Trong một chuỗi gần đây trên StackExchange, một người dùng đã gặp sự cố sau:
Tôi muốn truy vấn trả về người đầu tiên trong bảng có GroupID =2. Nếu không có ai có GroupID =2 tồn tại, tôi muốn người đầu tiên có RoleID =2.
Bây giờ chúng ta hãy loại bỏ thực tế là "đầu tiên" được định nghĩa một cách khủng khiếp. Trên thực tế, người dùng không quan tâm họ nhận được người nào, cho dù người đó đến ngẫu nhiên, tùy ý hay thông qua một số logic rõ ràng ngoài tiêu chí chính của họ. Bỏ qua điều đó, giả sử bạn có một bảng cơ bản:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
Trong thế giới thực có lẽ có các cột khác, các ràng buộc bổ sung, có thể là các khóa ngoại cho các bảng khác, và chắc chắn là các chỉ mục khác. Nhưng hãy đơn giản hóa vấn đề này và đưa ra một truy vấn.
Các giải pháp có thể xảy ra
Với thiết kế bàn đó, giải quyết vấn đề có vẻ đơn giản, phải không? Nỗ lực đầu tiên bạn có thể sẽ thực hiện là:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Điều này sử dụng TOP và ORDER BY có điều kiện để coi những người dùng có GroupID =2 là mức độ ưu tiên cao hơn. Kế hoạch cho truy vấn này khá đơn giản, với hầu hết chi phí xảy ra trong một hoạt động sắp xếp. Dưới đây là số liệu thời gian chạy so với một bảng trống:
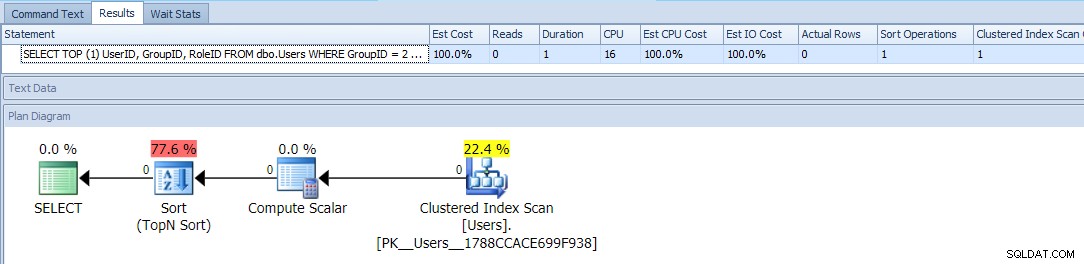
Điều này có vẻ tốt như bạn có thể làm - một kế hoạch đơn giản chỉ quét bảng một lần và không phải là một kiểu khó chịu mà bạn có thể sống chung, không vấn đề gì, phải không?
Chà, một câu trả lời khác trong chuỗi cung cấp biến thể phức tạp hơn này:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
Thoạt nhìn, bạn có thể nghĩ rằng truy vấn này cực kỳ kém hiệu quả, vì nó yêu cầu hai lần quét chỉ mục theo cụm. Bạn chắc chắn sẽ đúng về điều đó; đây là chỉ số kế hoạch và thời gian chạy so với một bảng trống:
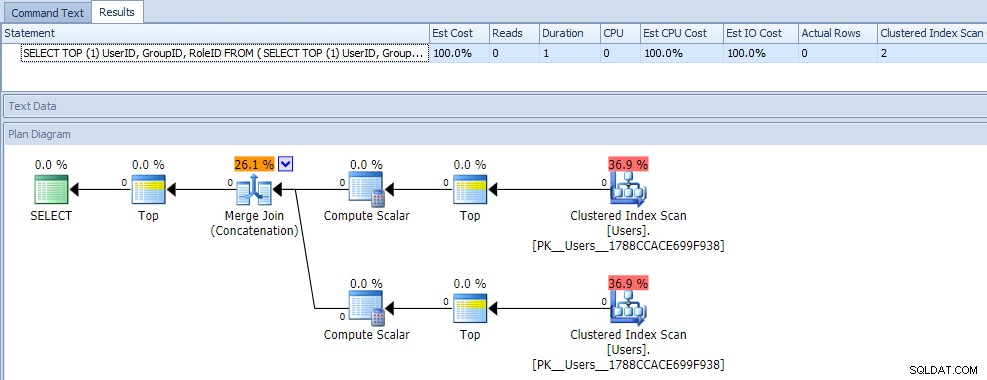
Nhưng bây giờ, hãy thêm dữ liệu
Để kiểm tra các truy vấn này, tôi muốn sử dụng một số dữ liệu thực tế. Vì vậy, trước tiên, tôi đã điền 1.000 hàng từ sys.all_objects, với các hoạt động modulo đối với object_id để có được một số phân phối phù hợp:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Bây giờ khi tôi chạy hai truy vấn, đây là số liệu thời gian chạy:

Phiên bản UNION ALL có I / O ít hơn một chút (4 lần đọc so với 5), thời lượng thấp hơn và chi phí tổng thể ước tính thấp hơn, trong khi phiên bản ORDER BY có điều kiện có chi phí CPU ước tính thấp hơn. Dữ liệu ở đây là khá nhỏ để đưa ra bất kỳ kết luận nào về; Tôi chỉ muốn nó như một cái cọc trên mặt đất. Bây giờ, hãy thay đổi phân phối để hầu hết các hàng đáp ứng ít nhất một trong các tiêu chí (và đôi khi là cả hai):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Lần này, lệnh có điều kiện theo có chi phí ước tính cao nhất trong cả CPU và I / O:

Nhưng một lần nữa, ở kích thước dữ liệu này, có tác động tương đối nhỏ đến thời lượng và lượt đọc, và ngoài chi phí ước tính (dù sao thì phần lớn cũng được tạo thành), thật khó để tuyên bố người chiến thắng ở đây.
Vì vậy, hãy thêm nhiều dữ liệu hơn nữa
Mặc dù tôi thích xây dựng dữ liệu mẫu từ các chế độ xem danh mục, vì mọi người đều có những thứ đó, nhưng lần này tôi sẽ vẽ trên bảng Sales.SalesOrderHeaderEnlarged từ AdventureWorks2012, được mở rộng bằng cách sử dụng tập lệnh này của Jonathan Kehayias. Trên hệ thống của tôi, bảng này có 1.258.600 hàng. Tập lệnh sau sẽ chèn một triệu hàng trong số đó vào bảng dbo.Users của chúng tôi:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Được rồi, bây giờ khi chúng tôi chạy các truy vấn, chúng tôi thấy một vấn đề:biến thể ORDER BY đã song song và đã xóa cả lượt đọc và CPU, tạo ra sự chênh lệch gần 120 lần về thời lượng:
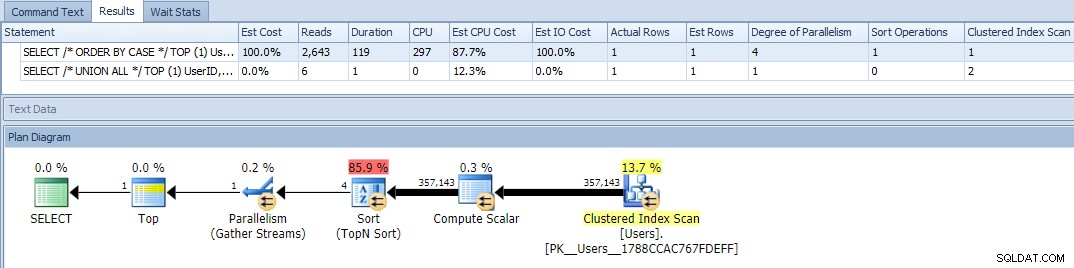
Loại bỏ song song (sử dụng MAXDOP) không giúp được gì:
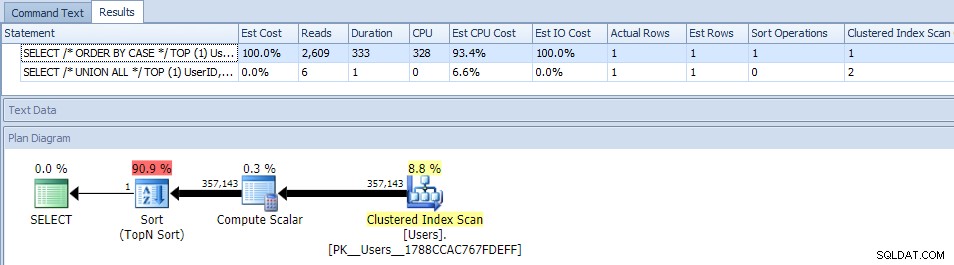
(Kế hoạch UNION ALL vẫn giống nhau.)
Và nếu chúng ta thay đổi độ lệch thành số chẵn, trong đó 95% hàng đáp ứng ít nhất một tiêu chí:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Các truy vấn vẫn cho thấy rằng loại này rất đắt:

Và với MAXDOP =1, điều đó còn tệ hơn nhiều (chỉ cần nhìn vào thời lượng):

Cuối cùng, làm thế nào về độ lệch 95% theo một trong hai hướng (ví dụ:hầu hết các hàng thỏa mãn tiêu chí GroupID hoặc hầu hết các hàng thỏa mãn tiêu chí RoleID)? Tập lệnh này sẽ đảm bảo ít nhất 95% dữ liệu có GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Kết quả khá giống nhau (tôi sẽ ngừng thử điều này từ bây giờ trở đi):

Và sau đó nếu chúng ta đi theo hướng khác, trong đó ít nhất 95% dữ liệu có RoleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Kết quả:

Kết luận
Không một trường hợp nào mà tôi có thể tạo ra truy vấn ORDER BY "đơn giản hơn" - ngay cả với một lần quét chỉ mục ít phân cụm hơn - hoạt động tốt hơn truy vấn UNION ALL phức tạp hơn. Đôi khi bạn phải rất cảnh giác về những gì SQL Server phải làm khi bạn đưa các hoạt động như sắp xếp vào ngữ nghĩa truy vấn của mình và không dựa vào sự đơn giản của kế hoạch (đừng bận tâm đến bất kỳ sự thiên vị nào mà bạn có thể có dựa trên các tình huống trước đó).
Bản năng đầu tiên của bạn thường có thể đúng, nhưng tôi cá rằng có những lúc có một lựa chọn tốt hơn mà bề ngoài có vẻ như nó không thể hoạt động tốt hơn. Như trong ví dụ này. Tôi đã khá hơn một chút về việc đặt câu hỏi các giả định mà tôi đã thực hiện từ các quan sát và không đưa ra các tuyên bố chung chung như "quét không bao giờ hoạt động tốt" và "truy vấn đơn giản hơn luôn chạy nhanh hơn." Nếu bạn loại bỏ những từ không bao giờ và luôn luôn ra khỏi vốn từ vựng của mình, bạn có thể thấy mình đặt nhiều giả định và câu nói chung đó vào bài kiểm tra, và kết thúc tốt hơn nhiều.