộc Kết hợp Hợp nhất, nhưng đây chỉ là hệ quả của số lượng hàng thấp trong ví dụ. Trình tối ưu hóa sẽ tự nhiên chọn cùng một kế hoạch Kết hợp với dữ liệu bảng khác nhau.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Kế hoạch thực hiện là:
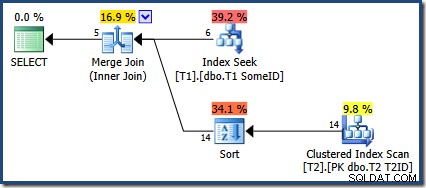
Trình tối ưu hóa đã chọn sử dụng chỉ mục mới, nhưng truy vấn hiện chỉ tạo ra năm hàng đầu ra:

Điều gì đã xảy ra với 9 hàng còn lại? Để rõ ràng, kết quả này không chính xác. Dữ liệu không thay đổi, vì vậy tất cả 14 hàng sẽ được trả lại (như chúng vẫn ở với gói Vòng lặp lồng nhau hoặc Kết hợp băm).
Nguyên nhân và Giải thích
Chỉ mục không hợp nhất mới trên SomeID không được khai báo là duy nhất, vì vậy khóa chỉ mục nhóm được thêm âm thầm vào tất cả các cấp chỉ mục không phân nhóm. SQL Server thêm T1ID (khóa được phân nhóm) cho chỉ mục không phân nhóm giống như thể chúng ta đã tạo chỉ mục như sau:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Nhận thấy thiếu DESC định tính trên T1ID được thêm âm thầm Chìa khóa. Các khóa chỉ mục là ASC theo mặc định. Đây không phải là một vấn đề tự nó (mặc dù nó có đóng góp). Điều thứ hai xảy ra với chỉ mục của chúng ta một cách tự động là nó được phân vùng giống như cách của bảng cơ sở. Vì vậy, đặc tả chỉ mục đầy đủ, nếu chúng ta viết nó ra một cách rõ ràng, sẽ là:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Đây là một cấu trúc khá phức tạp, với các khóa theo đủ loại thứ tự khác nhau. Nó đủ phức tạp để trình tối ưu hóa truy vấn mắc lỗi khi suy luận về thứ tự sắp xếp do chỉ mục cung cấp. Để minh họa, hãy xem xét truy vấn đơn giản sau:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
Cột bổ sung sẽ chỉ cho chúng tôi biết phân vùng mà hàng hiện tại thuộc về. Nếu không, nó chỉ là một truy vấn đơn giản trả về T1ID các giá trị theo thứ tự tăng dần, WHERE SomeID = 123 . Thật không may, kết quả không phải là những gì được chỉ định bởi truy vấn:
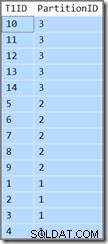
Truy vấn yêu cầu T1ID đó các giá trị phải được trả về theo thứ tự tăng dần, nhưng đó không phải là những gì chúng ta nhận được. Chúng tôi nhận các giá trị theo thứ tự tăng dần trên mỗi phân vùng , nhưng bản thân các phân vùng được trả về theo thứ tự ngược lại! Nếu các phân vùng được trả về theo thứ tự tăng dần (và T1ID các giá trị vẫn được sắp xếp trong mỗi phân vùng như được hiển thị) kết quả sẽ đúng.
Kế hoạch truy vấn cho thấy rằng trình tối ưu hóa đã bị nhầm lẫn bởi DESC hàng đầu khóa của chỉ mục và nghĩ rằng nó cần đọc các phân vùng theo thứ tự ngược lại để có kết quả chính xác:
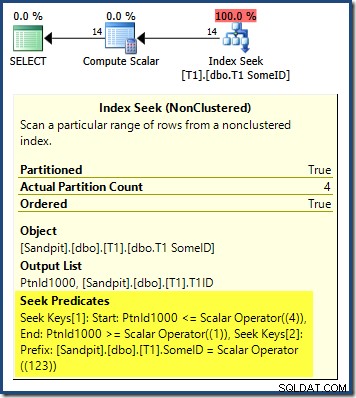
Tìm kiếm phân vùng bắt đầu ở phân vùng ngoài cùng bên phải (4) và tiến hành ngược trở lại phân vùng 1. Bạn có thể nghĩ rằng chúng tôi có thể khắc phục sự cố bằng cách sắp xếp rõ ràng theo số phân vùng ASC trong ORDER BY mệnh đề:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Truy vấn này trả về cùng một kết quả (đây không phải là lỗi in sai hoặc sao chép / dán):
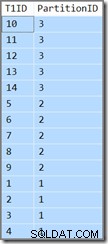
Id phân vùng vẫn ở giảm dần thứ tự (không tăng dần, như đã chỉ định) và T1ID chỉ được sắp xếp tăng dần trong mỗi phân vùng. Đó là sự nhầm lẫn của trình tối ưu hóa, nó thực sự nghĩ rằng (hãy thở sâu ngay bây giờ) rằng việc quét chỉ mục khóa hàng đầu giảm dần được phân vùng theo hướng về phía trước, nhưng với các phân vùng bị đảo ngược, sẽ dẫn đến thứ tự được chỉ định bởi truy vấn.
Thành thật mà nói, tôi không trách, việc cân nhắc thứ tự sắp xếp khác nhau cũng khiến tôi đau đầu.
Ví dụ cuối cùng, hãy xem xét:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Kết quả là:

Một lần nữa, T1ID sắp xếp thứ tự trong mỗi phân vùng đang giảm dần một cách chính xác, nhưng bản thân các phân vùng được liệt kê lùi lại (chúng đi từ 1 đến 3 xuống các hàng). Nếu các phân vùng được trả về theo thứ tự ngược lại, kết quả chính xác sẽ là 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Quay lại Hợp nhất Tham gia
Nguyên nhân của kết quả không chính xác với truy vấn Kết hợp Hợp nhất hiện đã rõ ràng:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
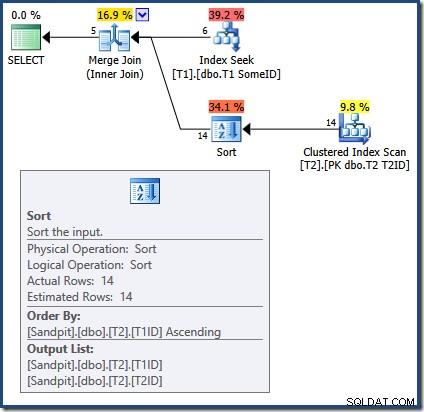
Kết hợp Hợp nhất yêu cầu các đầu vào được sắp xếp. Đầu vào từ T2 được sắp xếp rõ ràng theo T1TD vậy là ok. Trình tối ưu hóa không chính xác lý do khiến chỉ mục trên T1 có thể cung cấp các hàng trong T1ID gọi món. Như chúng ta đã thấy, đây không phải là trường hợp. Index Seek tạo ra kết quả giống như một truy vấn mà chúng ta đã thấy:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Chỉ 5 hàng đầu tiên nằm trong T1ID gọi món. Giá trị tiếp theo (5) chắc chắn không theo thứ tự tăng dần và Kết hợp hợp nhất diễn giải điều này là cuối luồng thay vì tạo ra lỗi (cá nhân tôi mong đợi xác nhận bán lẻ ở đây). Dù sao thì, hậu quả là Merge Join không chính xác sẽ kết thúc quá trình xử lý sớm. Xin nhắc lại, kết quả (không đầy đủ) là:

Kết luận
Đây là một lỗi rất nghiêm trọng theo quan điểm của tôi. Một tìm kiếm chỉ mục đơn giản có thể trả về kết quả không tuân theo ORDER BY mệnh đề. Quan trọng hơn, lý luận nội bộ của trình tối ưu hóa hoàn toàn bị hỏng dành cho các chỉ mục không phân nhánh không phải duy nhất được phân vùng với khóa hàng đầu giảm dần.
Có, đây là một hơi sự sắp xếp bất thường. Tuy nhiên, như chúng ta đã thấy, kết quả đúng có thể đột ngột bị thay thế bằng kết quả không chính xác chỉ vì ai đó đã thêm chỉ số giảm dần. Hãy nhớ rằng chỉ mục được thêm vào trông đủ vô tội:không có ASC/DESC rõ ràng khóa không khớp và không có phân vùng rõ ràng.
Lỗi này không giới hạn đối với Merge Joins. Có khả năng bất kỳ truy vấn nào liên quan đến một bảng được phân vùng và dựa vào thứ tự sắp xếp chỉ mục (rõ ràng hoặc ngầm hiểu) đều có thể trở thành nạn nhân. Lỗi này tồn tại trong tất cả các phiên bản của SQL Server từ 2008 đến 2014, bao gồm cả CTP 1. Cơ sở dữ liệu Windows SQL Azure không hỗ trợ phân vùng, vì vậy vấn đề không phát sinh. SQL Server 2005 đã sử dụng một mô hình triển khai khác để phân vùng (dựa trên APPLY ) và cũng không bị vấn đề này.
Nếu bạn có thời gian, vui lòng xem xét bỏ phiếu cho mục Kết nối của tôi cho lỗi này.
Độ phân giải
Bản sửa lỗi cho sự cố này hiện có sẵn và được ghi lại trong một bài báo trong Cơ sở Kiến thức. Xin lưu ý rằng bản sửa lỗi yêu cầu cập nhật mã và cờ theo dõi 4199 , cho phép một loạt các thay đổi khác của bộ xử lý truy vấn. Việc sửa lỗi kết quả không chính xác dưới 4199 là điều bất thường. Tôi đã yêu cầu giải thích rõ về lỗi đó và câu trả lời là:
Mặc dù sự cố này liên quan đến kết quả không chính xác như các bản sửa lỗi nóng khác liên quan đến Bộ xử lý truy vấn, chúng tôi chỉ bật bản sửa lỗi này dưới cờ theo dõi 4199 cho SQL Server 2008, 2008 R2 và 2012. Tuy nhiên, bản sửa lỗi này được "bật" bởi mặc định không có cờ theo dõi trong SQL Server 2014 RTM.