SQL Server 2005 đã thêm khả năng bao gồm các cột không phải khóa trong một chỉ mục không phân biệt. Trong SQL Server 2000 trở về trước, đối với một chỉ mục không phân biệt, tất cả các cột được xác định cho một chỉ mục đều là các cột chính, có nghĩa là chúng là một phần của mọi cấp của chỉ mục, từ gốc xuống đến cấp lá. Khi một cột được xác định là một cột được bao gồm, nó chỉ là một phần của cấp lá. Sách Trực tuyến ghi nhận những lợi ích sau của các cột bao gồm:
- Chúng có thể là loại dữ liệu không được phép dùng làm cột khóa chỉ mục.
- Chúng không được Công cụ cơ sở dữ liệu xem xét khi tính số cột khóa chỉ mục hoặc kích thước khóa chỉ mục.
Ví dụ, một cột varchar (max) không thể là một phần của khóa chỉ mục, nhưng nó có thể là một cột được bao gồm. Hơn nữa, cột varchar (max) đó không tính vào giới hạn 900 byte (hoặc 16 cột) áp đặt cho khóa chỉ mục.
Tài liệu cũng lưu ý lợi ích hiệu suất sau:
Chỉ mục có cột không khóa có thể cải thiện đáng kể hiệu suất truy vấn khi tất cả các cột trong truy vấn được đưa vào chỉ mục dưới dạng cột khóa hoặc cột không khóa. Đạt được hiệu suất bởi vì trình tối ưu hóa truy vấn có thể xác định vị trí tất cả các giá trị cột trong chỉ mục; dữ liệu bảng hoặc chỉ mục nhóm không được truy cập dẫn đến ít hoạt động vào / ra đĩa hơn.Chúng ta có thể suy luận rằng cho dù cột chỉ mục là cột chính hay cột không phải cột, chúng ta sẽ nhận được sự cải thiện về hiệu suất so với khi tất cả các cột không phải là một phần của chỉ mục. Tuy nhiên, có sự khác biệt về hiệu suất giữa hai biến thể không?
Thiết lập
Tôi đã cài đặt một bản sao của cơ sở dữ liệu AdventuresWork2012 và xác minh các chỉ mục cho bảng Sales.SalesOrderHeader bằng cách sử dụng phiên bản sp_helpindex của Kimberly Tripp:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Chỉ mục mặc định cho Sales.SalesOrderHeader
Chúng tôi sẽ bắt đầu với một truy vấn chuyển tiếp để thử nghiệm truy xuất dữ liệu từ nhiều cột:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Nếu chúng tôi thực thi điều này với cơ sở dữ liệu AdventureWorks2012 bằng cách sử dụng SQL Sentry Plan Explorer và kiểm tra kế hoạch và đầu ra Bảng I / O, chúng tôi thấy rằng chúng tôi nhận được một bản quét chỉ mục theo cụm với 689 lần đọc logic:
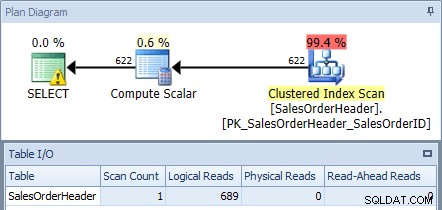
Kế hoạch thực thi từ truy vấn ban đầu
(Trong Management Studio, bạn có thể xem các chỉ số I / O bằng cách sử dụng SET STATISTICS IO ON; .)
SELECT có biểu tượng cảnh báo vì trình tối ưu hóa đề xuất một chỉ mục cho truy vấn này:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Thử nghiệm 1
Trước tiên, chúng tôi sẽ tạo chỉ mục mà trình tối ưu hóa đề xuất (có tên là NCI1_included), cũng như biến thể với tất cả các cột là cột chính (có tên là NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Nếu chúng tôi chạy lại truy vấn ban đầu, một lần gợi ý nó với NCI1 và một lần gợi ý nó với NCI1_included, chúng tôi sẽ thấy một kế hoạch tương tự như ban đầu, nhưng lần này có một tìm kiếm chỉ mục của mỗi chỉ mục không được phân loại, với các giá trị tương đương cho Bảng I / O và các chi phí tương tự (cả hai khoảng 0,006):
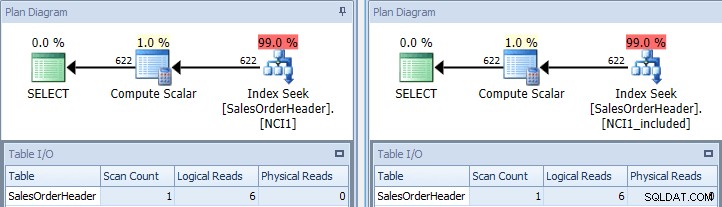
Truy vấn ban đầu với tìm kiếm chỉ mục - phím ở bên trái, bao gồm trên bên phải
(Số lần quét vẫn là 1 vì tìm kiếm chỉ mục thực sự là một quá trình quét theo phạm vi được ngụy trang.)
Bây giờ, cơ sở dữ liệu AdventureWorks2012 không đại diện cho cơ sở dữ liệu sản xuất về kích thước và nếu chúng ta nhìn vào số lượng trang trong mỗi chỉ mục, chúng ta thấy chúng hoàn toàn giống nhau:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
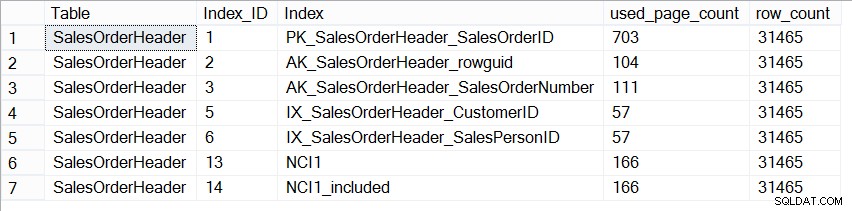
Kích thước chỉ mục trên Sales.SalesOrderHeader
Nếu chúng ta đang xem xét hiệu suất, thật lý tưởng (và thú vị hơn) để kiểm tra với tập dữ liệu lớn hơn.
Thử nghiệm 2
Tôi có một bản sao của cơ sở dữ liệu AdventureWorks2012 có bảng SalesOrderHeader với hơn 200 triệu hàng (tập lệnh TẠI ĐÂY), vì vậy hãy tạo cùng các chỉ mục không hợp nhất trong cơ sở dữ liệu đó và chạy lại các truy vấn:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
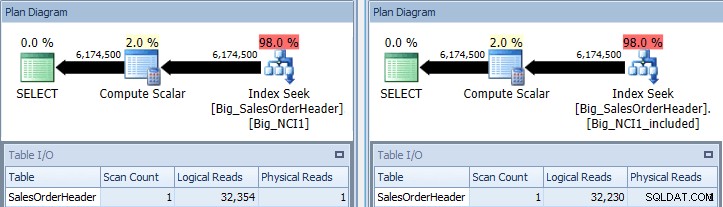
Truy vấn ban đầu với chỉ mục tìm cách chống lại Big_NCI1 (l) và Big_NCI1_Included ( r)
Bây giờ chúng tôi nhận được một số dữ liệu. Truy vấn trả về hơn 6 triệu hàng và việc tìm kiếm mỗi chỉ mục chỉ yêu cầu hơn 32.000 lần đọc và chi phí ước tính là như nhau cho cả hai truy vấn (31,233). Chưa có sự khác biệt về hiệu suất và nếu chúng tôi kiểm tra kích thước của các chỉ mục, chúng tôi thấy rằng chỉ mục với các cột được bao gồm có ít hơn 5.578 trang:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Kích thước chỉ mục trên Sales.Big_SalesOrderHeader
Nếu chúng ta tìm hiểu sâu hơn về vấn đề này và kiểm tra dm_dm_index_physical_stats, chúng ta có thể thấy rằng sự khác biệt tồn tại ở các cấp độ trung gian của chỉ mục:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
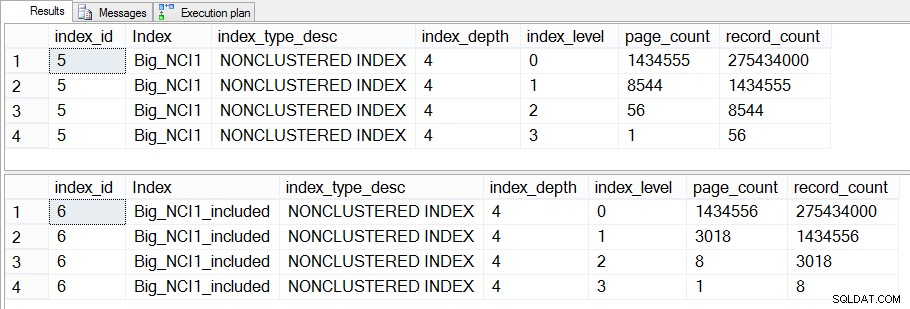
Kích thước chỉ mục (cấp cụ thể) trên Sales.Big_SalesOrderHeader
Sự khác biệt giữa các mức trung gian của hai chỉ mục là 43 MB, có thể không đáng kể, nhưng có lẽ tôi vẫn có xu hướng tạo chỉ mục với các cột được bao gồm để tiết kiệm dung lượng - cả trên đĩa và trong bộ nhớ. Từ góc độ truy vấn, chúng tôi vẫn không thấy sự thay đổi lớn về hiệu suất giữa chỉ mục với tất cả các cột trong khóa và chỉ mục với các cột được bao gồm.
Bài kiểm tra 3
Đối với thử nghiệm này, hãy thay đổi truy vấn và thêm bộ lọc cho [SubTotal] >= 100 đối với mệnh đề WHERE:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
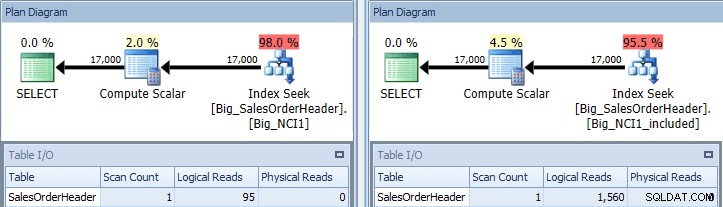
Kế hoạch thực thi truy vấn với vị từ SubTotal chống lại cả hai chỉ mục
Bây giờ chúng ta thấy sự khác biệt trong I / O (95 lần đọc so với 1,560), chi phí (0,848 so với 1,55) và một sự khác biệt nhỏ nhưng đáng chú ý trong kế hoạch truy vấn. Khi sử dụng chỉ mục với tất cả các cột trong khóa, vị từ tìm kiếm là CustomerID và SubTotal:
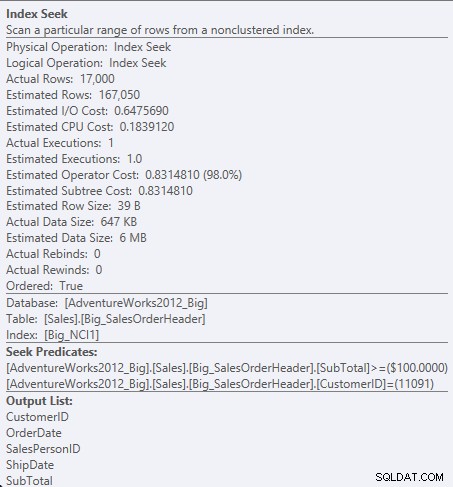
Tìm kiếm vị từ chống lại NCI1
Vì SubTotal là cột thứ hai trong khóa chỉ mục, dữ liệu được sắp xếp theo thứ tự và SubTotal tồn tại ở các cấp độ trung gian của chỉ mục. Công cụ có thể tìm kiếm trực tiếp bản ghi đầu tiên với CustomerID là 11091 và SubTotal lớn hơn hoặc bằng 100, sau đó đọc qua chỉ mục cho đến khi không còn bản ghi nào cho CustomerID 11091 tồn tại.
Đối với chỉ mục có các cột được bao gồm, SubTotal chỉ tồn tại ở cấp độ lá của chỉ mục, vì vậy CustomerID là vị từ tìm kiếm và SubTotal là vị từ dư (chỉ được liệt kê là Vị từ trong ảnh chụp màn hình):
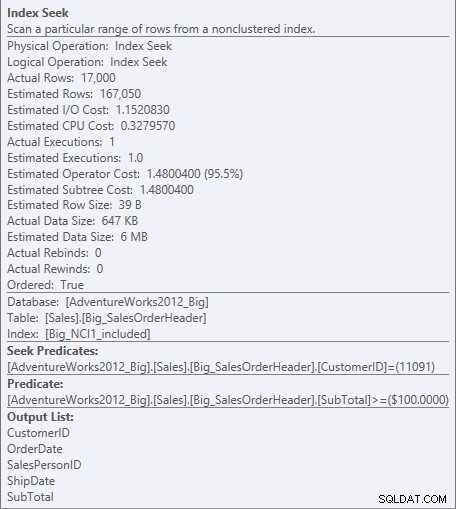
Tìm vị từ và vị từ còn lại so với NCI1_included
Công cụ có thể tìm kiếm trực tiếp bản ghi đầu tiên mà CustomerID là 11091, nhưng sau đó nó phải xem xét mọi ghi lại cho CustomerID 11091 để xem Tổng số phụ là 100 hoặc cao hơn, vì dữ liệu được sắp xếp theo thứ tự của CustomerID và SalesOrderID (khóa phân cụm).
Bài kiểm tra 4
Chúng tôi sẽ thử thêm một biến thể cho truy vấn của mình và lần này chúng tôi sẽ thêm một ĐƠN ĐẶT HÀNG BẰNG CÁCH:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
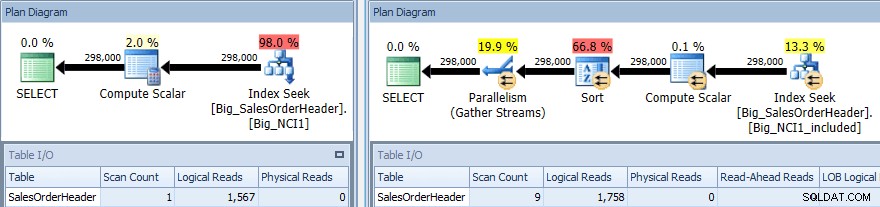
Kế hoạch thực thi truy vấn với SORT chống lại cả hai chỉ mục
Một lần nữa, chúng tôi có sự thay đổi về I / O (mặc dù rất nhỏ), thay đổi về chi phí (1.5 so với 9.3) và thay đổi lớn hơn nhiều về hình dạng kế hoạch; chúng tôi cũng thấy một số lượng lớn hơn các lần quét (1 so với 9). Truy vấn yêu cầu dữ liệu được sắp xếp theo SubTotal; khi SubTotal là một phần của khóa chỉ mục, nó được sắp xếp, vì vậy khi các bản ghi cho CustomerID 11091 được truy xuất, chúng đã ở theo thứ tự được yêu cầu.
Khi SubTotal tồn tại dưới dạng một cột được bao gồm, các bản ghi cho CustomerID 11091 phải được sắp xếp trước khi chúng có thể được trả lại cho người dùng, do đó trình tối ưu hóa sẽ can thiệp vào toán tử Sắp xếp trong truy vấn. Do đó, truy vấn sử dụng chỉ mục Big_NCI1_included cũng yêu cầu (và được cung cấp) cấp bộ nhớ 29.312 KB, đáng chú ý (và được tìm thấy trong các thuộc tính của kế hoạch).
Tóm tắt
Câu hỏi ban đầu mà chúng tôi muốn trả lời là liệu chúng tôi có thấy sự khác biệt về hiệu suất khi truy vấn sử dụng chỉ mục với tất cả các cột trong khóa, so với chỉ mục với hầu hết các cột được bao gồm trong cấp độ lá hay không. Trong bộ bài kiểm tra đầu tiên của chúng tôi không có sự khác biệt, nhưng trong bài kiểm tra thứ ba và thứ tư của chúng tôi thì có. Cuối cùng nó phụ thuộc vào truy vấn. Chúng tôi chỉ xem xét hai biến thể - một biến thể có vị từ bổ sung, biến thể kia có ORDER BY - còn nhiều biến thể khác tồn tại.
Điều mà các nhà phát triển và DBA cần hiểu là có một số lợi ích tuyệt vời khi bao gồm các cột trong một chỉ mục, nhưng chúng sẽ không phải lúc nào cũng hoạt động giống như các chỉ mục có tất cả các cột trong khóa. Có thể bạn muốn di chuyển các cột không phải là một phần của vị từ và nối ra khỏi khóa, và chỉ bao gồm chúng, để giảm kích thước tổng thể của chỉ mục. Tuy nhiên, trong một số trường hợp, điều này đòi hỏi nhiều tài nguyên hơn để thực thi truy vấn và có thể làm giảm hiệu suất. Sự xuống cấp có thể không đáng kể; nó có thể không ... bạn sẽ không biết cho đến khi bạn kiểm tra. Do đó, khi thiết kế một chỉ mục, điều quan trọng là phải suy nghĩ về các cột sau cột đứng đầu - và hiểu liệu chúng có cần phải là một phần của khóa (ví dụ:vì giữ dữ liệu được sắp xếp theo thứ tự sẽ mang lại lợi ích) hoặc liệu chúng có thể phục vụ mục đích của mình như đã bao gồm không cột.
Như điển hình với việc lập chỉ mục trong SQL Server, bạn phải kiểm tra các truy vấn với các chỉ mục của mình để xác định chiến lược tốt nhất. Nó vẫn là một nghệ thuật và một khoa học - cố gắng tìm số lượng chỉ mục tối thiểu để đáp ứng nhiều truy vấn nhất có thể.