Công cụ thực thi truy vấn SQL Server có hai cách để triển khai hoạt động 'hợp nhất tất cả' hợp lý, bằng cách sử dụng các toán tử vật lý Nối và Hợp nhất Nối Kết nối. Mặc dù hoạt động logic giống nhau, nhưng có sự khác biệt quan trọng giữa hai toán tử vật lý có thể tạo ra sự khác biệt to lớn đối với hiệu quả của các kế hoạch thực thi của bạn.
Trình tối ưu hóa truy vấn thực hiện một công việc hợp lý là lựa chọn giữa hai tùy chọn trong nhiều trường hợp, nhưng còn lâu mới hoàn hảo trong lĩnh vực này. Bài viết này mô tả các cơ hội điều chỉnh truy vấn do Merge Join Concatenation trình bày và nêu chi tiết các hành vi và cân nhắc nội bộ mà bạn cần biết để tận dụng tối đa.
Kết hợp

Toán tử Kết hợp tương đối đơn giản:đầu ra của nó là kết quả của việc đọc đầy đủ từng đầu vào của nó theo trình tự. Toán tử Kết hợp là một n-ary toán tử vật lý, nghĩa là nó có thể có đầu vào '2… n'. Để minh họa, hãy xem lại ví dụ dựa trên AdventureWorks từ bài viết trước của tôi, "Viết lại các truy vấn để cải thiện hiệu suất":
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Truy vấn sau liệt kê ID sản phẩm và giao dịch cho sáu sản phẩm cụ thể:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Nó tạo ra một kế hoạch thực thi có toán tử Kết nối với sáu đầu vào, như được thấy trong SQL Sentry Plan Explorer:
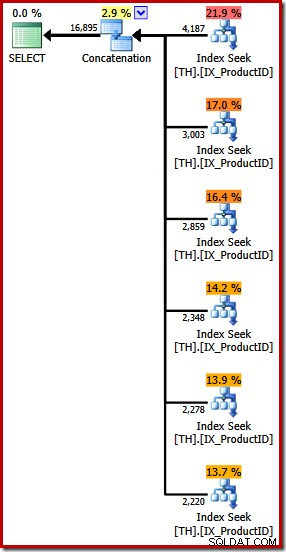
Kế hoạch ở trên có tính năng Tìm kiếm chỉ mục riêng cho từng ID sản phẩm được liệt kê, theo thứ tự như được chỉ định trong truy vấn (đọc từ trên xuống). Tìm kiếm chỉ mục trên cùng dành cho sản phẩm 870, tìm kiếm chỉ mục tiếp theo dành cho sản phẩm 873, sau đó là 921, v.v. Tất nhiên, không có điều gì trong số đó là hành vi được đảm bảo, nó chỉ là một cái gì đó thú vị để quan sát.
Tôi đã đề cập trước đó rằng toán tử Kết hợp hình thành đầu ra của nó bằng cách đọc từ các đầu vào của nó theo trình tự. Khi kế hoạch này được thực thi, có nhiều khả năng tập hợp kết quả sẽ hiển thị các hàng cho sản phẩm 870 đầu tiên, sau đó là 873, 921, 712, 707 và cuối cùng là sản phẩm 711. Một lần nữa, điều này không được đảm bảo vì chúng tôi không chỉ định ĐƠN HÀNG Mệnh đề BY, nhưng nó cho thấy cách Kết nối hoạt động nội bộ.
"Kế hoạch thực thi" SSIS
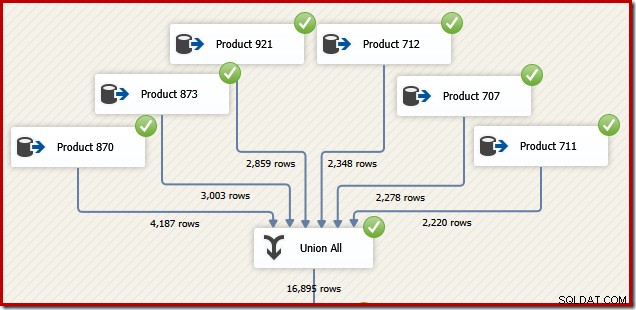
Vì những lý do sẽ có ý nghĩa trong chốc lát, hãy xem xét cách chúng tôi có thể thiết kế một gói SSIS để thực hiện cùng một nhiệm vụ. Chúng tôi chắc chắn cũng có thể viết toàn bộ nội dung dưới dạng một câu lệnh T-SQL duy nhất trong SSIS, nhưng tùy chọn thú vị hơn là tạo nguồn dữ liệu riêng biệt cho từng sản phẩm và sử dụng thành phần SSIS "Union All" thay cho SQL Server Concatenation nhà điều hành:
Bây giờ hãy tưởng tượng chúng ta cần đầu ra cuối cùng từ luồng dữ liệu đó theo thứ tự ID giao dịch. Một tùy chọn sẽ là thêm thành phần Sắp xếp rõ ràng sau Liên minh Tất cả:
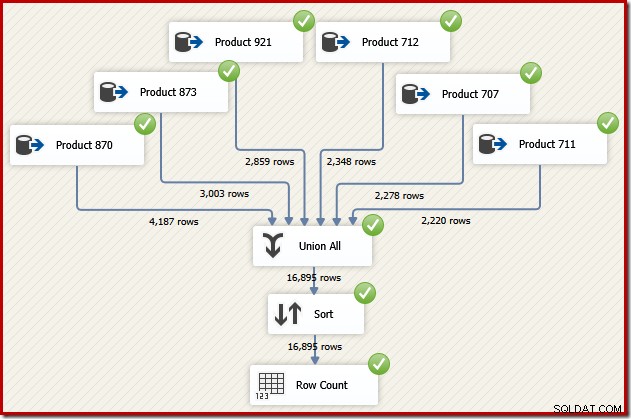
Điều đó chắc chắn sẽ thực hiện được công việc, nhưng một nhà thiết kế SSIS có kỹ năng và kinh nghiệm sẽ nhận ra có một lựa chọn tốt hơn:đọc dữ liệu nguồn cho từng sản phẩm theo thứ tự ID giao dịch (sử dụng chỉ mục), sau đó sử dụng thao tác bảo toàn đơn hàng để kết hợp các bộ .
Trong SSIS, thành phần kết hợp các hàng từ hai luồng dữ liệu được sắp xếp thành một luồng dữ liệu được sắp xếp duy nhất được gọi là "Hợp nhất". Luồng dữ liệu SSIS được thiết kế lại sử dụng Hợp nhất để trả về các hàng mong muốn theo thứ tự ID giao dịch như sau:
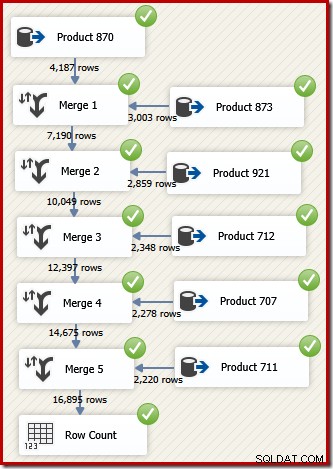
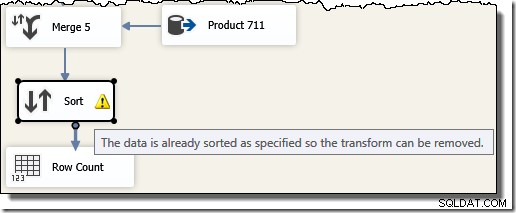
Lưu ý rằng chúng tôi cần năm thành phần Hợp nhất riêng biệt vì Hợp nhất là một thành phần nhị phân, không giống như thành phần "Liên minh Tất cả" của SSIS, là n-ary . Luồng Hợp nhất mới tạo ra kết quả theo thứ tự ID giao dịch mà không yêu cầu thành phần Sắp xếp (và chặn) đắt tiền. Thật vậy, nếu chúng tôi cố gắng thêm Sắp xếp trên ID giao dịch sau lần Hợp nhất cuối cùng, SSIS sẽ hiển thị cảnh báo để cho chúng tôi biết luồng đã được sắp xếp theo kiểu mong muốn:
Điểm của ví dụ SSIS bây giờ có thể được tiết lộ. Xem xét kế hoạch thực thi được chọn bởi trình tối ưu hóa truy vấn SQL Server khi chúng tôi yêu cầu nó trả về kết quả truy vấn T-SQL ban đầu theo thứ tự ID giao dịch (bằng cách thêm mệnh đề ORDER BY):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
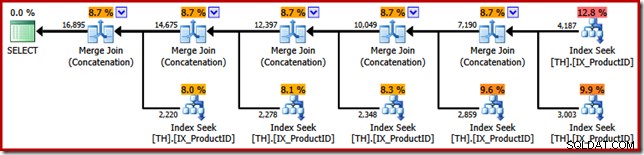
Điểm tương đồng với gói SSIS Merge là rất nổi bật; thậm chí là cần đến năm toán tử "Hợp nhất" nhị phân. Một điểm khác biệt quan trọng là SSIS có các thành phần riêng biệt cho "Merge Join" và "Merge" trong khi SQL Server sử dụng cùng một toán tử cốt lõi cho cả hai.
Để rõ ràng, các toán tử Kết hợp Hợp nhất (Nối) trong kế hoạch thực thi SQL Server không thực hiện một tham gia; engine chỉ đơn thuần là sử dụng lại cùng một toán tử vật lý để thực hiện liên kết bảo toàn trật tự tất cả.
Viết kế hoạch thực thi trong SQL Server
SSIS không có ngôn ngữ đặc tả luồng dữ liệu, cũng không có trình tối ưu hóa để biến một thông số kỹ thuật đó thành Nhiệm vụ luồng dữ liệu có thể thực thi. Người thiết kế gói SSIS phải nhận ra rằng có thể Hợp nhất theo thứ tự, đặt các thuộc tính thành phần (chẳng hạn như khóa sắp xếp) một cách thích hợp, sau đó so sánh hiệu suất. Điều này đòi hỏi nhiều nỗ lực hơn (và kỹ năng) từ phía nhà thiết kế, nhưng nó cung cấp một mức độ kiểm soát rất tốt.
Tình huống trong SQL Server ngược lại:chúng tôi viết một truy vấn đặc tả sử dụng ngôn ngữ T-SQL, sau đó phụ thuộc vào trình tối ưu hóa truy vấn để khám phá các tùy chọn triển khai và chọn một tùy chọn hiệu quả. Chúng tôi không có tùy chọn để xây dựng kế hoạch thực thi trực tiếp. Hầu hết thời gian, điều này rất đáng mong đợi:SQL Server chắc chắn sẽ ít phổ biến hơn nếu mọi truy vấn yêu cầu chúng ta viết một gói kiểu SSIS.
Tuy nhiên (như đã giải thích trong bài viết trước của tôi), kế hoạch được chọn bởi trình tối ưu hóa có thể nhạy cảm với T-SQL được sử dụng để mô tả kết quả mong muốn. Lặp lại ví dụ từ bài viết đó, chúng tôi có thể đã viết truy vấn T-SQL ban đầu bằng cách sử dụng cú pháp thay thế:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Truy vấn này chỉ định chính xác cùng một tập hợp kết quả như trước đây, nhưng trình tối ưu hóa không xem xét kế hoạch bảo toàn thứ tự (nối kết hợp nhất), thay vào đó chọn quét Chỉ mục được phân cụm (một tùy chọn kém hiệu quả hơn nhiều):
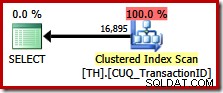
Tận dụng Bảo lưu Thứ tự trong SQL Server
Việc tránh sắp xếp không cần thiết có thể dẫn đến tăng hiệu quả đáng kể, cho dù chúng ta đang nói về SSIS hay SQL Server. Việc đạt được mục tiêu này có thể phức tạp và khó khăn hơn trong SQL Server vì chúng tôi không có quyền kiểm soát chi tiết như vậy đối với kế hoạch thực thi, nhưng vẫn có những điều chúng tôi có thể làm.
Cụ thể, việc hiểu cách hoạt động nội bộ của toán tử kết hợp kết hợp liên kết máy chủ SQL có thể giúp chúng tôi tiếp tục viết T-SQL quan hệ, rõ ràng, đồng thời khuyến khích trình tối ưu hóa truy vấn xem xét các tùy chọn xử lý duy trì thứ tự (hợp nhất) nếu thích hợp.
Cách hoạt động của Hợp nhất Tham gia Kết hợp

Một phép kết hợp thông thường yêu cầu cả hai đầu vào phải được sắp xếp trên các khóa kết hợp. Mặt khác, Merge Join Concatenation, chỉ cần hợp nhất hai luồng đã được sắp xếp sẵn thành một luồng có thứ tự duy nhất - không có phép nối, chẳng hạn như vậy.
Điều này đặt ra câu hỏi: 'trật tự' được bảo toàn chính xác là gì?
Trong SSIS, chúng ta phải thiết lập các thuộc tính khóa sắp xếp trên các đầu vào Hợp nhất để xác định thứ tự. SQL Server không có tương đương với cái này. Câu trả lời cho câu hỏi trên hơi phức tạp, vì vậy chúng tôi sẽ thực hiện từng bước.
Hãy xem xét ví dụ sau, yêu cầu ghép nối hợp nhất của hai bảng heap không được lập chỉ mục (trường hợp đơn giản nhất):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Hai bảng này không có chỉ mục và không có mệnh đề ORDER BY. Thứ tự nào mà phép nối kết hợp nhất sẽ 'giữ nguyên'? Để cho bạn một chút thời gian để suy nghĩ về điều đó, trước tiên chúng ta hãy xem kế hoạch thực thi được tạo cho truy vấn ở trên trong các phiên bản SQL Server trước 2012:
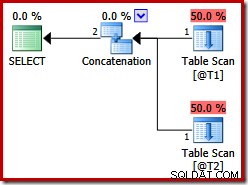
Không có Liên kết Kết hợp Hợp nhất, mặc dù gợi ý truy vấn:trước SQL Server 2012, gợi ý này chỉ hoạt động với UNION, không phải UNION ALL. Để có được một kế hoạch với toán tử hợp nhất mong muốn, chúng ta cần vô hiệu hóa việc triển khai một UNION ALL (UNIA) hợp lý bằng cách sử dụng toán tử vật lý Concatenation (CON). Xin lưu ý rằng những thứ sau không có giấy tờ và không được hỗ trợ để sử dụng trong sản xuất:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Truy vấn đó tạo ra cùng một kế hoạch như SQL Server 2012 và 2014 chỉ với gợi ý truy vấn MERGE UNION:
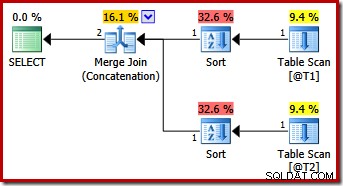
Có lẽ ngoài dự đoán, kế hoạch thực thi có các phân loại rõ ràng trên cả hai đầu vào để hợp nhất. Các thuộc tính sắp xếp là:
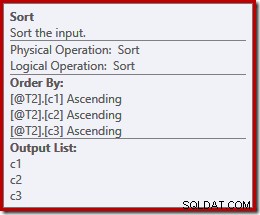
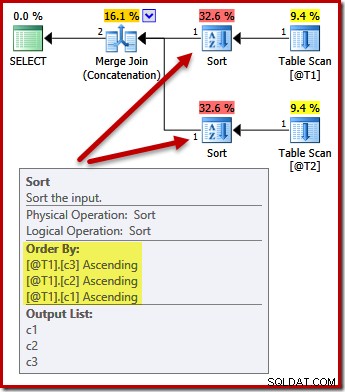
Hợp nhất bảo toàn thứ tự yêu cầu một thứ tự đầu vào nhất quán, nhưng tại sao nó lại chọn (c1, c2, c3) thay vì (c3, c1, c2) hoặc (c2, c3, c1)? Như một điểm bắt đầu, các đầu vào ghép nối hợp nhất được sắp xếp trên danh sách chiếu đầu ra. Dấu sao chọn trong truy vấn mở rộng thành (c1, c2, c3) để đó là thứ tự đã chọn.
Sắp xếp theo danh sách chiếu đầu ra hợp nhất
Để minh họa thêm cho vấn đề này, chúng ta có thể tự mở rộng dấu sao chọn (như chúng ta nên làm!) Bằng cách chọn một thứ tự khác (c3, c2, c1) khi đang ở đó:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Các loại bây giờ thay đổi để phù hợp (c3, c2, c1):
Một lần nữa, truy vấn đầu ra thứ tự (giả sử chúng ta thêm một số dữ liệu vào các bảng) không được đảm bảo sắp xếp như được hiển thị, bởi vì chúng ta không có mệnh đề ORDER BY. Những ví dụ này chỉ nhằm mục đích chỉ ra cách trình tối ưu hóa chọn thứ tự sắp xếp đầu vào ban đầu, trong trường hợp không có bất kỳ lý do nào khác để sắp xếp.
Thứ tự sắp xếp xung đột
Bây giờ hãy xem xét điều gì sẽ xảy ra nếu chúng ta để danh sách chiếu dưới dạng (c3, c2, c1) và thêm một yêu cầu để sắp xếp các kết quả truy vấn theo (c1, c2, c3). Các đầu vào để hợp nhất vẫn sắp xếp trên (c3, c2, c1) với sắp xếp sau hợp nhất trên (c1, c2, c3) để đáp ứng ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Không. Trình tối ưu hóa đủ thông minh để tránh sắp xếp hai lần:
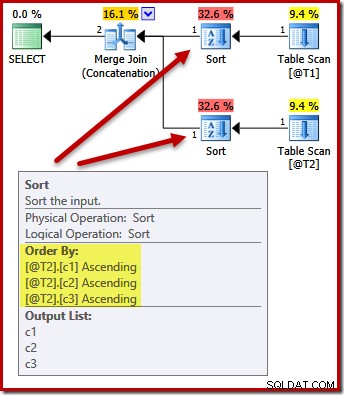
Việc sắp xếp cả hai đầu vào trên (c1, c2, c3) hoàn toàn có thể chấp nhận được đối với phép nối hợp nhất, vì vậy không cần sắp xếp kép.
Lưu ý rằng kế hoạch này không đảm bảo rằng thứ tự kết quả sẽ là (c1, c2, c3). Kế hoạch trông giống với các kế hoạch trước đó mà không có ORDER BY, nhưng không phải tất cả các chi tiết nội bộ đều được trình bày trong các kế hoạch thực thi mà người dùng có thể nhìn thấy.
Ảnh hưởng của tính duy nhất
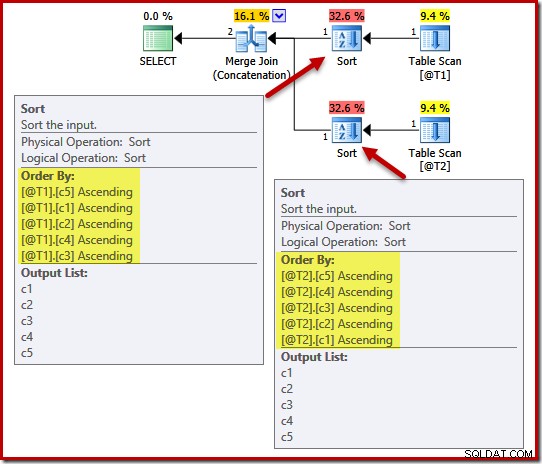
Khi chọn thứ tự sắp xếp cho các đầu vào hợp nhất, trình tối ưu hóa cũng bị ảnh hưởng bởi bất kỳ đảm bảo tính duy nhất nào tồn tại. Hãy xem xét ví dụ sau, với năm cột, nhưng lưu ý các thứ tự cột khác nhau trong hoạt động UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Kế hoạch thực thi bao gồm các loại trên (c5, c1, c2, c4, c3) cho bảng @ T1 và (c5, c4, c3, c2, c1) cho bảng @ T2:
Để chứng minh tác động của tính duy nhất đối với những cách sắp xếp này, chúng tôi sẽ thêm ràng buộc DUY NHẤT vào cột c1 trong bảng T1 và cột c4 trong bảng T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
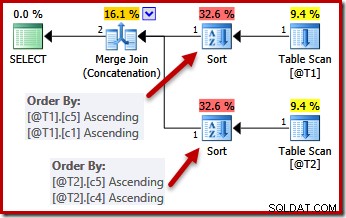
Điểm duy nhất về tính duy nhất là trình tối ưu hóa biết rằng nó có thể ngừng sắp xếp ngay khi gặp cột được đảm bảo là duy nhất. Sắp xếp theo các cột bổ sung sau khi gặp khóa duy nhất sẽ không ảnh hưởng đến thứ tự sắp xếp cuối cùng, theo định nghĩa.
Với các ràng buộc DUY NHẤT tại chỗ, trình tối ưu hóa có thể đơn giản hóa danh sách sắp xếp (c5, c1, c2, c4, c3) cho từ T1 đến (c5, c1) vì c1 là duy nhất. Tương tự, danh sách sắp xếp (c5, c4, c3, c2, c1) cho T2 được đơn giản hóa thành (c5, c4) vì c4 là một khóa:
Song song
Việc đơn giản hóa do một khóa duy nhất không được thực hiện một cách hoàn hảo. Trong một kế hoạch song song, các luồng được phân vùng để tất cả các hàng cho cùng một trường hợp hợp nhất kết thúc trên cùng một luồng. Việc phân vùng tập dữ liệu này dựa trên các cột hợp nhất và không được đơn giản hóa bởi sự hiện diện của khóa.
Tập lệnh sau sử dụng cờ theo dõi không được hỗ trợ 8649 để tạo một kế hoạch song song cho truy vấn trước đó (nếu không thì không thay đổi):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
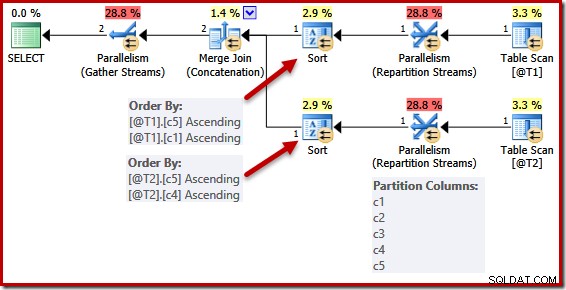
Danh sách sắp xếp được đơn giản hóa như trước đây, nhưng các toán tử Luồng phân vùng vẫn phân vùng trên tất cả các cột. Nếu việc đơn giản hóa này được thực hiện một cách nhất quán, thì các toán tử phân vùng lại cũng sẽ hoạt động trên (c5, c1) và (c5, c4) một mình.
Sự cố với các chỉ mục không phải là duy nhất
Cách trình tối ưu hóa giải thích về các yêu cầu sắp xếp đối với ghép nối hợp nhất có thể dẫn đến các vấn đề sắp xếp không cần thiết, như ví dụ tiếp theo cho thấy:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Nhìn vào truy vấn và các chỉ mục có sẵn, chúng tôi mong đợi một kế hoạch thực thi thực hiện quét theo thứ tự các chỉ mục được phân cụm, sử dụng nối kết hợp liên kết để tránh cần phải sắp xếp. Kỳ vọng này hoàn toàn chính đáng, bởi vì các chỉ mục được phân nhóm cung cấp thứ tự được chỉ định trong mệnh đề ORDER BY. Thật không may, kế hoạch mà chúng tôi thực sự nhận được bao gồm hai loại:
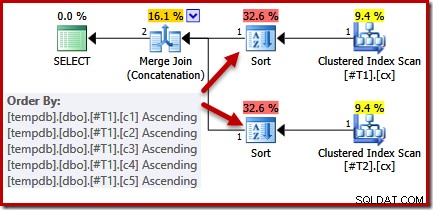
Không có lý do chính đáng cho những loại này, chúng chỉ xuất hiện vì logic của trình tối ưu hóa truy vấn không hoàn hảo. Danh sách cột đầu ra hợp nhất (c1, c2, c3, c4, c5) là tập hợp con của ORDER BY, nhưng không có duy nhất chìa khóa để đơn giản hóa danh sách đó. Do khoảng trống này trong lý luận của trình tối ưu hóa, nó kết luận rằng hợp nhất yêu cầu đầu vào của nó được sắp xếp theo (c1, c2, c3, c4, c5).
Chúng tôi có thể xác minh phân tích này bằng cách sửa đổi tập lệnh để làm cho một trong các chỉ mục được nhóm thành duy nhất:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Kế hoạch thực thi bây giờ chỉ có một loại phía trên bảng với chỉ mục không phải là duy nhất:
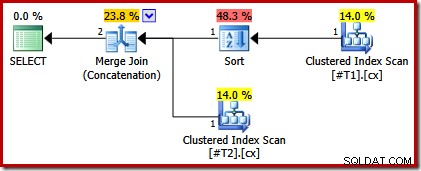
Nếu bây giờ chúng ta thực hiện cả hai nhóm chỉ mục duy nhất, không có loại nào xuất hiện:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Với cả hai chỉ mục là duy nhất, danh sách sắp xếp đầu vào hợp nhất ban đầu có thể được đơn giản hóa thành chỉ cột c1. Sau đó, danh sách được đơn giản hóa khớp chính xác với mệnh đề ORDER BY, vì vậy không cần sắp xếp trong phương án cuối cùng:
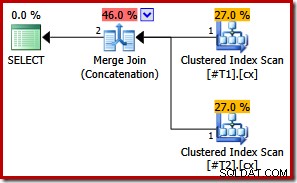
Lưu ý rằng chúng tôi thậm chí không cần gợi ý truy vấn trong ví dụ cuối cùng này để có được kế hoạch thực thi tối ưu.
Lời kết
Việc loại bỏ các loại trong một kế hoạch thực hiện có thể rất phức tạp. Trong một số trường hợp, có thể đơn giản như sửa đổi chỉ mục hiện có (hoặc cung cấp chỉ mục mới) để phân phối các hàng theo thứ tự được yêu cầu. Trình tối ưu hóa truy vấn thực hiện một công việc hợp lý về tổng thể khi có các chỉ mục thích hợp.
Tuy nhiên, trong (nhiều) trường hợp khác, việc tránh sắp xếp có thể đòi hỏi sự hiểu biết sâu sắc hơn nhiều về công cụ thực thi, trình tối ưu hóa truy vấn và bản thân các toán tử lập kế hoạch. Tránh các loại chắc chắn là một chủ đề điều chỉnh truy vấn nâng cao, nhưng cũng là một chủ đề vô cùng bổ ích khi mọi thứ đều đúng.